 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Exploiting Diffusion Prior for Task-driven Image Restoration
Jul 30, 2025Task-driven image restoration (TDIR) has recently emerged to address performance drops in high-level vision tasks caused by low-quality (LQ) inputs. Previous TDIR methods struggle to handle practical scenarios in which images are degraded by multiple complex factors, leaving minimal clues for restoration. This motivates us to leverage the diffusion prior, one of the most powerful natural image priors. However, while the diffusion prior can help generate visually plausible results, using it to restore task-relevant details remains challenging, even when combined with recent TDIR methods. To address this, we propose EDTR, which effectively harnesses the power of diffusion prior to restore task-relevant details. Specifically, we propose directly leveraging useful clues from LQ images in the diffusion process by generating from pixel-error-based pre-restored LQ images with mild noise added. Moreover, we employ a small number of denoising steps to prevent the generation of redundant details that dilute crucial task-related information. We demonstrate that our method effectively utilizes diffusion prior for TDIR, significantly enhancing task performance and visual quality across diverse tasks with multiple complex degradations.
Find A Winning Sign: Sign Is All We Need to Win the Lottery
Apr 07, 2025



The Lottery Ticket Hypothesis (LTH) posits the existence of a sparse subnetwork (a.k.a. winning ticket) that can generalize comparably to its over-parameterized counterpart when trained from scratch. The common approach to finding a winning ticket is to preserve the original strong generalization through Iterative Pruning (IP) and transfer information useful for achieving the learned generalization by applying the resulting sparse mask to an untrained network. However, existing IP methods still struggle to generalize their observations beyond ad-hoc initialization and small-scale architectures or datasets, or they bypass these challenges by applying their mask to trained weights instead of initialized ones. In this paper, we demonstrate that the parameter sign configuration plays a crucial role in conveying useful information for generalization to any randomly initialized network. Through linear mode connectivity analysis, we observe that a sparse network trained by an existing IP method can retain its basin of attraction if its parameter signs and normalization layer parameters are preserved. To take a step closer to finding a winning ticket, we alleviate the reliance on normalization layer parameters by preventing high error barriers along the linear path between the sparse network trained by our method and its counterpart with initialized normalization layer parameters. Interestingly, across various architectures and datasets, we observe that any randomly initialized network can be optimized to exhibit low error barriers along the linear path to the sparse network trained by our method by inheriting its sparsity and parameter sign information, potentially achieving performance comparable to the original. The code is available at https://github.com/JungHunOh/AWS\_ICLR2025.git
CLOSER: Towards Better Representation Learning for Few-Shot Class-Incremental Learning
Oct 08, 2024Aiming to incrementally learn new classes with only few samples while preserving the knowledge of base (old) classes, few-shot class-incremental learning (FSCIL) faces several challenges, such as overfitting and catastrophic forgetting. Such a challenging problem is often tackled by fixing a feature extractor trained on base classes to reduce the adverse effects of overfitting and forgetting. Under such formulation, our primary focus is representation learning on base classes to tackle the unique challenge of FSCIL: simultaneously achieving the transferability and the discriminability of the learned representation. Building upon the recent efforts for enhancing transferability, such as promoting the spread of features, we find that trying to secure the spread of features within a more confined feature space enables the learned representation to strike a better balance between transferability and discriminability. Thus, in stark contrast to prior beliefs that the inter-class distance should be maximized, we claim that the closer different classes are, the better for FSCIL. The empirical results and analysis from the perspective of information bottleneck theory justify our simple yet seemingly counter-intuitive representation learning method, raising research questions and suggesting alternative research directions. The code is available at https://github.com/JungHunOh/CLOSER_ECCV2024.
Beyond Image Super-Resolution for Image Recognition with Task-Driven Perceptual Loss
Apr 04, 2024



In real-world scenarios, image recognition tasks, such as semantic segmentation and object detection, often pose greater challenges due to the lack of information available within low-resolution (LR) content. Image super-resolution (SR) is one of the promising solutions for addressing the challenges. However, due to the ill-posed property of SR, it is challenging for typical SR methods to restore task-relevant high-frequency contents, which may dilute the advantage of utilizing the SR method. Therefore, in this paper, we propose Super-Resolution for Image Recognition (SR4IR) that effectively guides the generation of SR images beneficial to achieving satisfactory image recognition performance when processing LR images. The critical component of our SR4IR is the task-driven perceptual (TDP) loss that enables the SR network to acquire task-specific knowledge from a network tailored for a specific task. Moreover, we propose a cross-quality patch mix and an alternate training framework that significantly enhances the efficacy of the TDP loss by addressing potential problems when employing the TDP loss. Through extensive experiments, we demonstrate that our SR4IR achieves outstanding task performance by generating SR images useful for a specific image recognition task, including semantic segmentation, object detection, and image classification. The implementation code is available at https://github.com/JaehaKim97/SR4IR.
