 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Image Deblurring: a Review
Jan 22, 2022

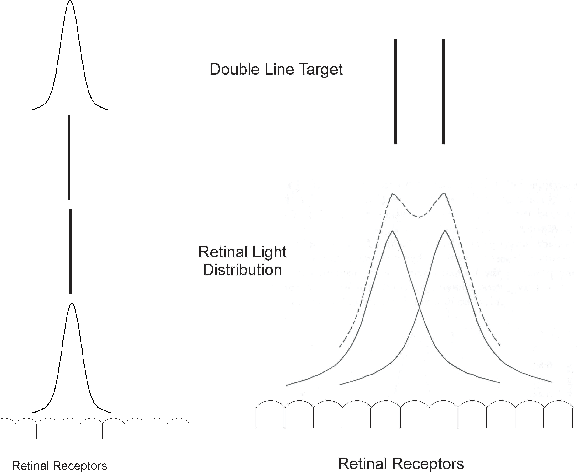


This is a review on blind image deblurring. First, we formulate the blind image deblurring problem and explain why it is challenging. Next, we bring some psychological and cognitive studies on the way our human vision system deblurs. Then, relying on several previous reviews, we discuss the topic of metrics and datasets, which is non-trivial to blind deblurring. Finally, we introduce some typical optimization-based methods and learning-based methods.
ERNIE-UniX2: A Unified Cross-lingual Cross-modal Framework for Understanding and Generation
Nov 09, 2022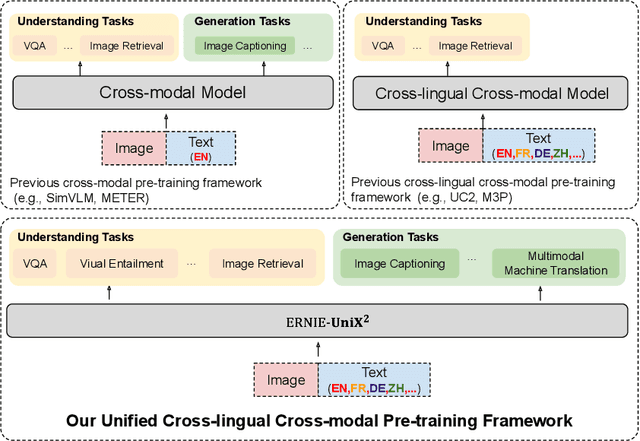
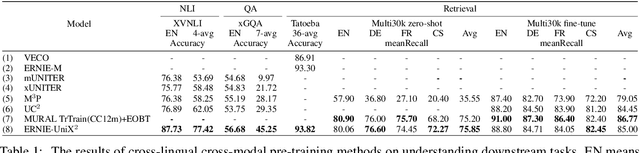
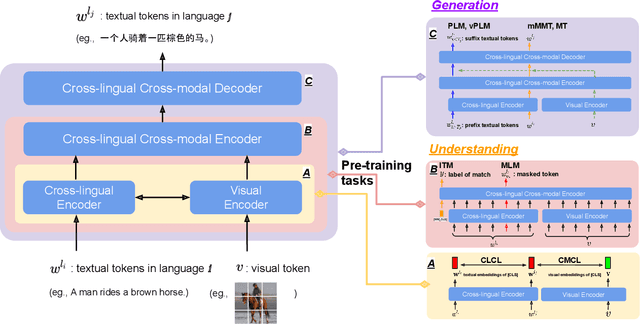
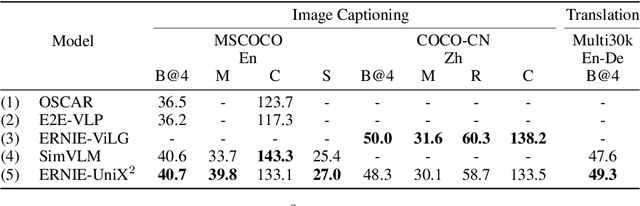
Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
UID2021: An Underwater Image Dataset for Evaluation of No-reference Quality Assessment Metrics
Apr 19, 2022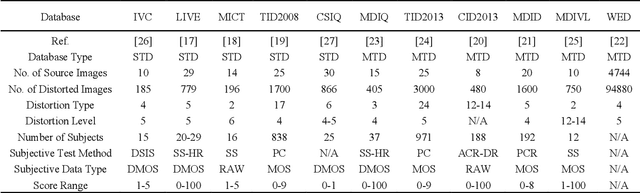

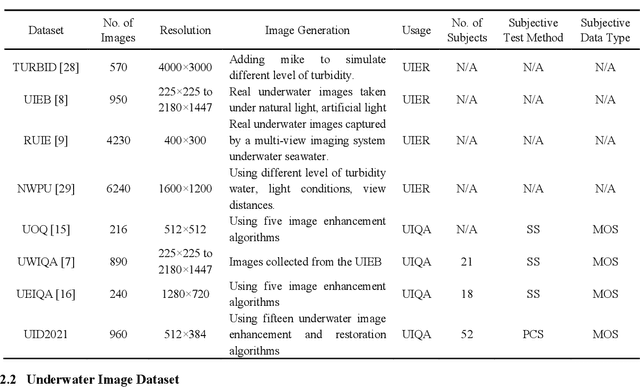

Achieving subjective and objective quality assessment of underwater images is of high significance in underwater visual perception and image/video processing. However, the development of underwater image quality assessment (UIQA) is limited for the lack of comprehensive human subjective user study with publicly available dataset and reliable objective UIQA metric. To address this issue, we establish a large-scale underwater image dataset, dubbed UID2021, for evaluating no-reference UIQA metrics. The constructed dataset contains 60 multiply degraded underwater images collected from various sources, covering six common underwater scenes (i.e. bluish scene, bluish-green scene, greenish scene, hazy scene, low-light scene, and turbid scene), and their corresponding 900 quality improved versions generated by employing fifteen state-of-the-art underwater image enhancement and restoration algorithms. Mean opinion scores (MOS) for UID2021 are also obtained by using the pair comparison sorting method with 52 observers. Both in-air NR-IQA and underwater-specific algorithms are tested on our constructed dataset to fairly compare the performance and analyze their strengths and weaknesses. Our proposed UID2021 dataset enables ones to evaluate NR UIQA algorithms comprehensively and paves the way for further research on UIQA. Our UID2021 will be a free download and utilized for research purposes at: https://github.com/Hou-Guojia/UID2021.
Tensor-to-Image: Image-to-Image Translation with Vision Transformers
Oct 06, 2021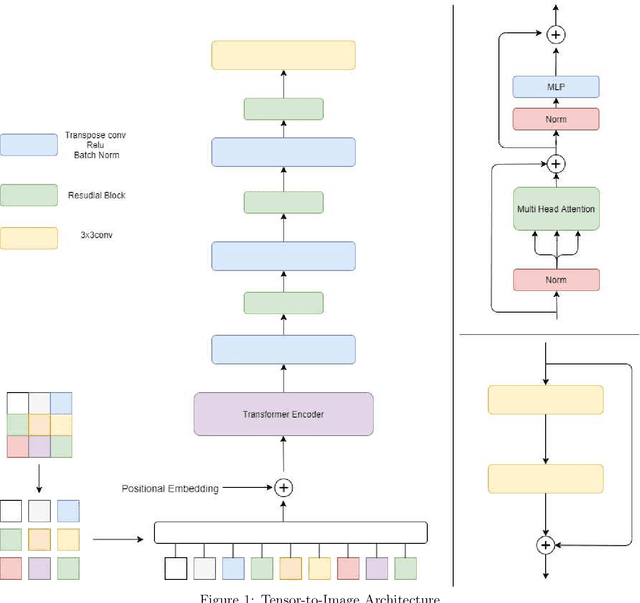


