 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Guided Semantic Alignment for Feature Fusion Networks
Jun 12, 2026Feature fusion networks are fundamental components in modern object detectors, aggregating multi-scale features to detect objects of varying sizes. However, directly fusing features from different pyramid levels often introduces semantic inconsistency due to their heterogeneous representations. In this paper, we propose Feature Interaction NEtwork (FINE), a lightweight semantic alignment module that refines low-level features via high-level contextual guidance using cross-level attention prior to fusion. To bridge the structural gap and ensure computational efficiency, we introduce an Alignment-Aware Token Sampling that aligns corresponding spatial regions across scales, reducing the attention complexity by an order of magnitude. The resulting attention weights generate a spatial-channel modulation map that is upsampled and applied to the low-level features via residual element-wise modulation. This mechanism ensures that the network selectively enhances semantically relevant pixels while preserving the sub-pixel localization accuracy necessary for dense prediction tasks. FINE is generally applicable to various detectors and consistently improves detection accuracy without compromising efficiency.
Hybrid Adaptive Kalman Filtering for Data-Efficient Joint Tracking and Classification
Jun 01, 2026Kalman filtering performance is highly sensitive to model mismatch and noise covariance tuning. Learning-based approaches address these limitations but typically rely on supervised training with large datasets and do not produce consistent uncertainty estimates. In this paper, we propose a self-supervised Hybrid Adaptive Kalman Filter that learns structured corrections to system dynamics and process noise covariance from measurements alone while preserving the probabilistic structure of the filter. This allows the innovation likelihood to be computed and subsequently used for model classification via generalized Bayesian inference. Experimental results on real-world and simulated datasets demonstrate improved estimation accuracy and statistical consistency as well as robust classification performance across both low-data and large-data scenarios.
AnyDepth-DETR/-YOLO: Any-depth object detection with a single network
May 10, 2026Modern object detectors are static, fixed-depth networks optimized for a single operating point, requiring separate models for different deployment scenarios. We present an any-depth detection framework that enables a single network to span a continuous range of accuracy--efficiency trade-offs by controlling depth at inference time without retraining. Each backbone and neck stage is divided into an essential path, which always executes, and a skippable refinement path; this decomposition preserves the full multi-scale feature hierarchy at every depth configuration, unlike conventional early exiting that discards entire stages. To train such a network, jointly optimizing many sub-networks of varying depth introduces conflicting gradient signals. We address this via self-distillation between only the two extremes, with prediction-level and feature-level alignment losses that enforce stage-wise modularity, ensuring the outputs of each stage remain compatible regardless of the paths taken. Instantiated on RT-DETR and YOLOv12, our full-depth configurations match or surpass their respective SOTA baselines with negligible parameter overhead, while the most efficient configurations achieve up to $1.82\times$ speedup at a cost of only 2.0 AP, all from a single set of weights.
IMPACT: Industrial Machine Perception via Acoustic Cognitive Transformer
Jul 09, 2025



Acoustic signals from industrial machines offer valuable insights for anomaly detection, predictive maintenance, and operational efficiency enhancement. However, existing task-specific, supervised learning methods often scale poorly and fail to generalize across diverse industrial scenarios, whose acoustic characteristics are distinct from general audio. Furthermore, the scarcity of accessible, large-scale datasets and pretrained models tailored for industrial audio impedes community-driven research and benchmarking. To address these challenges, we introduce DINOS (Diverse INdustrial Operation Sounds), a large-scale open-access dataset. DINOS comprises over 74,149 audio samples (exceeding 1,093 hours) collected from various industrial acoustic scenarios. We also present IMPACT (Industrial Machine Perception via Acoustic Cognitive Transformer), a novel foundation model for industrial machine sound analysis. IMPACT is pretrained on DINOS in a self-supervised manner. By jointly optimizing utterance and frame-level losses, it captures both global semantics and fine-grained temporal structures. This makes its representations suitable for efficient fine-tuning on various industrial downstream tasks with minimal labeled data. Comprehensive benchmarking across 30 distinct downstream tasks (spanning four machine types) demonstrates that IMPACT outperforms existing models on 24 tasks, establishing its superior effectiveness and robustness, while providing a new performance benchmark for future research.
