 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Schrödinger's Camera: First Steps Towards a Quantum-Based Privacy Preserving Camera
Mar 13, 2023
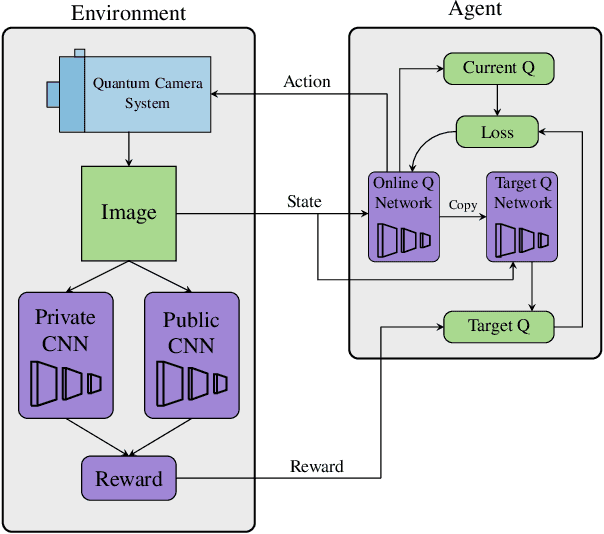
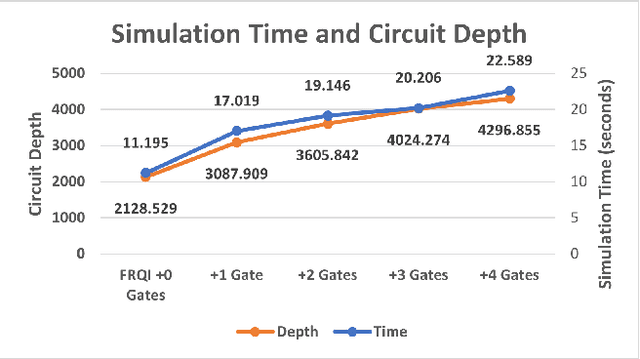

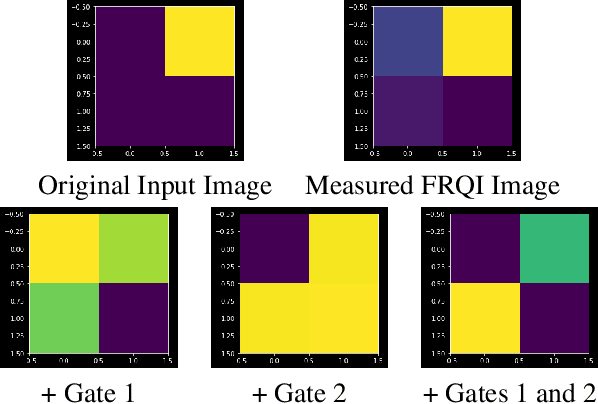
Privacy-preserving vision must overcome the dual challenge of utility and privacy. Too much anonymity renders the images useless, but too little privacy does not protect sensitive data. We propose a novel design for privacy preservation, where the imagery is stored in quantum states. In the future, this will be enabled by quantum imaging cameras, and, currently, storing very low resolution imagery in quantum states is possible. Quantum state imagery has the advantage of being both private and non-private till the point of measurement. This occurs even when images are manipulated, since every quantum action is fully reversible. We propose a control algorithm, based on double deep Q-learning, to learn how to anonymize the image before measurement. After learning, the RL weights are fixed, and new attack neural networks are trained from scratch to break the system's privacy. Although all our results are in simulation, we demonstrate, with these first steps, that it is possible to control both privacy and utility in a quantum-based manner.
