 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fighting Malicious Media Data: A Survey on Tampering Detection and Deepfake Detection
Dec 12, 2022



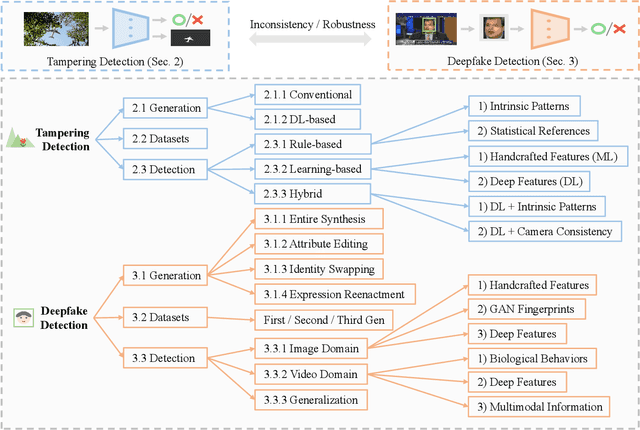
Online media data, in the forms of images and videos, are becoming mainstream communication channels. However, recent advances in deep learning, particularly deep generative models, open the doors for producing perceptually convincing images and videos at a low cost, which not only poses a serious threat to the trustworthiness of digital information but also has severe societal implications. This motivates a growing interest of research in media tampering detection, i.e., using deep learning techniques to examine whether media data have been maliciously manipulated. Depending on the content of the targeted images, media forgery could be divided into image tampering and Deepfake techniques. The former typically moves or erases the visual elements in ordinary images, while the latter manipulates the expressions and even the identity of human faces. Accordingly, the means of defense include image tampering detection and Deepfake detection, which share a wide variety of properties. In this paper, we provide a comprehensive review of the current media tampering detection approaches, and discuss the challenges and trends in this field for future research.
ADAS: A Simple Active-and-Adaptive Baseline for Cross-Domain 3D Semantic Segmentation
Dec 21, 2022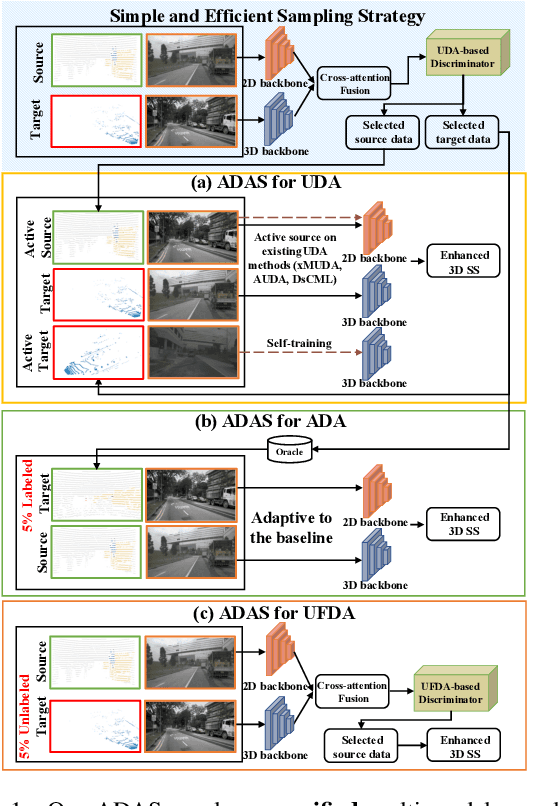
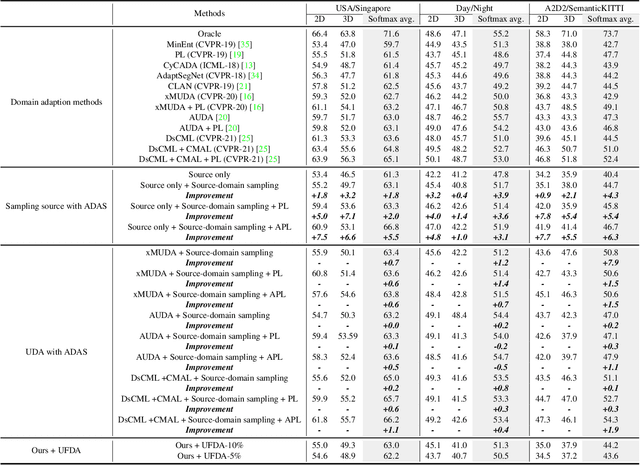
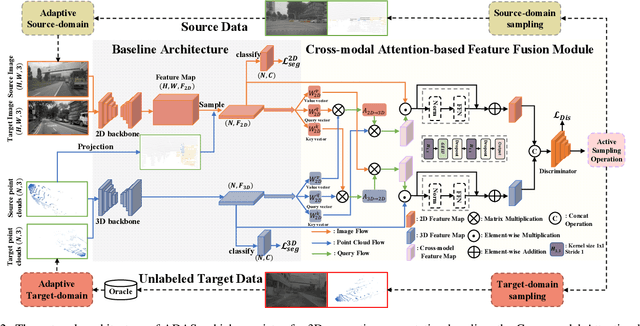
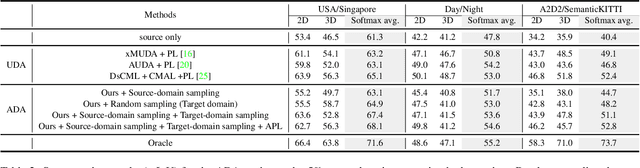
State-of-the-art 3D semantic segmentation models are trained on the off-the-shelf public benchmarks, but they often face the major challenge when these well-trained models are deployed to a new domain. In this paper, we propose an Active-and-Adaptive Segmentation (ADAS) baseline to enhance the