 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Retrieval on Real-life Images with Pre-trained Vision-and-Language Models
Aug 09, 2021

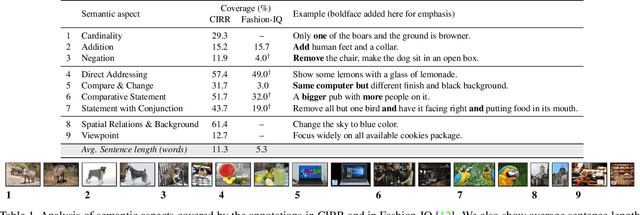
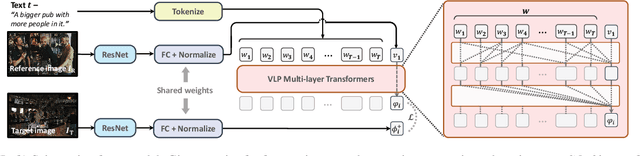
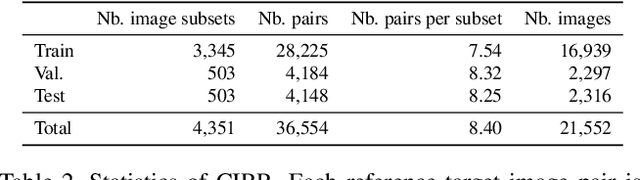
We extend the task of composed image retrieval, where an input query consists of an image and short textual description of how to modify the image. Existing methods have only been applied to non-complex images within narrow domains, such as fashion products, thereby limiting the scope of study on in-depth visual reasoning in rich image and language contexts. To address this issue, we collect the Compose Image Retrieval on Real-life images (CIRR) dataset, which consists of over 36,000 pairs of crowd-sourced, open-domain images with human-generated modifying text. To extend current methods to the open-domain, we propose CIRPLANT, a transformer based model that leverages rich pre-trained vision-and-language (V&L) knowledge for modifying visual features conditioned on natural language. Retrieval is then done by nearest neighbor lookup on the modified features. We demonstrate that with a relatively simple architecture, CIRPLANT outperforms existing methods on open-domain images, while matching state-of-the-art accuracy on the existing narrow datasets, such as fashion. Together with the release of CIRR, we believe this work will inspire further research on composed image retrieval.
End-to-end optimized image compression with competition of prior distributions
Nov 17, 2021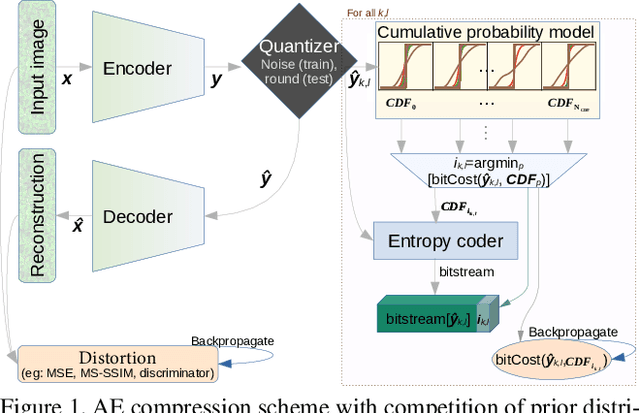
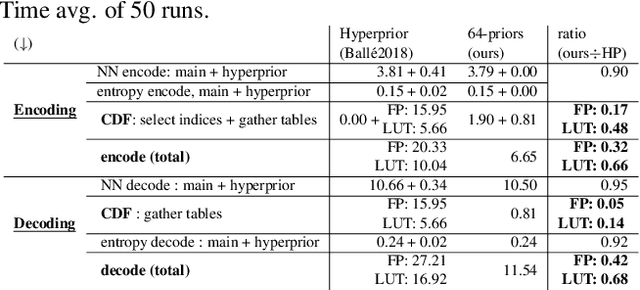

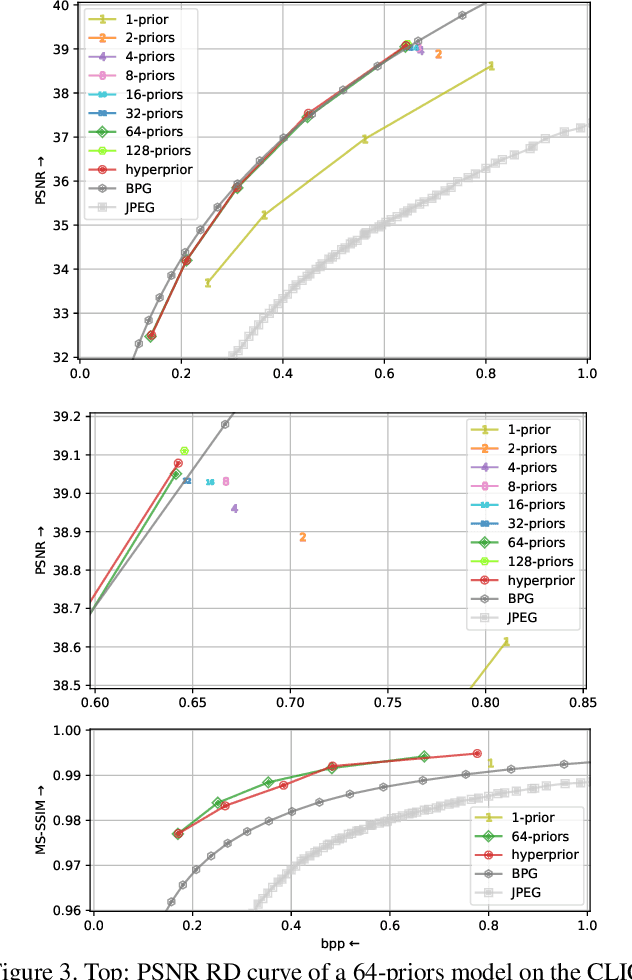