DiffusionDepth: Diffusion Denoising Approach for Monocular Depth Estimation
Mar 13, 2023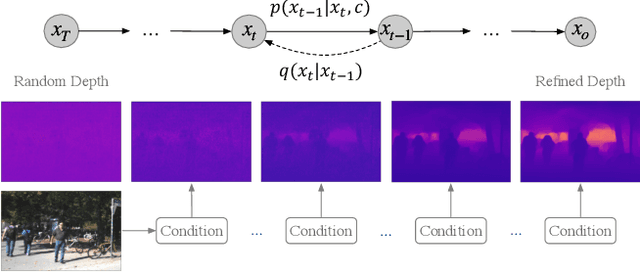
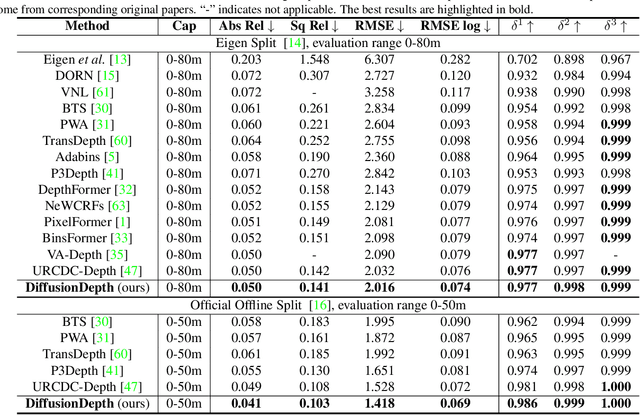
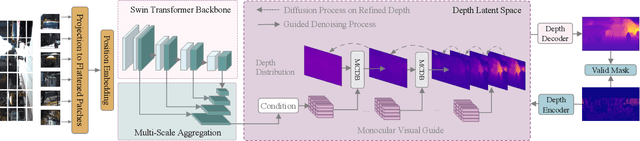
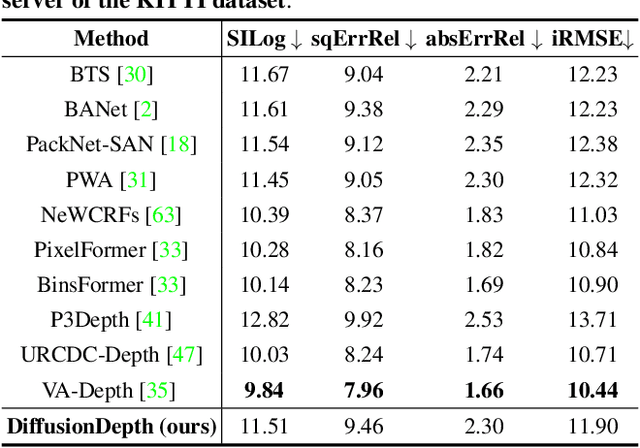
Monocular depth estimation is a challenging task that predicts the pixel-wise depth from a single 2D image. Current methods typically model this problem as a regression or classification task. We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. The process is performed in the latent space encoded by a dedicated depth encoder and decoder. Instead of diffusing ground truth (GT) depth, the model learns to reverse the process of diffusing the refined depth of itself into random depth distribution. This self-diffusion formulation overcomes the difficulty of applying generative models to sparse GT depth scenarios. The proposed approach benefits this task by refining depth estimation step by step, which is superior for generating accurate and highly detailed depth maps. Experimental results on KITTI and NYU-Depth-V2 datasets suggest that a simple yet efficient diffusion approach could reach state-of-the-art performance in both indoor and outdoor scenarios with acceptable inference time.
LocalEyenet: Deep Attention framework for Localization of Eyes
Mar 13, 2023
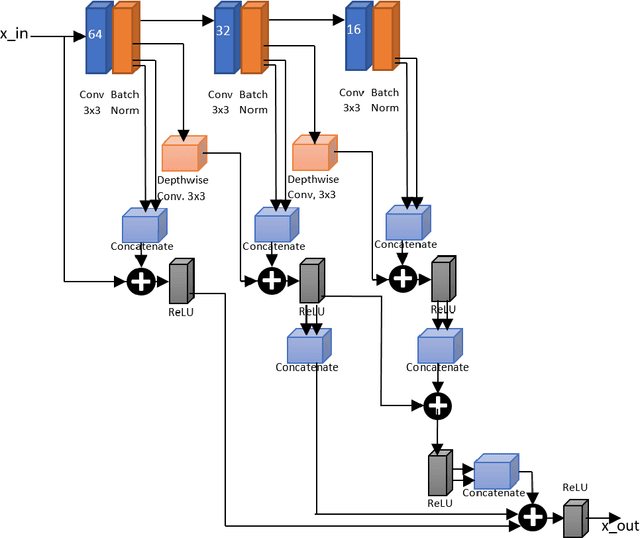
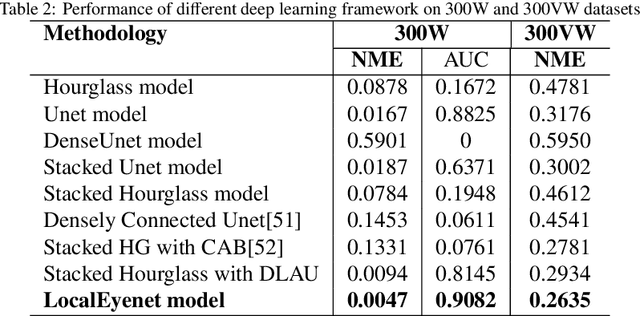
Development of human machine interface has become a necessity for modern day machines to catalyze more autonomy and more efficiency. Gaze driven human intervention is an effective and convenient option for creating an interface to alleviate human errors. Facial landmark detection is very crucial for designing a robust gaze detection system. Regression based methods capacitate good spatial localization of the landmarks corresponding to different parts of the faces. But there are still scope of improvements which have been addressed by incorporating attention. In this paper, we have