 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MSVQ: Self-Supervised Learning with Multiple Sample Views and Queues
May 09, 2023
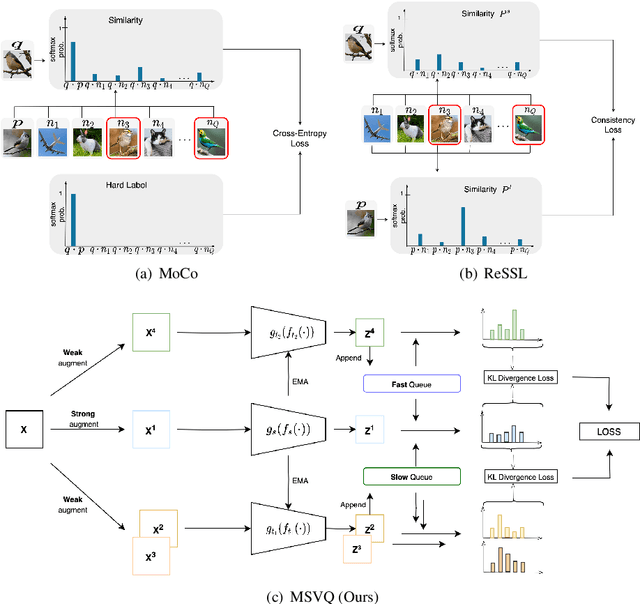
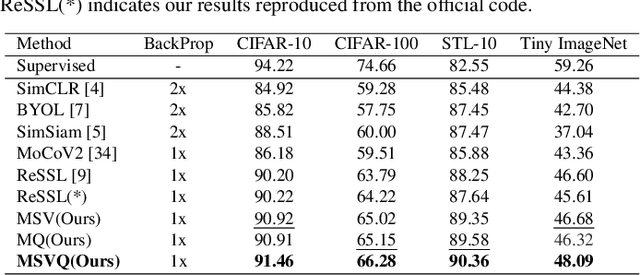
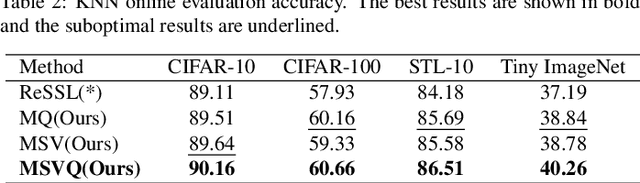
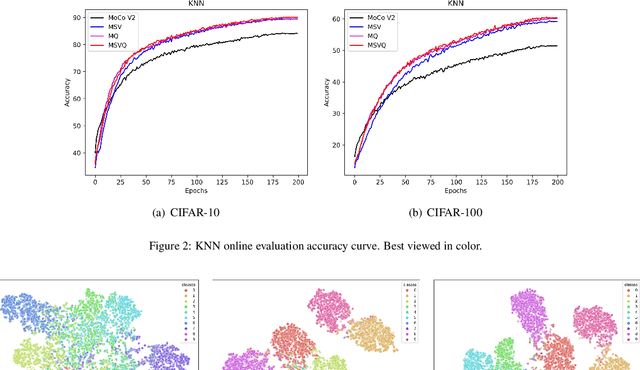
Self-supervised methods based on contrastive learning have achieved great success in unsupervised visual representation learning. However, most methods under this framework suffer from the problem of false negative samples. Inspired by mean shift for self-supervised learning, we propose a new simple framework, namely Multiple Sample Views and Queues (MSVQ). We jointly construct a soft label on-the-fly by introducing two complementary and symmetric ways: multiple augmented positive views and two momentum encoders forming various semantic features of negative samples. Two teacher networks perform similarity relationship calculations with negative samples and then transfer this knowledge to the student. Let the student mimic the similar relationship between the samples, thus giving the student a more flexible ability to identify false negative samples in the dataset. The classification results on four benchmark image datasets demonstrate the high effectiveness and efficiency of our approach compared to some classical methods. Source code and pretrained models are available at $\href{https://github.com/pc-cp/MSVQ}{this~http~URL}$.