Convolutional autoencoders are now at the forefront of image compression research. To improve their entropy coding, encoder output is typically analyzed with a second autoencoder to generate per-variable parametrized prior probability distributions. We instead propose a compression scheme that uses a single convolutional autoencoder and multiple learned prior distributions working as a competition of experts. Trained prior distributions are stored in a static table of cumulative distribution functions. During inference, this table is used by an entropy coder as a look-up-table to determine the best prior for each spatial location. Our method offers rate-distortion performance comparable to that obtained with a predicted parametrized prior with only a fraction of its entropy coding and decoding complexity.
Deep Statistic Shape Model for Myocardium Segmentation
Jul 21, 2022
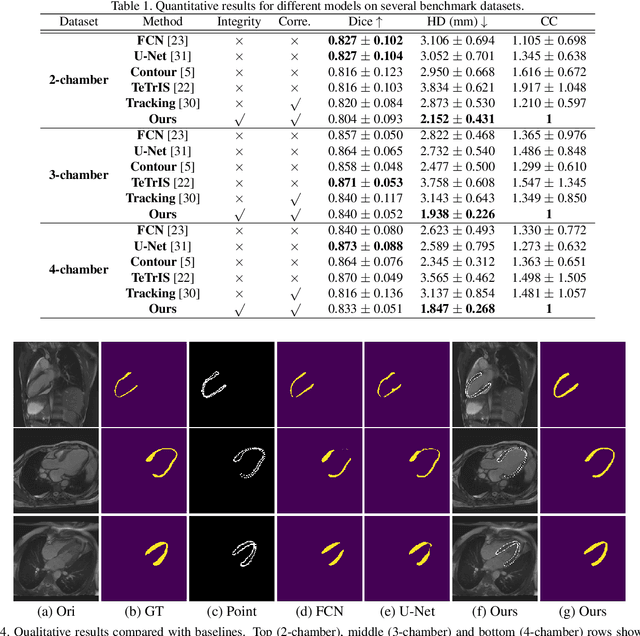
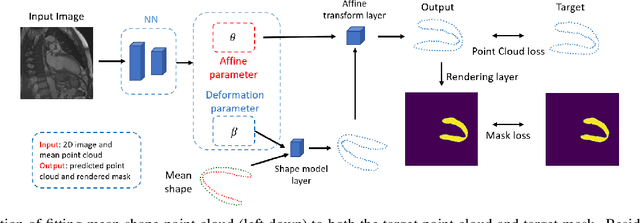
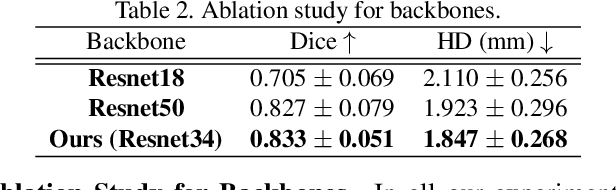
Accurate segmentation and motion estimation of myocardium have always been important in clinic field, which essentially contribute to the downstream diagnosis. However, existing methods cannot always guarantee the shape integrity for myocardium segmentation. In addition, motion estimation requires point correspondence on the myocardium region across different frames. In this paper, we propose a novel end-to-end deep statistic shape model to focus on myocardium segmentation with both shape integrity and boundary correspondence preserving. Specifically, myocardium shapes are represented by a fixed number of points, whose variations are extracted by Principal