 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-fabrication Targeted Attack for Object Detection
Dec 14, 2022
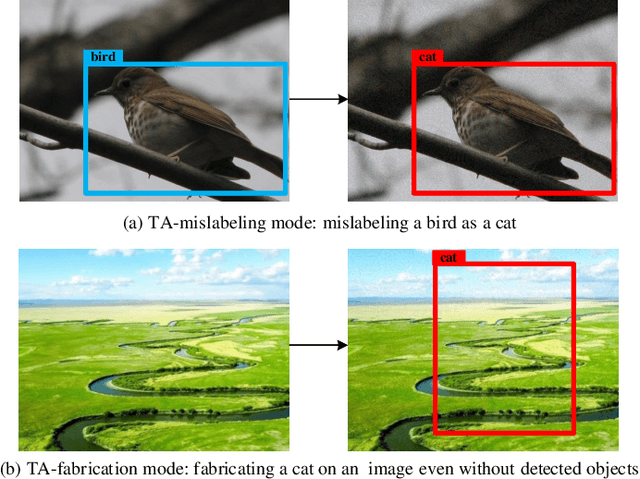
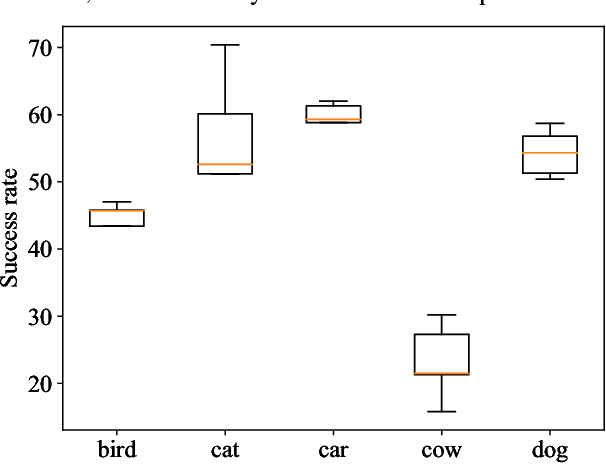
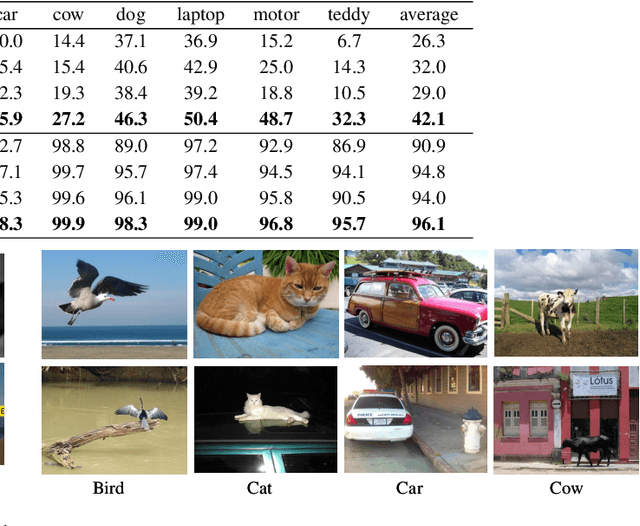
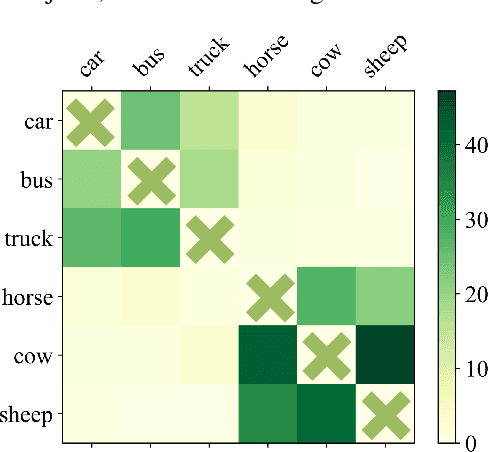
Recent researches show that the deep learning based object detection is vulnerable to adversarial examples. Generally, the adversarial attack for object detection contains targeted attack and untargeted attack. According to our detailed investigations, the research on the former is relatively fewer than the latter and all the existing methods for the targeted attack follow the same mode, i.e., the object-mislabeling mode that misleads detectors to mislabel the detected object as a specific wrong label. However, this mode has limited attack success rate, universal and generalization performances. In this paper, we propose a new object-fabrication targeted attack mode which can mislead detectors to `fabricate' extra false objects with specific target labels. Furthermore, we design a dual attention based targeted feature space attack method to implement the proposed targeted attack mode. The attack performances of the proposed mode and method are evaluated on MS COCO and BDD100K datasets using FasterRCNN and YOLOv5. Evaluation results demonstrate that, the proposed object-fabrication targeted attack mode and the corresponding targeted feature space attack method show significant improvements in terms of image-specific attack, universal performance and generalization capability, compared with the previous targeted attack for object detection. Code will be made available.
