 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based Document Layout Generation
Mar 19, 2023
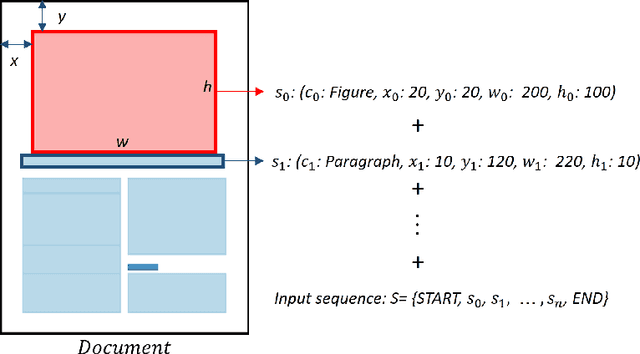
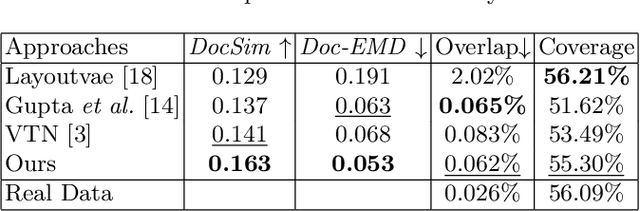

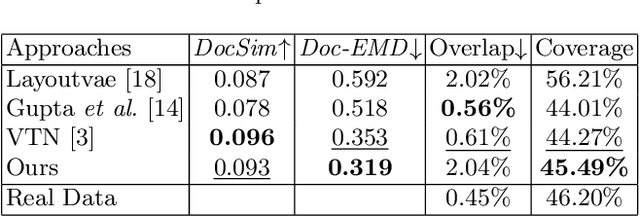
We develop a diffusion-based approach for various document layout sequence generation. Layout sequences specify the contents of a document design in an explicit format. Our novel diffusion-based approach works in the sequence domain rather than the image domain in order to permit more complex and realistic layouts. We also introduce a new metric, Document Earth Mover's Distance (Doc-EMD). By considering similarity between heterogeneous categories document designs, we handle the shortcomings of prior document metrics that only evaluate the same category of layouts. Our empirical analysis shows that our diffusion-based approach is comparable to or outperforming other previous methods for layout generation across various document datasets. Moreover, our metric is capable of differentiating documents better than previous metrics for specific cases.
Image Quality Assessment: Learning to Rank Image Distortion Level
Aug 04, 2022
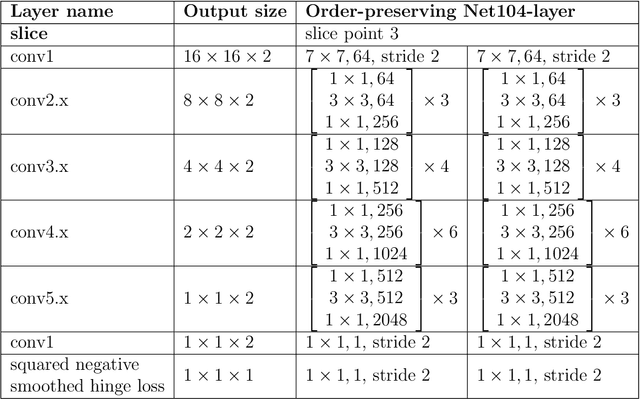
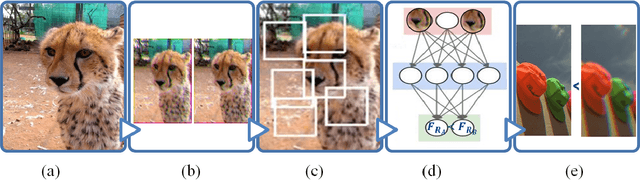

Over the years, various algorithms were developed, attempting to imitate the Human Visual System (HVS), and evaluate the perceptual image quality. However, for certain image distortions, the functionality of the HVS continues to be an enigma, and echoing its behavior remains a challenge (especially for ill-defined distortions). In this paper, we learn to compare the image quality of two registered images, with respect to a chosen distortion. Our method takes advantage of the fact that at times, simulating image distortion and later evaluating its relative image quality, is easier than assessing its absolute value. Thus, given a pair of images, we look for an optimal dimensional reduction function that will map each image to a numerical score, so that the scores will reflect the image quality relation (i.e., a less distorted image will receive a lower score). We look for an optimal dimensional reduction mapping in the form of a Deep Neural Network which minimizes the violation of image quality order. Subsequently, we extend the method to order a set of images by utilizing the predicted level of the chosen distortion. We demonstrate the validity of our method on Latent Chromatic Aberration and Moire distortions, on synthetic and real datasets.
CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning
Mar 08, 2023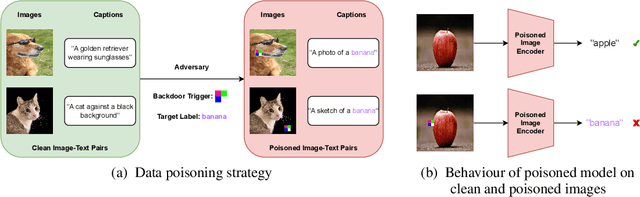

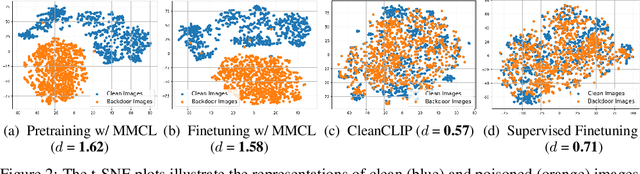

Multimodal contrastive pretraining has been used to train multimodal representation models, such as CLIP, on large amounts of paired image-text data. However, previous studies have revealed that such models are vulnerable to backdoor attacks. Specifically, when trained on backdoored examples, CLIP learns spurious correlations between the embedded backdoor trigger and the target label, aligning their representations in the joint embedding space. Injecting even a small number of poisoned examples, such as 75 examples in 3 million pretraining data, can significantly manipulate the model's behavior, making it difficult to detect or unlearn such correlations. To address this issue, we propose CleanCLIP, a finetuning framework that weakens the learned spurious associations introduced by backdoor attacks by independently re-aligning the representations for individual modalities. We demonstrate that unsupervised finetuning using a combination of multimodal contrastive and unimodal self-supervised objectives for individual modalities can significantly reduce the impact of the backdoor attack. Additionally, we show that supervised finetuning on task-specific labeled image data removes the backdoor trigger from the CLIP vision encoder. We show empirically that CleanCLIP maintains model performance on benign examples while erasing a range of backdoor attacks on multimodal contrastive learning.
CoreDiff: Contextual Error-Modulated Generalized Diffusion Model for Low-Dose CT Denoising and Generalization
Apr 04, 2023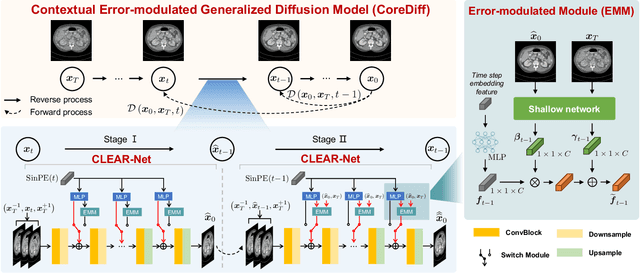
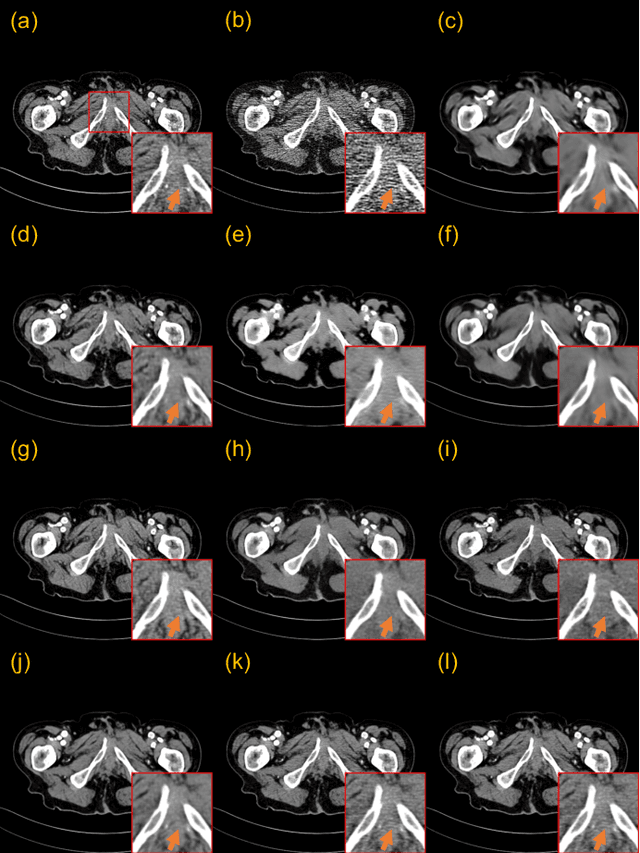
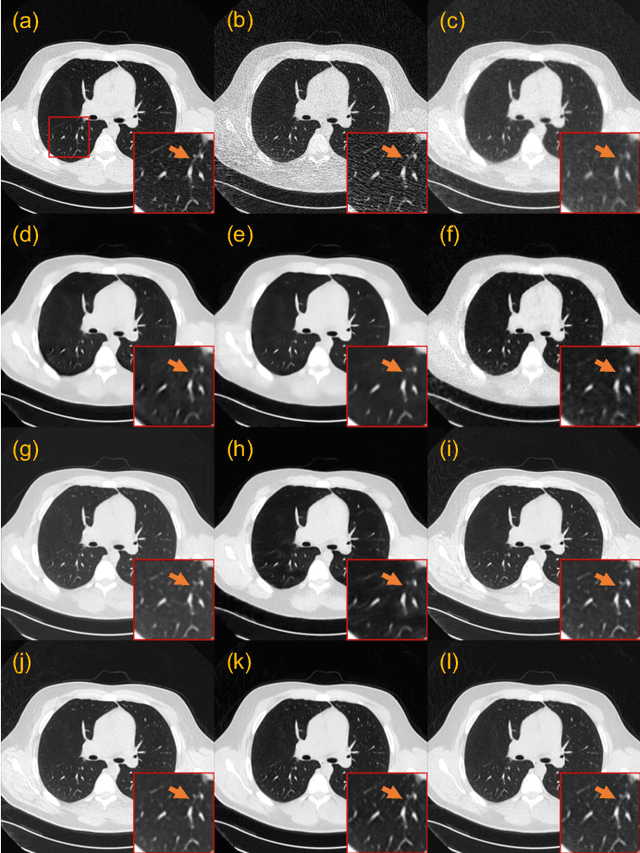