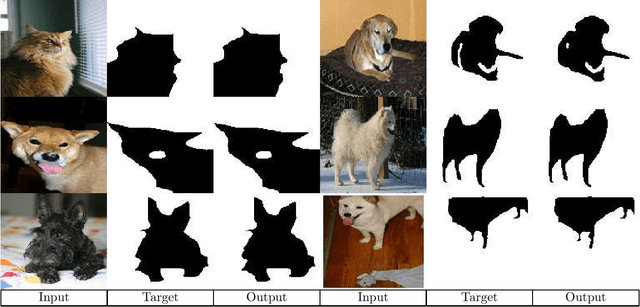
Transformers gain huge attention since they are first introduced and have a wide range of applications. Transformers start to take over all areas of deep learning and the Vision transformers paper also proved that they can be used for computer vision tasks. In this paper, we utilized a vision transformer-based custom-designed model, tensor-to-image, for the image to image translation. With the help of self-attention, our model was able to generalize and apply to different problems without a single modification.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022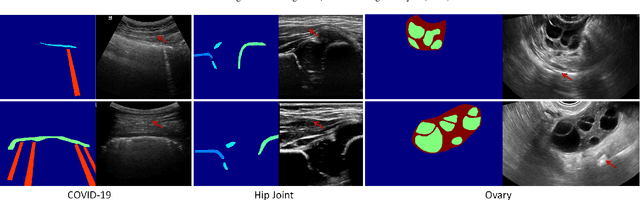
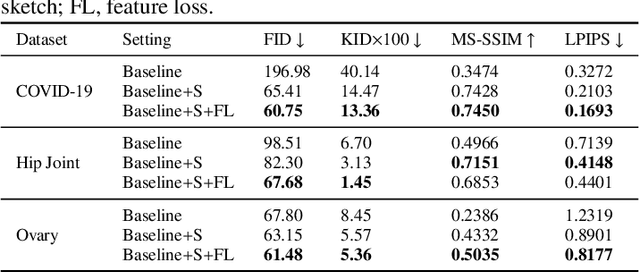
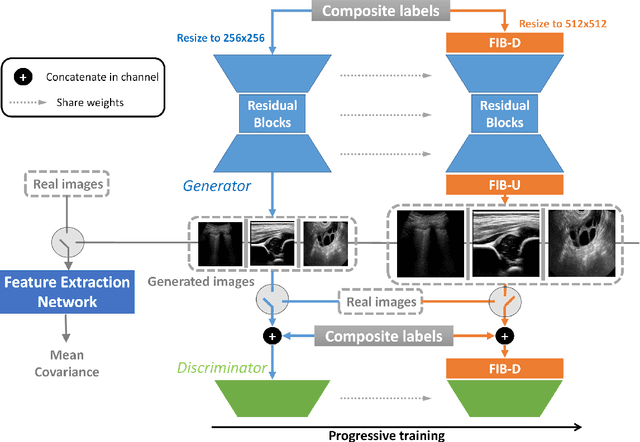

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.
Design and Mathematical Modelling of Inter Spike Interval of Temporal Neuromorphic Encoder for Image Recognition
May 19, 2022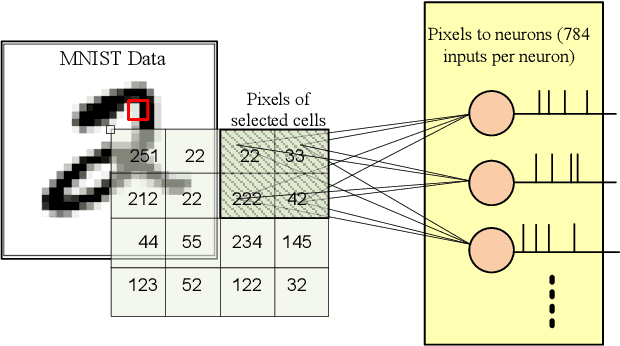
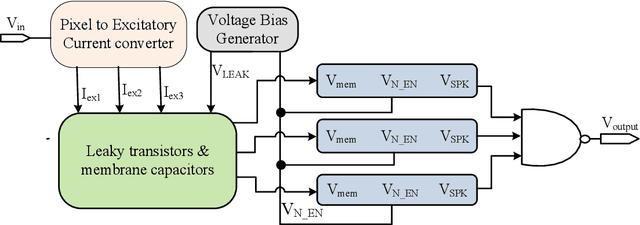
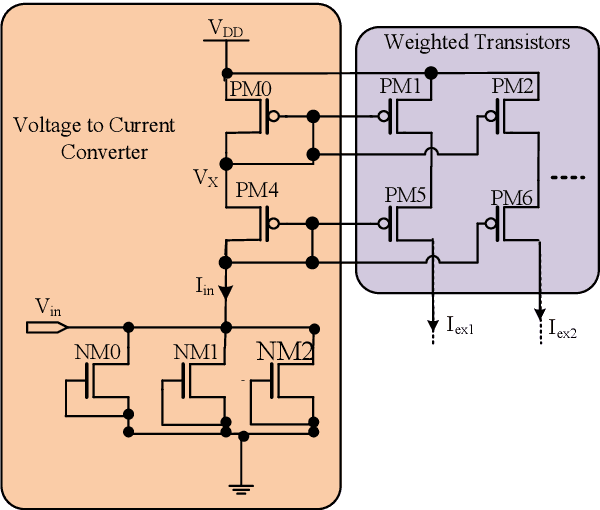
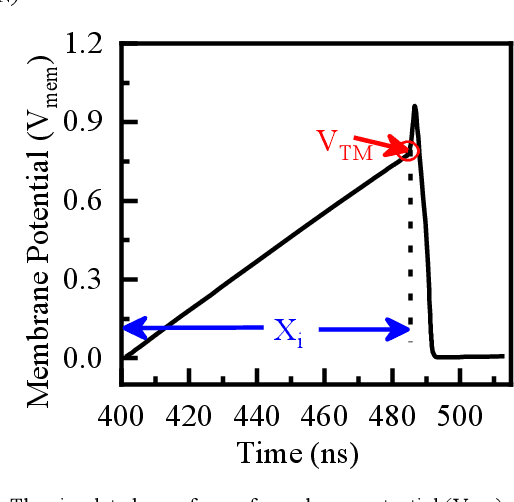
Neuromorphic computing systems emulate the electrophysiological behavior of the biological nervous system using mixed-mode analog or digital VLSI circuits. These systems show superior accuracy and power efficiency in carrying out cognitive