 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
Apr 06, 2023

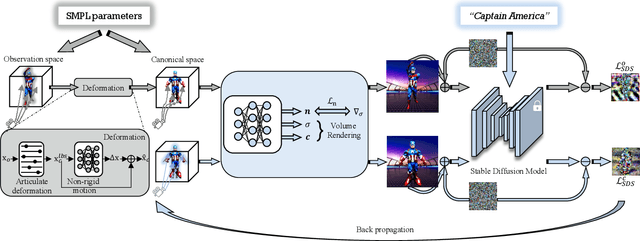


We present DreamAvatar, a text-and-shape guided framework for generating high-quality 3D human avatars with controllable poses. While encouraging results have been produced by recent methods on text-guided 3D common object generation, generating high-quality human avatars remains an open challenge due to the complexity of the human body's shape, pose, and appearance. We propose DreamAvatar to tackle this challenge, which utilizes a trainable NeRF for predicting density and color features for 3D points and a pre-trained text-to-image diffusion model for providing 2D self-supervision. Specifically, we leverage SMPL models to provide rough pose and shape guidance for the generation. We introduce a dual space design that comprises a canonical space and an observation space, which are related by a learnable deformation field through the NeRF, allowing for the transfer of well-optimized texture and geometry from the canonical space to the target posed avatar. Additionally, we exploit a normal-consistency regularization to allow for more vivid generation with detailed geometry and texture. Through extensive evaluations, we demonstrate that DreamAvatar significantly outperforms existing methods, establishing a new state-of-the-art for text-and-shape guided 3D human generation.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 15, 2023
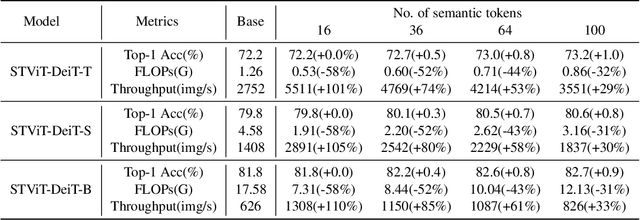
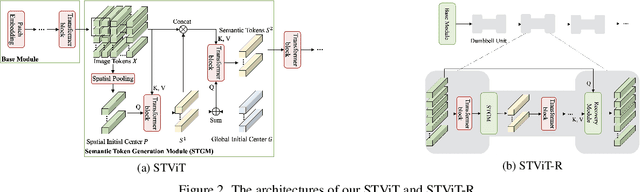
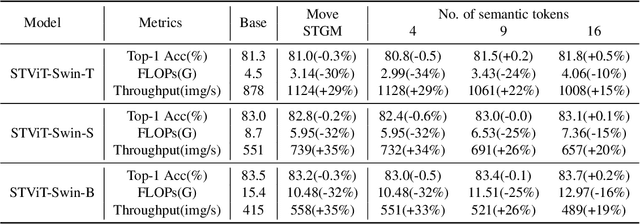
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone.
Towards Flexible Multi-modal Document Models
Mar 31, 2023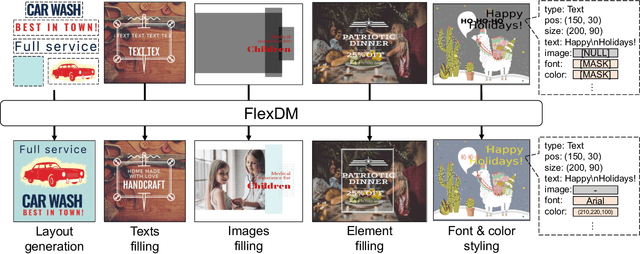
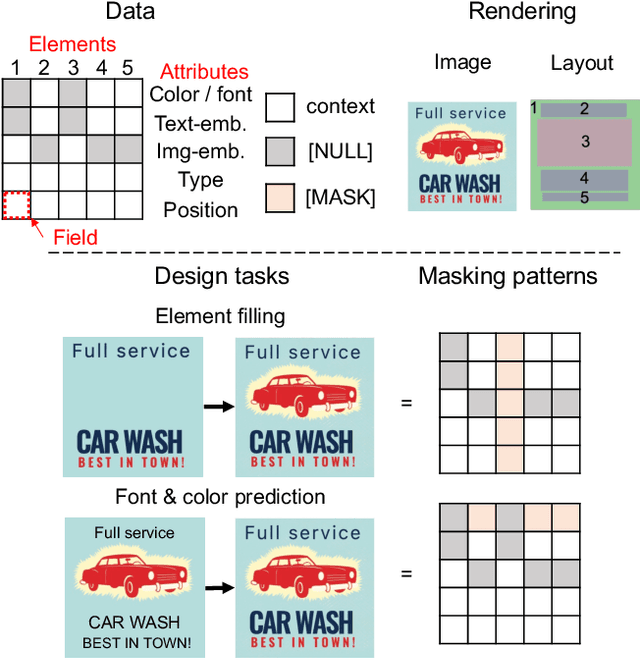
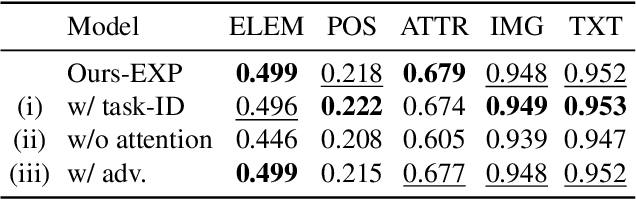
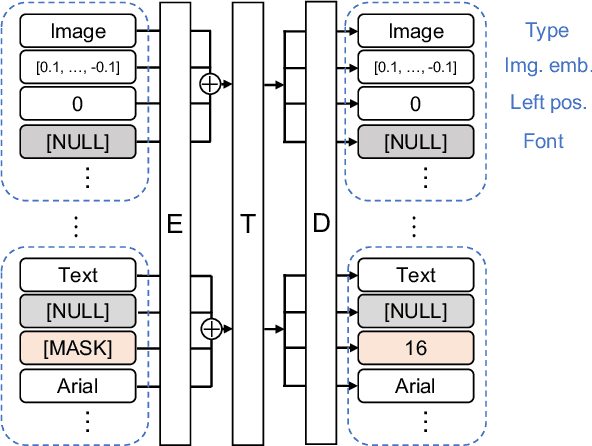
Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.