Component Analysis (PCA). Deep neural network is used to predict the transformation parameters (both affine and deformation), which are then used to warp the mean point cloud to the image domain. Furthermore, a differentiable rendering layer is introduced to incorporate mask supervision into the framework to learn more accurate point clouds. In this way, the proposed method is able to consistently produce anatomically reasonable segmentation mask without post processing. Additionally, the predicted point cloud guarantees boundary correspondence for sequential images, which contributes to the downstream tasks, such as the motion estimation of myocardium. We conduct several experiments to demonstrate the effectiveness of the proposed method on several benchmark datasets.
Temporally Consistent Semantic Video Editing
Jun 21, 2022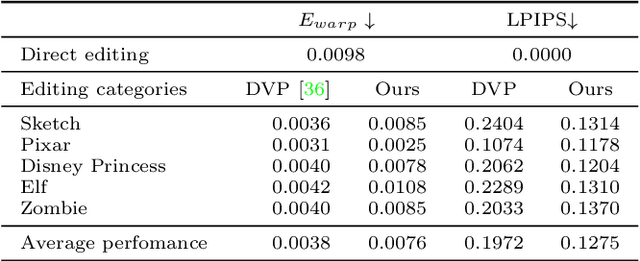

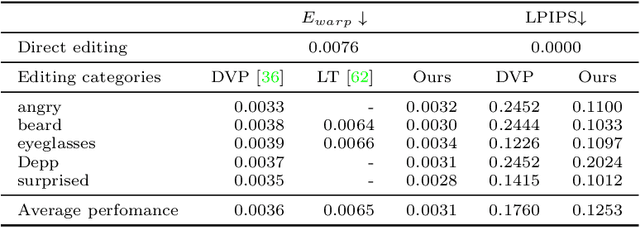
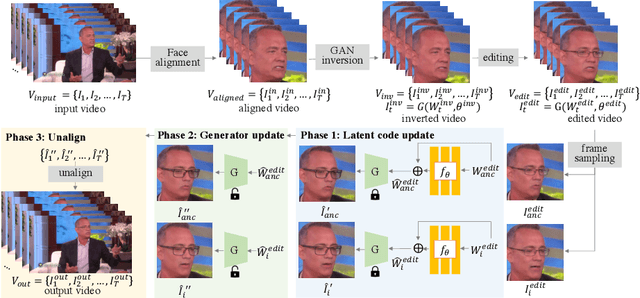
Generative adversarial networks (GANs) have demonstrated impressive image generation quality and semantic editing capability of real images, e.g., changing object classes, modifying attributes, or transferring styles. However, applying these GAN-based editing to a video independently for each frame inevitably results in temporal flickering artifacts. We present a simple yet effective method to facilitate temporally coherent video editing. Our core idea is to minimize the temporal photometric inconsistency by optimizing both the latent code and the pre-trained generator. We evaluate the quality of our editing on different domains and GAN inversion techniques and show favorable results against the baselines.