tasks. The neural network architecture used in neuromorphic computing systems is spiking neural networks (SNNs) analogous to the biological nervous system. SNN operates on spike trains as a function of time. A neuromorphic encoder converts sensory data into spike trains. In this paper, a low-power neuromorphic encoder for image processing is implemented. A mathematical model between pixels of an image and the inter-spike intervals is also formulated. Wherein an exponential relationship between pixels and inter-spike intervals is obtained. Finally, the mathematical equation is validated with circuit simulation.
Robust real-time imaging through flexible multimode fibers
Oct 25, 2022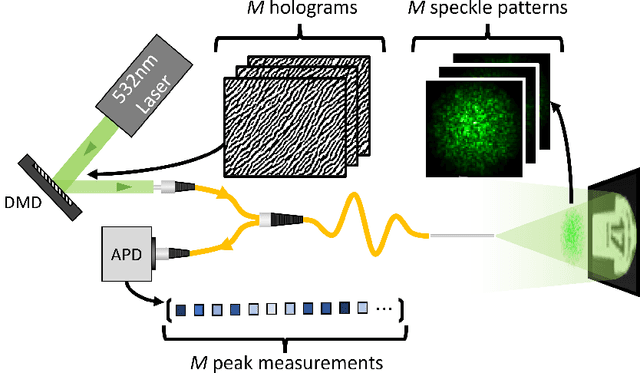
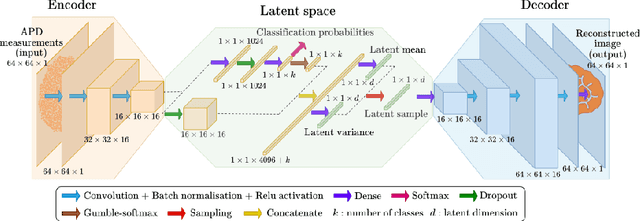
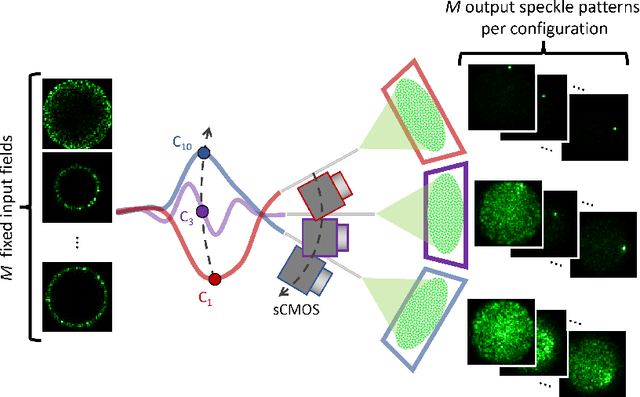
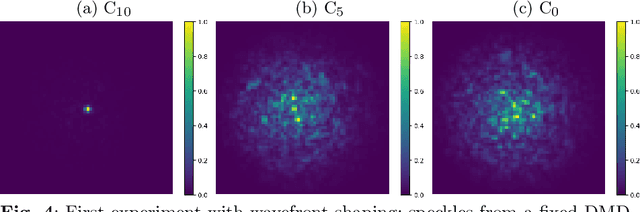
Conventional endoscopes comprise a bundle of optical fibers, associating one fiber for each pixel in the image. In principle, this can be reduced to a single multimode optical fiber (MMF), the width of a human hair, with one fiber spatial-mode per image pixel. However, images transmitted through a MMF emerge as unrecognisable speckle patterns due to dispersion and coupling between the spatial modes of the fiber. Furthermore, speckle patterns change as the fiber undergoes