Low-dose computed tomography (CT) images suffer from noise and artifacts due to photon starvation and electronic noise. Recently, some works have attempted to use diffusion models to address the over-smoothness and training instability encountered by previous deep-learning-based denoising models. However, diffusion models suffer from long inference times due to the large number of sampling steps involved. Very recently, cold diffusion model generalizes classical diffusion models and has greater flexibility. Inspired by the cold diffusion, this paper presents a novel COntextual eRror-modulated gEneralized Diffusion model for low-dose CT (LDCT) denoising, termed CoreDiff. First, CoreDiff utilizes LDCT images to displace the random Gaussian noise and employs a novel mean-preserving degradation operator to mimic the physical process of CT degradation, significantly reducing sampling steps thanks to the informative LDCT images as the starting point of the sampling process. Second, to alleviate the error accumulation problem caused by the imperfect restoration operator in the sampling process, we propose a novel ContextuaL Error-modulAted Restoration Network (CLEAR-Net), which can leverage contextual information to constrain the sampling process from structural distortion and modulate time step embedding features for better alignment with the input at the next time step. Third, to rapidly generalize to a new, unseen dose level with as few resources as possible, we devise a one-shot learning framework to make CoreDiff generalize faster and better using only a single LDCT image (un)paired with NDCT. Extensive experimental results on two datasets demonstrate that our CoreDiff outperforms competing methods in denoising and generalization performance, with a clinically acceptable inference time.