Training Transformers Together
Jul 07, 2022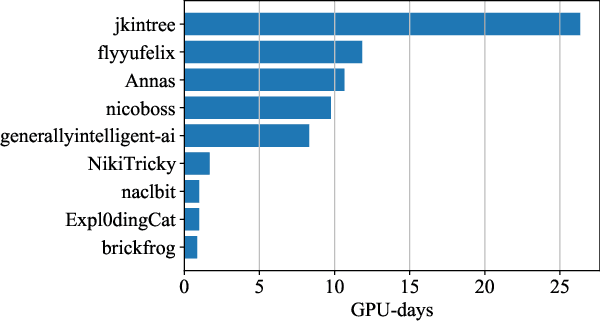

The infrastructure necessary for training state-of-the-art models is becoming overly expensive, which makes training such models affordable only to large corporations and institutions. Recent work proposes several methods for training such models collaboratively, i.e., by pooling together hardware from many independent parties and training a shared model over the Internet. In this demonstration, we collaboratively trained a text-to-image transformer similar to OpenAI DALL-E. We invited the viewers to join the ongoing training run, showing them instructions on how to contribute using the available hardware. We explained how to address the engineering challenges associated with such a training run (slow communication, limited memory, uneven performance between devices, and security concerns) and discussed how the viewers can set up collaborative training runs themselves. Finally, we show that the resulting model generates images of reasonable quality on a number of prompts.
Universal Adaptive Data Augmentation
Jul 14, 2022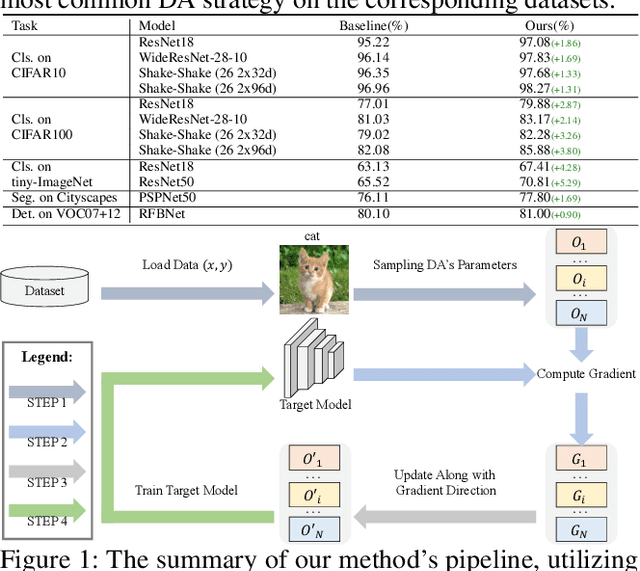
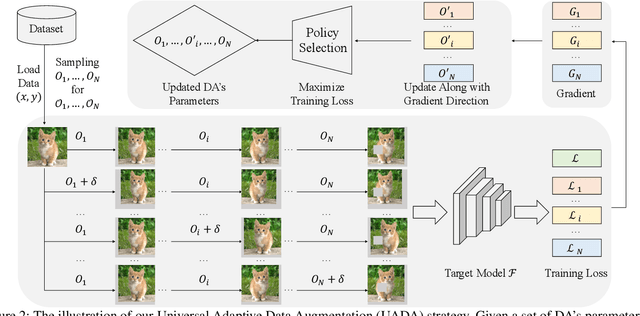
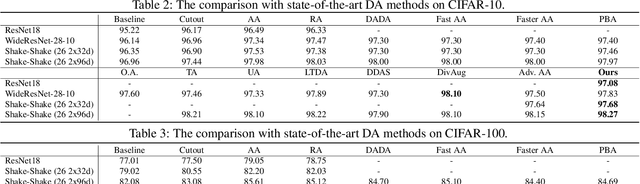
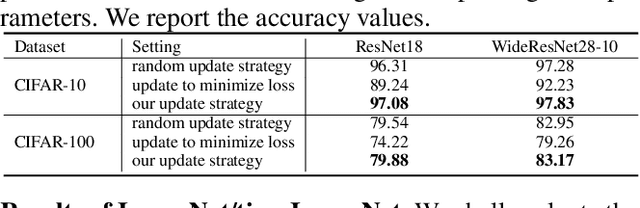
Existing automatic data augmentation (DA) methods either ignore updating DA's parameters according to the target model's state during training or adopt update strategies that are not effective enough. In this work, we design a novel data augmentation strategy called "Universal Adaptive Data Augmentation" (UADA). Different from existing methods, UADA would adaptively update DA's parameters according to the target model's gradient information during training: given a pre-defined set of DA operations, we randomly decide types and