Duke Spleen Data Set: A Publicly Available Spleen MRI and CT dataset for Training Segmentation
May 09, 2023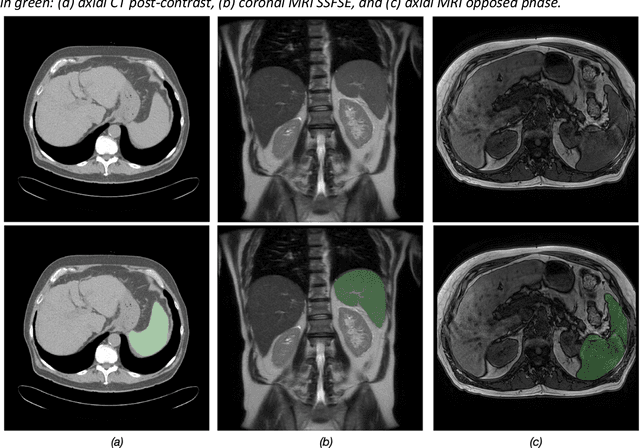
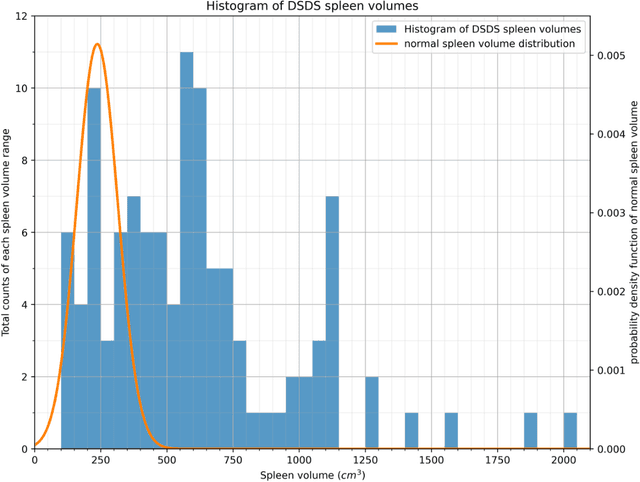
Spleen volumetry is primarily associated with patients suffering from chronic liver disease and portal hypertension, as they often have spleens with abnormal shapes and sizes. However, manually segmenting the spleen to obtain its volume is a time-consuming process. Deep learning algorithms have proven to be effective in automating spleen segmentation, but a suitable dataset is necessary for training such algorithms. To our knowledge, the few publicly available datasets for spleen segmentation lack confounding features such as ascites and abdominal varices. To address this issue, the Duke Spleen Data Set (DSDS) has been developed, which includes 109 CT and MRI volumes from patients with chronic liver disease and portal hypertension. The dataset includes a diverse range of image types, vendors, planes, and contrasts, as well as varying spleen shapes and sizes due to underlying disease states. The DSDS aims to facilitate the creation of robust spleen segmentation models that can take into account these variations and confounding factors.
An Efficient Ensemble Explainable AI (XAI) Approach for Morphed Face Detection
Apr 23, 2023

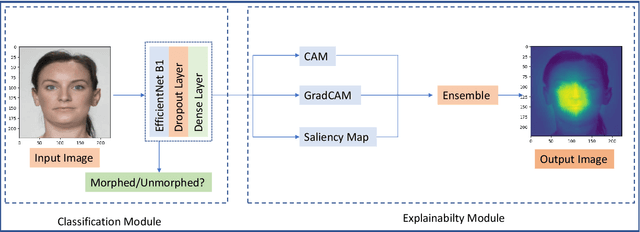
The extensive utilization of biometric authentication systems have emanated attackers / imposters to forge user identity based on morphed images. In this attack, a synthetic image is produced and merged with genuine. Next, the resultant image is user for authentication. Numerous deep neural convolutional architectures have been proposed in literature for face Morphing Attack Detection (MADs) to prevent such attacks and lessen the risks associated with them. Although, deep learning models achieved optimal results in terms of performance, it is difficult to understand and analyse these networks since they are black box/opaque in nature. As a consequence, incorrect judgments may be made. There is, however, a dearth of literature that explains decision-making methods of black box deep learning models for biometric Presentation Attack Detection (PADs) or MADs that can aid the biometric community to have trust in deep learning-based biometric systems for identification and authentication in various security applications such as border control, criminal database establishment etc. In this work, we present a novel visual explanation approach named Ensemble XAI integrating Saliency maps, Class Activation Maps (CAM) and Gradient-CAM (Grad-CAM) to provide a more comprehensive visual explanation for a deep learning prognostic model (EfficientNet-B1) that we have employed to predict whether the input presented to a biometric authentication system is morphed or genuine. The experimentations have been performed on three publicly available datasets namely Face Research Lab London Set, Wide Multi-Channel Presentation Attack (WMCA), and Makeup Induced Face Spoofing (MIFS). The experimental evaluations affirms that the resultant visual explanations highlight more fine-grained details of image features/areas focused by EfficientNet-B1 to reach decisions along with appropriate reasoning.