Attentive Fine-Grained Structured Sparsity for Image Restoration
Apr 26, 2022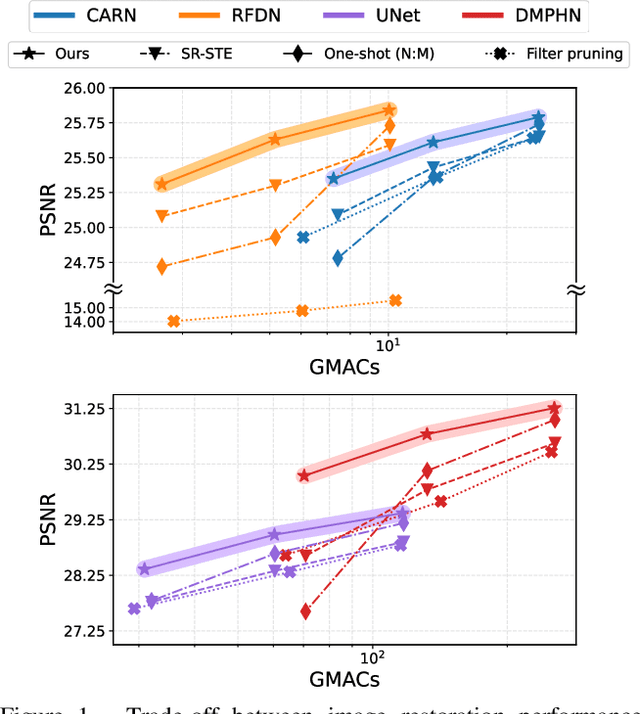
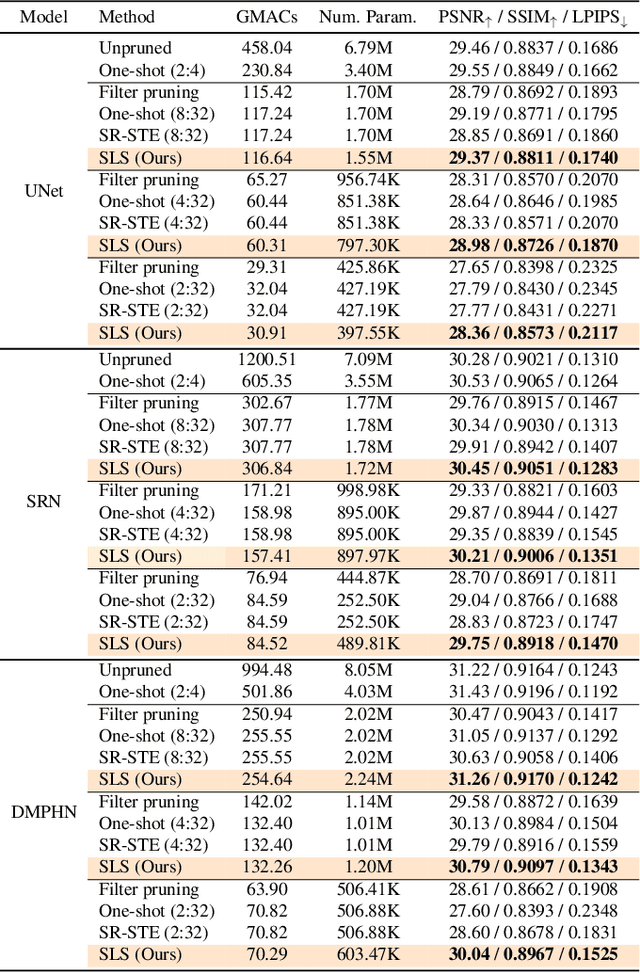
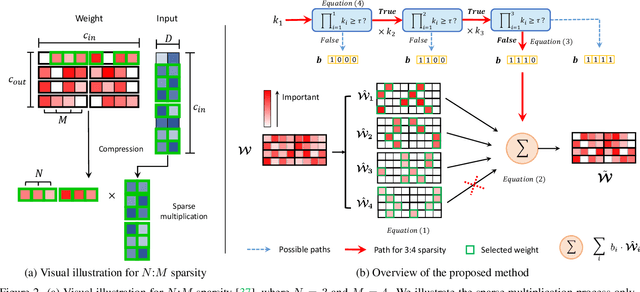
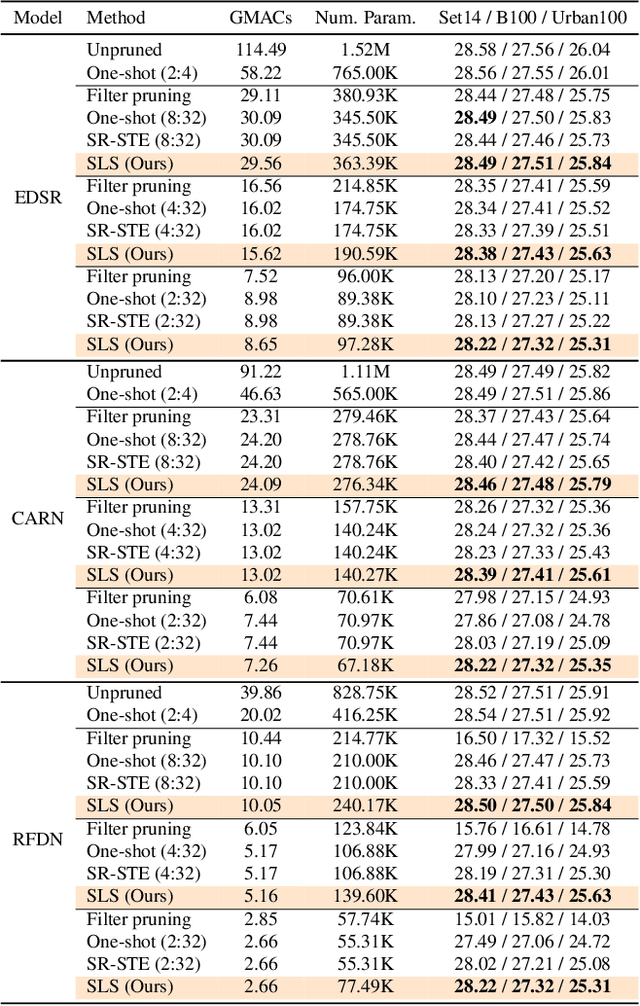
Image restoration tasks have witnessed great performance improvement in recent years by developing large deep models. Despite the outstanding performance, the heavy computation demanded by the deep models has restricted the application of image restoration. To lift the restriction, it is required to reduce the size of the networks while maintaining accuracy. Recently, N:M structured pruning has appeared as one of the effective and practical pruning approaches for making the model efficient with the accuracy constraint. However, it fails to account for different computational complexities and performance requirements for different layers of an image restoration network. To further optimize the trade-off between the efficiency and the restoration accuracy, we propose a novel pruning method that determines the pruning ratio for N:M structured sparsity at each layer. Extensive experimental results on super-resolution and deblurring tasks demonstrate the efficacy of our method which outperforms previous pruning methods significantly. PyTorch implementation for the proposed methods will be publicly available at https://github.com/JungHunOh/SLS_CVPR2022.