magnitudes of DA operations for every data batch during training, and adaptively update DA's parameters along the gradient direction of the loss concerning DA's parameters. In this way, UADA can increase the training loss of the target networks, and the target networks would learn features from harder samples to improve the generalization. Moreover, UADA is very general and can be utilized in numerous tasks, e.g., image classification, semantic segmentation and object detection. Extensive experiments with various models are conducted on CIFAR-10, CIFAR-100, ImageNet, tiny-ImageNet, Cityscapes, and VOC07+12 to prove the significant performance improvements brought by our proposed adaptive augmentation.
Mixed-UNet: Refined Class Activation Mapping for Weakly-Supervised Semantic Segmentation with Multi-scale Inference
May 06, 2022
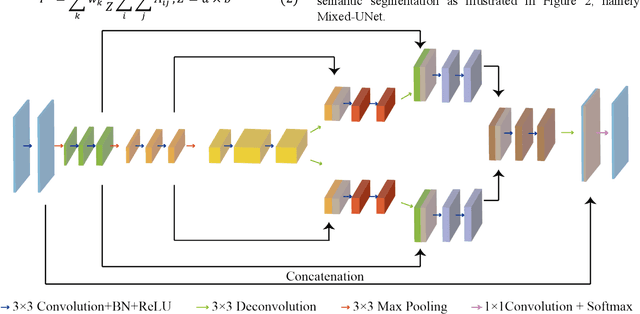
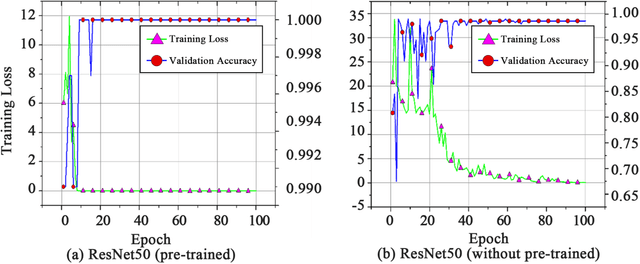
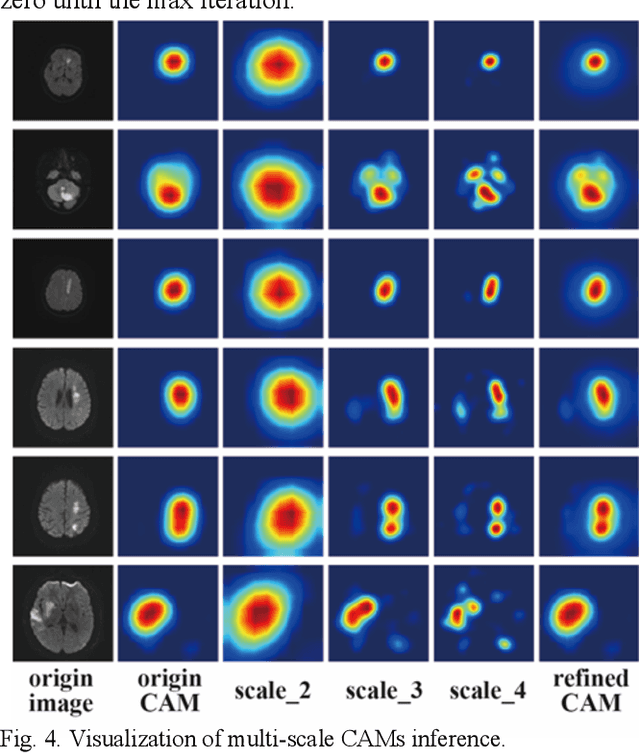
Deep learning techniques have shown great potential in medical image processing, particularly through accurate and reliable image segmentation on magnetic resonance imaging (MRI) scans or computed tomography (CT) scans, which allow the localization and diagnosis of lesions. However, training these segmentation models requires a large number of manually annotated pixel-level labels, which are time-consuming and labor-intensive, in contrast to image-level labels that are easier to obtain. It is imperative to resolve this problem through weakly-supervised semantic segmentation models using image-level labels as supervision since it can significantly reduce human annotation efforts. Most of the advanced solutions exploit class activation mapping (CAM). However, the original CAMs rarely capture the precise boundaries of lesions. In this study, we