Weakly Supervised Realtime Dynamic Background Subtraction
Mar 06, 2023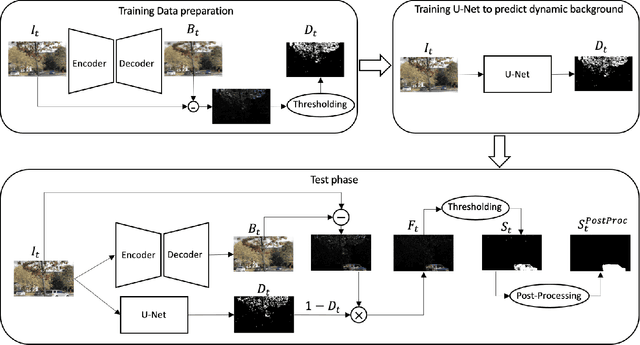
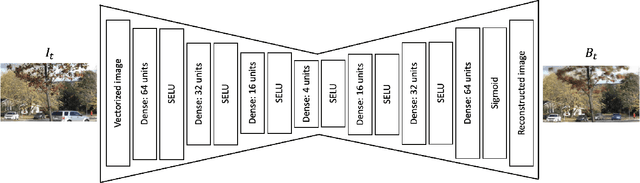

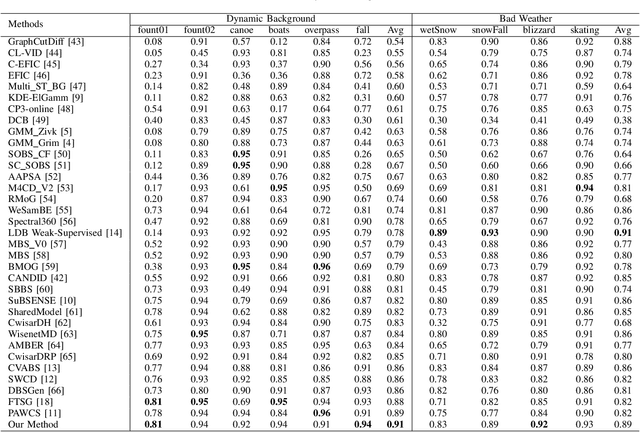
Background subtraction is a fundamental task in computer vision with numerous real-world applications, ranging from object tracking to video surveillance. Dynamic backgrounds poses a significant challenge here. Supervised deep learning-based techniques are currently considered state-of-the-art for this task. However, these methods require pixel-wise ground-truth labels, which can be time-consuming and expensive. In this work, we propose a weakly supervised framework that can perform background subtraction without requiring per-pixel ground-truth labels. Our framework is trained on a moving object-free sequence of images and comprises two networks. The first network is an autoencoder that generates background images and prepares dynamic background images for training the second network. The dynamic background images are obtained by thresholding the background-subtracted images. The second network is a U-Net that uses the same object-free video for training and the dynamic background images as pixel-wise ground-truth labels. During the test phase, the input images are processed by the autoencoder and U-Net, which generate background and dynamic background images, respectively. The dynamic background image helps remove dynamic motion from the background-subtracted image, enabling us to obtain a foreground image that is free of dynamic artifacts. To demonstrate the effectiveness of our method, we conducted experiments on selected categories of the CDnet 2014 dataset and the I2R dataset. Our method outperformed all top-ranked unsupervised methods. We also achieved better results than one of the two existing weakly supervised methods, and our performance was similar to the other. Our proposed method is online, real-time, efficient, and requires minimal frame-level annotation, making it suitable for a wide range of real-world applications.
