 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kernel Attention Transformer (KAT) for Histopathology Whole Slide Image Classification
Jun 27, 2022
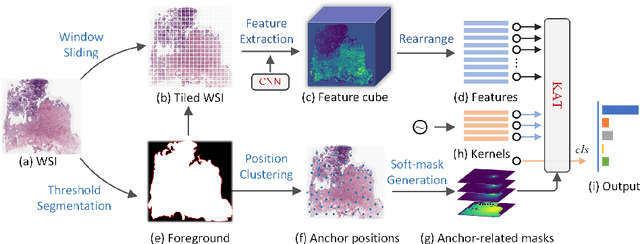
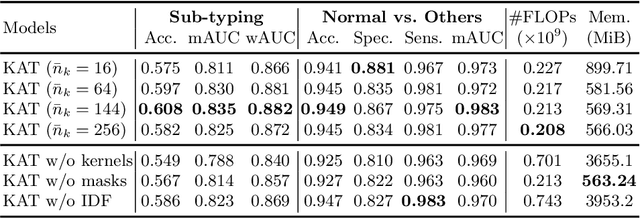
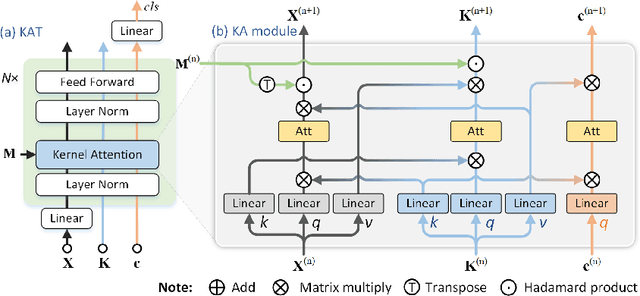
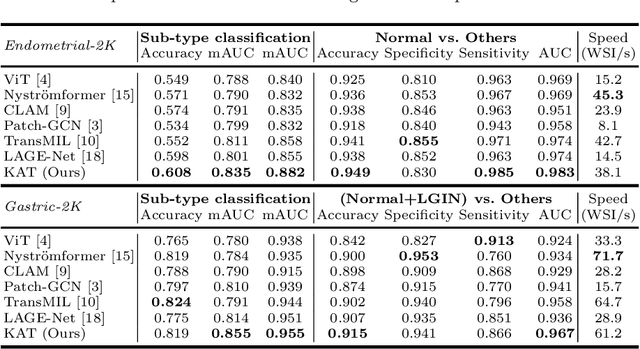
Transformer has been widely used in histopathology whole slide image (WSI) classification for the purpose of tumor grading, prognosis analysis, etc. However, the design of token-wise self-attention and positional embedding strategy in the common Transformer limits the effectiveness and efficiency in the application to gigapixel histopathology images. In this paper, we propose a kernel attention Transformer (KAT) for histopathology WSI classification. The information transmission of the tokens is achieved by cross-attention between the tokens and a set of kernels related to a set of positional anchors on the WSI. Compared to the common Transformer structure, the proposed KAT can better describe the hierarchical context information of the local regions of the WSI and meanwhile maintains a lower computational complexity. The proposed method was evaluated on a gastric dataset with 2040 WSIs and an endometrial dataset with 2560 WSIs, and was compared with 6 state-of-the-art methods. The experimental results have demonstrated the proposed KAT is effective and efficient in the task of histopathology WSI classification and is superior to the state-of-the-art methods. The code is available at https://github.com/zhengyushan/kat.
