 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DehazeNeRF: Multiple Image Haze Removal and 3D Shape Reconstruction using Neural Radiance Fields
Mar 20, 2023

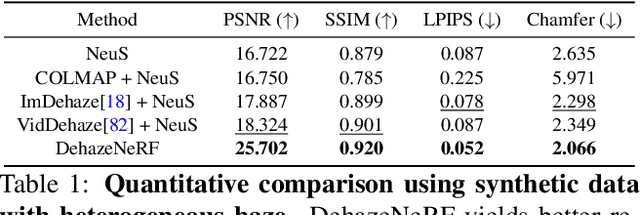
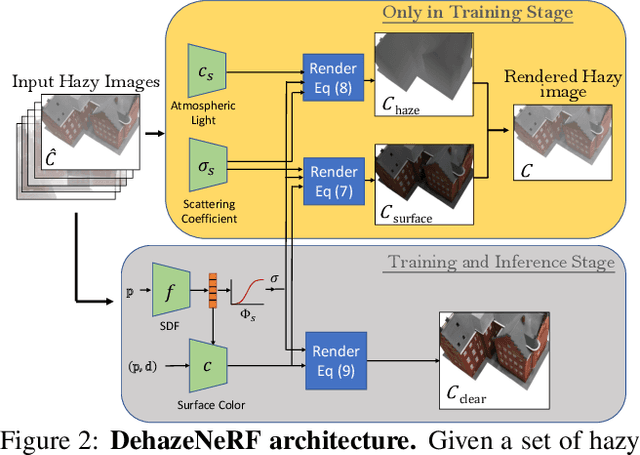
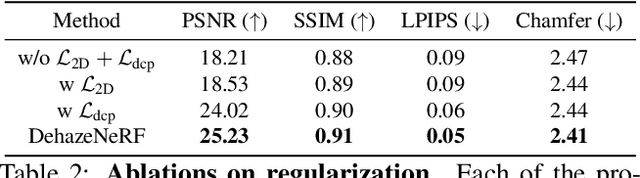
Neural radiance fields (NeRFs) have demonstrated state-of-the-art performance for 3D computer vision tasks, including novel view synthesis and 3D shape reconstruction. However, these methods fail in adverse weather conditions. To address this challenge, we introduce DehazeNeRF as a framework that robustly operates in hazy conditions. DehazeNeRF extends the volume rendering equation by adding physically realistic terms that model atmospheric scattering. By parameterizing these terms using suitable networks that match the physical properties, we introduce effective inductive biases, which, together with the proposed regularizations, allow DehazeNeRF to demonstrate successful multi-view haze removal, novel view synthesis, and 3D shape reconstruction where existing approaches fail.
Reverse Engineering Breast MRIs: Predicting Acquisition Parameters Directly from Images
Mar 08, 2023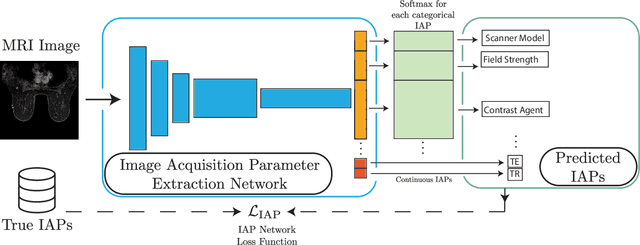
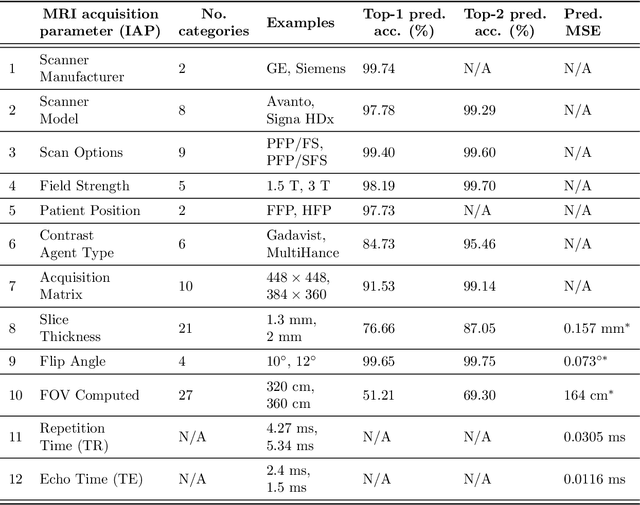
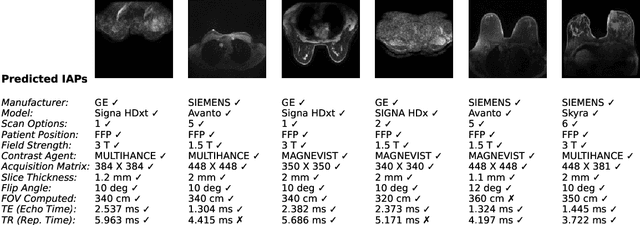

The image acquisition parameters (IAPs) used to create MRI scans are central to defining the appearance of the images. Deep learning models trained on data acquired using certain parameters might not generalize well to images acquired with different parameters. Being able to recover such parameters directly from an image could help determine whether a deep learning model is applicable, and could assist with data harmonization and/or domain adaptation. Here, we introduce a neural network model that can predict many complex IAPs used to generate an MR image with high accuracy solely using the image, with a single forward pass. These predicted parameters include field strength, echo and repetition times, acquisition matrix, scanner model, scan options, and others. Even challenging parameters such as contrast agent type can be predicted with good accuracy. We perform a