Self-Corrective Task Planning by Inverse Prompting with Large Language Models
Mar 10, 2025In robot task planning, large language models (LLMs) have shown significant promise in generating complex and long-horizon action sequences. However, it is observed that LLMs often produce responses that sound plausible but are not accurate. To address these problems, existing methods typically employ predefined error sets or external knowledge sources, requiring human efforts and computation resources. Recently, self-correction approaches have emerged, where LLM generates and refines plans, identifying errors by itself. Despite their effectiveness, they are more prone to failures in correction due to insufficient reasoning. In this paper, we introduce InversePrompt, a novel self-corrective task planning approach that leverages inverse prompting to enhance interpretability. Our method incorporates reasoning steps to provide clear, interpretable feedback. It generates inverse actions corresponding to the initially generated actions and verifies whether these inverse actions can restore the system to its original state, explicitly validating the logical coherence of the generated plans. The results on benchmark datasets show an average 16.3% higher success rate over existing LLM-based task planning methods. Our approach offers clearer justifications for feedback in real-world environments, resulting in more successful task completion than existing self-correction approaches across various scenarios.
RDMM: Fine-Tuned LLM Models for On-Device Robotic Decision Making with Enhanced Contextual Awareness in Specific Domains
Jan 28, 2025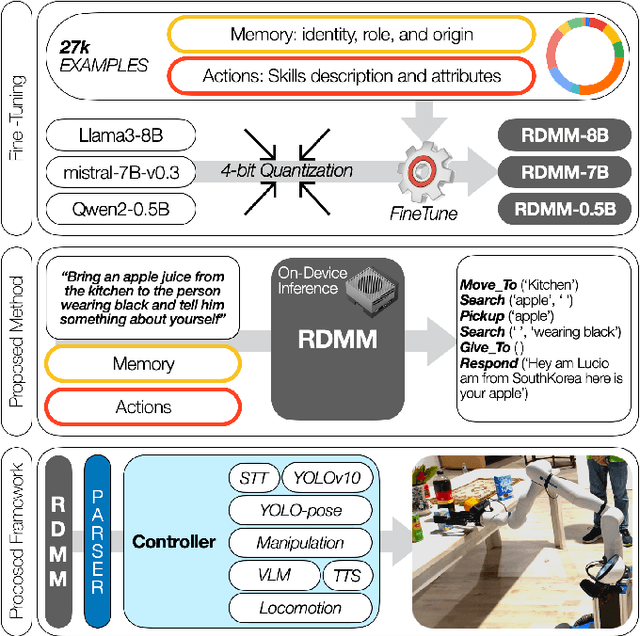
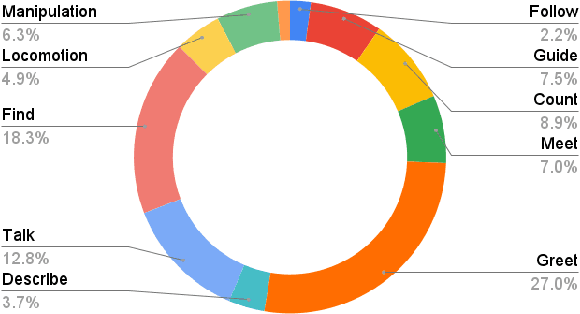


Large language models (LLMs) represent a significant advancement in integrating physical robots with AI-driven systems. We showcase the capabilities of our framework within the context of the real-world household competition. This research introduces a framework that utilizes RDMM (Robotics Decision-Making Models), which possess the capacity for decision-making within domain-specific contexts, as well as an awareness of their personal knowledge and capabilities. The framework leverages information to enhance the autonomous decision-making of the system. In contrast to other approaches, our focus is on real-time, on-device solutions, successfully operating on hardware with as little as 8GB of memory. Our framework incorporates visual perception models equipping robots with understanding of their environment. Additionally, the framework has integrated real-time speech recognition capabilities, thus enhancing the human-robot interaction experience. Experimental results demonstrate that the RDMM framework can plan with an 93\% accuracy. Furthermore, we introduce a new dataset consisting of 27k planning instances, as well as 1.3k text-image annotated samples derived from the competition. The framework, benchmarks, datasets, and models developed in this work are publicly available on our GitHub repository at https://github.com/shadynasrat/RDMM.