MoGDE: Boosting Mobile Monocular 3D Object Detection with Ground Depth Estimation
Mar 23, 2023
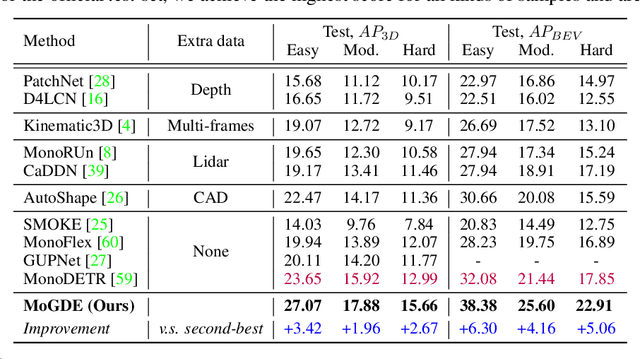
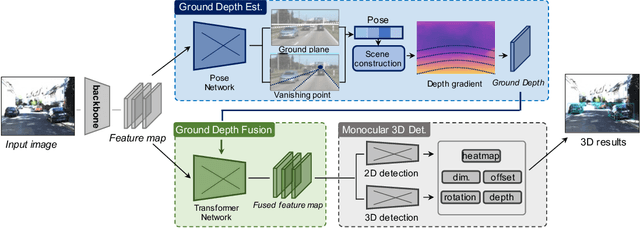
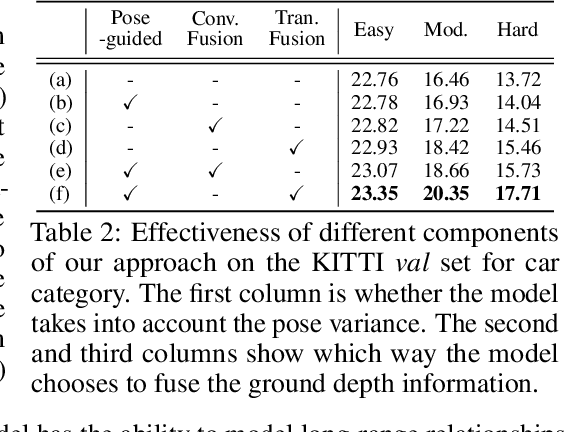
Monocular 3D object detection (Mono3D) in mobile settings (e.g., on a vehicle, a drone, or a robot) is an important yet challenging task. Due to the near-far disparity phenomenon of monocular vision and the ever-changing camera pose, it is hard to acquire high detection accuracy, especially for far objects. Inspired by the insight that the depth of an object can be well determined according to the depth of the ground where it stands, in this paper, we propose a novel Mono3D framework, called MoGDE, which constantly estimates the corresponding ground depth of an image and then utilizes the estimated ground depth information to guide Mono3D. To this end, we utilize a pose detection network to estimate the pose of the camera and then construct a feature map portraying pixel-level ground depth according to the 3D-to-2D perspective geometry. Moreover, to improve Mono3D with the estimated ground depth, we design an RGB-D feature fusion network based on the transformer structure, where the long-range self-attention mechanism is utilized to effectively identify ground-contacting points and pin the corresponding ground depth to the image feature map. We conduct extensive experiments on the real-world KITTI dataset. The results demonstrate that MoGDE can effectively improve the Mono3D accuracy and robustness for both near and far objects. MoGDE yields the best performance compared with the state-of-the-art methods by a large margin and is ranked number one on the KITTI 3D benchmark.
FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction
Apr 04, 2023
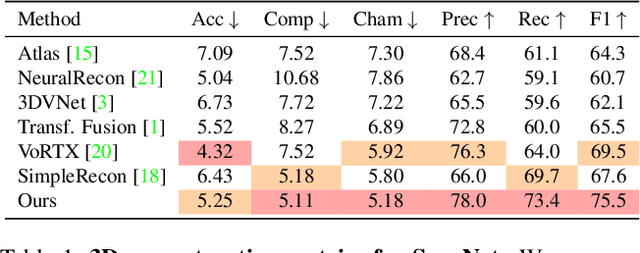
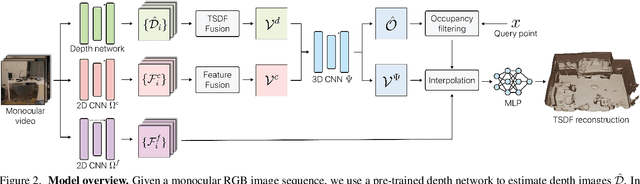
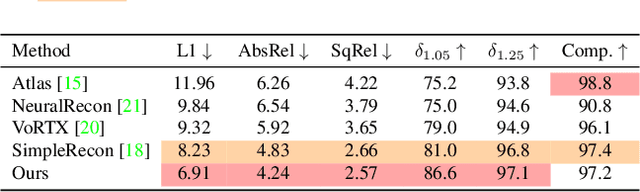
Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work. We then introduce a depth guidance strategy using multi-view depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. Our method produces smooth and highly accurate reconstructions, showing significant improvements across multiple depth and 3D reconstruction metrics.
Universal Deep Image Compression via Content-Adaptive Optimization with Adapters
Nov 02, 2022
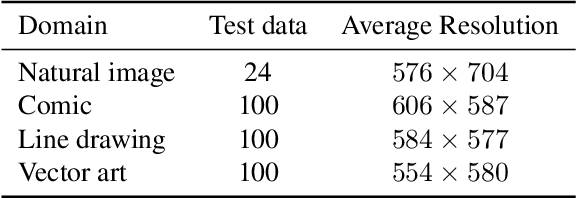
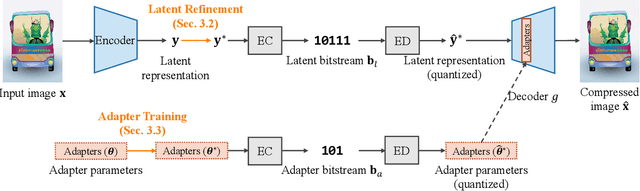
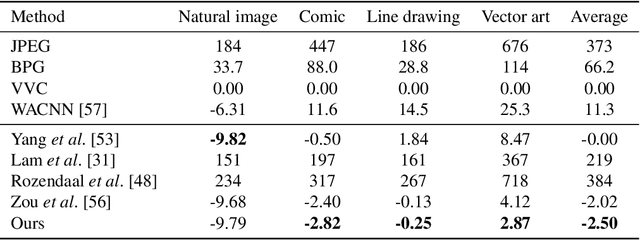
Deep image compression performs better than conventional codecs, such as JPEG, on natural images. However, deep image compression is learning-based and encounters a problem: the compression performance deteriorates significantly for out-of-domain images. In this study, we highlight this problem and address a novel task: universal deep image compression. This task aims to compress images belonging to arbitrary domains, such as natural images, line drawings, and comics. To address this problem, we propose a content-adaptive optimization framework; this framework uses a pre-trained compression model and adapts the model to a target image during compression. Adapters are inserted into the decoder of the model. For each input image, our framework optimizes the latent representation extracted by the encoder and the adapter parameters in terms of rate-distortion. The adapter parameters are additionally transmitted per image. For the experiments, a benchmark dataset containing uncompressed images of four domains (natural images, line drawings, comics, and vector arts) is constructed and the proposed universal deep compression is evaluated. Finally, the proposed model is compared with non-adaptive and existing adaptive compression models. The comparison reveals that the proposed model outperforms these. The code and dataset are publicly available at https://github.com/kktsubota/universal-dic.
