 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hard Sample Aware Noise Robust Learning for Histopathology Image Classification
Dec 05, 2021
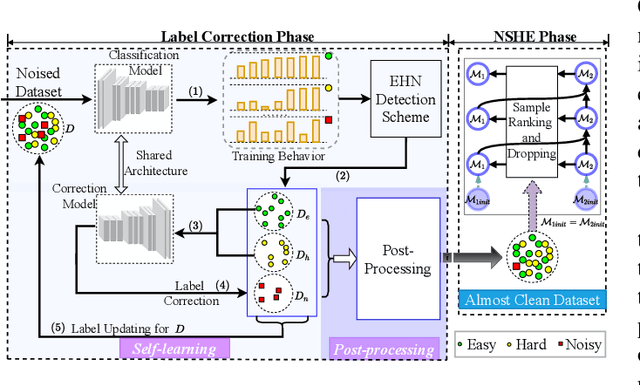
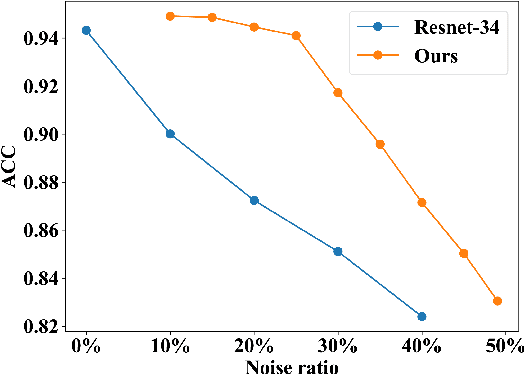
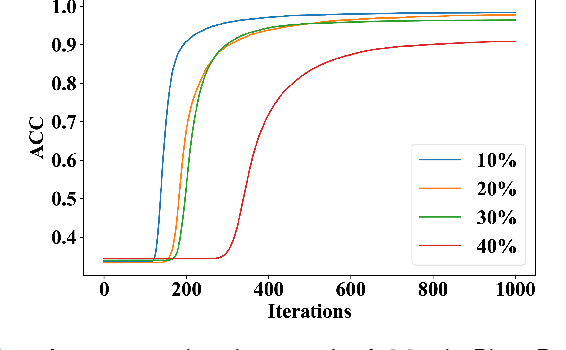
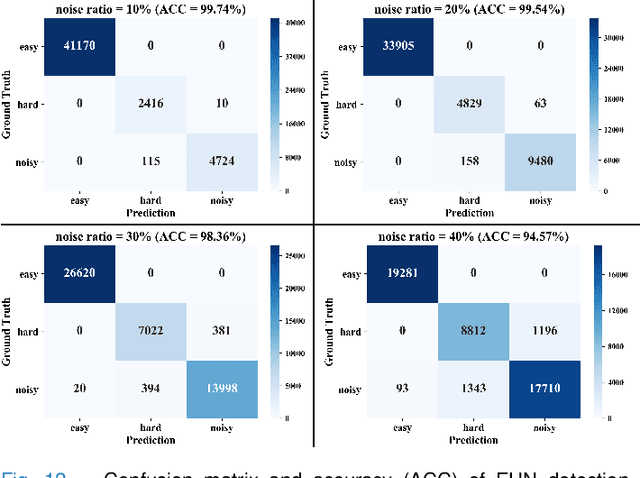
Deep learning-based histopathology image classification is a key technique to help physicians in improving the accuracy and promptness of cancer diagnosis. However, the noisy labels are often inevitable in the complex manual annotation process, and thus mislead the training of the classification model. In this work, we introduce a novel hard sample aware noise robust learning method for histopathology image classification. To distinguish the informative hard samples from the harmful noisy ones, we build an easy/hard/noisy (EHN) detection model by using the sample training history. Then we integrate the EHN into a self-training architecture to lower the noise rate through gradually label correction. With the obtained almost clean dataset, we further propose a noise suppressing and hard enhancing (NSHE) scheme to train the noise robust model. Compared with the previous works, our method can save more clean samples and can be directly applied to the real-world noisy dataset scenario without using a clean subset. Experimental results demonstrate that the proposed scheme outperforms the current state-of-the-art methods in both the synthetic and real-world noisy datasets. The source code and data are available at https://github.com/bupt-ai-cz/HSA-NRL/.