Rao-Blackwellized POMDP Planning
Sep 24, 2024



Partially Observable Markov Decision Processes (POMDPs) provide a structured framework for decision-making under uncertainty, but their application requires efficient belief updates. Sequential Importance Resampling Particle Filters (SIRPF), also known as Bootstrap Particle Filters, are commonly used as belief updaters in large approximate POMDP solvers, but they face challenges such as particle deprivation and high computational costs as the system's state dimension grows. To address these issues, this study introduces Rao-Blackwellized POMDP (RB-POMDP) approximate solvers and outlines generic methods to apply Rao-Blackwellization in both belief updates and online planning. We compare the performance of SIRPF and Rao-Blackwellized Particle Filters (RBPF) in a simulated localization problem where an agent navigates toward a target in a GPS-denied environment using POMCPOW and RB-POMCPOW planners. Our results not only confirm that RBPFs maintain accurate belief approximations over time with fewer particles, but, more surprisingly, RBPFs combined with quadrature-based integration improve planning quality significantly compared to SIRPF-based planning under the same computational limits.
Simplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Apr 29, 2024



Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.
Learning a Patent-Informed Biomedical Knowledge Graph Reveals Technological Potential of Drug Repositioning Candidates
Sep 04, 2023
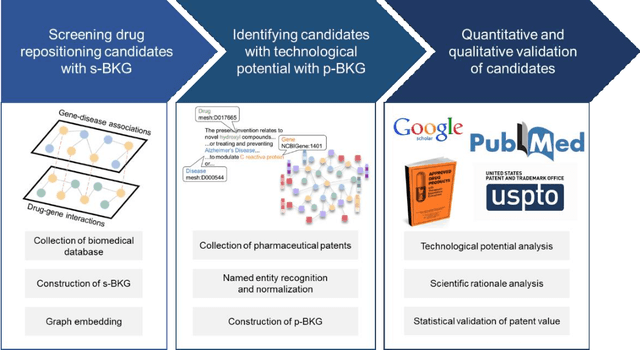
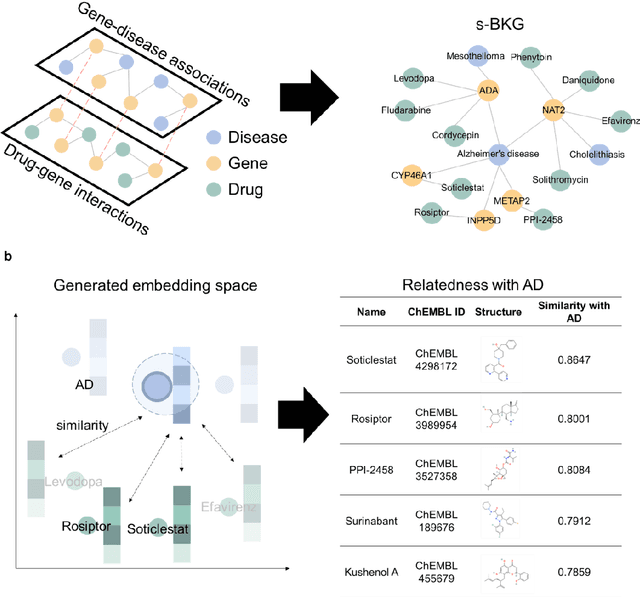
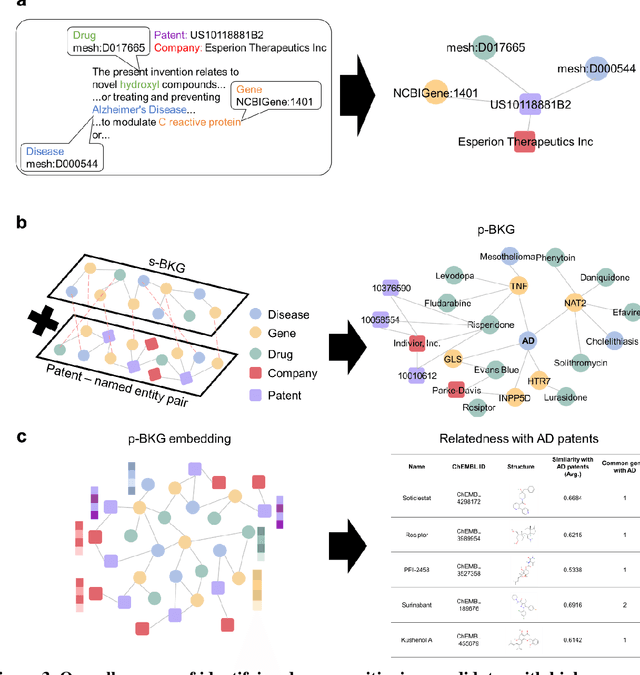
