 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Operation Theatre: An AI-based System for Surgical Gauze Counting
Mar 21, 2026During surgeries, there is a risk of medical gauzes being left inside patients' bodies, leading to "Gossypiboma" in patients and can cause serious complications in patients and also lead to legal problems for hospitals from malpractice lawsuits and regulatory penalties. Diagnosis depends on imaging methods such as X-rays or CT scans, and the usual treatment involves surgical excision. Prevention methods, such as manual counts and RFID-integrated gauzes, aim to minimize gossypiboma risks. However, manual tallying of 100s of gauzes by nurses is time-consuming and diverts resources from patient care. In partnership with Singapore General Hospital (SGH) we have developed a new prevention method, an AI-based system for gauze counting in surgical settings. Utilizing real-time video surveillance and object recognition technology powered by YOLOv5, a Deep Learning model was designed to monitor gauzes on two designated trays labelled "In" and "Out". Gauzes are tracked from the "In" tray, prior to their use in the patient's body & in the "Out" tray post-use, ensuring accurate counting and verifying that no gauze remains inside the patient at the end of the surgery. We have trained it using numerous images from Operation Theatres & augmented it to satisfy all possible scenarios. This study has also addressed the shortcomings of previous project iterations. Previously, the project employed two models: one for human detection and another for gauze detection, trained on a total of 2800 images. Now we have an integrated model capable of identifying both humans and gauzes, using a training set of 11,000 images. This has led to improvements in accuracy and increased the frame rate from 8 FPS to 15 FPS now. Incorporating doctor's feedback, the system now also supports manual count adjustments, enhancing its reliability in actual surgeries.
Learning to regulate 3D head shape by removing occluding hair from in-the-wild images
Aug 25, 2022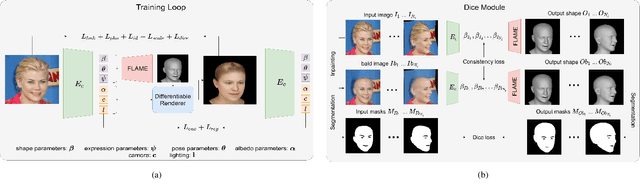
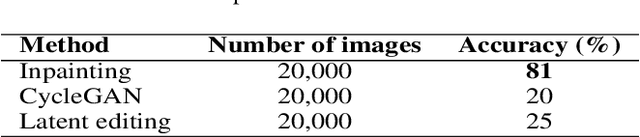
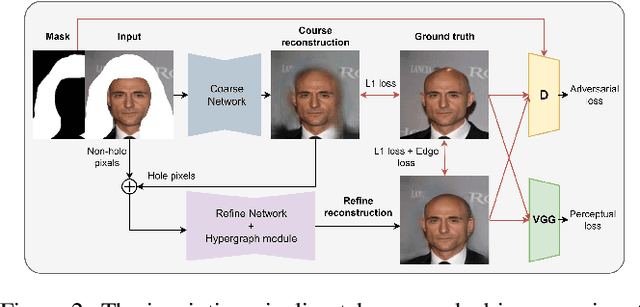
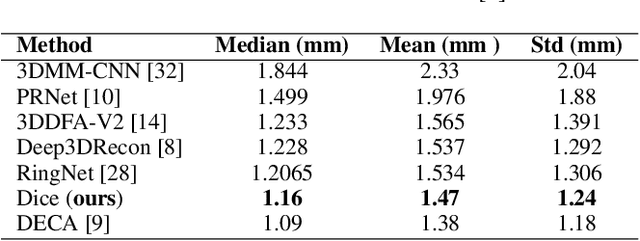
Recent 3D face reconstruction methods reconstruct the entire head compared to earlier approaches which only model the face. Although these methods accurately reconstruct facial features, they do not explicitly regulate the upper part of the head. Extracting information about this part of the head is challenging due to varying degrees of occlusion by hair. We present a novel approach for modeling the upper head by removing occluding hair and reconstructing the skin, revealing information about the head shape. We introduce three objectives: 1) a dice consistency loss that enforces similarity between the overall head shape of the source and rendered image, 2) a scale consistency loss to ensure that head shape is accurately reproduced even if the upper part of the head is not visible, and 3) a 71 landmark detector trained using a moving average loss function to detect additional landmarks on the head. These objectives are used to train an encoder in an unsupervised manner to regress FLAME parameters from in-the-wild input images. Our unsupervised 3DMM model achieves state-of-the-art results on popular benchmarks and can be used to infer the head shape, facial features, and textures for direct use in animation or avatar creation.