propose the strategy of multi-scale inference to refine CAMs by reducing the detail loss in single-scale reasoning. For segmentation, we develop a novel model named Mixed-UNet, which has two parallel branches in the decoding phase. The results can be obtained after fusing the extracted features from two branches. We evaluate the designed Mixed-UNet against several prevalent deep learning-based segmentation approaches on our dataset collected from the local hospital and public datasets. The validation results demonstrate that our model surpasses available methods under the same supervision level in the segmentation of various lesions from brain imaging.
A strong baseline for image and video quality assessment
Nov 13, 2021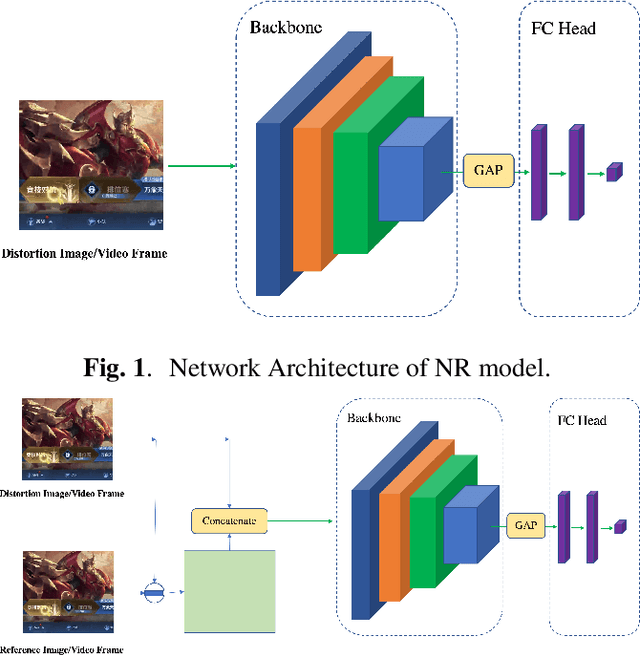
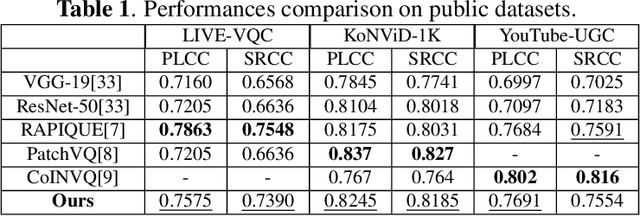

In this work, we present a simple yet effective unified model for perceptual quality assessment of image and video. In contrast to existing models which usually consist of complex network architecture, or rely on the concatenation of multiple branches of features, our model achieves a comparable performance by applying only one global feature derived from a backbone network (i.e. resnet18 in the presented work). Combined with some training tricks, the proposed model surpasses the current baselines of SOTA models on public and private datasets. Based on the architecture proposed, we release the models well trained for three common real-world scenarios: UGC videos in the wild, PGC videos with compression, Game videos with compression. These three pre-trained models can be directly applied for quality assessment, or be further fine-tuned for more customized usages. All the code, SDK, and the pre-trained weights of the proposed models are publicly available at https://github.com/Tencent/CenseoQoE.