EPVT: Environment-aware Prompt Vision Transformer for Domain Generalization in Skin Lesion Recognition
Apr 09, 2023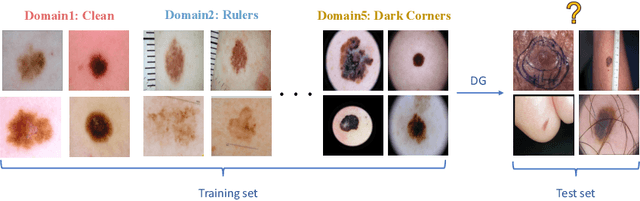
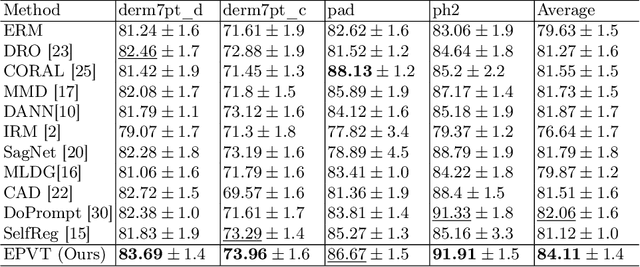
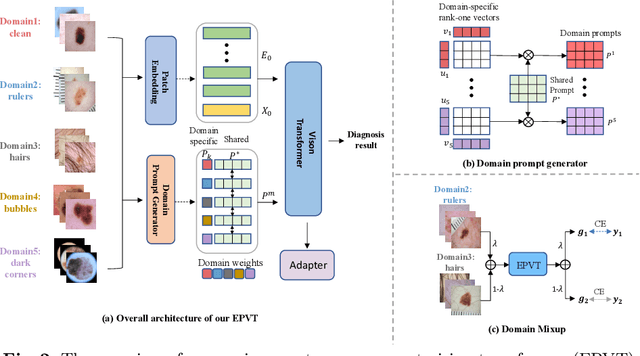
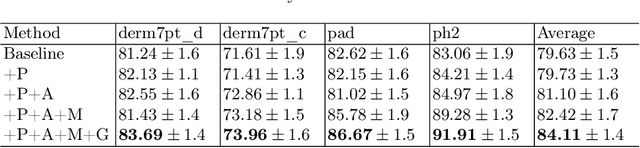
Skin lesion recognition using deep learning has made remarkable progress, and there is an increasing need for deploying these systems in real-world scenarios. However, recent research has revealed that deep neural networks for skin lesion recognition may overly depend on disease-irrelevant image artifacts (i.e. dark corners, dense hairs), leading to poor generalization in unseen environments. To address this issue, we propose a novel domain generalization method called EPVT, which involves embedding prompts into the vision transformer to collaboratively learn knowledge from diverse domains. Concretely, EPVT leverages a set of domain prompts, each of which plays as a domain expert, to capture domain-specific knowledge; and a shared prompt for general knowledge over the entire dataset. To facilitate knowledge sharing and the interaction of different prompts, we introduce a domain prompt generator that enables low-rank multiplicative updates between domain prompts and the shared prompt. A domain mixup strategy is additionally devised to reduce the co-occurring artifacts in each domain, which allows for more flexible decision margins and mitigates the issue of incorrectly assigned domain labels. Experiments on four out-of-distribution datasets and six different biased ISIC datasets demonstrate the superior generalization ability of EPVT in skin lesion recognition across various environments. Our code and dataset will be released at https://github.com/SiyuanYan1/EPVT.
