 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Image Inpainting by Stripe Window Transformer with Joint Attention to CNN
Jan 02, 2023Image inpainting is an important task in computer vision. As admirable methods are presented, the inpainted image is getting closer to reality. However, the result is still not good enough in the reconstructed texture and structure based on human vision. Although more and more larger models have been proposed recently because of the advancement of computer hardware, we would like to build a suitable model for personal use or small-sized institution. Therefore, we propose a lightweight model that combines the special transformer and the traditional convolutional neural network (CNN). Furthermore, we noticed most researchers only consider three primary colors (RGB) in inpainted images, but we think this is not enough so we propose a new loss function to intensify color details. Extensive experiments on commonly seen datasets (Places2 and CelebA) validate the efficacy of our proposed model compared with other state-of-the-art methods. Index Terms - HSV color space, image inpainting, joint attention mechanism, stripe window, vision transformer
Compound Multi-branch Feature Fusion for Real Image Restoration
Jun 02, 2022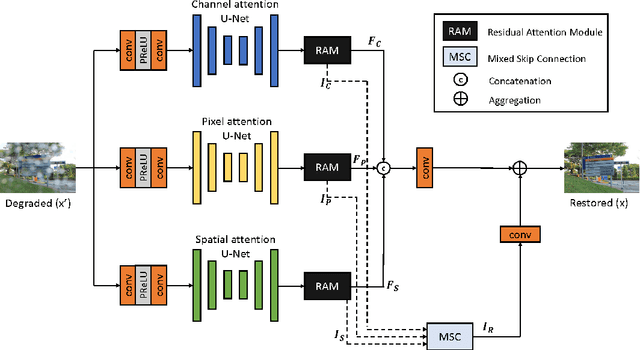
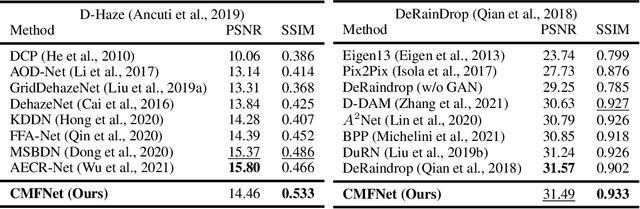
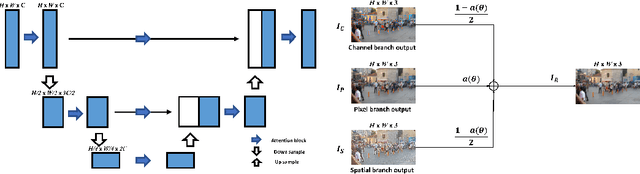
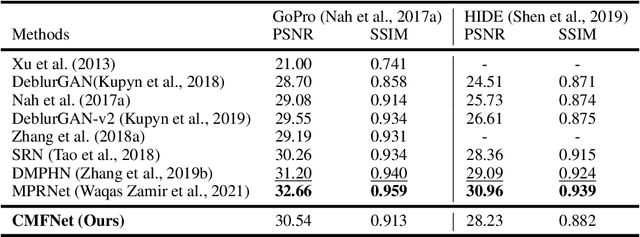
Image restoration is a challenging and ill-posed problem which also has been a long-standing issue. However, most of learning based restoration methods are proposed to target one degradation type which means they are lack of generalization. In this paper, we proposed a multi-branch restoration model inspired from the Human Visual System (i.e., Retinal Ganglion Cells) which can achieve multiple restoration tasks in a general framework. The experiments show that the proposed multi-branch architecture, called CMFNet, has competitive performance results on four datasets, including image dehazing, deraindrop, and deblurring, which are very common applications for autonomous cars. The source code and pretrained models of three restoration tasks are available at https://github.com/FanChiMao/CMFNet.