variety of experiments and analyses of our model's ability to predict IAPs on many MRI scans of new patients, and demonstrate its usage in a realistic application. Predicting IAPs from the images is an important step toward better understanding the relationship between image appearance and IAPs. This in turn will advance the understanding of many concepts related to the generalizability of neural network models on medical images, including domain shift, domain adaptation, and data harmonization.
Iterative Data Refinement for Self-Supervised MR Image Reconstruction
Nov 24, 2022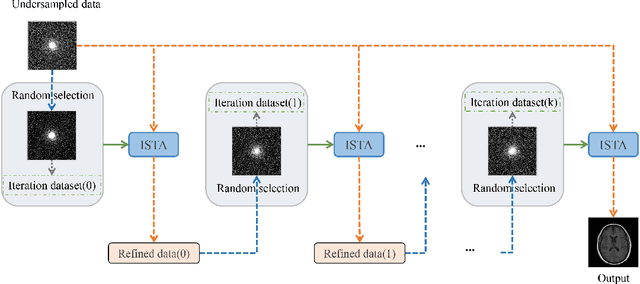
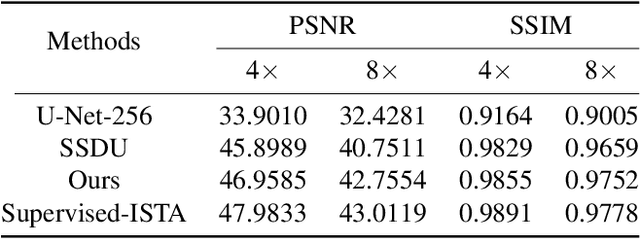
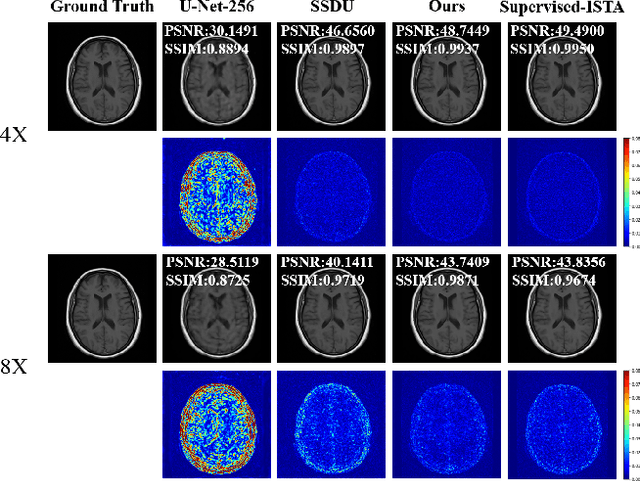
Magnetic Resonance Imaging (MRI) has become an important technique in the clinic for the visualization, detection, and diagnosis of various diseases. However, one bottleneck limitation of MRI is the relatively slow data acquisition process. Fast MRI based on k-space undersampling and high-quality image reconstruction has been widely utilized, and many deep learning-based methods have been developed in recent years. Although promising results have been achieved, most existing methods require fully-sampled reference data for training the deep learning models. Unfortunately, fully-sampled MRI data are difficult if not impossible to obtain in real-world applications. To address this issue, we propose a data refinement framework for self-supervised MR image reconstruction. Specifically, we first analyze the reason of the performance gap between self-supervised and supervised methods and identify that the bias in the training datasets between the two is one major factor. Then, we design an effective self-supervised training data refinement method to reduce this data bias. With the data refinement, an enhanced self-supervised MR image reconstruction framework is developed to prompt accurate MR imaging. We evaluate our method on an in-vivo MRI dataset. Experimental results show that without utilizing any fully sampled MRI data, our self-supervised framework possesses strong capabilities in capturing image details and structures at high acceleration factors.