MIMO-DBnet: Multi-channel Input and Multiple Outputs DOA-aware Beamforming Network for Speech Separation
Dec 07, 2022
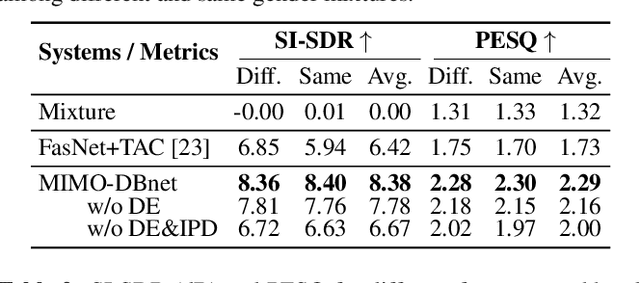
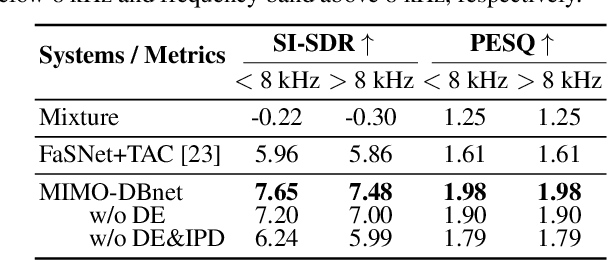
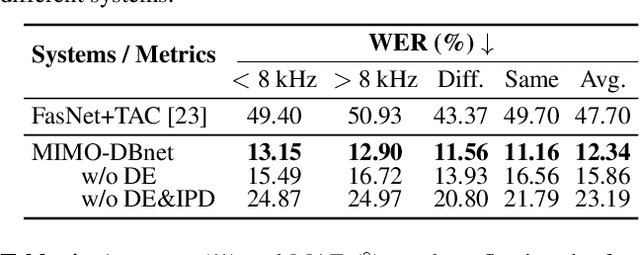
Recently, many deep learning based beamformers have been proposed for multi-channel speech separation. Nevertheless, most of them rely on extra cues known in advance, such as speaker feature, face image or directional information. In this paper, we propose an end-to-end beamforming network for direction guided speech separation given merely the mixture signal, namely MIMO-DBnet. Specifically, we design a multi-channel input and multiple outputs architecture to predict the direction-of-arrival based embeddings and beamforming weights for each source. The precisely estimated directional embedding provides quite effective spatial discrimination guidance for the neural beamformer to offset the effect of phase wrapping, thus allowing more accurate reconstruction of two sources' speech signals. Experiments show that our proposed MIMO-DBnet not only achieves a comprehensive decent improvement compared to baseline systems, but also maintain the performance on high frequency bands when phase wrapping occurs.