Learning to regulate 3D head shape by removing occluding hair from in-the-wild images
Aug 25, 2022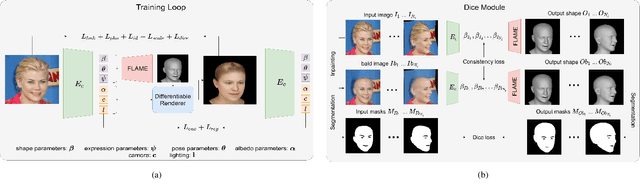
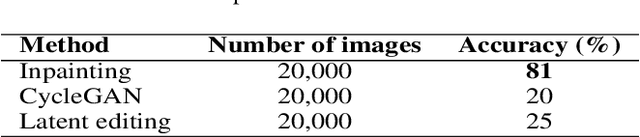
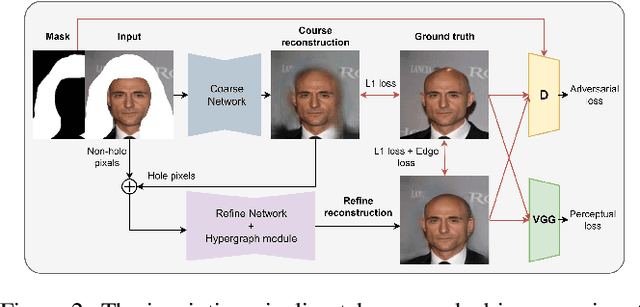
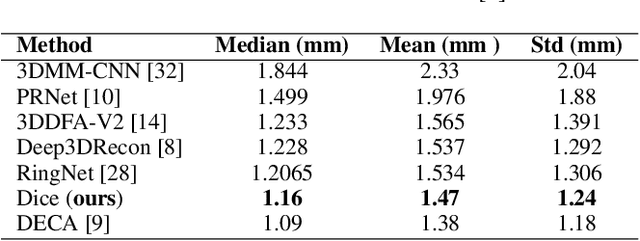
Recent 3D face reconstruction methods reconstruct the entire head compared to earlier approaches which only model the face. Although these methods accurately reconstruct facial features, they do not explicitly regulate the upper part of the head. Extracting information about this part of the head is challenging due to varying degrees of occlusion by hair. We present a novel approach for modeling the upper head by removing occluding hair and reconstructing the skin, revealing information about the head shape. We introduce three objectives: 1) a dice consistency loss that enforces similarity between the overall head shape of the source and rendered image, 2) a scale consistency loss to ensure that head shape is accurately reproduced even if the upper part of the head is not visible, and 3) a 71 landmark detector trained using a moving average loss function to detect additional landmarks on the head. These objectives are used to train an encoder in an unsupervised manner to regress FLAME parameters from in-the-wild input images. Our unsupervised 3DMM model achieves state-of-the-art results on popular benchmarks and can be used to infer the head shape, facial features, and textures for direct use in animation or avatar creation.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021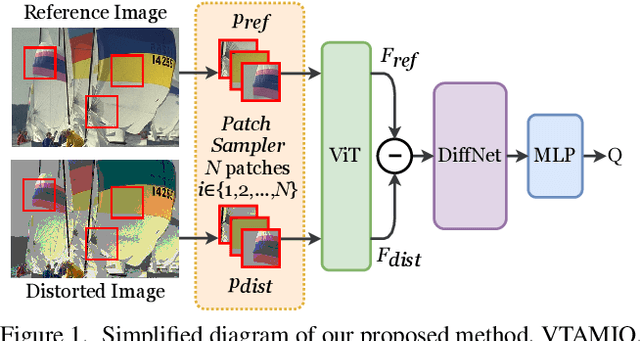
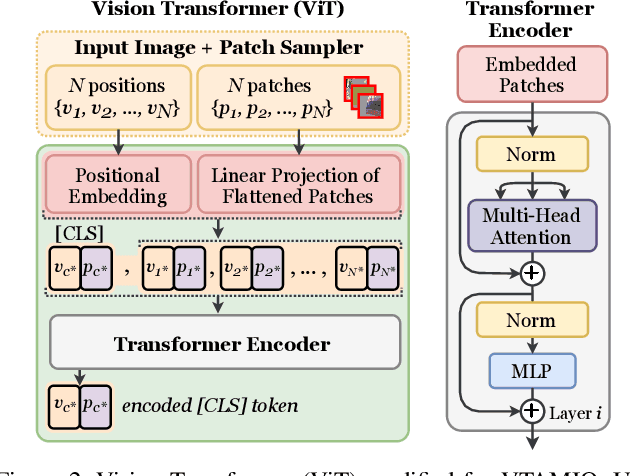
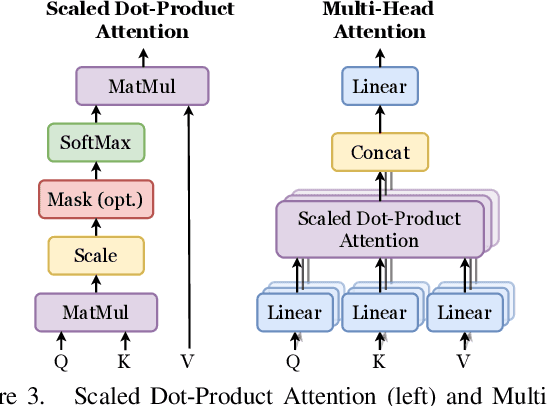
Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.
FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimization
Dec 02, 2021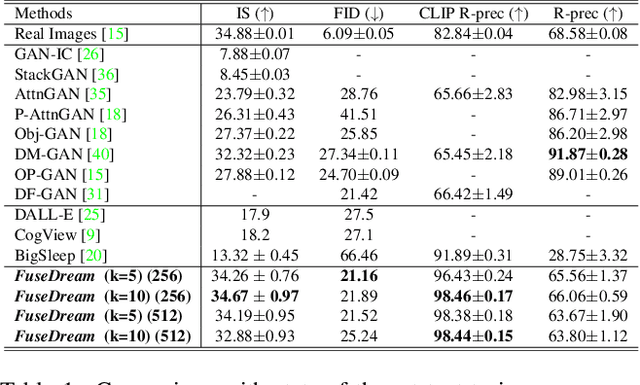



Generating images from natural language instructions is an intriguing yet highly challenging task. We approach text-to-image generation by combining the power of the retrained CLIP representation with an off-the-shelf image generator (GANs), optimizing in the latent space of GAN to find images that achieve maximum CLIP score with the given input text. Compared to traditional methods that train generative models from text to image starting from scratch, the CLIP+GAN approach is training-free, zero shot and can be easily customized with different generators. However, optimizing CLIP score in the GAN space casts a highly challenging optimization problem and off-the-shelf optimizers such as Adam fail to yield satisfying results. In this work, we propose a FuseDream pipeline, which improves the CLIP+GAN approach with three key techniques: 1) an AugCLIP score which robustifies the CLIP objective by introducing random augmentation on image. 2) a novel initialization and over-parameterization strategy for optimization which allows us to efficiently navigate the non-convex landscape in GAN space. 3) a composed generation technique which, by leveraging a novel bi-level optimization formulation, can compose multiple images to extend the GAN space and overcome the data-bias. When promoted by different input text, FuseDream can generate high-quality images with varying objects, backgrounds, artistic styles, even novel counterfactual concepts that do not appear in the training data of the GAN we use. Quantitatively, the images generated by FuseDream yield top-level Inception score and FID score on MS COCO dataset, without additional architecture design or training. Our code is publicly available at \url{https://github.com/gnobitab/FuseDream}.