A Masked Image Reconstruction Network for Document-level Relation Extraction
Apr 21, 2022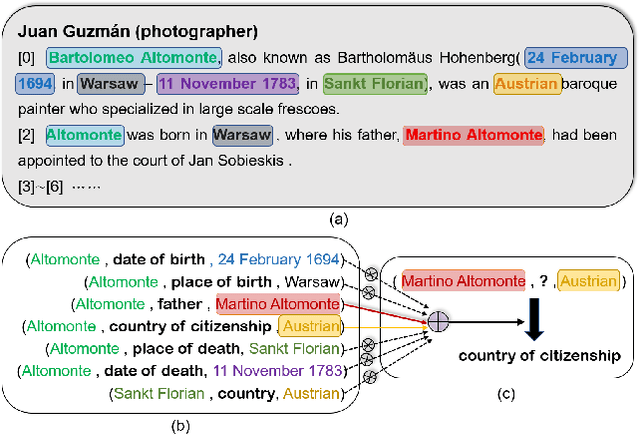
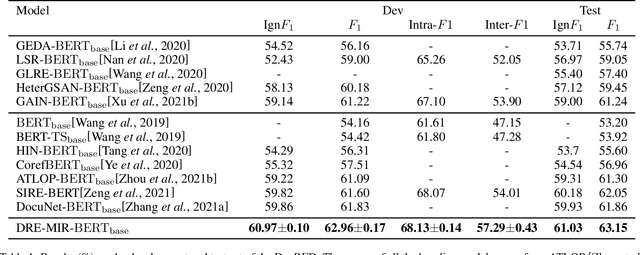
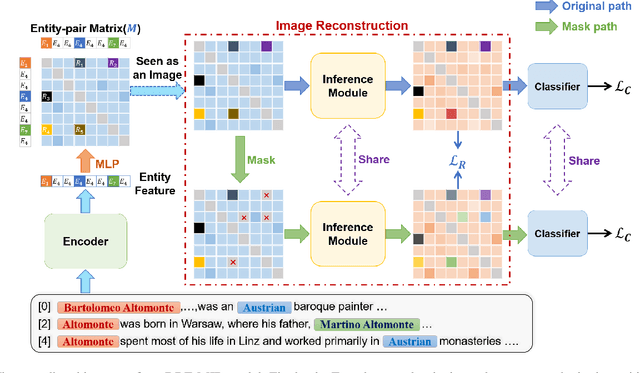
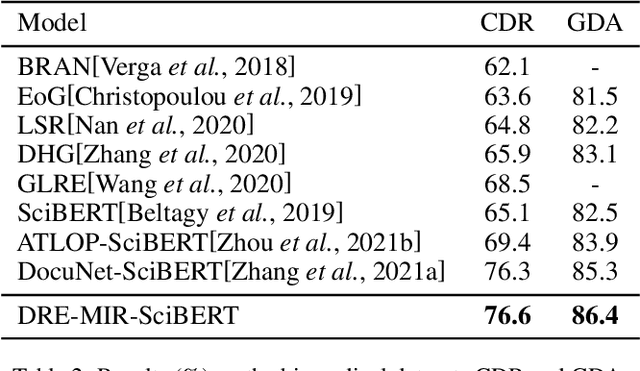
Document-level relation extraction aims to extract relations among entities within a document. Compared with its sentence-level counterpart, Document-level relation extraction requires inference over multiple sentences to extract complex relational triples. Previous research normally complete reasoning through information propagation on the mention-level or entity-level document-graphs, regardless of the correlations between the relationships. In this paper, we propose a novel Document-level Relation Extraction model based on a Masked Image Reconstruction network (DRE-MIR), which models inference as a masked image reconstruction problem to capture the correlations between relationships. Specifically, we first leverage an encoder module to get the features of entities and construct the entity-pair matrix based on the features. After that, we look on the entity-pair matrix as an image and then randomly mask it and restore it through an inference module to capture the correlations between the relationships. We evaluate our model on three public document-level relation extraction datasets, i.e. DocRED, CDR, and GDA. Experimental results demonstrate that our model achieves state-of-the-art performance on these three datasets and has excellent robustness against the noises during the inference process.