GAMMA: Generative Augmentation for Attentive Marine Debris Detection
Dec 07, 2022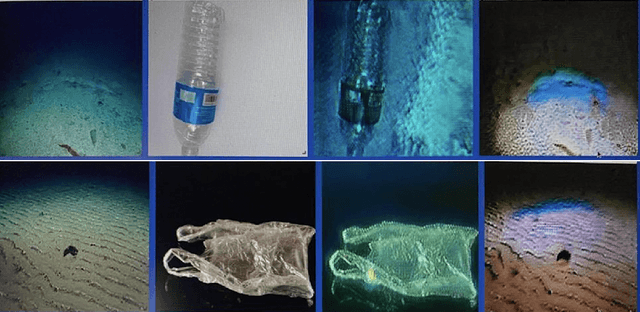
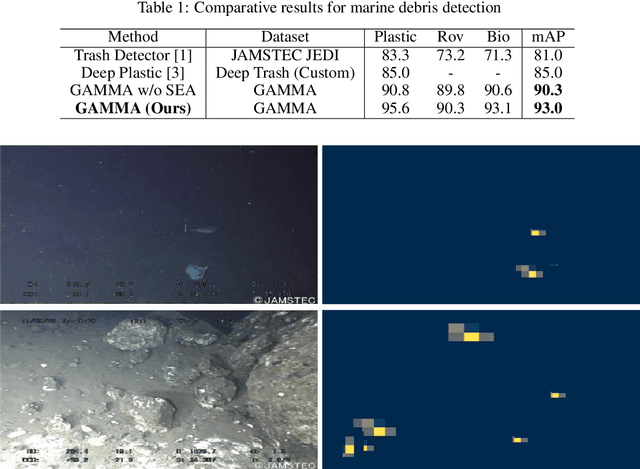
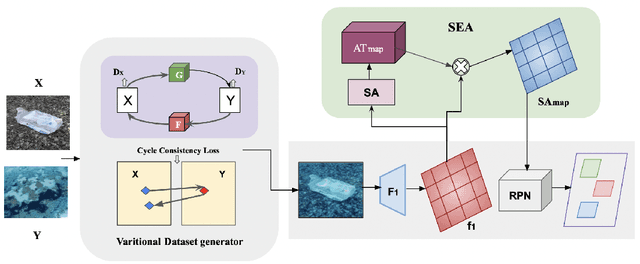

We propose an efficient and generative augmentation approach to solve the inadequacy concern of underwater debris data for visual detection. We use cycleGAN as a data augmentation technique to convert openly available, abundant data of terrestrial plastic to underwater-style images. Prior works just focus on augmenting or enhancing existing data, which moreover adds bias to the dataset. Compared to our technique, which devises variation, transforming additional in-air plastic data to the marine background. We also propose a novel architecture for underwater debris detection using an attention mechanism. Our method helps to focus only on relevant instances of the image, thereby enhancing the detector performance, which is highly obliged while detecting the marine debris using Autonomous Underwater Vehicle (AUV). We perform extensive experiments for marine debris detection using our approach. Quantitative and qualitative results demonstrate the potential of our framework that significantly outperforms the state-of-the-art methods.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Nov 26, 2022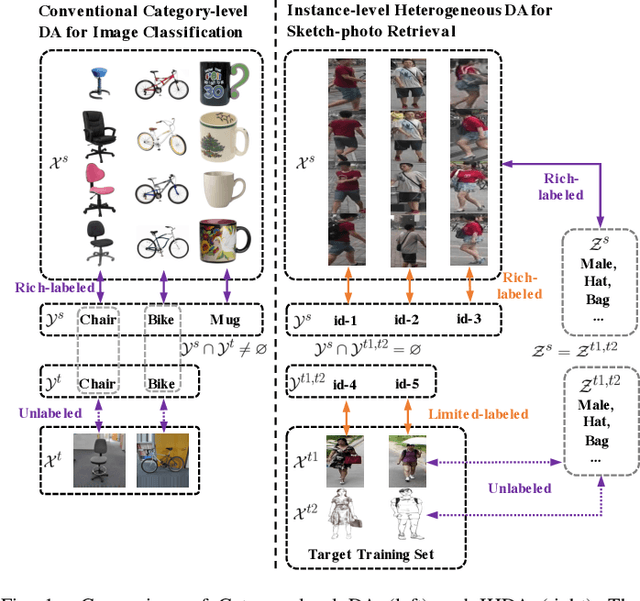
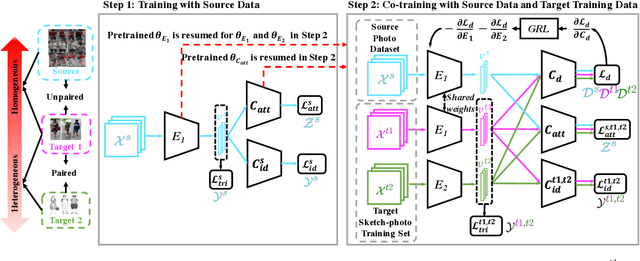

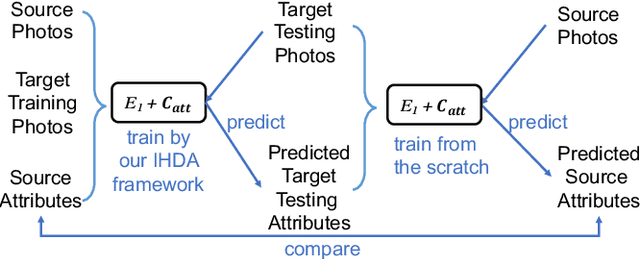
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at \url{https://github.com/fandulu/IHDA.