Virtual staining of defocused autofluorescence images of unlabeled tissue using deep neural networks
Jul 06, 2022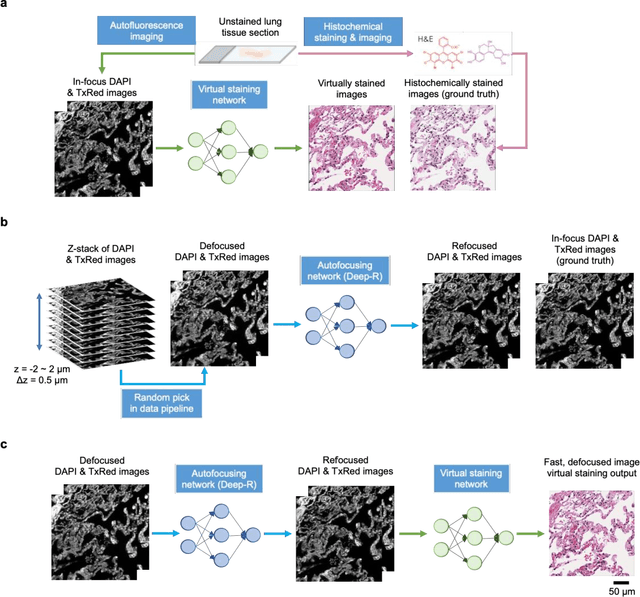
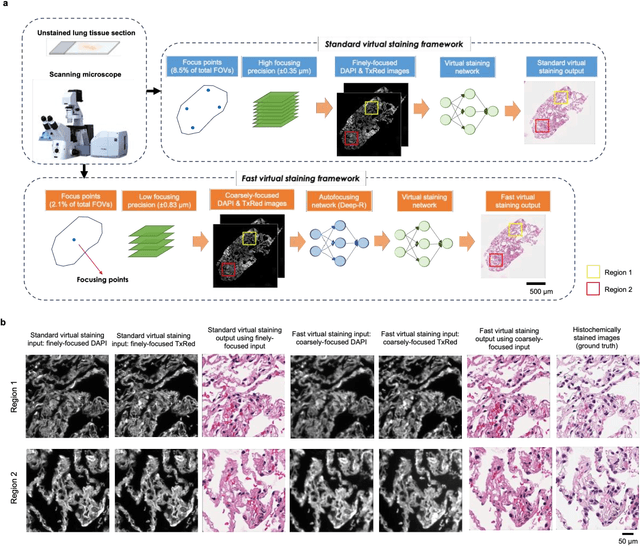
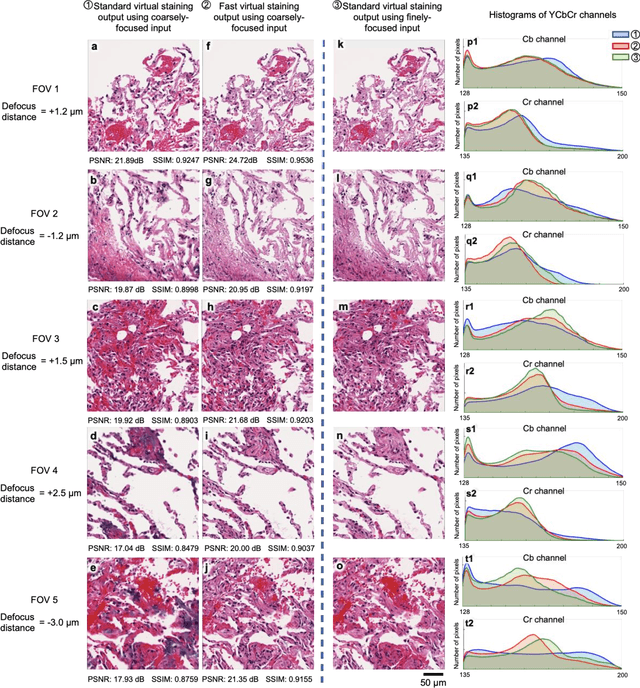
Deep learning-based virtual staining was developed to introduce image contrast to label-free tissue sections, digitally matching the histological staining, which is time-consuming, labor-intensive, and destructive to tissue. Standard virtual staining requires high autofocusing precision during the whole slide imaging of label-free tissue, which consumes a significant portion of the total imaging time and can lead to tissue photodamage. Here, we introduce a fast virtual staining framework that can stain defocused autofluorescence images of unlabeled tissue, achieving equivalent performance to virtual staining of in-focus label-free images, also saving significant imaging time by lowering the microscope's autofocusing precision. This framework incorporates a virtual-autofocusing neural network to digitally refocus the defocused images and then transforms the refocused images into virtually stained images using a successive network. These cascaded networks form a collaborative inference scheme: the virtual staining model regularizes the virtual-autofocusing network through a style loss during the training. To demonstrate the efficacy of this framework, we trained and blindly tested these networks using human lung tissue. Using 4x fewer focus points with 2x lower focusing precision, we successfully transformed the coarsely-focused autofluorescence images into high-quality virtually stained H&E images, matching the standard virtual staining framework that used finely-focused autofluorescence input images. Without sacrificing the staining quality, this framework decreases the total image acquisition time needed for virtual staining of a label-free whole-slide image (WSI) by ~32%, together with a ~89% decrease in the autofocusing time, and has the potential to eliminate the laborious and costly histochemical staining process in pathology.