Attentive Fine-Grained Structured Sparsity for Image Restoration
Apr 26, 2022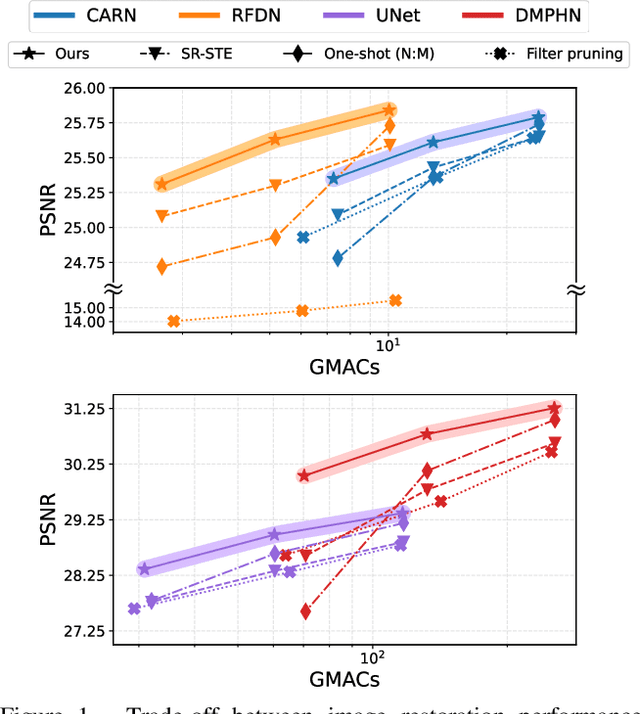
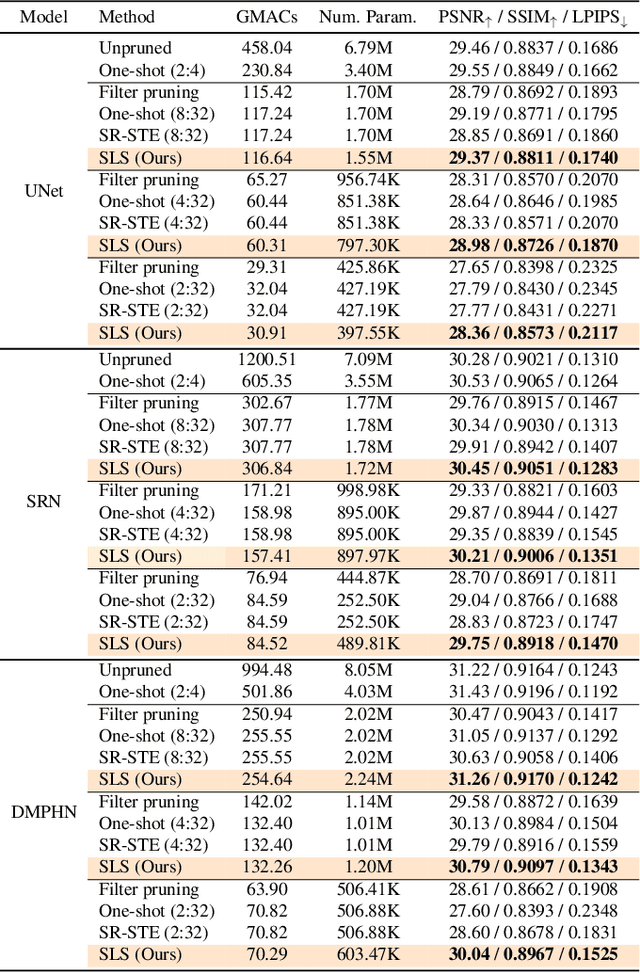
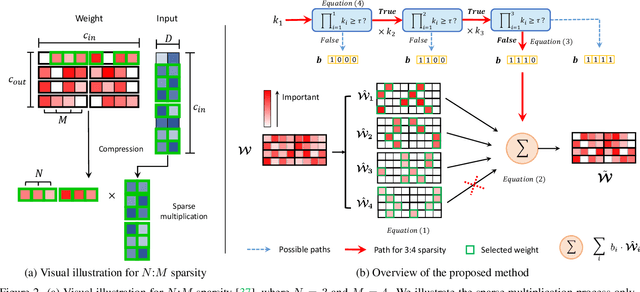
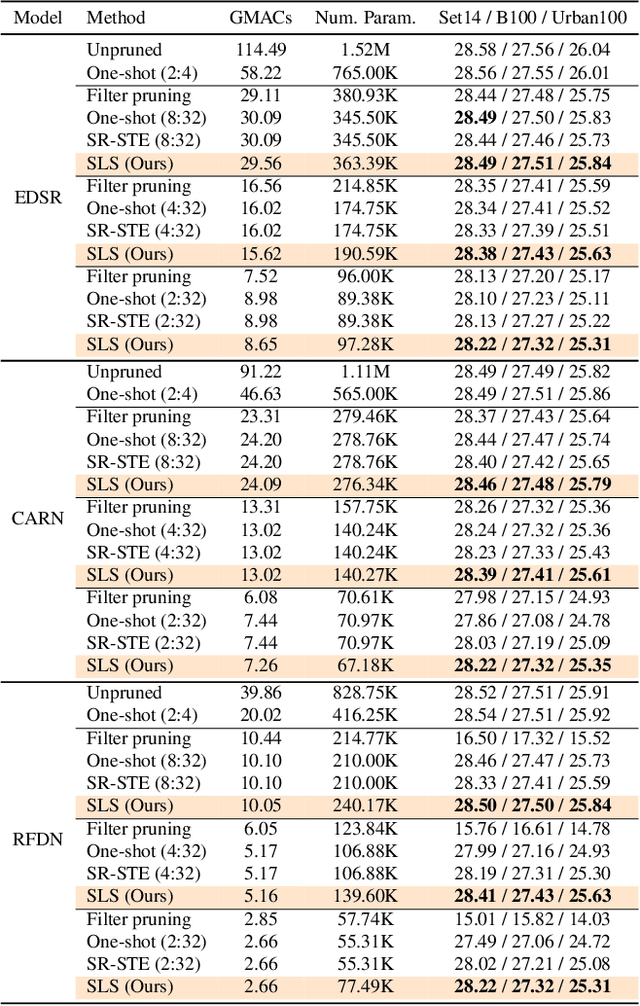
Image restoration tasks have witnessed great performance improvement in recent years by developing large deep models. Despite the outstanding performance, the heavy computation demanded by the deep models has restricted the application of image restoration. To lift the restriction, it is required to reduce the size of the networks while maintaining accuracy. Recently, N:M structured pruning has appeared as one of the effective and practical pruning approaches for making the model efficient with the accuracy constraint. However, it fails to account for different computational complexities and performance