QFF: Quantized Fourier Features for Neural Field Representations
Dec 02, 2022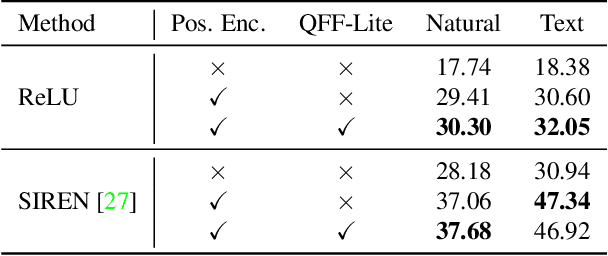
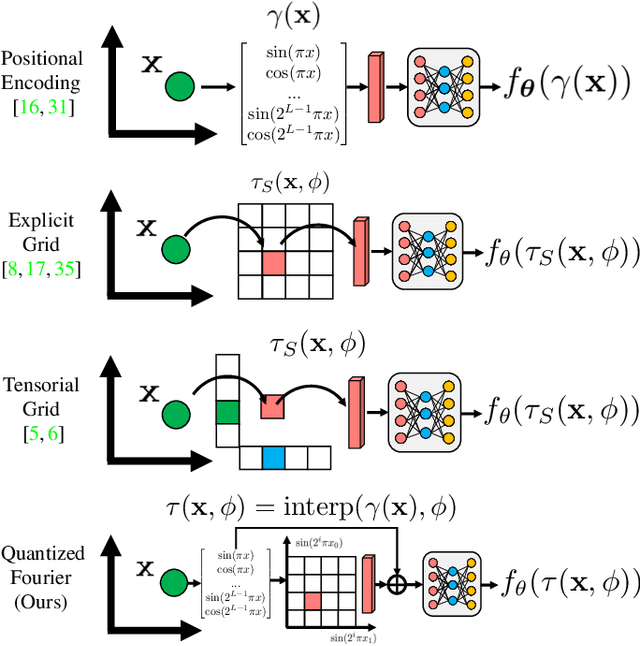
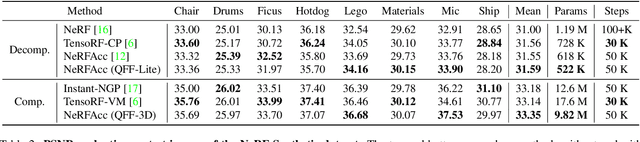
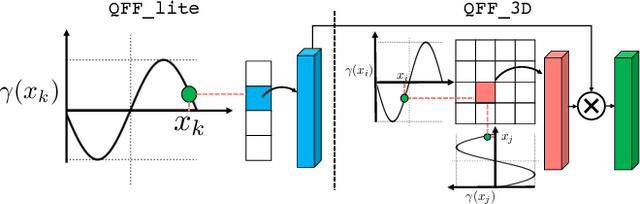
Multilayer perceptrons (MLPs) learn high frequencies slowly. Recent approaches encode features in spatial bins to improve speed of learning details, but at the cost of larger model size and loss of continuity. Instead, we propose to encode features in bins of Fourier features that are commonly used for positional encoding. We call these Quantized Fourier Features (QFF). As a naturally multiresolution and periodic representation, our experiments show that using QFF can result in smaller model size, faster training, and better quality outputs for several applications, including Neural Image Representations (NIR), Neural Radiance Field (NeRF) and Signed Distance Function (SDF) modeling. QFF are easy to code, fast to compute, and serve as a simple drop-in addition to many neural field representations.