Signal Injection Attacks against CCD Image Sensors
Aug 19, 2021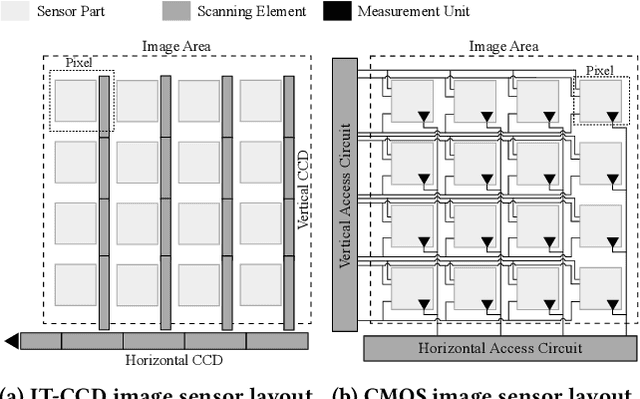

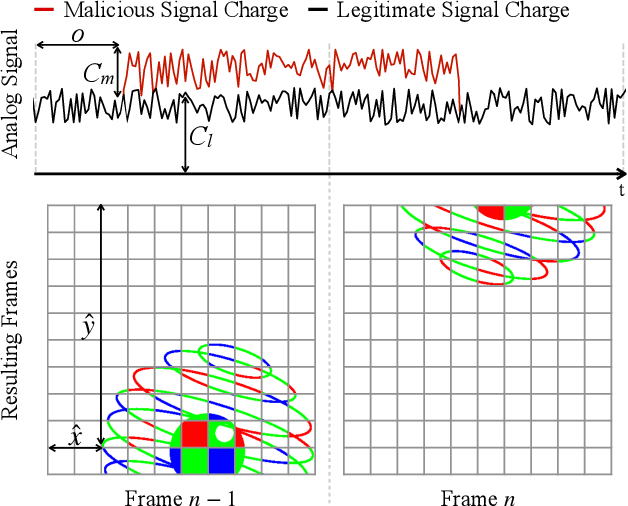
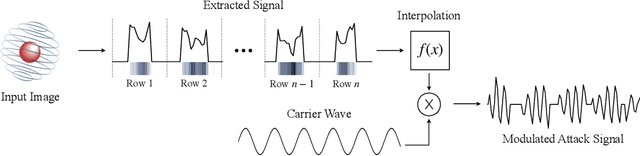
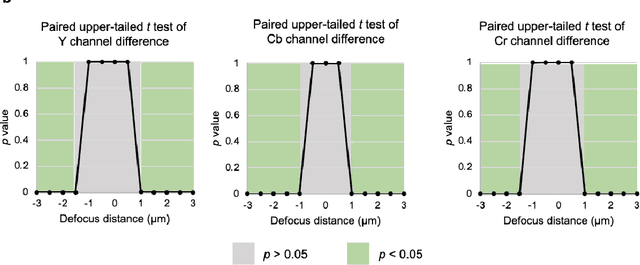
Since cameras have become a crucial part in many safety-critical systems and applications, such as autonomous vehicles and surveillance, a large body of academic and non-academic work has shown attacks against their main component - the image sensor. However, these attacks are limited to coarse-grained and often suspicious injections because light is used as an attack vector. Furthermore, due to the nature of optical attacks, they require the line-of-sight between the adversary and the target camera. In this paper, we present a novel post-transducer signal injection attack against CCD image sensors, as they are used in professional, scientific, and even military settings. We show how electromagnetic emanation can be used to manipulate the image information captured by a CCD image sensor with the granularity down to the brightness of individual pixels. We study the feasibility of our attack and then demonstrate its effects in the scenario of automatic barcode scanning. Our results indicate that the injected distortion can disrupt automated vision-based intelligent systems.