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun 05, 2021
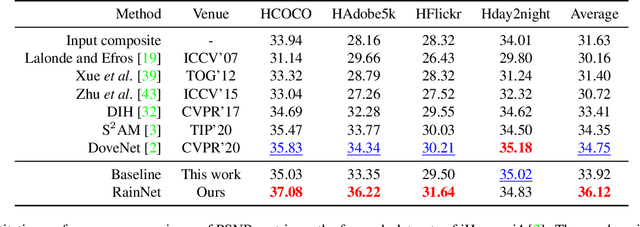
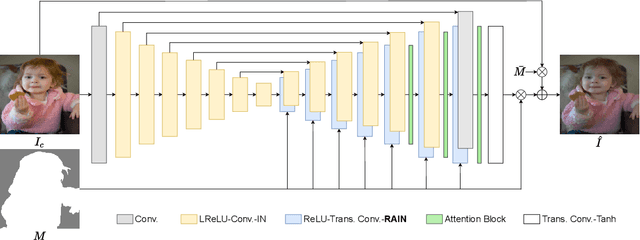
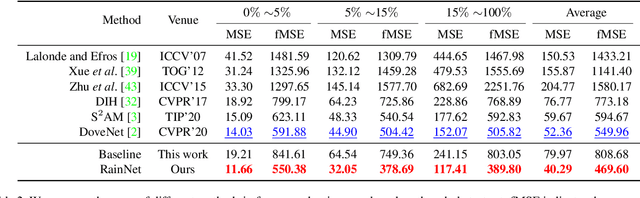
Image composition plays a common but important role in photo editing. To acquire photo-realistic composite images, one must adjust the appearance and visual style of the foreground to be compatible with the background. Existing deep learning methods for harmonizing composite images directly learn an image mapping network from the composite to the real one, without explicit exploration on visual style consistency between the background and the foreground images. To ensure the visual style consistency between the foreground and the background, in this paper, we treat image harmonization as a style transfer problem. In particular, we propose a simple yet effective Region-aware Adaptive Instance Normalization (RAIN) module, which explicitly formulates the visual style from the background and adaptively applies them to the foreground. With our settings, our RAIN module can be used as a drop-in module for existing image harmonization networks and is able to bring significant improvements. Extensive experiments on the existing image harmonization benchmark datasets show the superior capability of the proposed method. Code is available at {https://github.com/junleen/RainNet}.