Language models are good pathologists: using attention-based sequence reduction and text-pretrained transformers for efficient WSI classification
Nov 14, 2022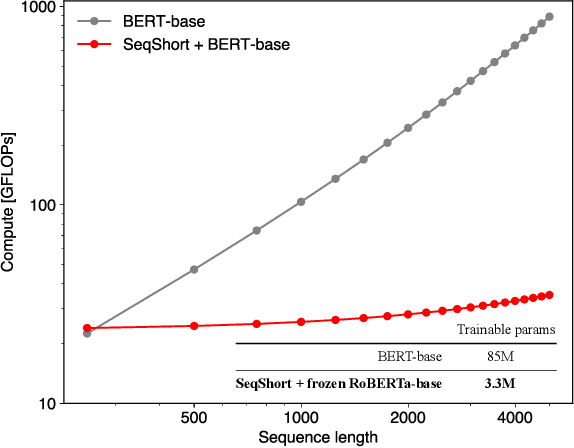
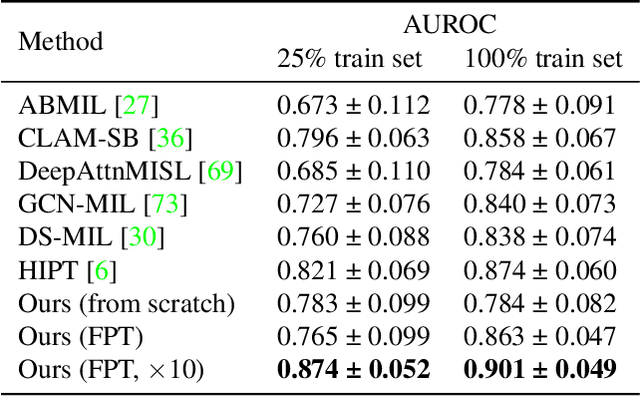
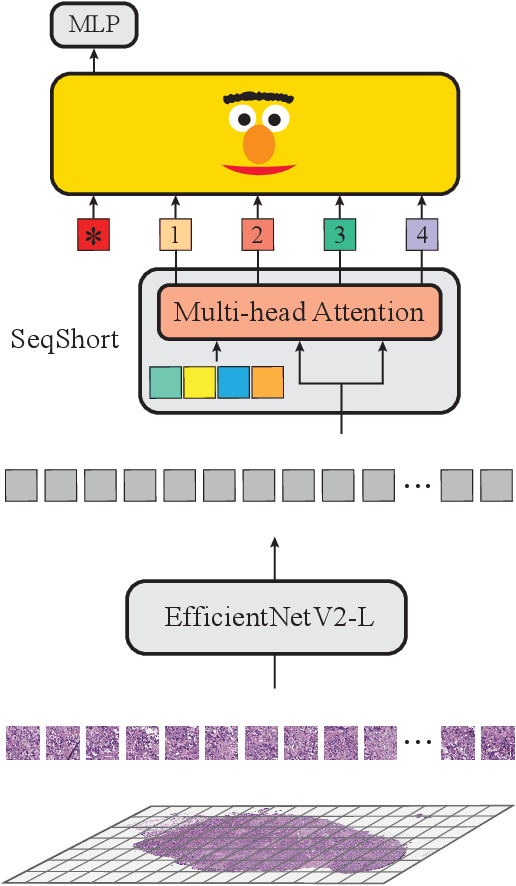

In digital pathology, Whole Slide Image (WSI) analysis is usually formulated as a Multiple Instance Learning (MIL) problem. Although transformer-based architectures have been used for WSI classification, these methods require modifications to adapt them to specific challenges of this type of image data. Despite their power across domains, reference transformer models in classical Computer Vision (CV) and Natural Language Processing (NLP) tasks are not used for pathology slide analysis. In this work we demonstrate the use of standard, frozen, text-pretrained, transformer language models in application to WSI classification. We propose SeqShort, a multi-head attention-based sequence reduction input layer to summarize each WSI in a fixed and short size sequence of instances. This allows us to reduce the computational costs of self-attention on long sequences, and to include positional information that is unavailable in other MIL approaches. We demonstrate the effectiveness of our methods in the task of cancer subtype classification, without the need of designing a WSI-specific transformer or performing in-domain self-supervised pretraining, while keeping a reduced compute budget and number of trainable parameters.
Adaptive Fine-Grained Sketch-Based Image Retrieval
Jul 06, 2022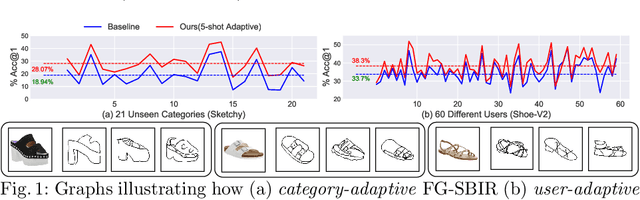
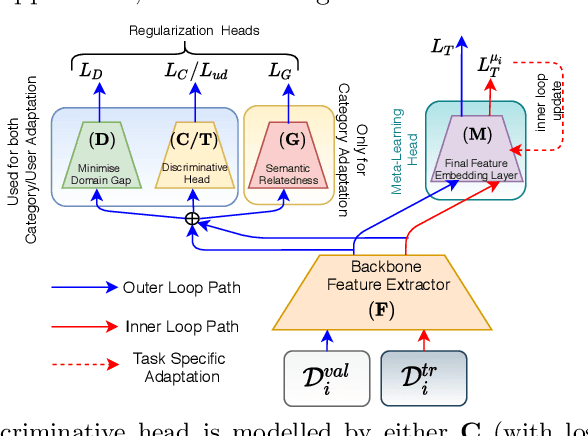
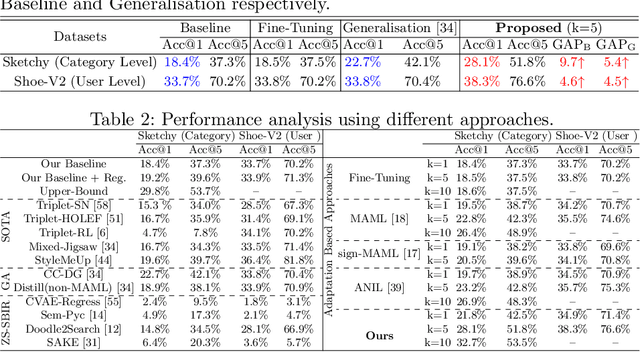
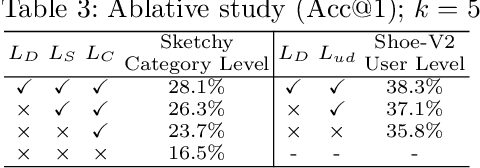