D^2LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Nov 13, 2021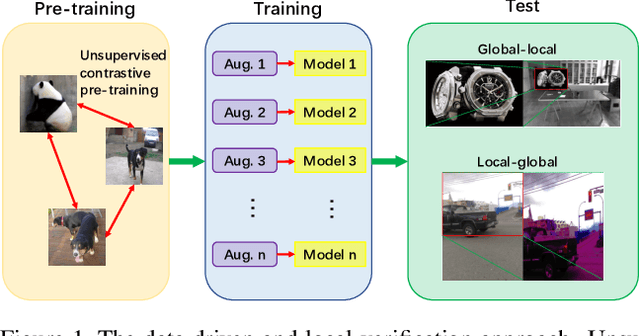
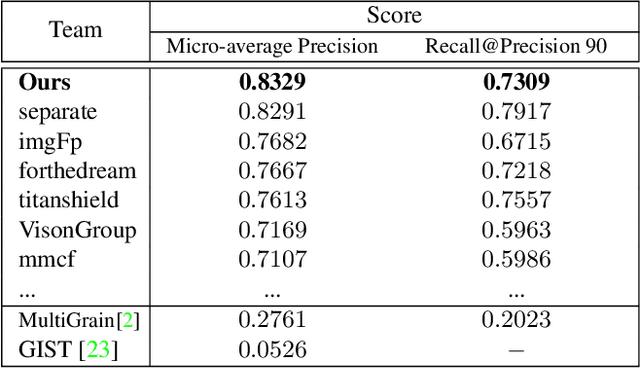
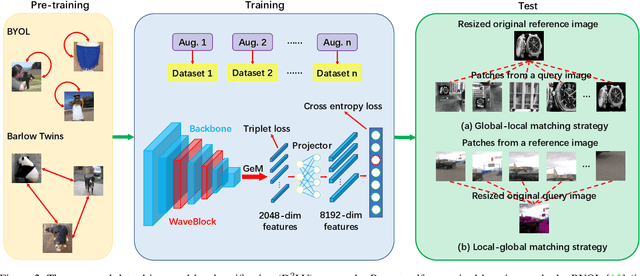
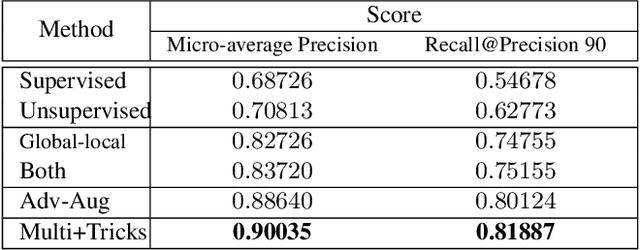
Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D^2LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D^2LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Contrastive Deep Supervision
Jul 12, 2022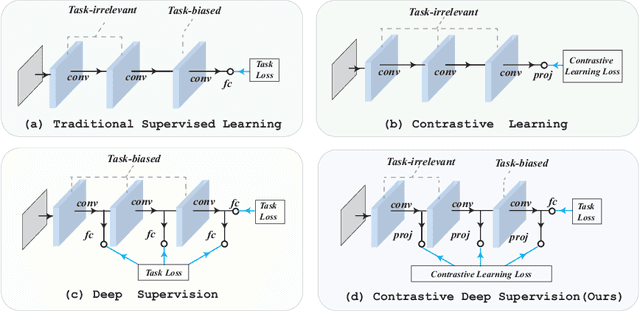
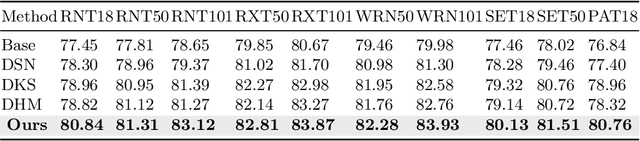
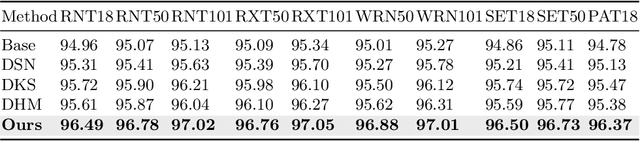
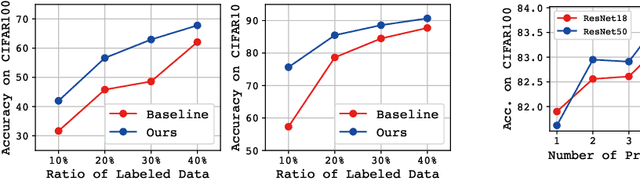
The success of deep learning is usually accompanied by the growth in neural network depth. However, the traditional training method only supervises the neural network at its last layer and propagates the supervision layer-by-layer, which leads to hardship in optimizing the intermediate layers. Recently, deep supervision has been proposed to add auxiliary classifiers to the intermediate layers of deep neural networks. By optimizing these auxiliary classifiers with the supervised task loss, the supervision can be applied to the shallow layers directly. However, deep supervision conflicts with the well-known observation that the shallow layers learn low-level features instead of task-biased high-level semantic features. To address this issue, this paper proposes a novel training framework named Contrastive Deep Supervision, which supervises the intermediate layers with augmentation-based contrastive learning. Experimental results on nine popular datasets with eleven models demonstrate its effects on general image classification, fine-grained image classification and object detection in supervised learning, semi-supervised learning and knowledge distillation. Codes have been released in Github.