SUNet: Swin Transformer UNet for Image Denoising
Feb 28, 2022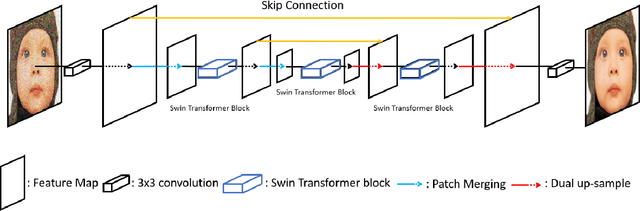
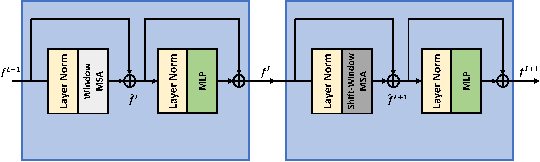
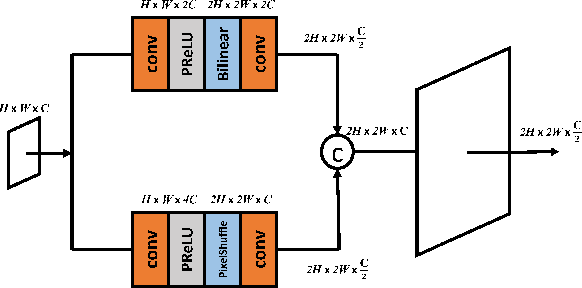

Image restoration is a challenging ill-posed problem which also has been a long-standing issue. In the past few years, the convolution neural networks (CNNs) almost dominated the computer vision and had achieved considerable success in different levels of vision tasks including image restoration. However, recently the Swin Transformer-based model also shows impressive performance, even surpasses the CNN-based methods to become the state-of-the-art on high-level vision tasks. In this paper, we proposed a restoration model called SUNet which uses the Swin Transformer layer as our basic block and then is applied to UNet architecture for image denoising. The source code and pre-trained models are available at https://github.com/FanChiMao/SUNet.
Single Slice Thigh CT Muscle Group Segmentation with Domain Adaptation and Self-Training
Nov 30, 2022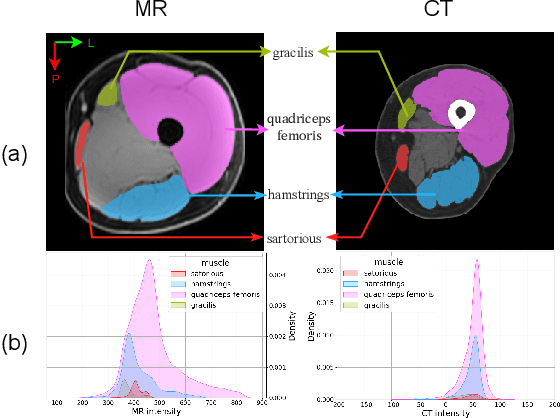
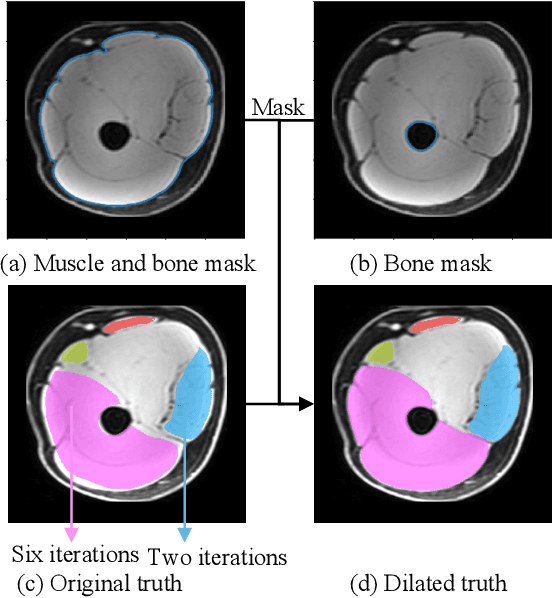
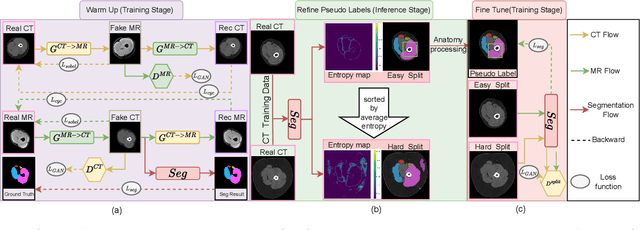
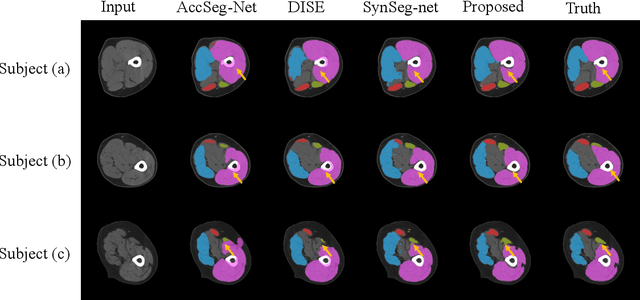
Objective: Thigh muscle group segmentation is important for assessment of muscle anatomy, metabolic disease and aging. Many efforts have been put into quantifying muscle tissues with magnetic resonance (MR) imaging including manual annotation of individual muscles. However, leveraging publicly available annotations in MR images to achieve muscle group segmentation on single slice computed tomography (CT) thigh images is challenging. Method: We propose an unsupervised domain adaptation pipeline with self-training to transfer labels from 3D MR to single CT slice. First, we transform the image appearance from MR to CT with CycleGAN and feed the synthesized CT images to a segmenter