Enhancing Border Security and Countering Terrorism Through Computer Vision: a Field of Artificial Intelligence
Mar 06, 2023Border security had been a persistent problem in international border especially when it get to the issue of preventing illegal movement of weapons, contraband, drugs, and combating issue of illegal or undocumented immigrant while at the same time ensuring that lawful trade, economic prosperity coupled with national sovereignty across the border is maintained. In this research work, we used open source computer vision (Open CV) and adaboost algorithm to develop a model which can detect a moving object a far off, classify it, automatically snap full image and face of the individual separately, and then run a background check on them against worldwide databases while making a prediction about an individual being a potential threat, intending immigrant, potential terrorists or extremist and then raise sound alarm. Our model can be deployed on any camera device and be mounted at any international border. There are two stages involved, we first developed a model based on open CV computer vision algorithm, with the ability to detect human movement from afar, it will automatically snap both the face and the full image of the person separately, and the second stage is the automatic triggering of background check against the moving object. This ensures it check the moving object against several databases worldwide and is able to determine the admissibility of the person afar off. If the individual is inadmissible, it will automatically alert the border officials with the image of the person and other details, and if the bypass the border officials, the system is able to detect and alert the authority with his images and other details. All these operations will be done afar off by the AI powered camera before the individual reach the border
* 10 pages, 8 figures, Conference publication
BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
Nov 18, 2022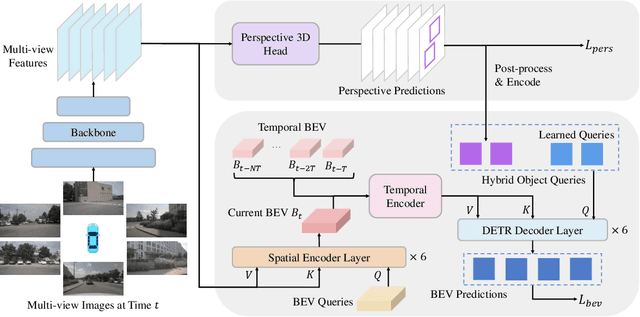
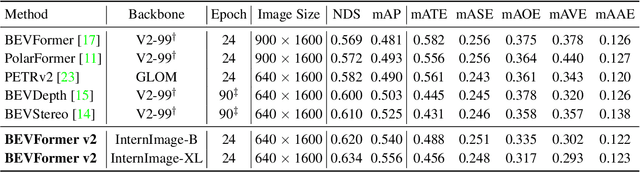
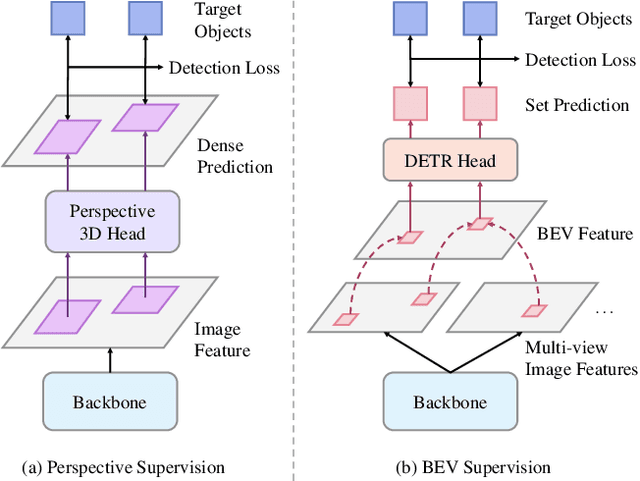
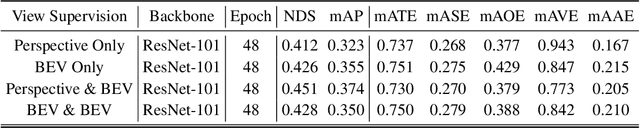
We present a novel bird's-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones. Existing state-of-the-art BEV detectors are often tied to certain depth pre-trained backbones like VoVNet, hindering the synergy between booming image backbones and BEV detectors. To address this limitation, we prioritize easing the optimization of BEV detectors by introducing perspective space supervision. To this end, we propose a two-stage BEV detector, where proposals from the perspective head are fed into the bird's-eye-view head for final predictions. To evaluate the effectiveness of our model, we conduct extensive ablation studies focusing on the form of supervision and the generality of the proposed detector. The proposed method is verified with a wide spectrum of traditional and modern image backbones and achieves new SoTA results on the large-scale nuScenes dataset. The code shall be released soon.