Toward an ImageNet Library of Functions for Global Optimization Benchmarking
Jun 27, 2022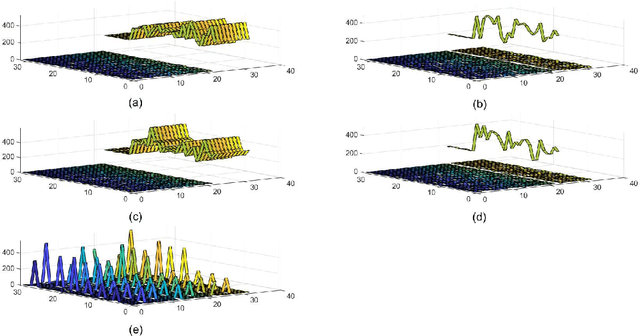
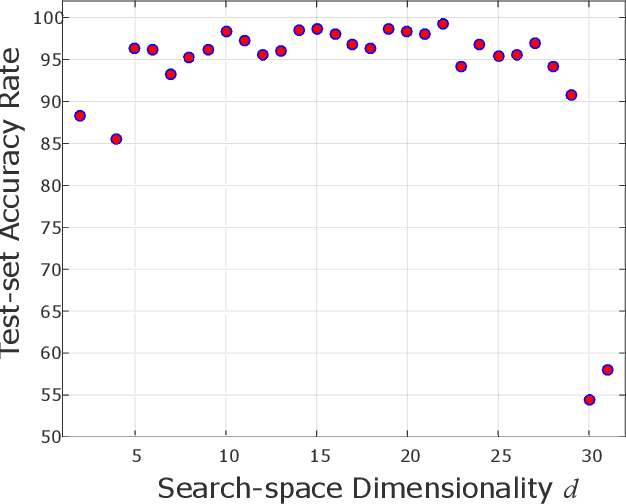
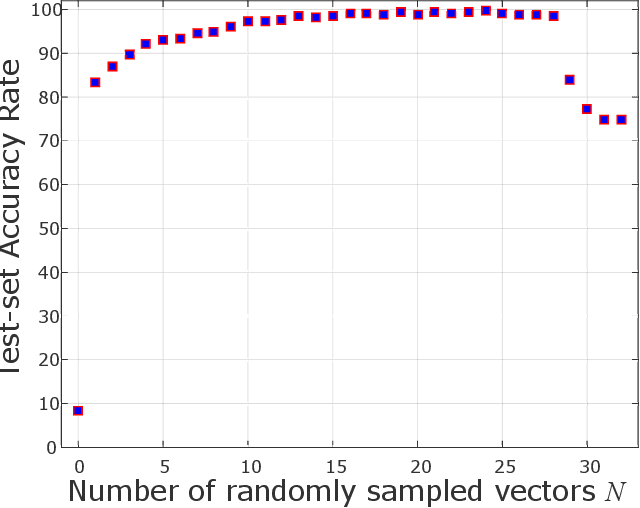
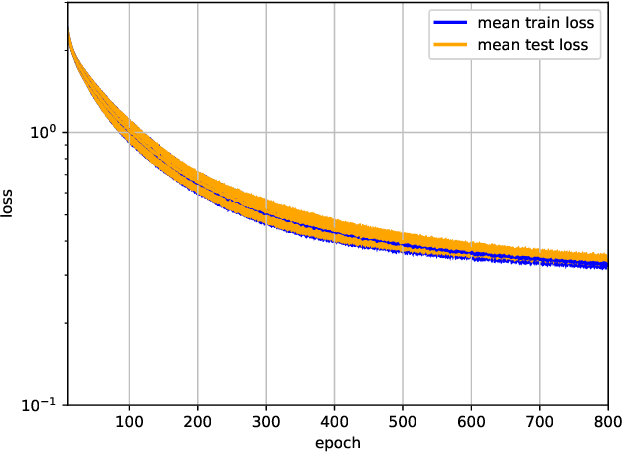
Knowledge of search-landscape features of BlackBox Optimization (BBO) problems offers valuable information in light of the Algorithm Selection and/or Configuration problems. Exploratory Landscape Analysis (ELA) models have gained success in identifying predefined human-derived features and in facilitating portfolio selectors to address those challenges. Unlike ELA approaches, the current study proposes to transform the identification problem into an image recognition problem, with a potential to detect conception-free, machine-driven landscape features. To this end, we introduce the notion of Landscape Images, which enables us to generate imagery instances per a benchmark function, and then target the classification challenge over a diverse generalized dataset of functions. We address it as a supervised multi-class image recognition problem and apply basic artificial neural network models to solve it. The efficacy of our approach is numerically validated on the noise free BBOB and IOHprofiler benchmarking suites. This evident successful learning is another step toward automated feature extraction and local structure deduction of BBO problems. By using this definition of landscape images, and by capitalizing on existing capabilities of image recognition algorithms, we foresee the construction of an ImageNet-like library of functions for training generalized detectors that rely on machine-driven features.