simultaneously. Single CT slices are divided into hard and easy cohorts based on the entropy of pseudo labels inferenced by the segmenter. After refining easy cohort pseudo labels based on anatomical assumption, self-training with easy and hard splits is applied to fine tune the segmenter. Results: On 152 withheld single CT thigh images, the proposed pipeline achieved a mean Dice of 0.888(0.041) across all muscle groups including sartorius, hamstrings, quadriceps femoris and gracilis. muscles Conclusion: To our best knowledge, this is the first pipeline to achieve thigh imaging domain adaptation from MR to CT. The proposed pipeline is effective and robust in extracting muscle groups on 2D single slice CT thigh images.The container is available for public use at https://github.com/MASILab/DA_CT_muscle_seg
Learning Audio-Video Modalities from Image Captions
Apr 01, 2022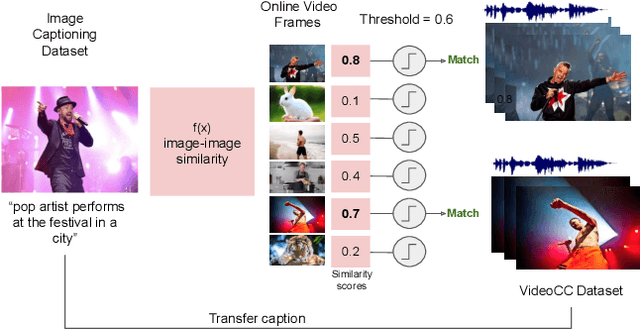
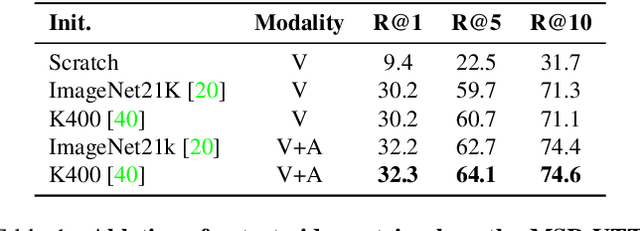

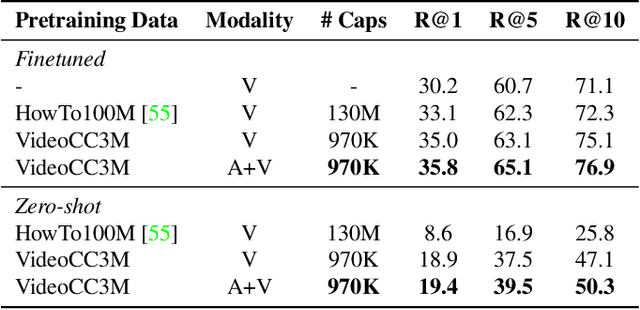
A major challenge in text-video and text-audio retrieval is the lack of large-scale training data. This is unlike image-captioning, where datasets are in the order of millions of samples. To close this gap we propose a new video mining pipeline which involves transferring captions from image captioning datasets to video clips with no additional manual effort. Using this pipeline, we create a new large-scale, weakly labelled audio-video captioning dataset consisting of millions of paired clips and captions. We show that training a multimodal transformed based model on this data achieves competitive performance on video retrieval and video captioning, matching or even outperforming HowTo100M pretraining with 20x fewer clips. We also show that our mined clips are suitable for text-audio pretraining, and achieve state of the art results for the task of audio retrieval.