Improving Diffusion Models for Scene Text Editing with Dual Encoders
Apr 12, 2023

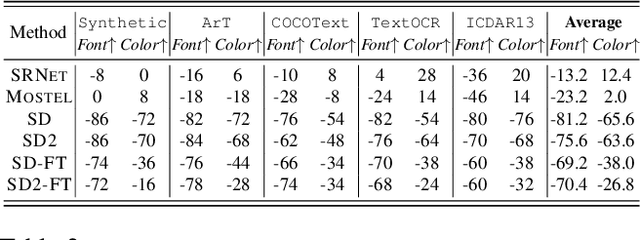
Scene text editing is a challenging task that involves modifying or inserting specified texts in an image while maintaining its natural and realistic appearance. Most previous approaches to this task rely on style-transfer models that crop out text regions and feed them into image transfer models, such as GANs. However, these methods are limited in their ability to change text style and are unable to insert texts into images. Recent advances in diffusion models have shown promise in overcoming these limitations with text-conditional image editing. However, our empirical analysis reveals that state-of-the-art diffusion models struggle with rendering correct text and controlling text style. To address these problems, we propose DIFFSTE to improve pre-trained diffusion models with a dual encoder design, which includes a character encoder for better text legibility and an instruction encoder for better style control. An instruction tuning framework is introduced to train our model to learn the mapping from the text instruction to the corresponding image with either the specified style or the style of the surrounding texts in the background. Such a training method further brings our method the zero-shot generalization ability to the following three scenarios: generating text with unseen font variation, e.g., italic and bold, mixing different fonts to construct a new font, and using more relaxed forms of natural language as the instructions to guide the generation task. We evaluate our approach on five datasets and demonstrate its superior performance in terms of text correctness, image naturalness, and style controllability. Our code is publicly available. https://github.com/UCSB-NLP-Chang/DiffSTE
SwipeBot: DNN-based Autonomous Robot Navigation among Movable Obstacles in Cluttered Environments
May 08, 2023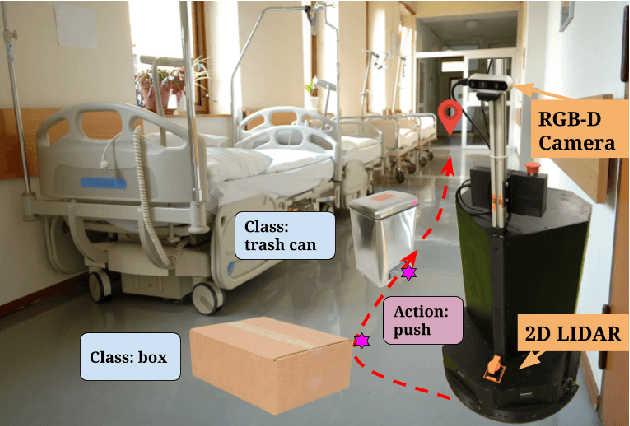
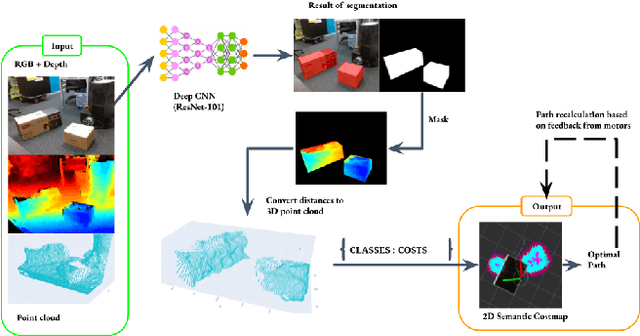

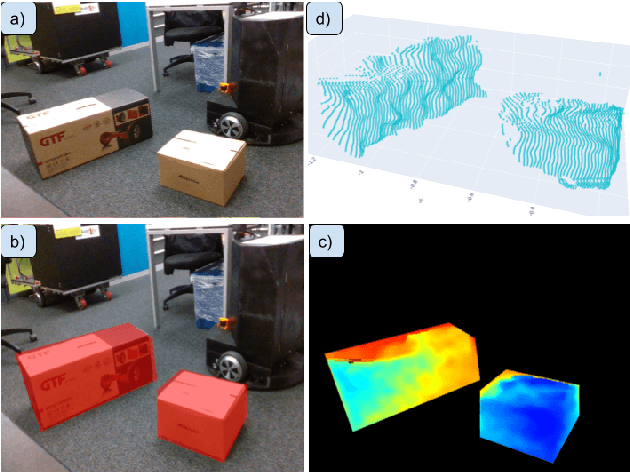