bending, making the use of MMFs in flexible imaging applications even more complicated. In this paper, we propose a real-time imaging system using flexible MMFs, but which is robust to bending. Our approach does not require access or feedback signal from the distal end of the fiber during imaging. We leverage a variational autoencoder (VAE) to reconstruct and classify images from the speckles and show that these images can still be recovered when the bend configuration of the fiber is changed to one that was not part of the training set. We utilize a MMF $300$ mm long with a 50 $\mu$m core for imaging $10\times 10$ cm objects placed approximately at $20$ cm from the fiber and the system can deal with a change in fiber bend of 50$^\circ$ and range of movement of 8 cm.
On-the-fly Object Detection using StyleGAN with CLIP Guidance
Oct 30, 2022
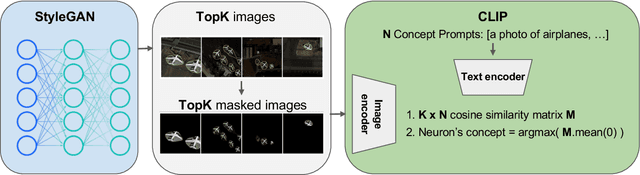

We present a fully automated framework for building object detectors on satellite imagery without requiring any human annotation or intervention. We achieve this by leveraging the combined power of modern generative models (e.g., StyleGAN) and recent advances in multi-modal learning (e.g., CLIP). While deep generative models effectively encode the key semantics pertinent to a data distribution, this information is not immediately accessible