Robustness of Humans and Machines on Object Recognition with Extreme Image Transformations
May 09, 2022
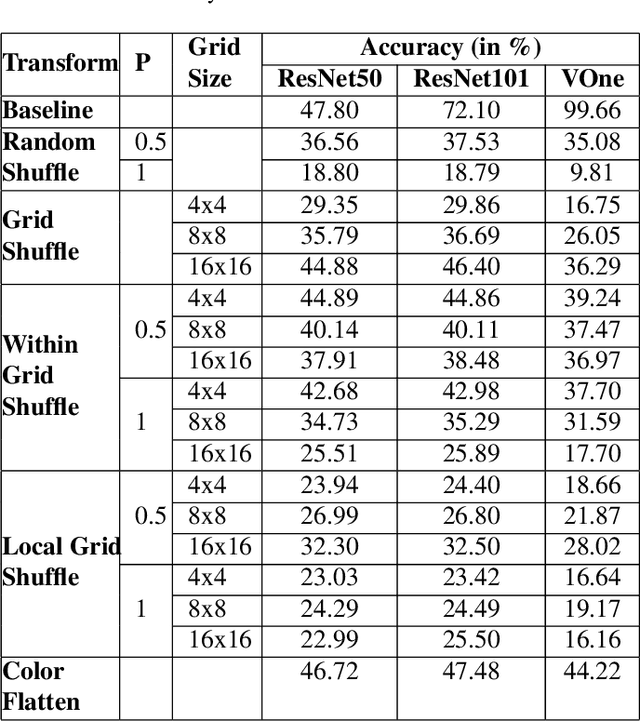
Recent neural network architectures have claimed to explain data from the human visual cortex. Their demonstrated performance is however still limited by the dependence on exploiting low-level features for solving visual tasks. This strategy limits their performance in case of out-of-distribution/adversarial data. Humans, meanwhile learn abstract concepts and are mostly unaffected by even extreme image distortions. Humans and networks employ strikingly different strategies to solve visual tasks. To probe this, we introduce a novel set of image transforms and evaluate humans and networks on an object recognition task. We found performance for a few common networks quickly decreases while humans are able to recognize objects with a high accuracy.
Learning Nonlocal Sparse and Low-Rank Models for Image Compressive Sensing
Mar 22, 2022
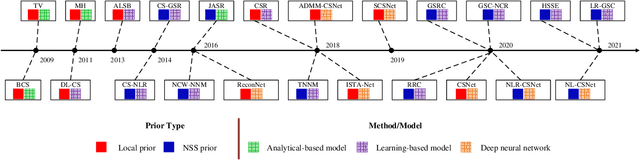

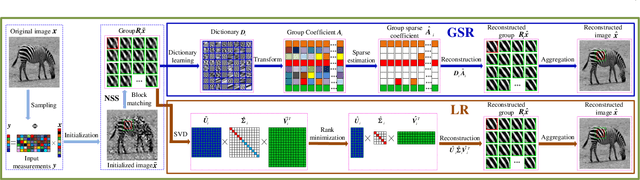
The compressive sensing (CS) scheme exploits much fewer measurements than suggested by the Nyquist-Shannon sampling theorem to accurately reconstruct images, which has attracted considerable attention in the computational imaging community. While classic image CS schemes employed sparsity using analytical transforms or bases, the learning-based approaches have become increasingly popular in recent years. Such methods can effectively model the structures of image patches by optimizing their sparse representations or learning deep neural networks, while preserving the known or modeled sensing process. Beyond exploiting local image properties, advanced CS schemes adopt nonlocal image modeling, by extracting similar or highly correlated patches at different locations of an image to form a group to process jointly. More recent learning-based CS schemes apply nonlocal structured sparsity prior using group sparse representation (GSR) and/or low-rank (LR) modeling, which have demonstrated promising performance in various computational imaging and image processing applications. This article reviews some recent works in image CS tasks with a focus on the advanced GSR and LR based methods. Furthermore, we present a unified framework for incorporating various GSR and LR models and discuss the relationship between GSR and LR models. Finally, we discuss the open problems and future directions in the field.