weak cross-domain generalization ability of a well-trained 3D segmentation model, and bridge the point distribution gap between domains. Specifically, before the cross-domain adaptation stage begins, ADAS performs an active sampling operation to select a maximally-informative subset from both source and target domains for effective adaptation, reducing the adaptation difficulty under 3D scenarios. Benefiting from the rise of multi-modal 2D-3D datasets, ADAS utilizes a cross-modal attention-based feature fusion module that can extract a representative pair of image features and point features to achieve a bi-directional image-point feature interaction for better safe adaptation. Experimentally, ADAS is verified to be effective in many cross-domain settings including: 1) Unsupervised Domain Adaptation (UDA), which means that all samples from target domain are unlabeled; 2) Unsupervised Few-shot Domain Adaptation (UFDA) which means that only a few unlabeled samples are available in the unlabeled target domain; 3) Active Domain Adaptation (ADA) which means that the selected target samples by ADAS are manually annotated. Their results demonstrate that ADAS achieves a significant accuracy gain by easily coupling ADAS with self-training methods or off-the-shelf UDA works.
Characterization of micro pore optics for full-field X-ray fluorescence imaging
Dec 21, 2022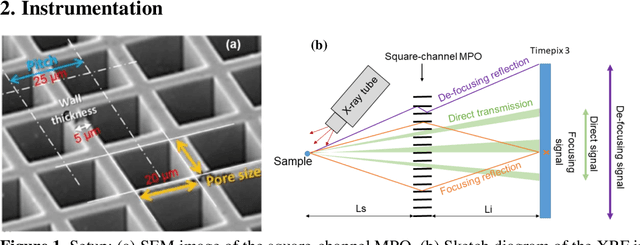
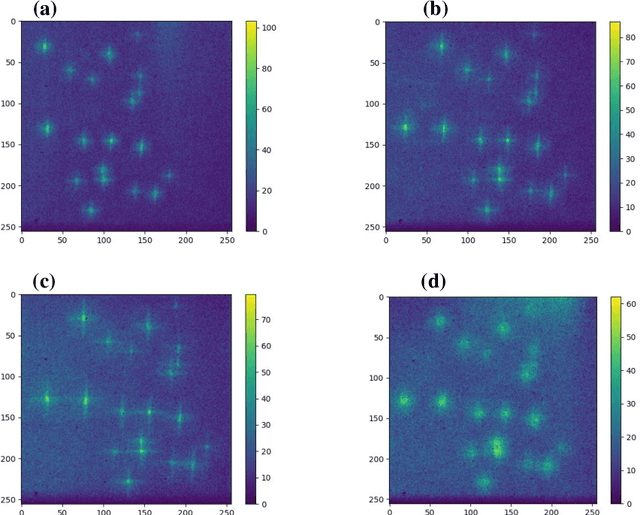
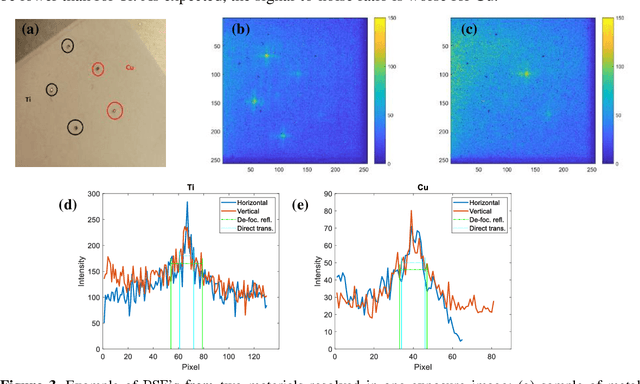
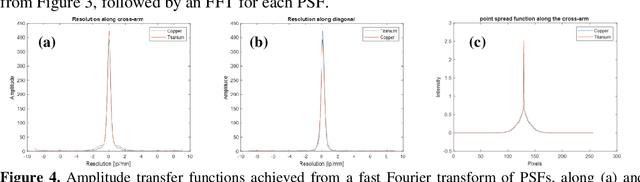
Elemental mapping images can be achieved through step scanning imaging using pinhole optics or micro pore optics (MPO), or alternatively by full-field X-ray fluorescence imaging (FF-XRF). X-ray optics for FF-XRF can be manufactured with different micro-channel geometries such as square, hexagonal or circular channels. Each optic geometry creates different imaging artefacts. Square-channel