proposed a deep coarse-to-fine architecture called LocalEyenet for localization of only the eye regions that can be trained end-to-end. The model architecture, build on stacked hourglass backbone, learns the self-attention in feature maps which aids in preserving global as well as local spatial dependencies in face image. We have incorporated deep layer aggregation in each hourglass to minimize the loss of attention over the depth of architecture. Our model shows good generalization ability in cross-dataset evaluation and in real-time localization of eyes.
MSINet: Twins Contrastive Search of Multi-Scale Interaction for Object ReID
Mar 13, 2023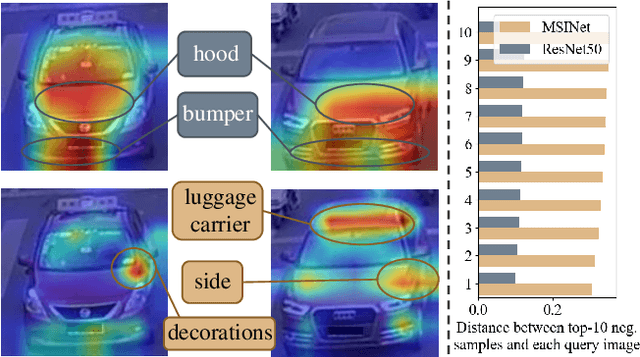

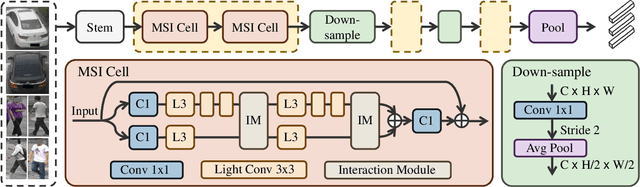
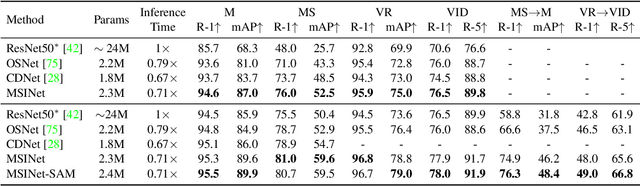
Neural Architecture Search (NAS) has been increasingly appealing to the society of object Re-Identification (ReID), for that task-specific architectures significantly improve the retrieval performance. Previous works explore new optimizing targets and search spaces for NAS ReID, yet they neglect the difference of training schemes between image classification and ReID. In this work, we propose a novel Twins Contrastive Mechanism (TCM) to provide more appropriate supervision for ReID architecture search. TCM reduces the category overlaps between the training and validation data, and assists NAS in simulating real-world ReID training schemes. We then design a Multi-Scale Interaction (MSI) search space to search for rational interaction operations between multi-scale features. In addition, we introduce a Spatial Alignment Module (SAM) to further enhance the attention consistency confronted with images from different sources. Under the proposed NAS scheme, a specific architecture is automatically searched, named as MSINet. Extensive experiments demonstrate that our method surpasses state-of-the-art ReID methods on both in-domain and cross-domain scenarios. Source code available in https://github.com/vimar-gu/MSINet.