Fine-Grained ImageNet Classification in the Wild
Mar 04, 2023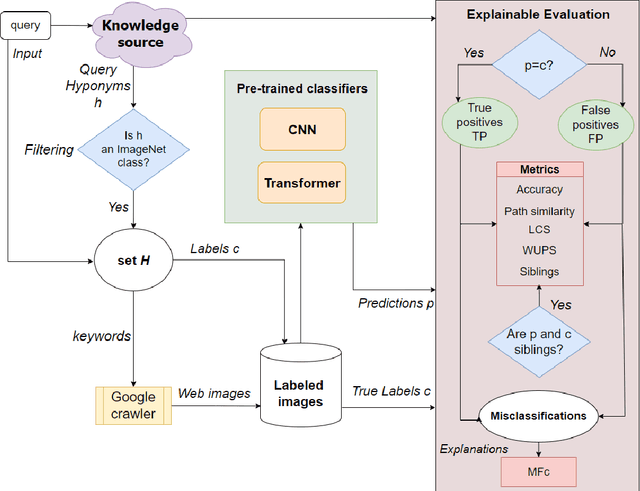
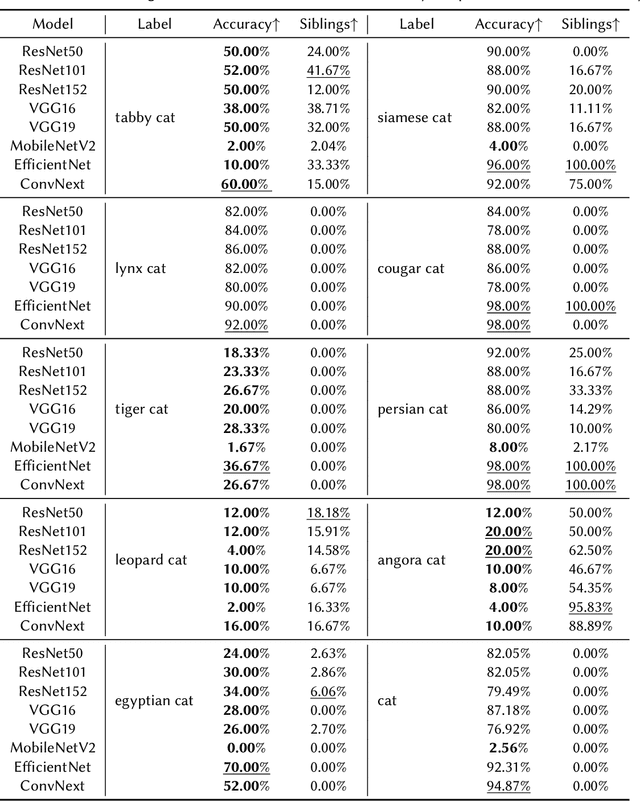
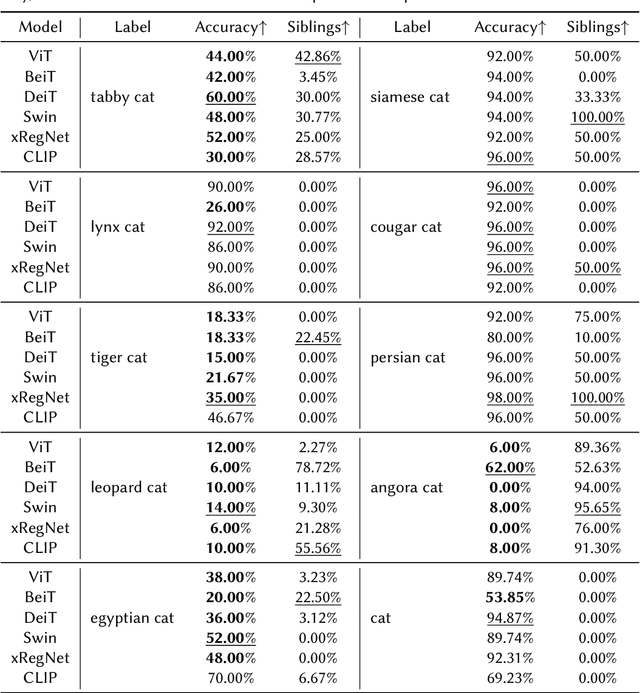
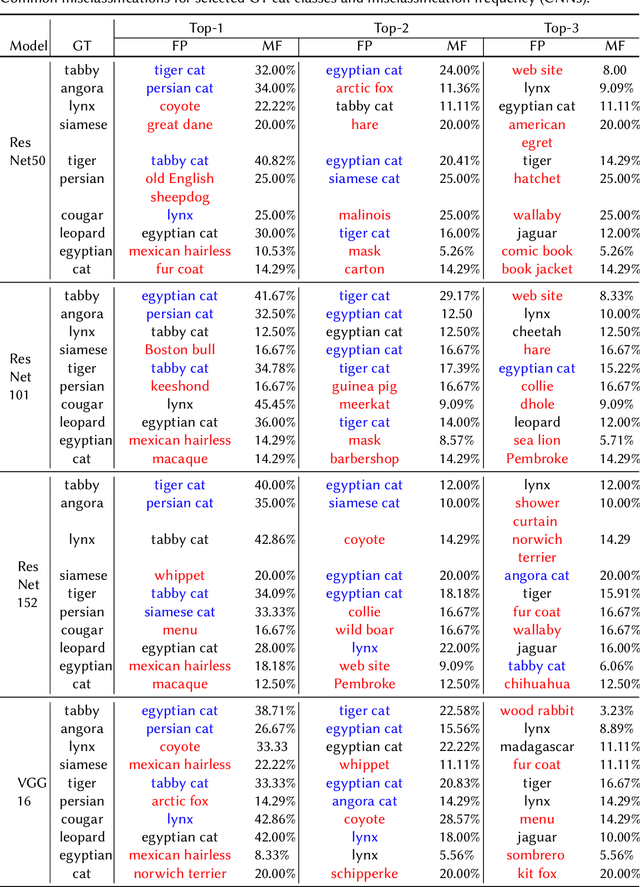
Image classification has been one of the most popular tasks in Deep Learning, seeing an abundance of impressive implementations each year. However, there is a lot of criticism tied to promoting complex architectures that continuously push performance metrics higher and higher. Robustness tests can uncover several vulnerabilities and biases which go unnoticed during the typical model evaluation stage. So far, model robustness under distribution shifts has mainly been examined within carefully curated datasets. Nevertheless, such approaches do not test the real response of classifiers in the wild, e.g. when uncurated web-crawled image data of corresponding classes are provided. In our work, we perform fine-grained classification on closely related categories, which are identified with the help of hierarchical knowledge. Extensive experimentation on a variety of convolutional and transformer-based architectures reveals model robustness in this novel setting. Finally, hierarchical knowledge is again employed to evaluate and explain misclassifications, providing an information-rich evaluation scheme adaptable to any classifier.
SDF-3DGAN: A 3D Object Generative Method Based on Implicit Signed Distance Function
Mar 13, 2023

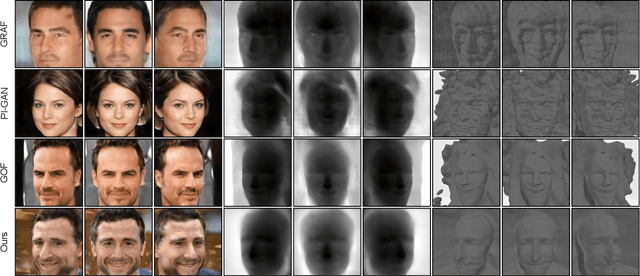

In this paper, we develop a new method, termed SDF-3DGAN, for 3D object generation and 3D-Aware image synthesis tasks, which introduce implicit Signed Distance Function (SDF) as the 3D object representation method in the generative field. We apply SDF for higher quality representation of 3D object in space and design a new SDF neural renderer, which has higher efficiency and higher accuracy. To train only on 2D images, we first generate the objects, which are represented by SDF, from Gaussian distribution. Then we render them to 2D images and use them to apply GAN training method together with 