MPOs generate a high intensity central spot due to two reflections via orthogonal channel walls inside a single channel, which is the desirable part for image formation, and two perpendicular lines forming a cross due to reflections in one plane only. Thus, we have studied the performance of a square-channel MPO in an FF-XRF imaging system. The setup consists of a commercially available MPO provided by Photonis and a Timepix3 readout chip with a silicon detector. Imaging of fluorescence from small metal particles has been used to obtain the point spread function (PSF) characteristics. The transmission through MPO channels and variation of the critical reflection angle are characterized by measurements of fluorescence from Copper and Titanium metal fragments. Since the critical angle of reflection is energy dependent, the cross-arm artefacts will affect the resolution differently for different fluorescence energies. It is possible to identify metal fragments due to the form of the PSF function. The PSF function can be further characterized using a Fourier transform to suppress diffuse background signals in the image.
Semantic Communication Enabling Robust Edge Intelligence for Time-Critical IoT Applications
Nov 28, 2022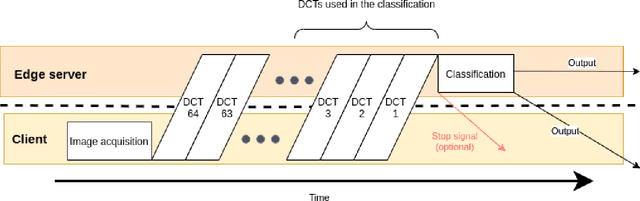
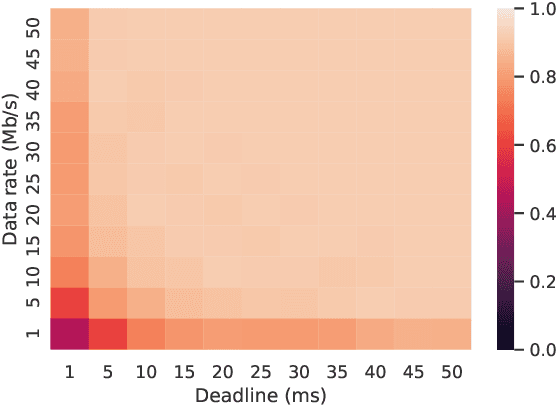
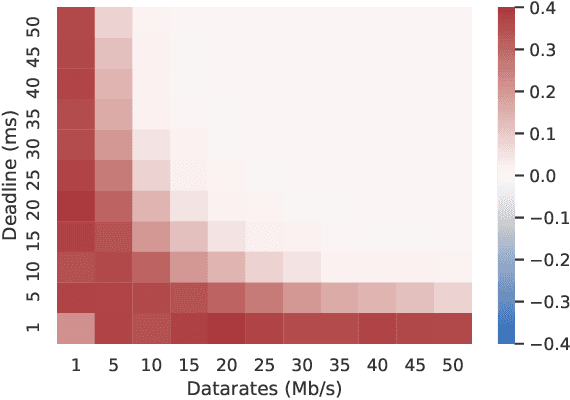
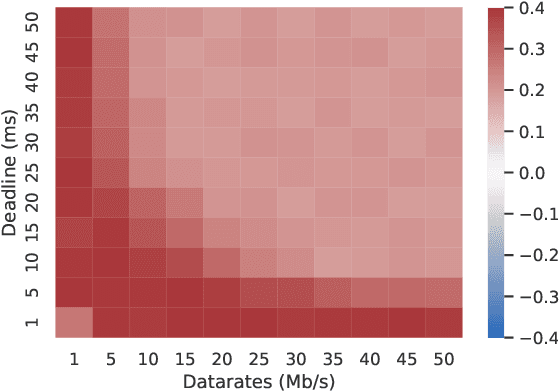
This paper aims to design robust Edge Intelligence using semantic communication for time-critical IoT applications. We systematically analyze the effect of image DCT coefficients on inference accuracy and propose the channel-agnostic effectiveness encoding for offloading by transmitting the most meaningful task data first. This scheme can well utilize all available communication resource and strike a balance between transmission latency and inference accuracy. Then, we design an effectiveness decoding by