Robust Autoencoders for Collective Corruption Removal
Mar 06, 2023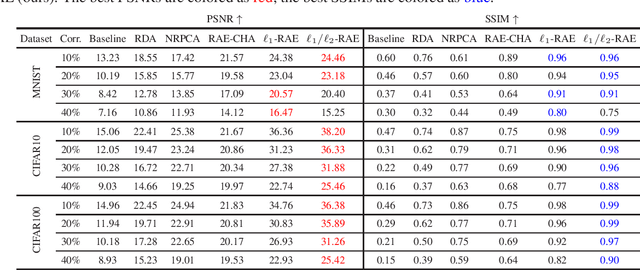
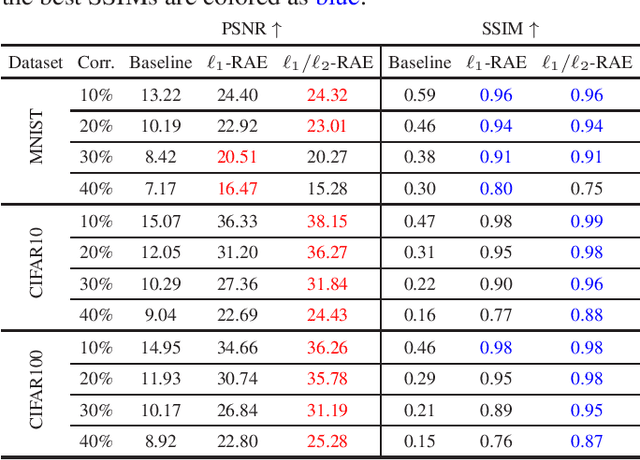
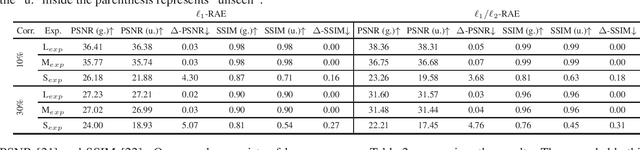
Robust PCA is a standard tool for learning a linear subspace in the presence of sparse corruption or rare outliers. What about robustly learning manifolds that are more realistic models for natural data, such as images? There have been several recent attempts to generalize robust PCA to manifold settings. In this paper, we propose $\ell_1$- and scaling-invariant $\ell_1/\ell_2$-robust autoencoders based on a surprisingly compact formulation built on the intuition that deep autoencoders perform manifold learning. We demonstrate on several standard image datasets that the proposed formulation significantly outperforms all previous methods in collectively removing sparse corruption, without clean images for training. Moreover, we also show that the learned manifold structures can be generalized to unseen data samples effectively.
A Systematic Evaluation of Backdoor Trigger Characteristics in Image Classification
Feb 03, 2023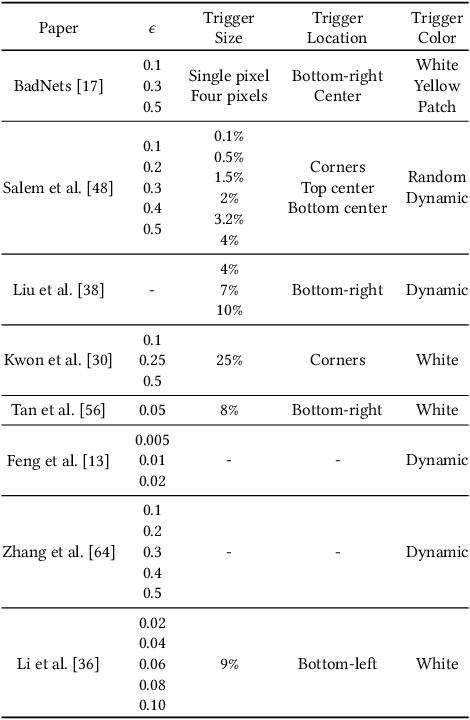

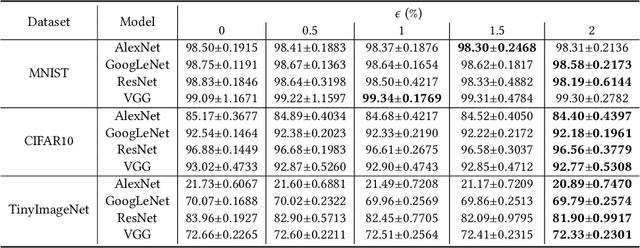
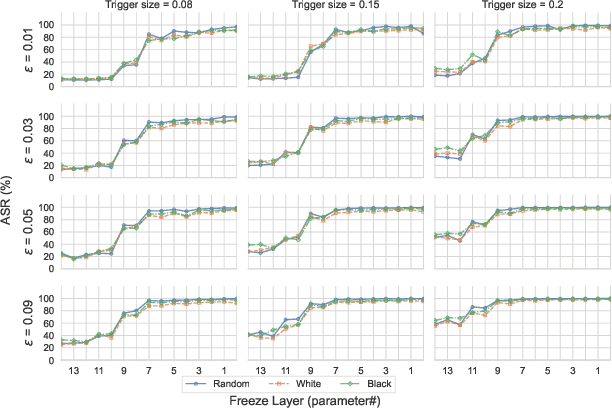
Deep learning achieves outstanding results in many machine learning tasks. Nevertheless, it is vulnerable to backdoor attacks that modify the training set to embed a secret functionality in the trained model. The modified training samples have a secret property, i.e., a trigger. At inference time, the secret functionality is activated when the input contains the trigger, while the model functions correctly in other cases. While there are many known backdoor attacks (and defenses), deploying a stealthy attack is still far from trivial. Successfully