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023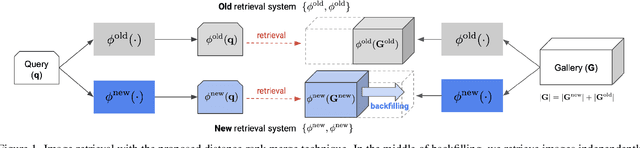
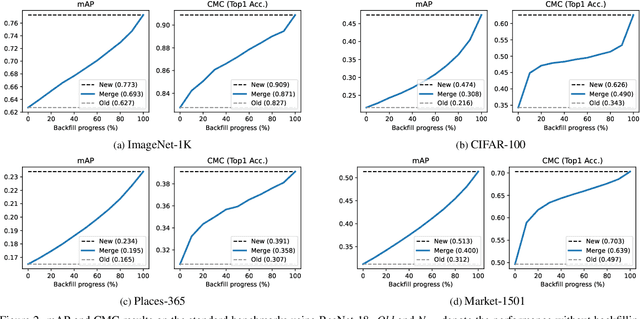
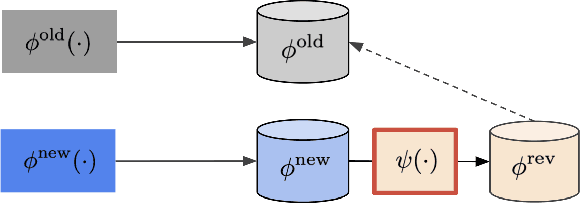
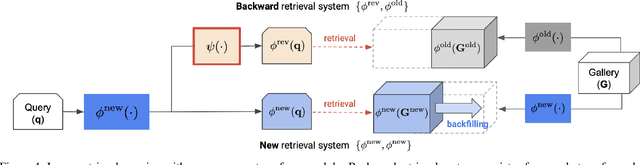
Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
Inverse problem regularization with hierarchical variational autoencoders
Mar 20, 2023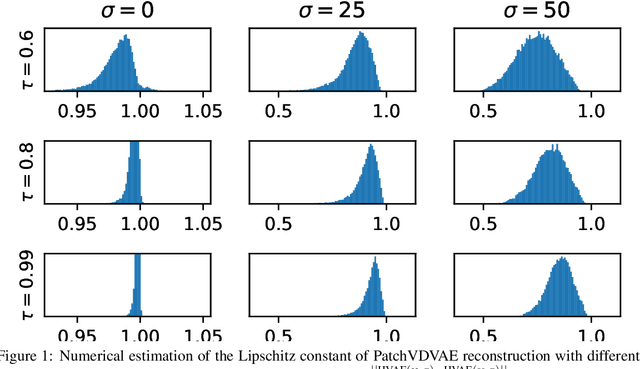
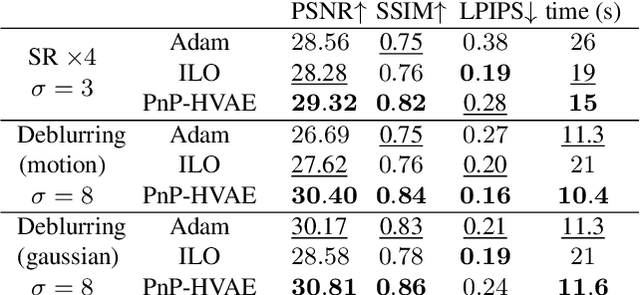
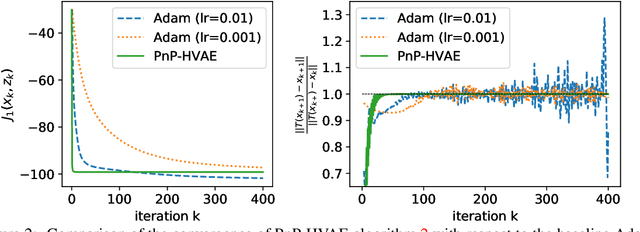
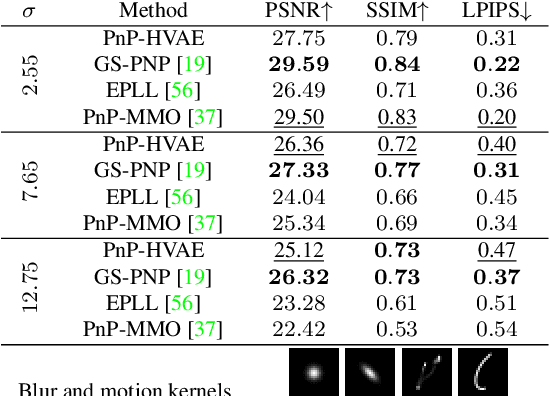
In this paper, we propose to regularize ill-posed inverse problems using a deep hierarchical variational autoencoder (HVAE) as an image prior. The proposed method synthesizes the advantages of i) denoiser-based Plug \& Play approaches and ii) generative model based approaches to inverse problems. First, we exploit VAE properties to design an efficient algorithm that benefits from convergence guarantees of Plug-and-Play (PnP) methods. Second, our approach is not restricted to specialized datasets and the proposed PnP-HVAE model is able to solve image restoration problems on natural images of any size. Our experiments show that the proposed PnP-HVAE method is competitive with both SOTA denoiser-based PnP approaches, and other SOTA restoration methods based on generative models.