Selective Residual M-Net for Real Image Denoising
Mar 03, 2022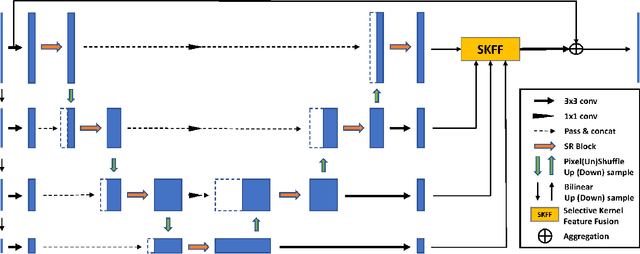
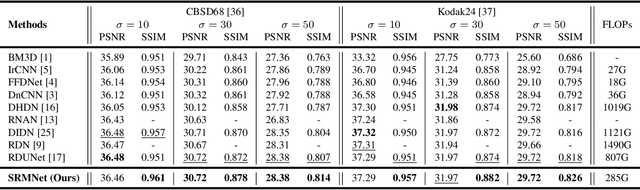
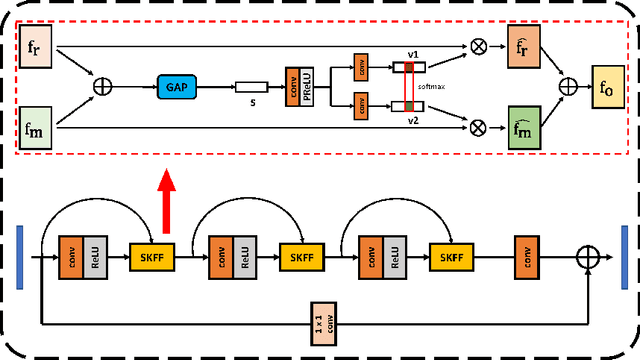
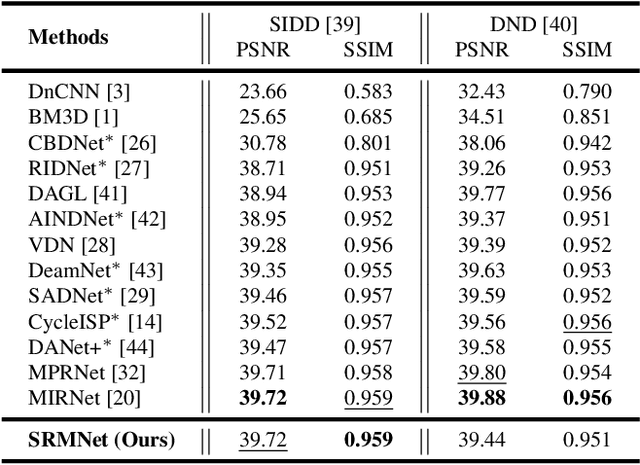
Image restoration is a low-level vision task which is to restore degraded images to noise-free images. With the success of deep neural networks, the convolutional neural networks surpass the traditional restoration methods and become the mainstream in the computer vision area. To advance the performanceof denoising algorithms, we propose a blind real image denoising network (SRMNet) by employing a hierarchical architecture improved from U-Net. Specifically, we use a selective kernel with residual block on the hierarchical structure called M-Net to enrich the multi-scale semantic information. Furthermore, our SRMNet has competitive performance results on two synthetic and two real-world noisy datasets in terms of quantitative metrics and visual quality. The source code and pretrained model are available at https://github.com/TentativeGitHub/SRMNet.