In this paper, we propose a novel approach to wheeled robot navigation through an environment with movable obstacles. A robot exploits knowledge about different obstacle classes and selects the minimally invasive action to perform to clear the path. We trained a convolutional neural network (CNN), so the robot can classify an RGB-D image and decide whether to push a blocking object and which force to apply. After known objects are segmented, they are being projected to a cost-map, and a robot calculates an optimal path to the goal. If the blocking objects are allowed to be moved, a robot drives through them while pushing them away. We implemented our algorithm in ROS, and an extensive set of simulations showed that the robot successfully overcomes the blocked regions. Our approach allows a robot to successfully build a path through regions, where it would have stuck with traditional path-planning techniques.
Causal Analysis for Robust Interpretability of Neural Networks
May 15, 2023
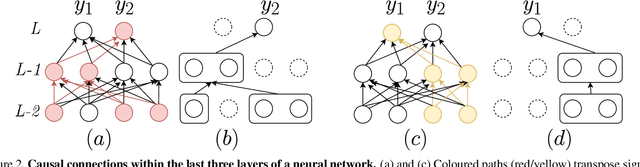
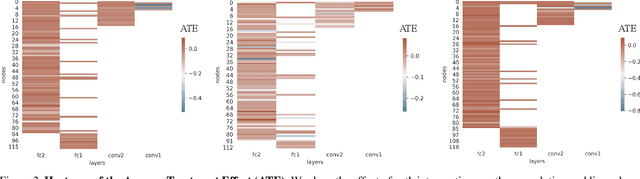
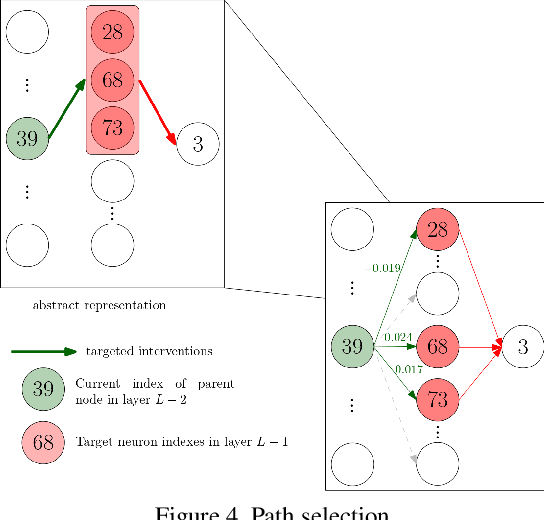
Interpreting the inner function of neural networks is crucial for the trustworthy development and deployment of these black-box models. Prior interpretability methods focus on correlation-based measures to attribute model decisions to individual examples. However, these measures are susceptible to noise and spurious correlations encoded in the model during the training phase (e.g., biased inputs, model overfitting, or misspecification). Moreover, this process has proven to result in noisy and unstable attributions that prevent any transparent understanding of the model's behavior. In this paper, we develop a robust interventional-based method grounded by causal analysis to capture cause-effect mechanisms in pre-trained neural networks and their relation to the prediction. Our novel approach relies on path interventions to infer the causal mechanisms within hidden layers and isolate relevant and necessary information (to model prediction), avoiding noisy ones. The result is task-specific causal explanatory graphs that can audit model behavior and express the actual causes underlying its performance. We apply our method to vision models trained on classification tasks. On image classification tasks, we provide extensive quantitative experiments to show that our approach can capture more stable and faithful explanations than standard attribution-based methods. Furthermore, the underlying causal graphs reveal the neural interactions in the model, making it a valuable tool in other applications (e.g., model repair).