Improving Human Image Synthesis with Residual Fast Fourier Transformation and Wasserstein Distance
May 26, 2022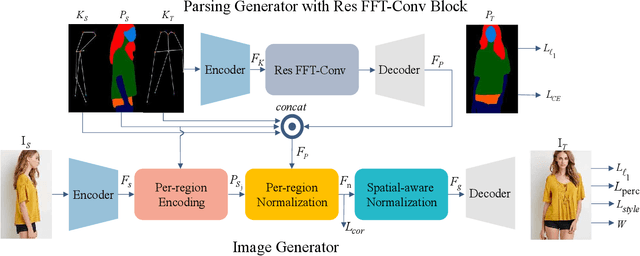
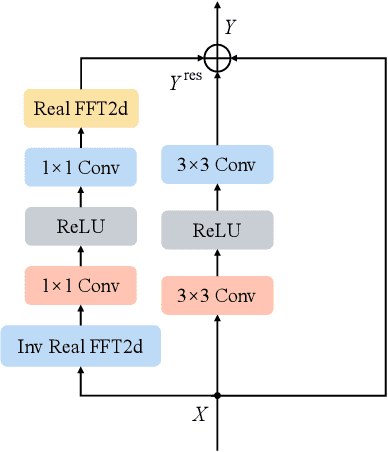
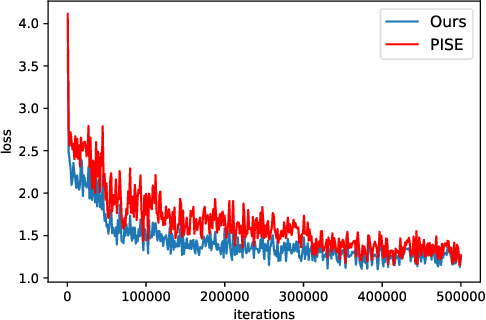
With the rapid development of the Metaverse, virtual humans have emerged, and human image synthesis and editing techniques, such as pose transfer, have recently become popular. Most of the existing techniques rely on GANs, which can generate good human images even with large variants and occlusions. But from our best knowledge, the existing state-of-the-art method still has the following problems: the first is that the rendering effect of the synthetic image is not realistic, such as poor rendering of some regions. And the second is that the training of GAN is unstable and slow to converge, such as model collapse. Based on the above two problems, we propose several methods to solve them. To improve the rendering effect, we use the Residual Fast Fourier Transform Block to replace the traditional Residual Block. Then, spectral normalization and Wasserstein distance are used to improve the speed and stability of GAN training. Experiments demonstrate that the methods we offer are effective at solving the problems listed above, and we get state-of-the-art scores in LPIPS and PSNR.
Giga-SSL: Self-Supervised Learning for Gigapixel Images
Dec 06, 2022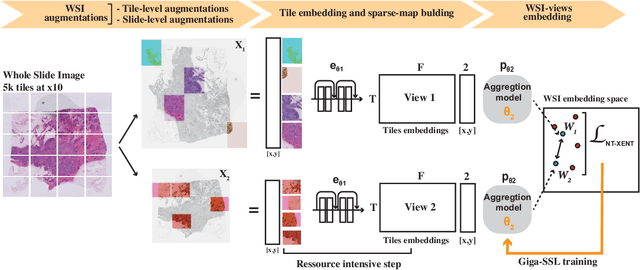
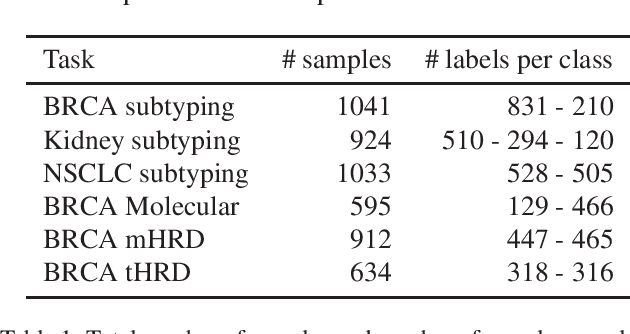
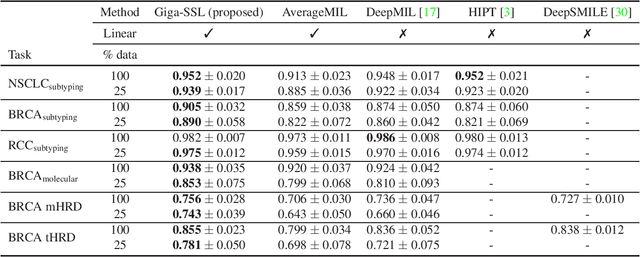
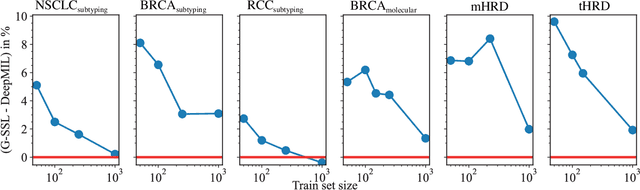
Whole slide images (WSI) are microscopy images of stained tissue slides routinely prepared for diagnosis and treatment selection in medical practice. WSI are very large (gigapixel size) and complex (made of up to millions of cells). The current state-of-the-art (SoTA) approach to classify WSI subdivides them into tiles, encodes them by pre-trained networks and applies Multiple Instance Learning (MIL) to train for specific downstream tasks. However, annotated datasets are often small, typically a few hundred to a few thousand WSI, which may cause overfitting and underperforming models. Conversely, the number of unannotated WSI is ever increasing, with datasets of tens of thousands (soon to be millions) of images available. While it has been previously proposed to use these unannotated data to identify suitable tile representations by