BlobGAN-3D: A Spatially-Disentangled 3D-Aware Generative Model for Indoor Scenes
Mar 26, 2023
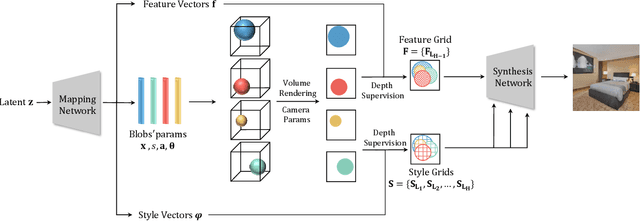
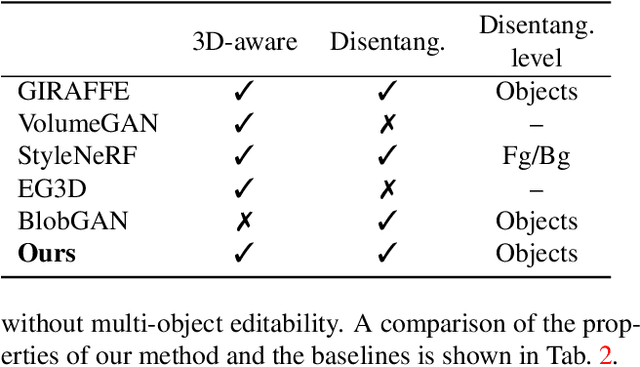

3D-aware image synthesis has attracted increasing interest as it models the 3D nature of our real world. However, performing realistic object-level editing of the generated images in the multi-object scenario still remains a challenge. Recently, a 2D GAN termed BlobGAN has demonstrated great multi-object editing capabilities on real-world indoor scene datasets. In this work, we propose BlobGAN-3D, which is a 3D-aware improvement of the original 2D BlobGAN. We enable explicit camera pose control while maintaining the disentanglement for individual objects in the scene by extending the 2D blobs into 3D blobs. We keep the object-level editing capabilities of BlobGAN and in addition allow flexible control over the 3D location of the objects in the scene. We test our method on real-world indoor datasets and show that our method can achieve comparable image quality compared to the 2D BlobGAN and other 3D-aware GAN baselines while being able to enable camera pose control and object-level editing in the challenging multi-object real-world scenarios.