VisualTextRank: Unsupervised Graph-based Content Extraction for Automating Ad Text to Image Search
Aug 05, 2021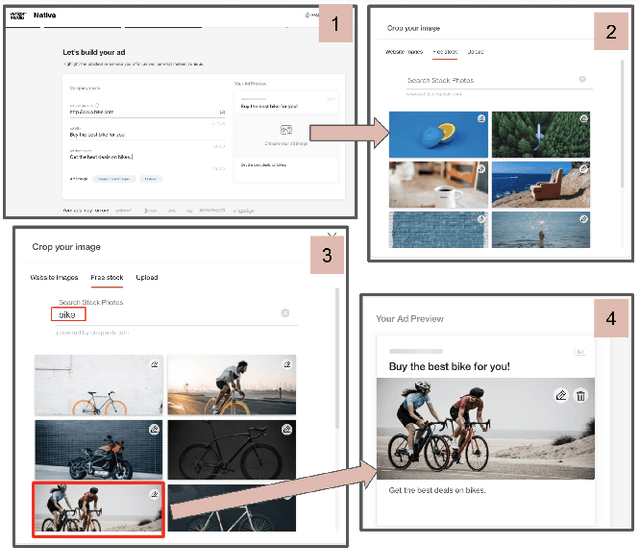
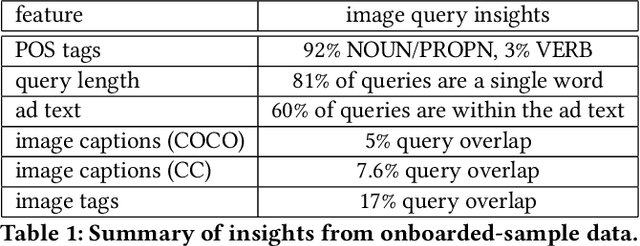
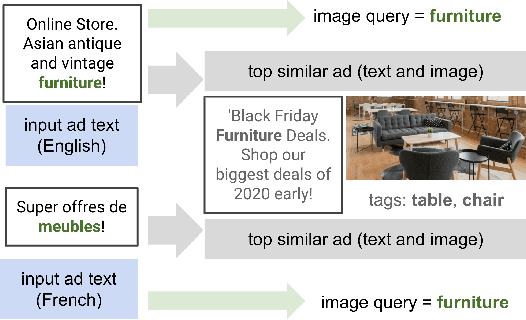
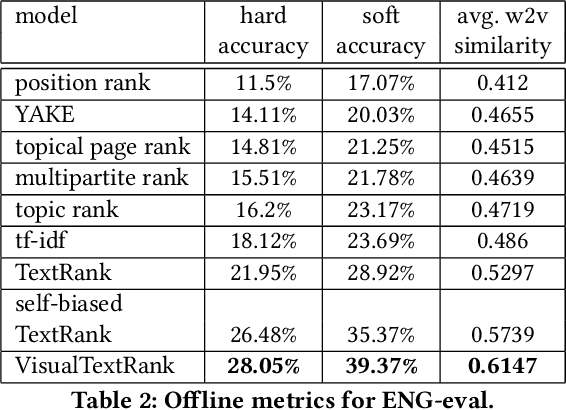
Numerous online stock image libraries offer high quality yet copyright free images for use in marketing campaigns. To assist advertisers in navigating such third party libraries, we study the problem of automatically fetching relevant ad images given the ad text (via a short textual query for images). Motivated by our observations in logged data on ad image search queries (given ad text), we formulate a keyword extraction problem, where a keyword extracted from the ad text (or its augmented version) serves as the ad image query. In this context, we propose VisualTextRank: an unsupervised method to (i) augment input ad text using semantically similar ads, and (ii) extract the image query from the augmented ad text. VisualTextRank builds on prior work on graph based context extraction (biased TextRank in particular) by leveraging both the text and image of similar ads for better keyword extraction, and using advertiser category specific biasing with sentence-BERT embeddings. Using data collected from the Verizon Media Native (Yahoo Gemini) ad platform's stock image search feature for onboarding advertisers, we demonstrate the superiority of VisualTextRank compared to competitive keyword extraction baselines (including an $11\%$ accuracy lift over biased TextRank). For the case when the stock image library is restricted to English queries, we show the effectiveness of VisualTextRank on multilingual ads (translated to English) while leveraging semantically similar English ads. Online tests with a simplified version of VisualTextRank led to a 28.7% increase in the usage of stock image search, and a 41.6% increase in the advertiser onboarding rate in the Verizon Media Native ad platform.