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted towards generalising a model to new categories without any training data from them. In real-world applications, however, a trained FG-SBIR model is often applied to both new categories and different human sketchers, i.e., different drawing styles. Although this complicates the generalisation problem, fortunately, a handful of examples are typically available, enabling the model to adapt to the new category/style. In this paper, we offer a novel perspective -- instead of asking for a model that generalises, we advocate for one that quickly adapts, with just very few samples during testing (in a few-shot manner). To solve this new problem, we introduce a novel model-agnostic meta-learning (MAML) based framework with several key modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the MAML training in the inner loop to make it more stable and tractable. (2) The margin in our contrastive loss is also meta-learned with the rest of the model. (3) Three additional regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR model more effective for category/style adaptation. Extensive experiments on public datasets suggest a large gain over generalisation and zero-shot based approaches, and a few strong few-shot baselines.
Image Super-Resolution With Deep Variational Autoencoders
Mar 17, 2022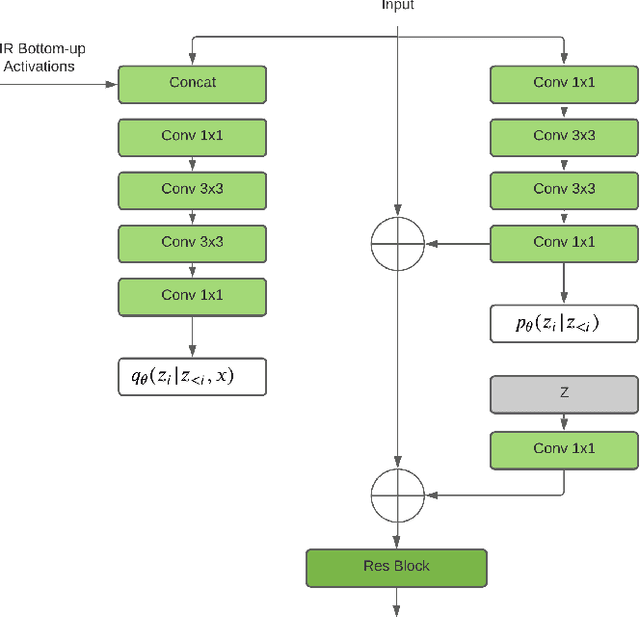
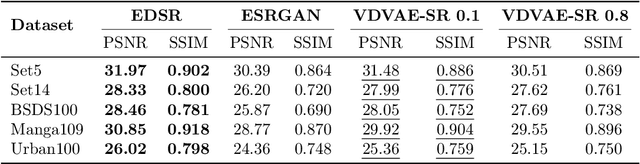
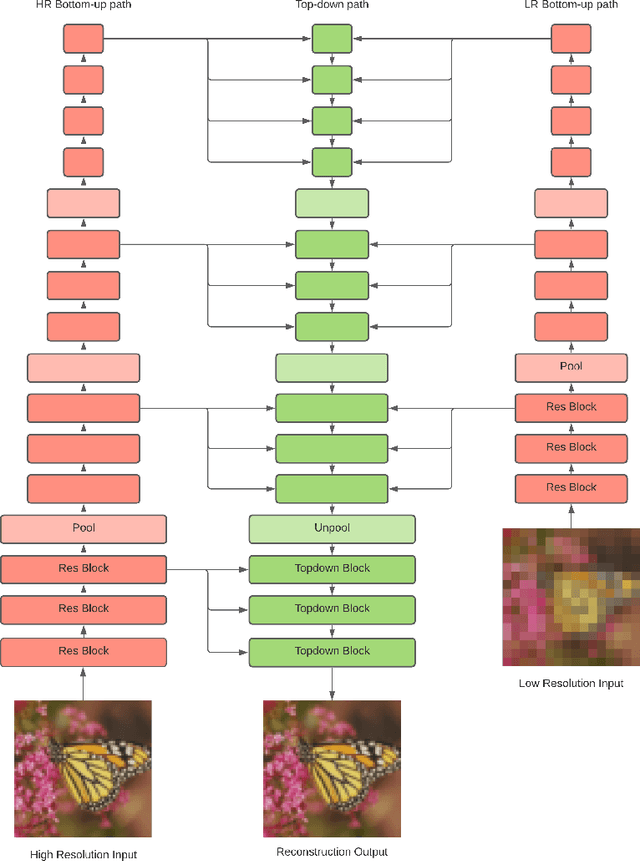
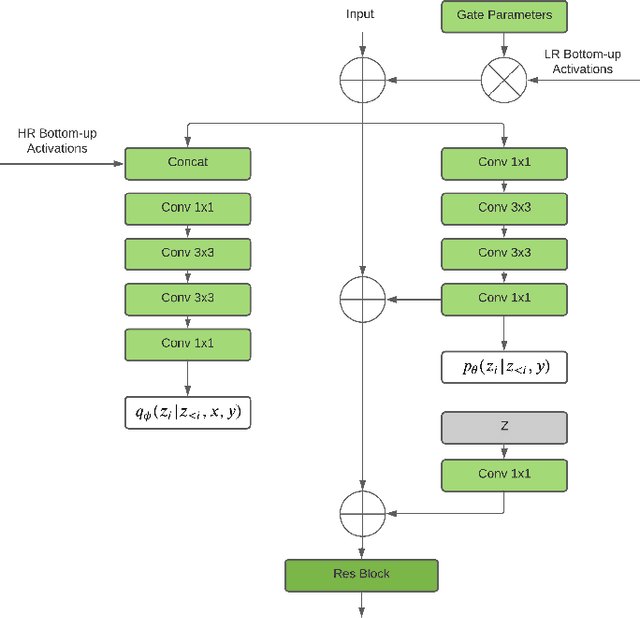
Image super-resolution (SR) techniques are used to generate a high-resolution image from a low-resolution image. Until now, deep generative models such as autoregressive models and Generative Adversarial Networks (GANs) have proven to be effective at modelling high-resolution images. Models based on Variational Autoencoders (VAEs) have often been criticized for their feeble generative performance, but with new advancements such as VDVAE (very