Shepherding Slots to Objects: Towards Stable and Robust Object-Centric Learning
Mar 31, 2023
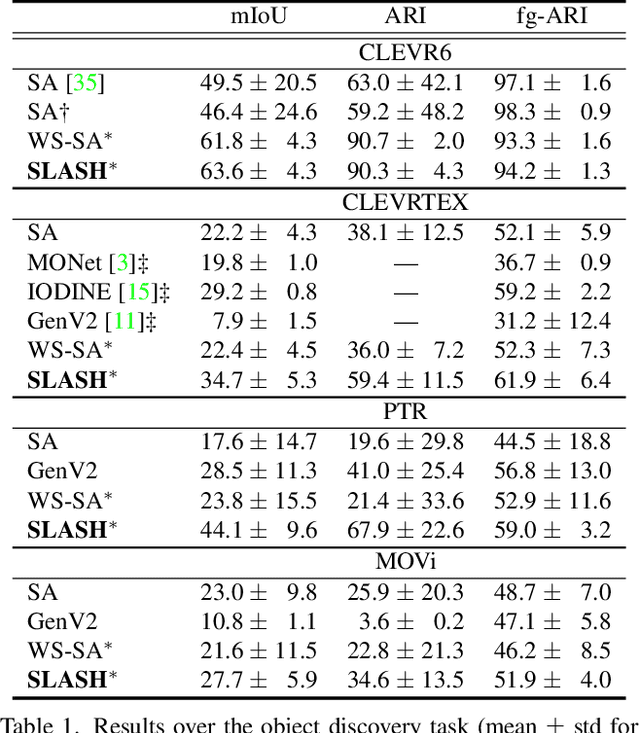
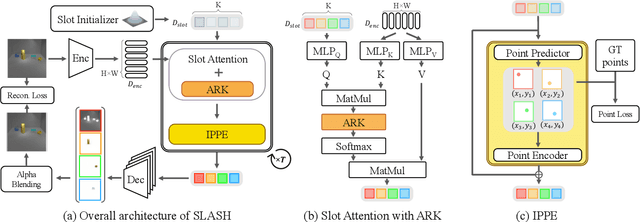
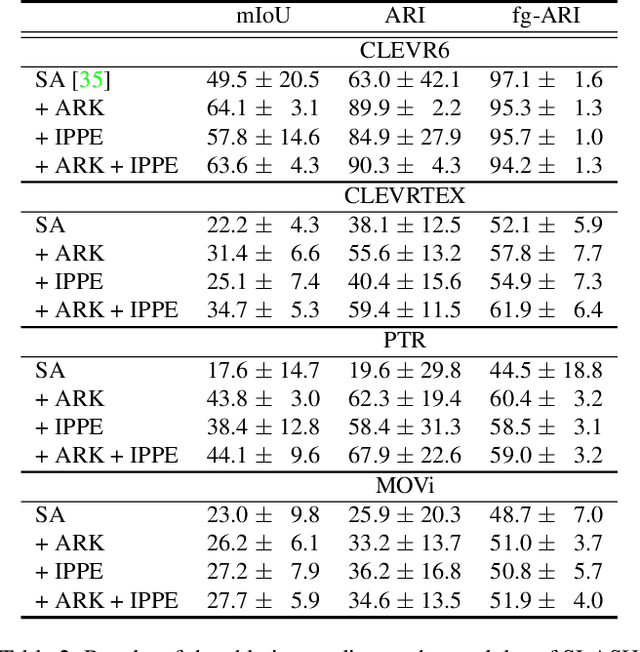
Object-centric learning (OCL) aspires general and compositional understanding of scenes by representing a scene as a collection of object-centric representations. OCL has also been extended to multi-view image and video datasets to apply various data-driven inductive biases by utilizing geometric or temporal information in the multi-image data. Single-view images carry less information about how to disentangle a given scene than videos or multi-view images do. Hence, owing to the difficulty of applying inductive biases, OCL for single-view images remains challenging, resulting in inconsistent learning of object-centric representation. To this end, we introduce a novel OCL framework for single-view images, SLot Attention via SHepherding (SLASH), which consists of two simple-yet-effective modules on top of Slot Attention. The new modules, Attention Refining Kernel (ARK) and Intermediate Point Predictor and Encoder (IPPE), respectively, prevent slots from being distracted by the background noise and indicate locations for slots to focus on to facilitate learning of object-centric representation. We also propose a weak semi-supervision approach for OCL, whilst our proposed framework can be used without any assistant annotation during the inference. Experiments show that our proposed method enables consistent learning of object-centric representation and achieves strong performance across four datasets. Code is available at \url{https://github.com/object-understanding/SLASH}.