implementing a novel image augmentation process for convolutional neural network (CNN) training, through which an original CNN model is transformed into a Robust CNN model. We use the proposed training method to generate Robust MobileNet-v2 and Robust ResNet-50. The proposed Edge Intelligence framework consists of the proposed effectiveness encoding and effectiveness decoding. The experimental results show that the effectiveness decoding using the Robust CNN models perform consistently better under various image distortions caused by channel errors or limited communication resource. The proposed Edge Intelligence framework using semantic communication significantly outperforms the conventional approach under latency and data rate constraints, in particular, under ultra stringent deadlines and low data rate.
SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields
Dec 05, 2022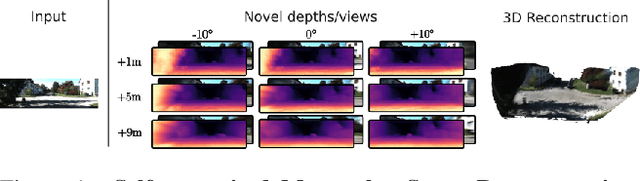

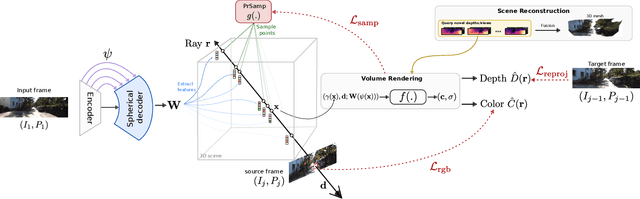
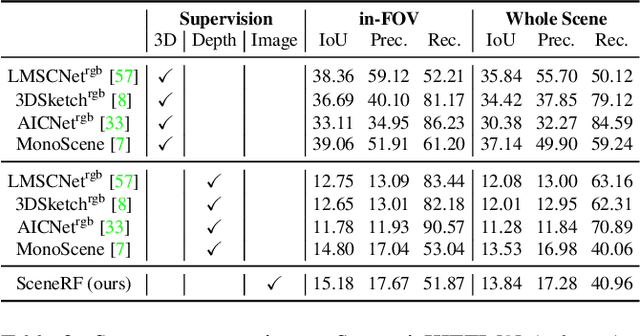
In the literature, 3D reconstruction from 2D image has been extensively addressed but often still requires geometrical supervision. In this paper, we propose SceneRF, a self-supervised monocular scene reconstruction method with neural radiance fields (NeRF) learned from multiple image sequences with pose. To improve geometry prediction, we introduce new geometry constraints and a novel probabilistic sampling strategy that efficiently update radiance fields. As the latter are conditioned on a single frame, scene reconstruction is achieved from the fusion of multiple synthesized novel depth views. This is enabled by our spherical-decoder, which allows hallucination beyond the input frame field of view. Thorough experiments demonstrate that we outperform all baselines on all metrics for novel depth views synthesis and scene reconstruction. Our code is available at https://astra-vision.github.io/SceneRF.