A Simple Baseline for Multi-Camera 3D Object Detection
Aug 22, 2022
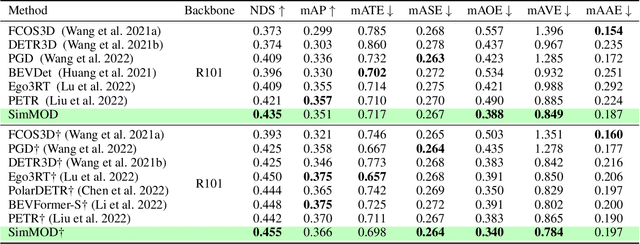
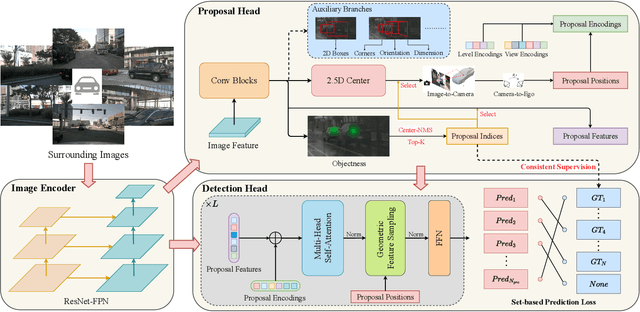
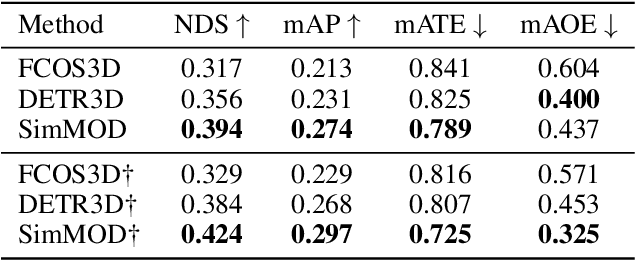
3D object detection with surrounding cameras has been a promising direction for autonomous driving. In this paper, we present SimMOD, a Simple baseline for Multi-camera Object Detection, to solve the problem. To incorporate multi-view information as well as build upon previous efforts on monocular 3D object detection, the framework is built on sample-wise object proposals and designed to work in a two-stage manner. First, we extract multi-scale features and generate the perspective object proposals on each monocular image. Second, the multi-view proposals are aggregated and then iteratively refined with multi-view and multi-scale visual features in the DETR3D-style. The refined proposals are end-to-end decoded into the detection results. To further boost the performance, we incorporate the auxiliary branches alongside the proposal generation to enhance the feature learning. Also, we design the methods of target filtering and teacher forcing to promote the consistency of two-stage training. We conduct extensive experiments on the 3D object detection benchmark of nuScenes to demonstrate the effectiveness of SimMOD and achieve new state-of-the-art performance. Code will be available at https://github.com/zhangyp15/SimMOD.