Smooth image-to-image translations with latent space interpolations
Oct 03, 2022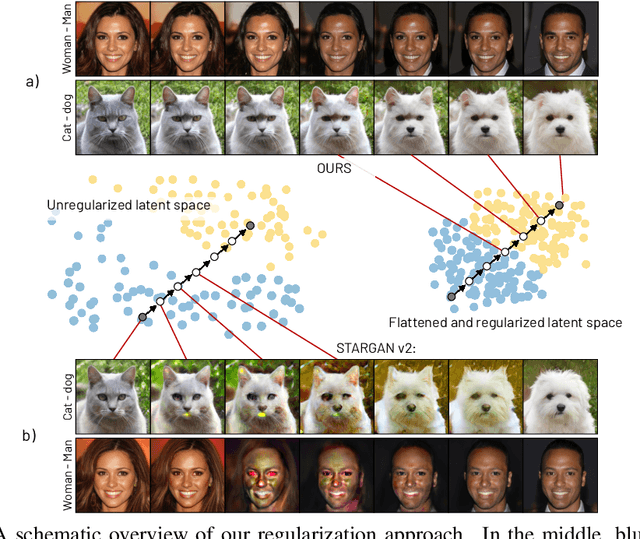
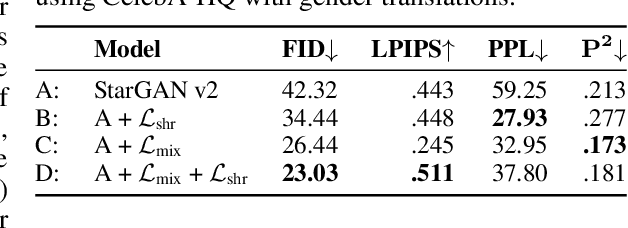
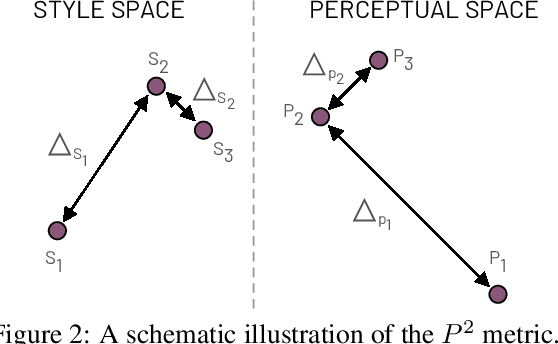
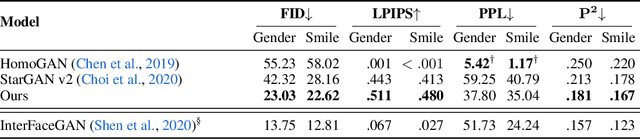
Multi-domain image-to-image (I2I) translations can transform a source image according to the style of a target domain. One important, desired characteristic of these transformations, is their graduality, which corresponds to a smooth change between the source and the target image when their respective latent-space representations are linearly interpolated. However, state-of-the-art methods usually perform poorly when evaluated using inter-domain interpolations, often producing abrupt changes in the appearance or non-realistic intermediate images. In this paper, we argue that one of the main reasons behind this problem is the lack of sufficient inter-domain training data and we propose two different regularization methods to alleviate this issue: a new shrinkage loss, which compacts the latent space, and a Mixup data-augmentation strategy, which flattens the style representations between domains. We also propose a new metric to quantitatively evaluate the degree of the interpolation smoothness, an aspect which is not sufficiently covered by the existing I2I translation metrics. Using both our proposed metric and standard evaluation protocols, we show that our regularization techniques can improve the state-of-the-art multi-domain I2I translations by a large margin. Our code will be made publicly available upon the acceptance of this article.
Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
Apr 03, 2023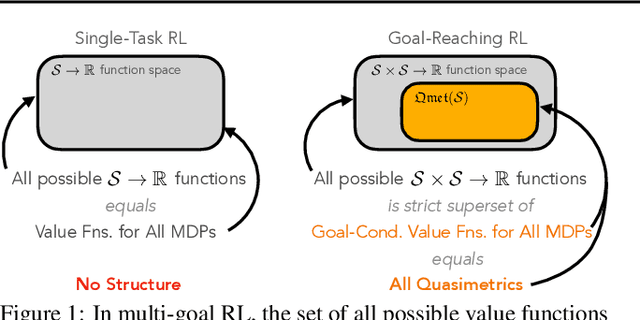
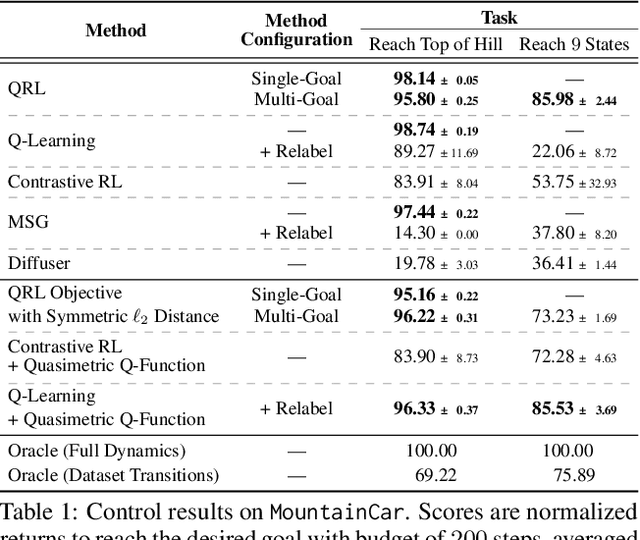
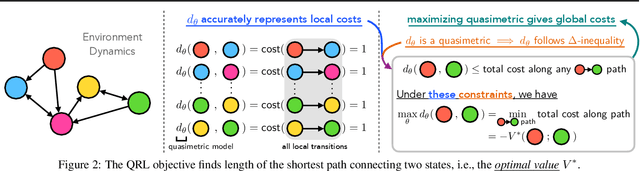
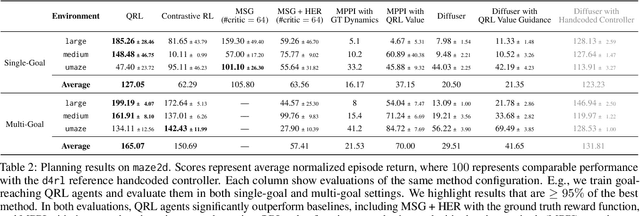
In goal-reaching reinforcement learning (RL), the optimal value function has a particular geometry, called quasimetric structure. This paper introduces Quasimetric Reinforcement Learning (QRL), a new RL method that utilizes quasimetric models to learn optimal value functions. Distinct from prior approaches, the QRL objective is specifically designed for quasimetrics, and provides strong theoretical recovery guarantees. Empirically, we conduct thorough analyses on a discretized MountainCar environment, identifying properties of QRL and its advantages over alternatives. On offline and online goal-reaching benchmarks, QRL also demonstrates improved sample efficiency and performance, across both state-based and image-based observations.