requirements for different layers of an image restoration network. To further optimize the trade-off between the efficiency and the restoration accuracy, we propose a novel pruning method that determines the pruning ratio for N:M structured sparsity at each layer. Extensive experimental results on super-resolution and deblurring tasks demonstrate the efficacy of our method which outperforms previous pruning methods significantly. PyTorch implementation for the proposed methods will be publicly available at https://github.com/JungHunOh/SLS_CVPR2022.
Batch Normalization Tells You Which Filter is Important
Dec 02, 2021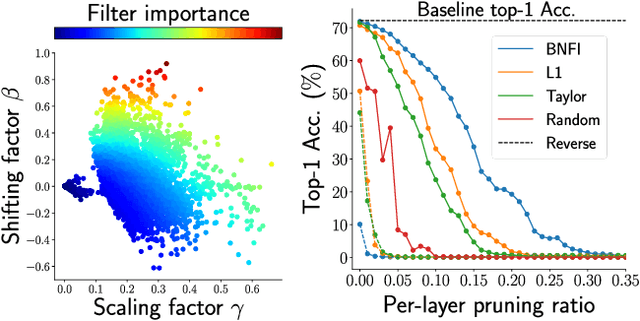
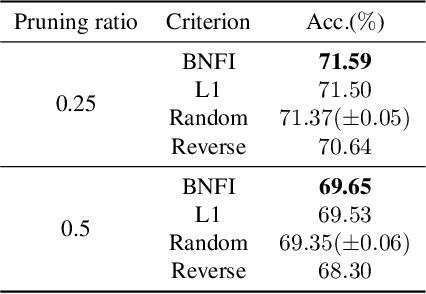
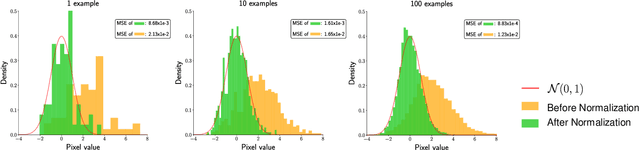
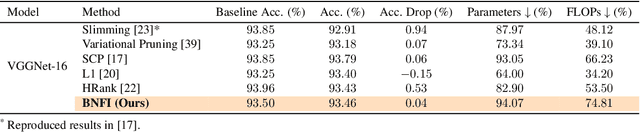
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.