deep VAE), there is now strong evidence that deep VAEs have the potential to outperform current state-of-the-art models for high-resolution image generation. In this paper, we introduce VDVAE-SR, a new model that aims to exploit the most recent deep VAE methodologies to improve upon image super-resolution using transfer learning on pretrained VDVAEs. Through qualitative and quantitative evaluations, we show that the proposed model is competitive with other state-of-the-art methods.
Feature-aggregated spatiotemporal spine surface estimation for wearable patch ultrasound volumetric imaging
Nov 11, 2022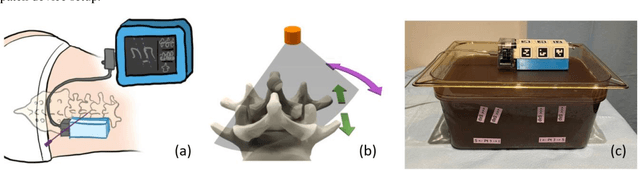
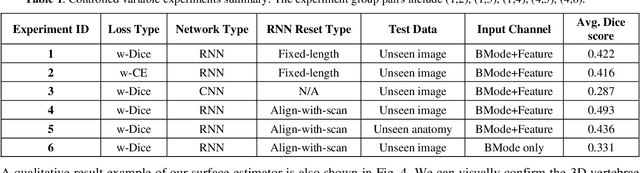

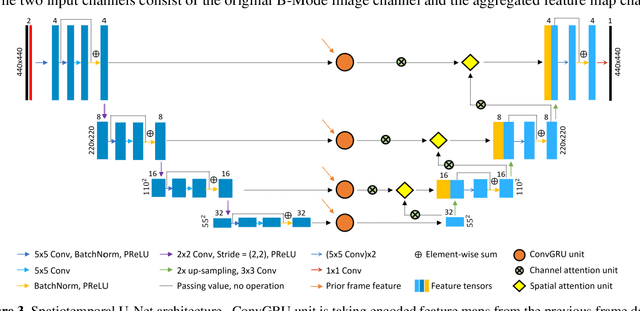
Clear identification of bone structures is crucial for ultrasound-guided lumbar interventions, but it can be challenging due to the complex shapes of the self-shadowing vertebra anatomy and the extensive background speckle noise from the surrounding soft tissue structures. Therefore, we propose to use a patch-like wearable ultrasound solution to capture the reflective bone surfaces from multiple imaging angles and create 3D bone representations for interventional guidance. In this work, we will present our method for estimating the vertebra bone surfaces by using a spatiotemporal U-Net architecture learning from the B-Mode image and aggregated feature maps of hand-crafted filters. The methods are evaluated on spine phantom image data collected by our proposed miniaturized wearable "patch" ultrasound device, and the results show that a significant improvement on baseline method can be achieved with promising accuracy. Equipped with this surface estimation framework, our wearable ultrasound system can potentially provide intuitive and accurate interventional guidance for clinicians in augmented reality setting.