creating backdoor triggers heavily depends on numerous parameters. Unfortunately, research has not yet determined which parameters contribute most to the attack performance. This paper systematically analyzes the most relevant parameters for the backdoor attacks, i.e., trigger size, position, color, and poisoning rate. Using transfer learning, which is very common in computer vision, we evaluate the attack on numerous state-of-the-art models (ResNet, VGG, AlexNet, and GoogLeNet) and datasets (MNIST, CIFAR10, and TinyImageNet). Our attacks cover the majority of backdoor settings in research, providing concrete directions for future works. Our code is publicly available to facilitate the reproducibility of our results.
Analog Image Denoising with an Adaptive Memristive Crossbar Network
Sep 25, 2022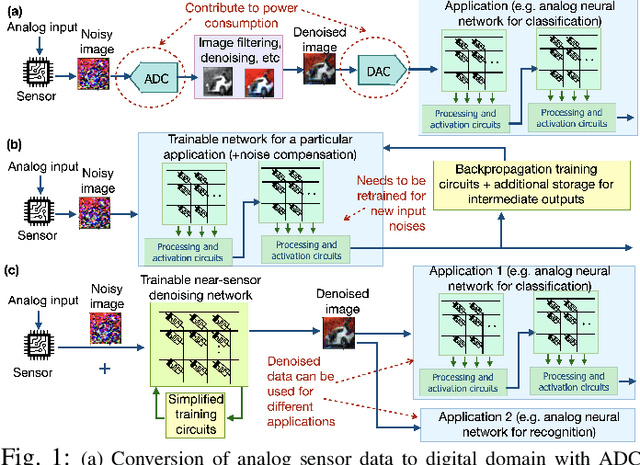
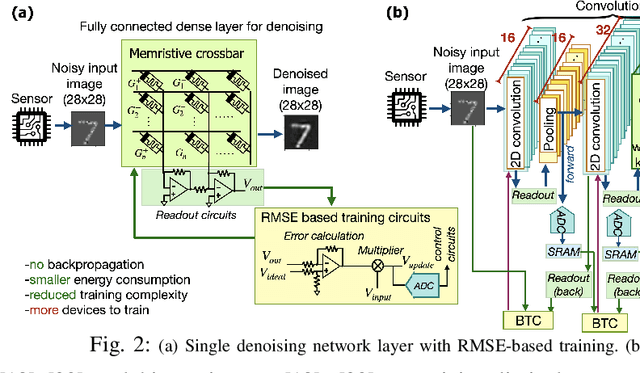
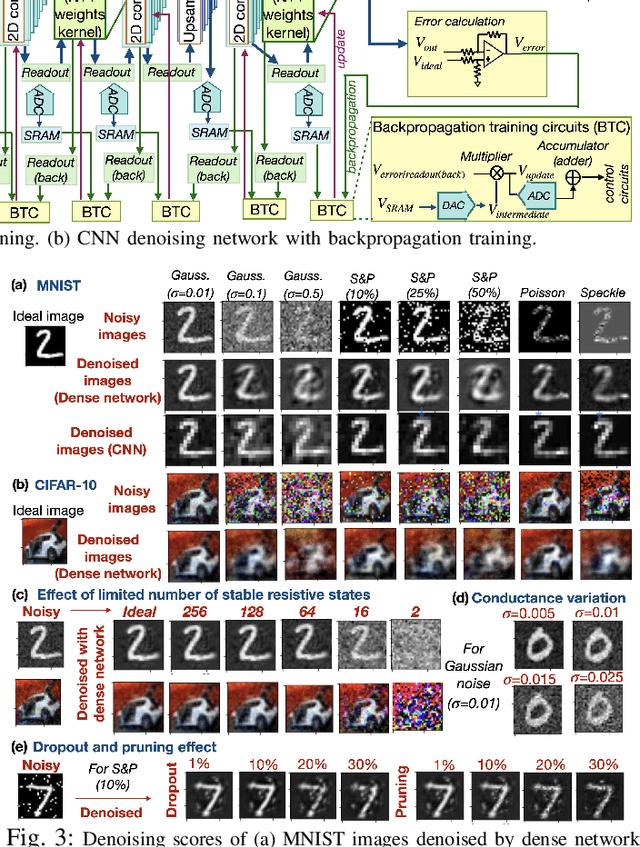
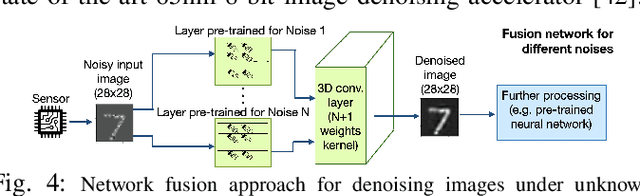
Noise in image sensors led to the development of a whole range of denoising filters. A noisy image can become hard to recognize and often require several types of post-processing compensation circuits. This paper proposes an adaptive denoising system implemented using an analog in-memory neural computing network. The proposed method can learn new noises and can be integrated into or alone with CMOS image sensors. Three denoising network configurations are implemented namely, (1) single layer network, (2) convolution network, and (3) fusion network. The single layer network shows the processing time, energy consumption, and on-chip area of 3.2us, 21nJ per image, and 0.3mm^2 respectively, meanwhile, the convolution denoising network correspondingly shows 72ms, 236uJ, and 0.48mm^2. Among all the implemented networks, it is observed that performance metrics SSIM, MSE, and PSNR show a maximum improvement of 3.61, 21.7, and 7.7 times respectively.