DAQ: Distribution-Aware Quantization for Deep Image Super-Resolution Networks
Dec 21, 2020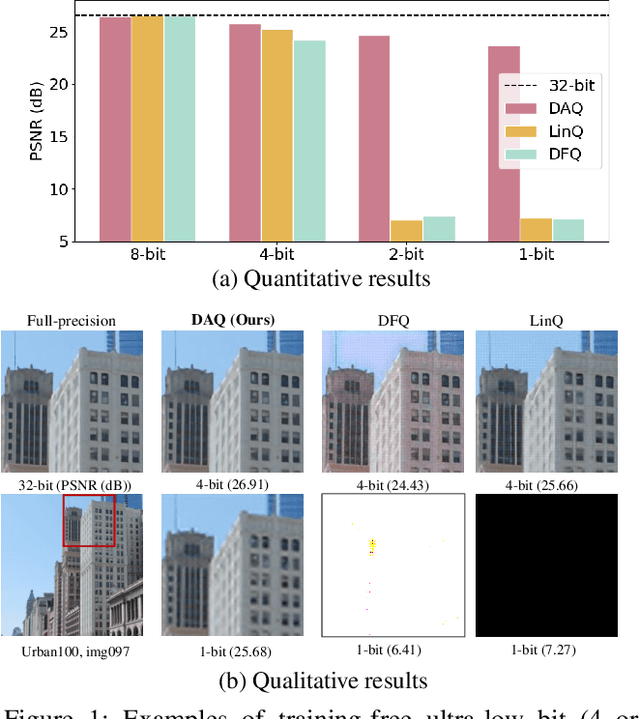

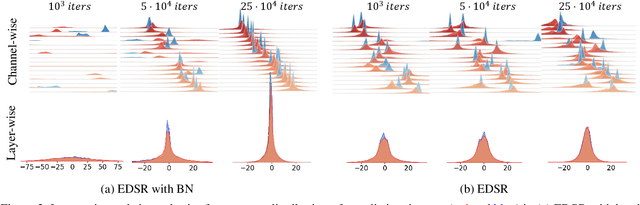
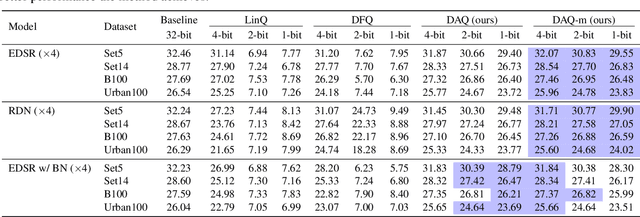
Quantizing deep convolutional neural networks for image super-resolution substantially reduces their computational costs. However, existing works either suffer from a severe performance drop in ultra-low precision of 4 or lower bit-widths, or require a heavy fine-tuning process to recover the performance. To our knowledge, this vulnerability to low precisions relies on two statistical observations of feature map values. First, distribution of feature map values varies significantly per channel and per input image. Second, feature maps have outliers that can dominate the quantization error. Based on these observations, we propose a novel distribution-aware quantization scheme (DAQ) which facilitates accurate training-free quantization in ultra-low precision. A simple function of DAQ determines dynamic range of feature maps and weights with low computational burden. Furthermore, our method enables mixed-precision quantization by calculating the relative sensitivity of each channel, without any training process involved. Nonetheless, quantization-aware training is also applicable for auxiliary performance gain. Our new method outperforms recent training-free and even training-based quantization methods to the state-of-the-art image super-resolution networks in ultra-low precision.