Stare at What You See: Masked Image Modeling without Reconstruction
Nov 16, 2022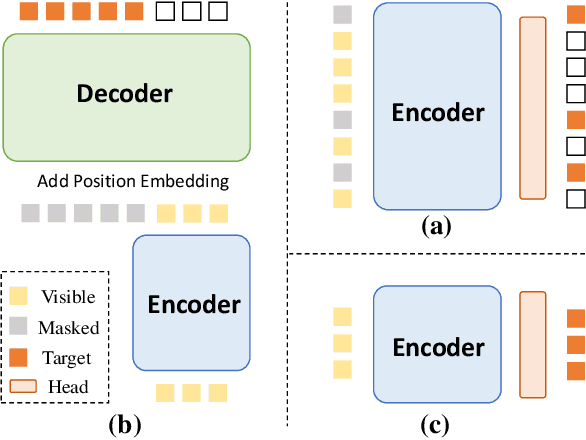
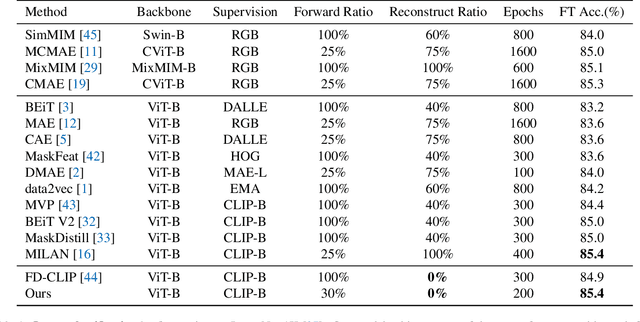
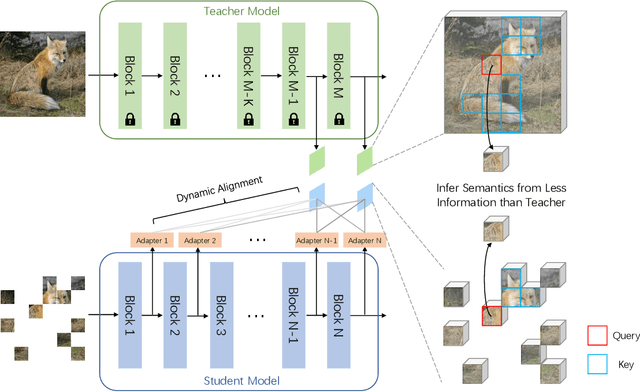
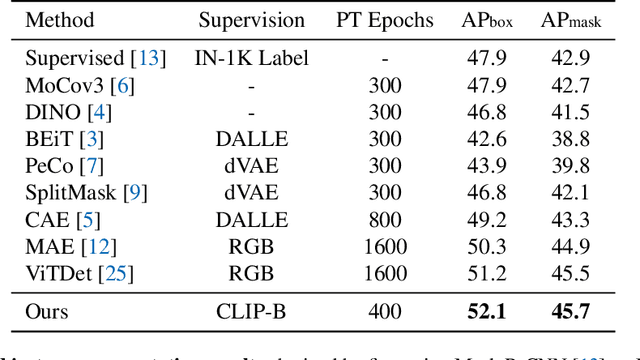
Masked Autoencoders (MAE) have been prevailing paradigms for large-scale vision representation pre-training. By reconstructing masked image patches from a small portion of visible image regions, MAE forces the model to infer semantic correlation within an image. Recently, some approaches apply semantic-rich teacher models to extract image features as the reconstruction target, leading to better performance. However, unlike the low-level features such as pixel values, we argue the features extracted by powerful teacher models already encode rich semantic correlation across regions in an intact image.This raises one question: is reconstruction necessary in Masked Image Modeling (MIM) with a teacher model? In this paper, we propose an efficient MIM paradigm named MaskAlign. MaskAlign simply learns the consistency of visible patch features extracted by the student model and intact image features extracted by the teacher model. To further advance the performance and tackle the problem of input inconsistency between the student and teacher model, we propose a Dynamic Alignment (DA) module to apply learnable alignment. Our experimental results demonstrate that masked modeling does not lose effectiveness even without reconstruction on masked regions. Combined with Dynamic Alignment, MaskAlign can achieve state-of-the-art performance with much higher efficiency. Code and models will be available at https://github.com/OpenPerceptionX/maskalign.