High-Resolution GAN Inversion for Degraded Images in Large Diverse Datasets
Feb 07, 2023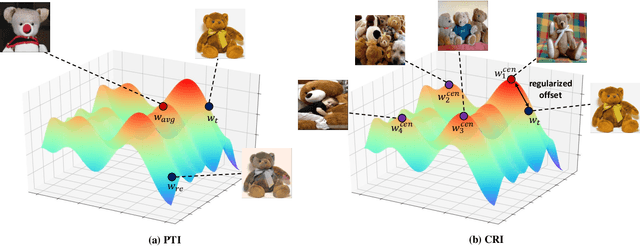
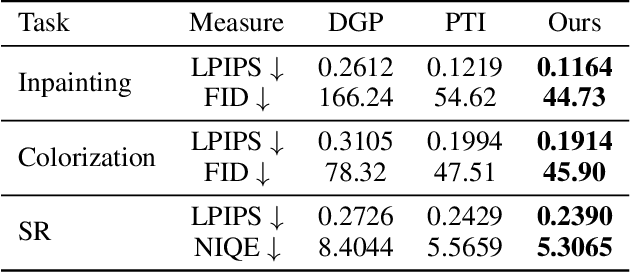

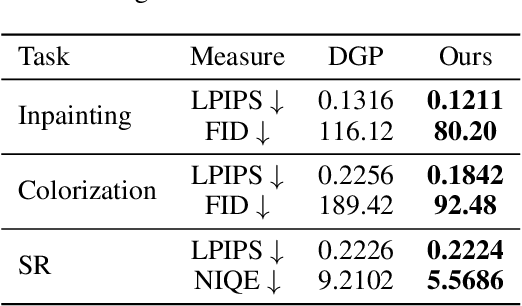
The last decades are marked by massive and diverse image data, which shows increasingly high resolution and quality. However, some images we obtained may be corrupted, affecting the perception and the application of downstream tasks. A generic method for generating a high-quality image from the degraded one is in demand. In this paper, we present a novel GAN inversion framework that utilizes the powerful generative ability of StyleGAN-XL for this problem. To ease the inversion challenge with StyleGAN-XL, Clustering \& Regularize Inversion (CRI) is proposed. Specifically, the latent space is firstly divided into finer-grained sub-spaces by clustering. Instead of initializing the inversion with the average latent vector, we approximate a centroid latent vector from the clusters, which generates an image close to the input image. Then, an offset with a regularization term is introduced to keep the inverted latent vector within a certain range. We validate our CRI scheme on multiple restoration tasks (i.e., inpainting, colorization, and super-resolution) of complex natural images, and show preferable quantitative and qualitative results. We further demonstrate our technique is robust in terms of data and different GAN models. To our best knowledge, we are the first to adopt StyleGAN-XL for generating high-quality natural images from diverse degraded inputs. Code is available at https://github.com/Booooooooooo/CRI.