DeepVoxNet2: Yet another CNN framework
Nov 17, 2022We know that both the CNN mapping function and the sampling scheme are of paramount importance for CNN-based image analysis. It is clear that both functions operate in the same space, with an image axis $\mathcal{I}$ and a feature axis $\mathcal{F}$. Remarkably, we found that no frameworks existed that unified the two and kept track of the spatial origin of the data automatically. Based on our own practical experience, we found the latter to often result in complex coding and pipelines that are difficult to exchange. This article introduces our framework for 1, 2 or 3D image classification or segmentation: DeepVoxNet2 (DVN2). This article serves as an interactive tutorial, and a pre-compiled version, including the outputs of the code blocks, can be found online in the public DVN2 repository. This tutorial uses data from the multimodal Brain Tumor Image Segmentation Benchmark (BRATS) of 2018 to show an example of a 3D segmentation pipeline.
Urban Visual Intelligence: Studying Cities with AI and Street-level Imagery
Jan 02, 2023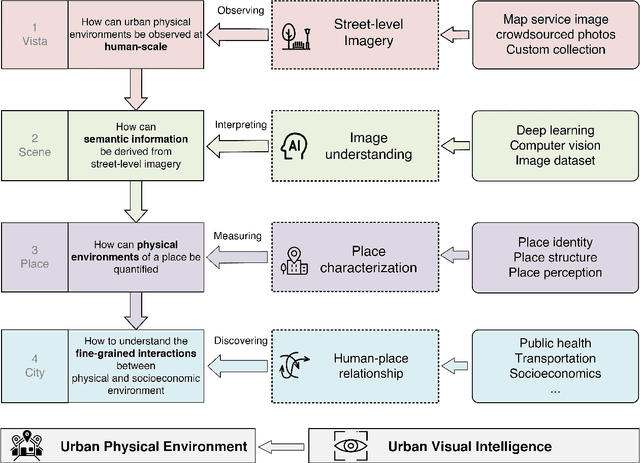

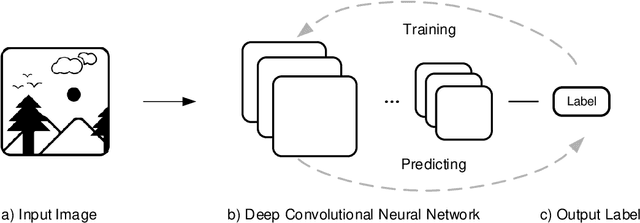
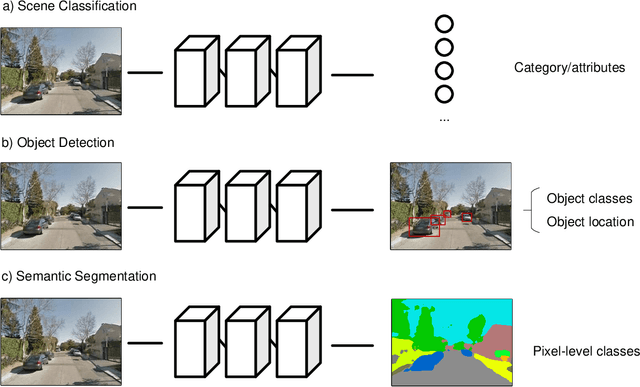
The visual dimension of cities has been a fundamental subject in urban studies, since the pioneering work of scholars such as Sitte, Lynch, Arnheim, and Jacobs. Several decades later, big data and artificial intelligence (AI) are revolutionizing how people move, sense, and interact with cities. This paper reviews the literature on the appearance and function of cities to illustrate how visual information has been used to understand them. A conceptual framework, Urban Visual Intelligence, is introduced to systematically elaborate on how new image data sources and AI techniques are reshaping the way researchers perceive and measure cities, enabling the study of the physical environment and its interactions with socioeconomic environments at various scales. The paper argues that these new approaches enable researchers to revisit the classic urban theories and themes, and potentially help cities create environments that are more in line with human behaviors and aspirations in the digital age.