2D images in the dataset. In the new rendering method, we relieve all the potential of SDF mathematical property to alleviate computation pressure in the previous SDF neural renderer. In specific, our new SDF neural renderer can solve the problem of sampling ambiguity when the number of sampling point is not enough, \ie use the less points to finish higher quality sampling task in the rendering pipeline. And in this rendering pipeline, we can locate the surface easily. Therefore, we apply normal loss on it to control the smoothness of generated object surface, which can make our method enjoy the much higher generation quality. Quantitative and qualitative experiments conducted on public benchmarks demonstrate favorable performance against the state-of-the-art methods in 3D object generation task and 3D-Aware image synthesis task. Our codes will be released at https://github.com/lutao2021/SDF-3DGAN.
Modelos Generativos basados en Mecanismos de Difusión
Feb 18, 2023Diffusion-based generative models are a design framework that allows generating new images from processes analogous to those found in non-equilibrium thermodynamics. These models model the reversal of a physical diffusion process in which two miscible liquids of different colors progressively mix until they form a homogeneous mixture. Diffusion models can be applied to signals of a different nature, such as audio and image signals. In the image case, a progressive pixel corruption process is carried out by applying random noise, and a neural network is trained to revert each one of the corruption steps. For the reconstruction process to be reversible, it is necessary to carry out the corruption very progressively. If the training of the neural network is successful, it will be possible to generate an image from random noise by chaining a number of steps similar to those used for image deconstruction at training time. In this article we present the theoretical foundations on which this method is based as well as some of its applications. This article is in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.