5th Place Solution to Kaggle Google Universal Image Embedding Competition
Oct 18, 2022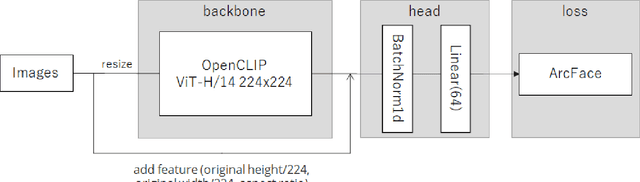
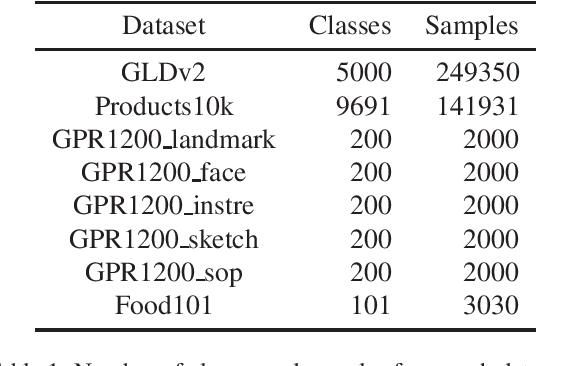
In this paper, we present our solution, which placed 5th in the kaggle Google Universal Image Embedding Competition in 2022. We use the ViT-H visual encoder of CLIP from the openclip repository as a backbone and train a head model composed of BatchNormalization and Linear layers using ArcFace. The dataset used was a subset of products10K, GLDv2, GPR1200, and Food101. And applying TTA for part of images also improves the score. With this method, we achieve a score of 0.684 on the public and 0.688 on the private leaderboard. Our code is available. https://github.com/riron1206/kaggle-Google-Universal-Image-Embedding-Competition-5th-Place-Solution
Revisiting Image Pyramid Structure for High Resolution Salient Object Detection
Sep 26, 2022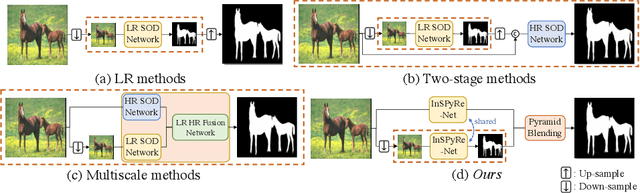
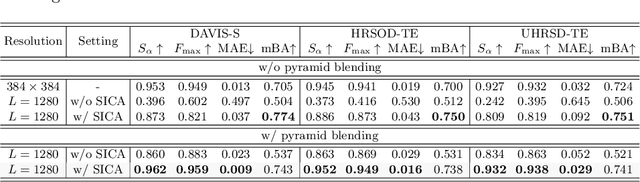

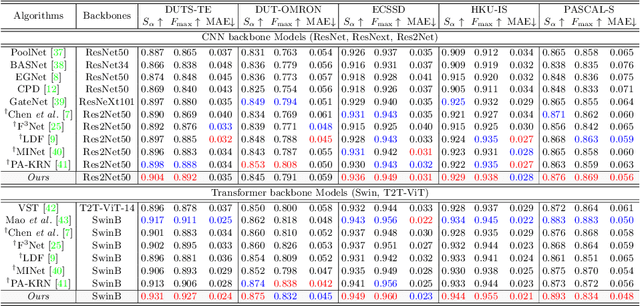
Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images and annotations. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluations on public LR and HR SOD benchmarks demonstrate that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.