Last-Mile Embodied Visual Navigation
Nov 21, 2022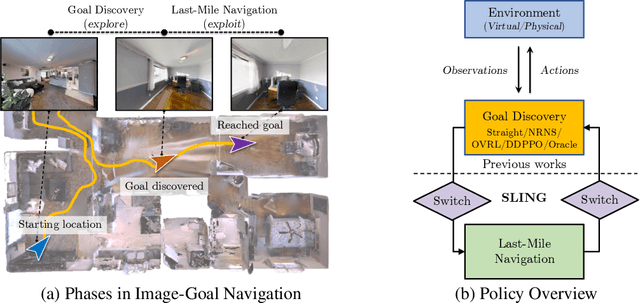
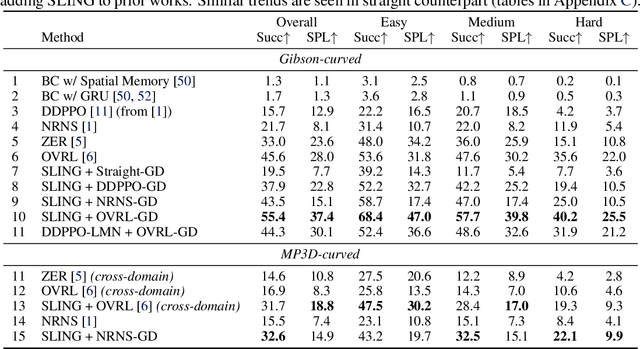
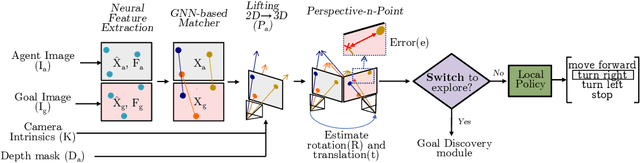
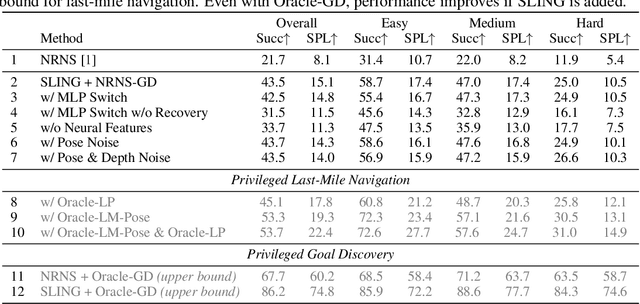
Realistic long-horizon tasks like image-goal navigation involve exploratory and exploitative phases. Assigned with an image of the goal, an embodied agent must explore to discover the goal, i.e., search efficiently using learned priors. Once the goal is discovered, the agent must accurately calibrate the last-mile of navigation to the goal. As with any robust system, switches between exploratory goal discovery and exploitative last-mile navigation enable better recovery from errors. Following these intuitive guide rails, we propose SLING to improve the performance of existing image-goal navigation systems. Entirely complementing prior methods, we focus on last-mile navigation and leverage the underlying geometric structure of the problem with neural descriptors. With simple but effective switches, we can easily connect SLING with heuristic, reinforcement learning, and neural modular policies. On a standardized image-goal navigation benchmark (Hahn et al. 2021), we improve performance across policies, scenes, and episode complexity, raising the state-of-the-art from 45% to 55% success rate. Beyond photorealistic simulation, we conduct real-robot experiments in three physical scenes and find these improvements to transfer well to real environments.
Three-dimensional reconstruction and characterization of bladder deformations
Jan 18, 2023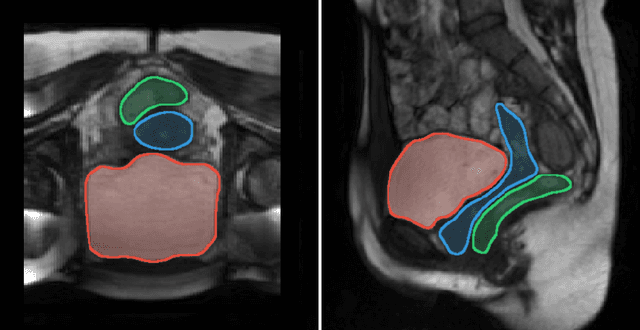
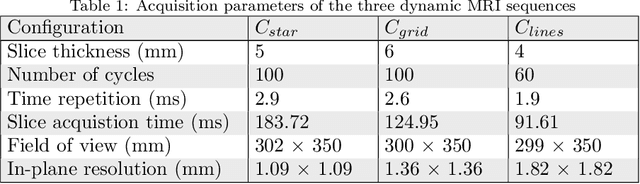
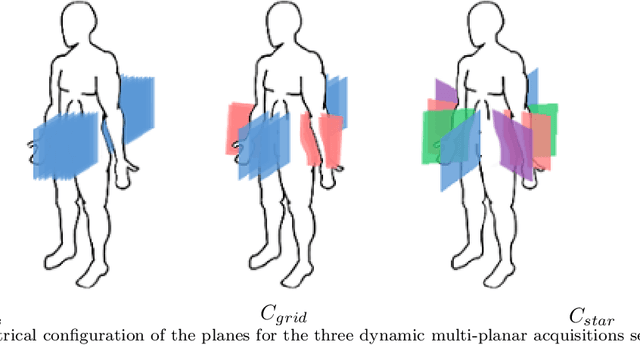
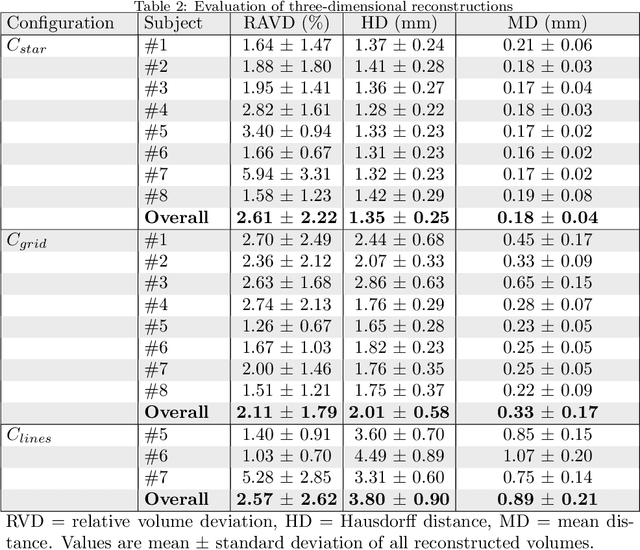
Background and Objective: Pelvic floor disorders are prevalent diseases and patient care remains difficult as the dynamics of the pelvic floor remains poorly known. So far, only 2D dynamic observations of straining exercises at excretion are available in the clinics and the understanding of three-dimensional pelvic organs mechanical defects is not yet achievable. In this context, we proposed a complete methodology