for downstream tasks, such as object detection. In this work, we exploit CLIP's ability to associate image features with text descriptions to identify neurons in the generator network, which are subsequently used to build detectors on-the-fly.
See as a Bee: UV Sensor for Aerial Strawberry Crop Monitoring
Oct 30, 2022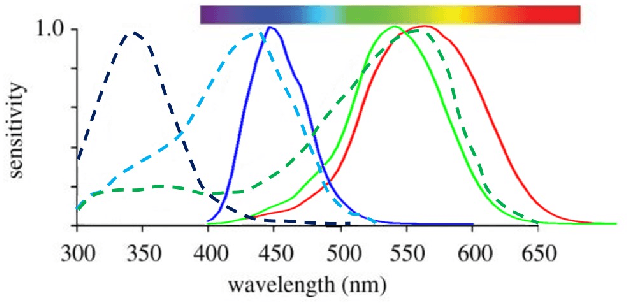
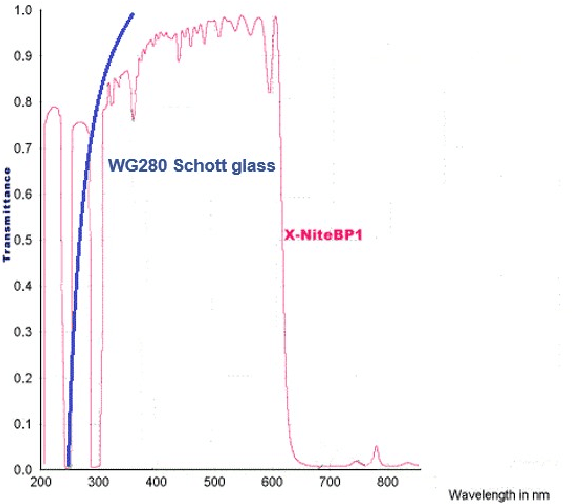
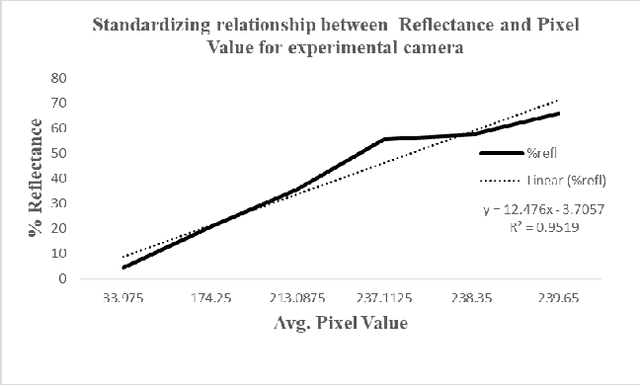
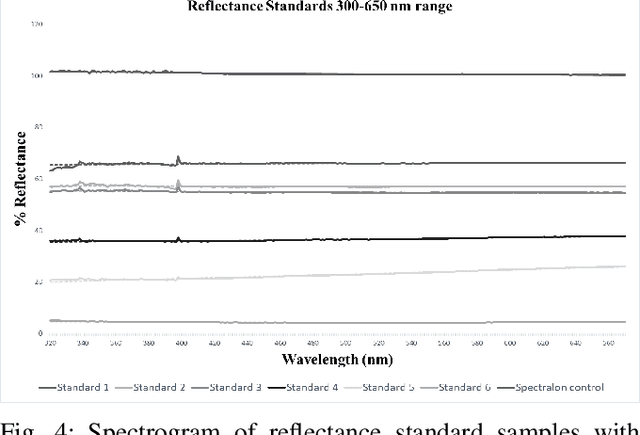
Precision agriculture aims to use technological tools for the agro-food sector to increase productivity, cut labor costs, and reduce the use of resources. This work takes inspiration from bees vision to design a remote sensing system tailored to incorporate UV-reflectance into a flower detector. We demonstrate how this approach can provide feature-rich images for deep learning strawberry flower detection and we apply it to a scalable, yet cost effective aerial monitoring robotic system in the field. We also compare the performance of our UV-G-B image detector with a similar work that utilizes RGB images.
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022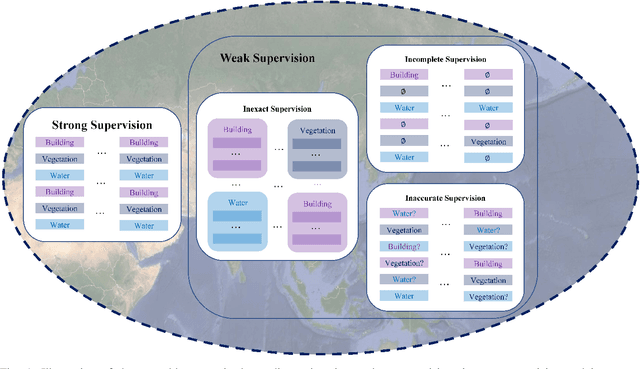
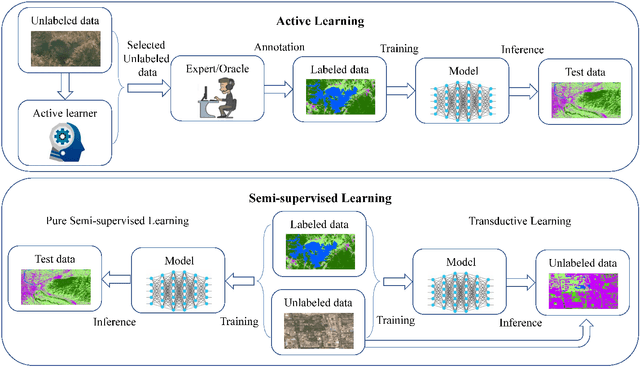
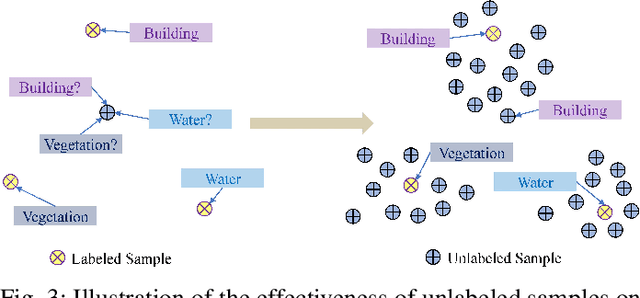

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.