self-supervised learning (SSL), downstream classification tasks still require full supervision because parts of the MIL architecture is not trained during tile level SSL pre-training. Here, we propose a strategy of slide level SSL to leverage the large number of WSI without annotations to infer powerful slide representations. Applying our method to The Cancer-Genome Atlas, one of the most widely used data resources in cancer research (16 TB image data), we are able to downsize the dataset to 23 MB without any loss in predictive power: we show that a linear classifier trained on top of these embeddings maintains or improves previous SoTA performances on various benchmark WSI classification tasks. Finally, we observe that training a classifier on these representations with tiny datasets (e.g. 50 slides) improved performances over SoTA by an average of +6.3 AUC points over all downstream tasks.
Patcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
Jun 03, 2022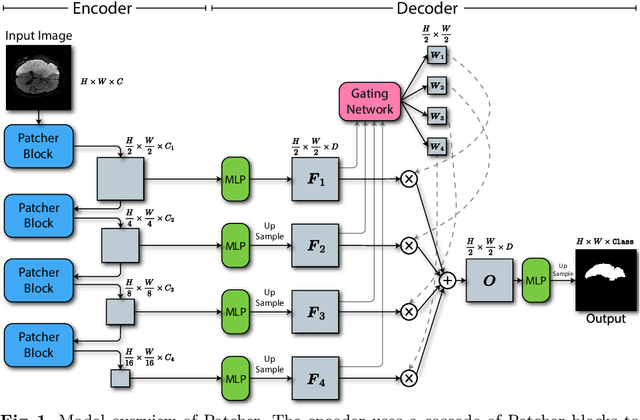
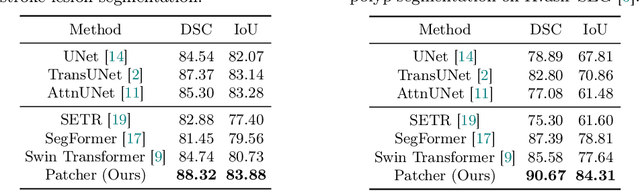


We present a new encoder-decoder Vision Transformer architecture, Patcher, for medical image segmentation. Unlike standard Vision Transformers, it employs Patcher blocks that segment an image into large patches, each of which is further divided into small patches. Transformers are applied to the small patches within a large patch, which constrains the receptive field of each pixel. We intentionally make the large patches overlap to enhance intra-patch communication. The encoder employs a cascade of Patcher blocks with increasing receptive fields to extract features from local to global levels. This design allows Patcher to benefit from both the coarse-to-fine feature extraction common in CNNs and the superior spatial relationship modeling of Transformers. We also propose a new mixture-of-experts (MoE) based decoder, which treats the feature maps from the encoder as experts and selects a suitable set of expert features to predict the label for each pixel. The use of MoE enables better specializations of the expert features and reduces interference between them during inference. Extensive experiments demonstrate that Patcher outperforms state-of-the-art Transformer- and CNN-based approaches significantly on stroke lesion segmentation and polyp segmentation. Code for Patcher will be released with publication to facilitate future research.