Drug repositioning-a promising strategy for discovering new therapeutic uses for existing drugs-has been increasingly explored in the computational science literature using biomedical databases. However, the technological potential of drug repositioning candidates has often been overlooked. This study presents a novel protocol to comprehensively analyse various sources such as pharmaceutical patents and biomedical databases, and identify drug repositioning candidates with both technological potential and scientific evidence. To this end, first, we constructed a scientific biomedical knowledge graph (s-BKG) comprising relationships between drugs, diseases, and genes derived from biomedical databases. Our protocol involves identifying drugs that exhibit limited association with the target disease but are closely located in the s-BKG, as potential drug candidates. We constructed a patent-informed biomedical knowledge graph (p-BKG) by adding pharmaceutical patent information. Finally, we developed a graph embedding protocol to ascertain the structure of the p-BKG, thereby calculating the relevance scores of those candidates with target disease-related patents to evaluate their technological potential. Our case study on Alzheimer's disease demonstrates its efficacy and feasibility, while the quantitative outcomes and systematic methods are expected to bridge the gap between computational discoveries and successful market applications in drug repositioning research.
Revisiting Image Pyramid Structure for High Resolution Salient Object Detection
Sep 26, 2022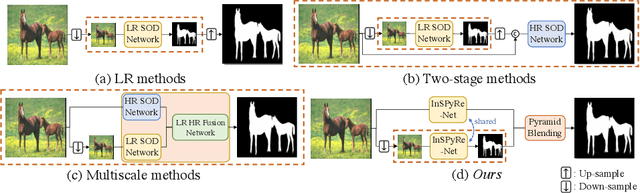
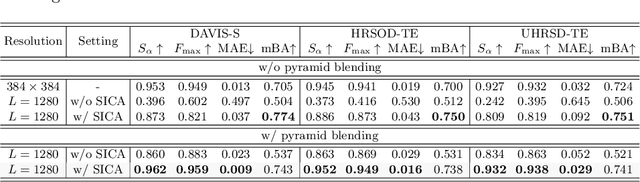

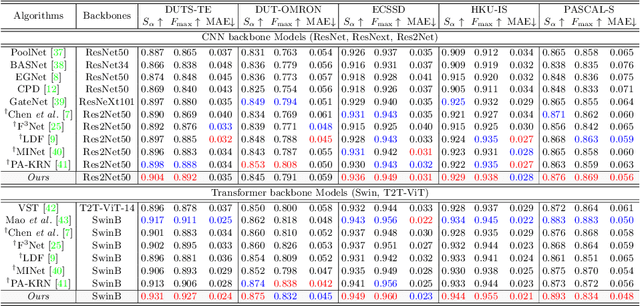
Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images and annotations. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluations on public LR and HR SOD benchmarks demonstrate that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.