Medical Image Retrieval via Nearest Neighbor Search on Pre-trained Image Features
Oct 05, 2022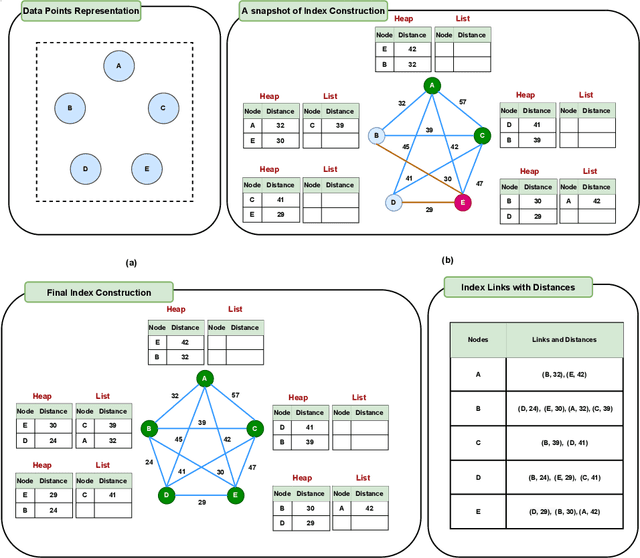

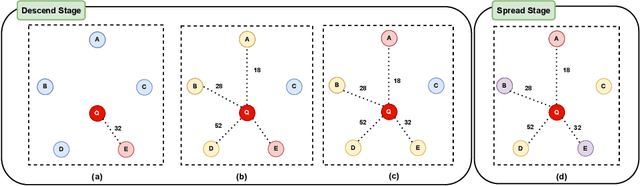
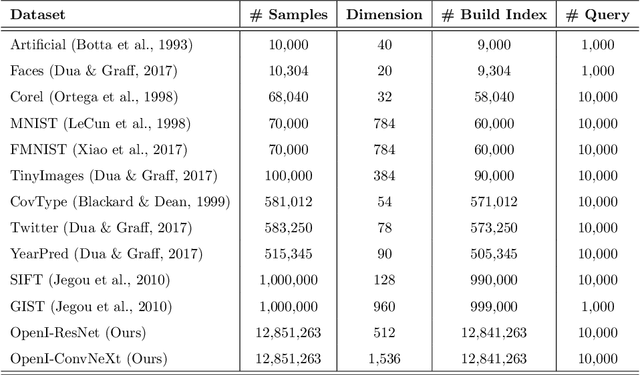
Nearest neighbor search (NNS) aims to locate the points in high-dimensional space that is closest to the query point. The brute-force approach for finding the nearest neighbor becomes computationally infeasible when the number of points is large. The NNS has multiple applications in medicine, such as searching large medical imaging databases, disease classification, diagnosis, etc. With a focus on medical imaging, this paper proposes DenseLinkSearch an effective and efficient algorithm that searches and retrieves the relevant images from heterogeneous sources of medical images. Towards this, given a medical database, the proposed algorithm builds the index that consists of pre-computed links of each point in the database. The search algorithm utilizes the index to efficiently traverse the database in search of the nearest neighbor. We extensively tested the proposed NNS approach and compared the performance with state-of-the-art NNS approaches on benchmark datasets and our created medical image datasets. The proposed approach outperformed the existing approach in terms of retrieving accurate neighbors and retrieval speed. We also explore the role of medical image feature representation in content-based medical image retrieval tasks. We propose a Transformer-based feature representation technique that outperformed the existing pre-trained Transformer approach on CLEF 2011 medical image retrieval task. The source code of our experiments are available at https://github.com/deepaknlp/DLS.