Half Wavelet Attention on M-Net+ for Low-Light Image Enhancement
Mar 02, 2022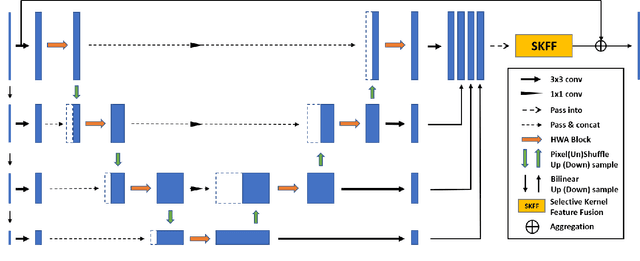
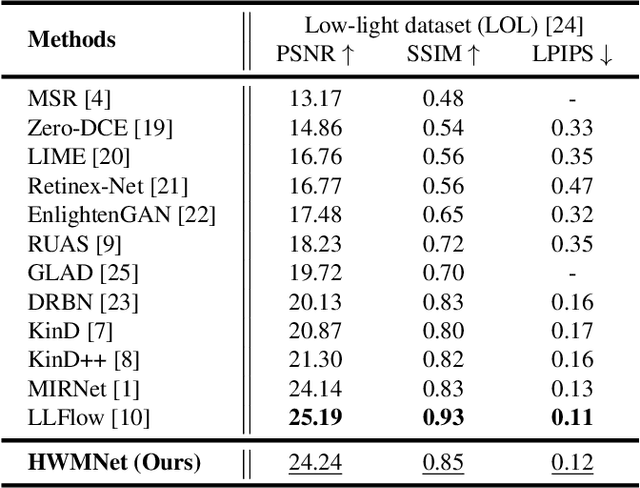
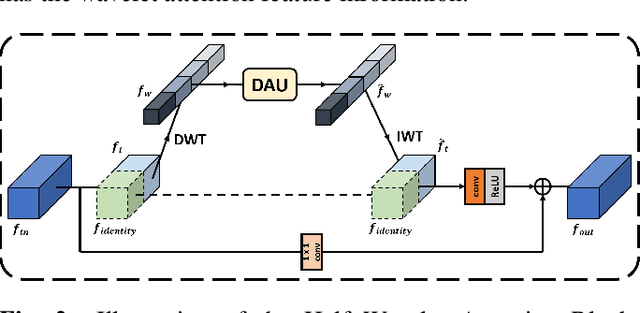

Low-Light Image Enhancement is a computer vision task which intensifies the dark images to appropriate brightness. It can also be seen as an ill-posed problem in image restoration domain. With the success of deep neural networks, the convolutional neural networks surpass the traditional algorithm-based methods and become the mainstream in the computer vision area. To advance the performance of enhancement algorithms, we propose an image enhancement network (HWMNet) based on an improved hierarchical model: M-Net+. Specifically, we use a half wavelet attention block on M-Net+ to enrich the features from wavelet domain. Furthermore, our HWMNet has competitive performance results on two image enhancement datasets in terms of quantitative metrics and visual quality. The source code and pretrained model are available at https://github.com/FanChiMao/HWMNet.
SUNet: Swin Transformer UNet for Image Denoising
Feb 28, 2022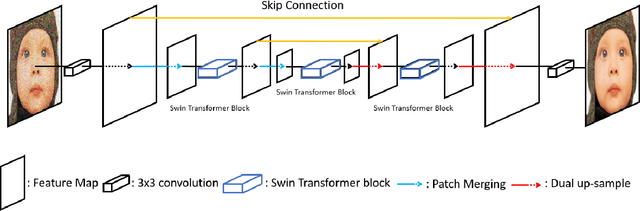
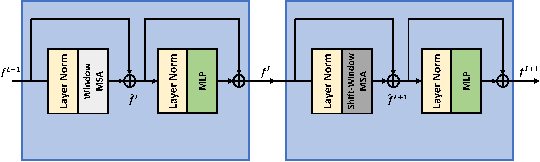
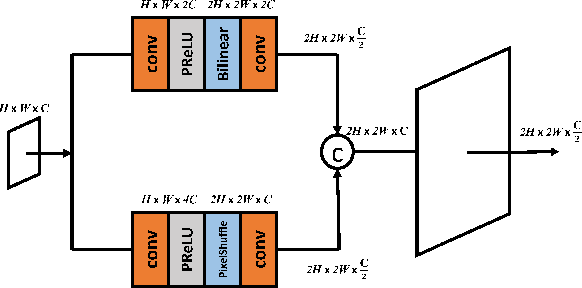

Image restoration is a challenging ill-posed problem which also has been a long-standing issue. In the past few years, the convolution neural networks (CNNs) almost dominated the computer vision and had achieved considerable success in different levels of vision tasks including image restoration. However, recently the Swin Transformer-based model also shows impressive performance, even surpasses the CNN-based methods to become the state-of-the-art on high-level vision tasks. In this paper, we proposed a restoration model called SUNet which uses the Swin Transformer layer as our basic block and then is applied to UNet architecture for image denoising. The source code and pre-trained models are available at https://github.com/FanChiMao/SUNet.