for the 3D representation of the non-reversible bladder deformations during exercises, directly combined with synthesized 3D representation of the location of the highest strain areas on the organ surface. Methods: Novel image segmentation and registration approaches have been combined with three geometrical configurations of up-to-date rapid dynamic multi-slices MRI acquisition for the reconstruction of real-time dynamic bladder volumes. Results: For the first time, we proposed real-time 3D deformation fields of the bladder under strain from in-bore forced breathing exercises. The potential of our method was assessed on eight control subjects undergoing forced breathing exercises. We obtained average volume deviation of the reconstructed dynamic volume of bladders around 2.5\% and high registration accuracy with mean distance values of 0.4 $\pm$ 0.3 mm and Hausdorff distance values of 2.2 $\pm$ 1.1 mm. Conclusions: Immediately transferable to the clinics with rapid acquisitions, the proposed framework represents a real advance in the field of pelvic floor disorders as it provides, for the first time, a proper 3D+t spatial tracking of bladder non-reversible deformations. This work is intended to be extended to patients with cavities filling and excretion to better characterize the degree of severity of pelvic floor pathologies for diagnostic assistance or in preoperative surgical planning.
Multi-layer Representation Learning for Robust OOD Image Classification
Jul 27, 2022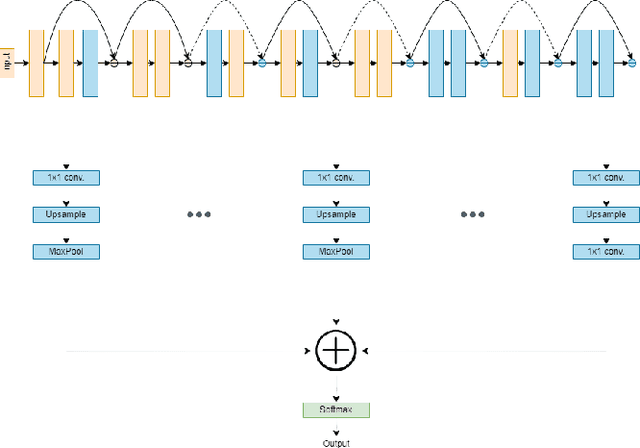

Convolutional Neural Networks have become the norm in image classification. Nevertheless, their difficulty to maintain high accuracy across datasets has become apparent in the past few years. In order to utilize such models in real-world scenarios and applications, they must be able to provide trustworthy predictions on unseen data. In this paper, we argue that extracting features from a CNN's intermediate layers can assist in the model's final prediction. Specifically, we adapt the Hypercolumns method to a ResNet-18 and find a significant increase in the model's accuracy, when evaluating on the NICO dataset.