LMR: A Large-Scale Multi-Reference Dataset for Reference-based Super-Resolution
Mar 09, 2023
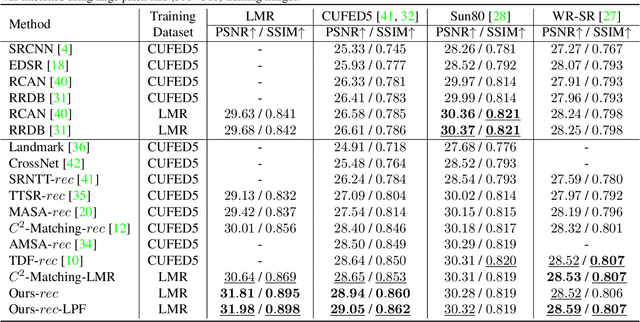

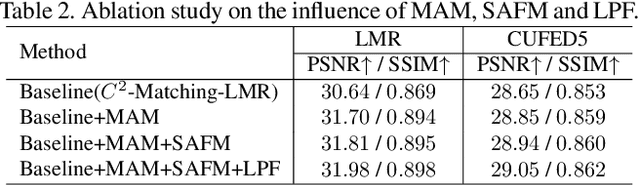
It is widely agreed that reference-based super-resolution (RefSR) achieves superior results by referring to similar high quality images, compared to single image super-resolution (SISR). Intuitively, the more references, the better performance. However, previous RefSR methods have all focused on single-reference image training, while multiple reference images are often available in testing or practical applications. The root cause of such training-testing mismatch is the absence of publicly available multi-reference SR training datasets, which greatly hinders research efforts on multi-reference super-resolution. To this end, we construct a large-scale, multi-reference super-resolution dataset, named LMR. It contains 112,142 groups of 300x300 training images, which is 10x of the existing largest RefSR dataset. The image size is also much larger. More importantly, each group is equipped with 5 reference images with different similarity levels. Furthermore, we propose a new baseline method for multi-reference super-resolution: MRefSR, including a Multi-Reference Attention Module (MAM) for feature fusion of an arbitrary number of reference images, and a Spatial Aware Filtering Module (SAFM) for the fused feature selection. The proposed MRefSR achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations. Our code and data would be made available soon.
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023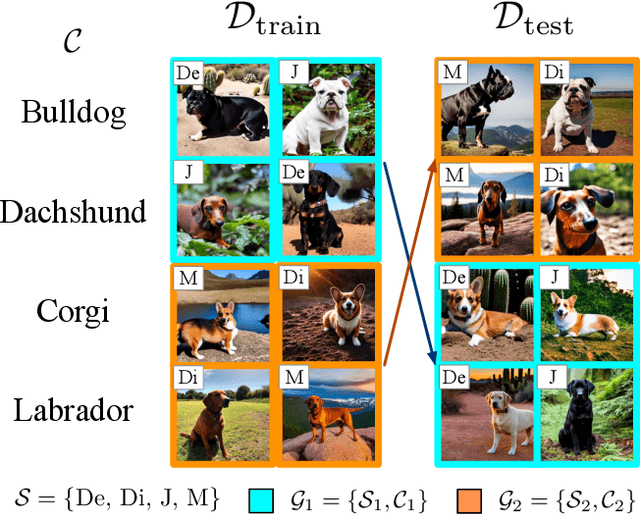
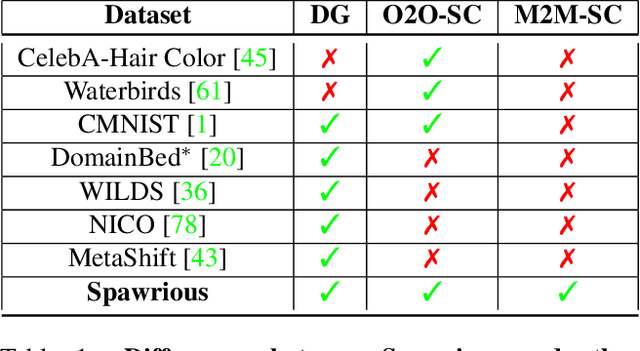

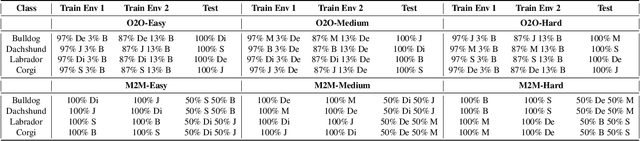
The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.