MIPI 2023 Challenge on RGBW Fusion: Methods and Results
Apr 24, 2023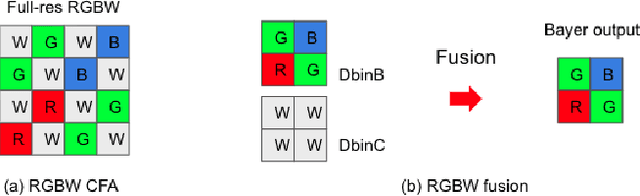


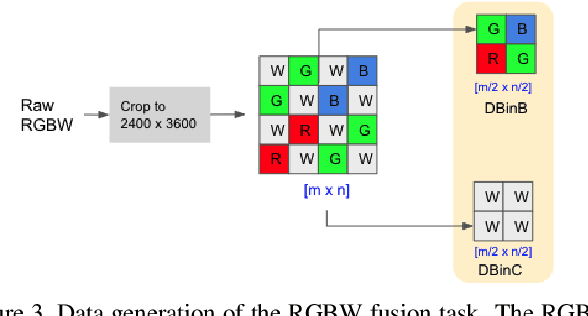
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Fusion and Denoise track on MIPI 2023. In total, 69 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
CoReFusion: Contrastive Regularized Fusion for Guided Thermal Super-Resolution
Apr 24, 2023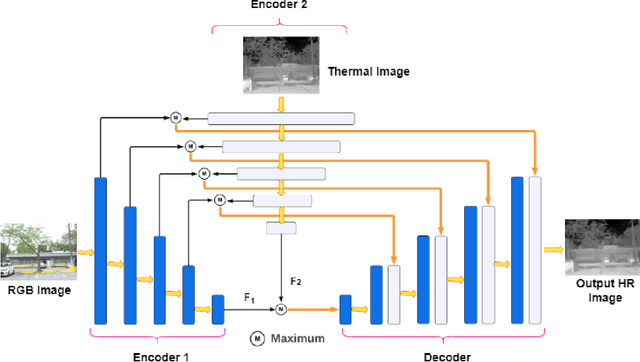

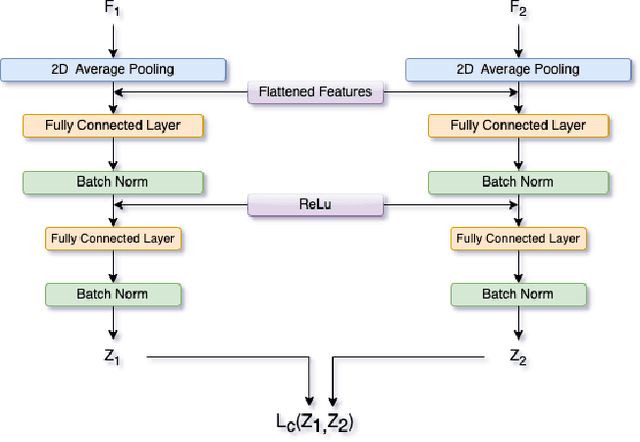
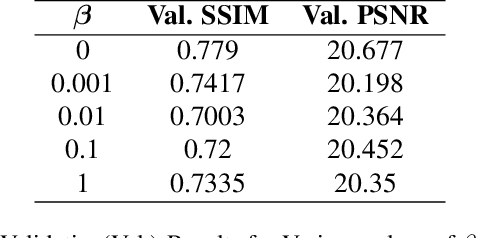
Thermal imaging has numerous advantages over regular visible-range imaging since it performs well in low-light circumstances. Super-Resolution approaches can broaden their usefulness by replicating accurate high-resolution thermal pictures using measurements from low-cost, low-resolution thermal sensors. Because of the spectral range mismatch between the images, Guided Super-Resolution of thermal images utilizing visible range images is difficult. However, In case of failure to capture Visible Range Images can prevent the operations of applications in critical areas. We present a novel data fusion framework and regularization technique for Guided Super Resolution of Thermal images. The proposed architecture is computationally in-expensive and lightweight with the ability to maintain performance despite missing one of the modalities, i.e., high-resolution RGB image or the lower-resolution thermal image, and is designed to be robust in the presence of missing data. The proposed method presents a promising solution to the frequently occurring problem of missing modalities in a real-world scenario. Code is available at https://github.com/Kasliwal17/CoReFusion .
Few-shot Class-incremental Pill Recognition
Apr 24, 2023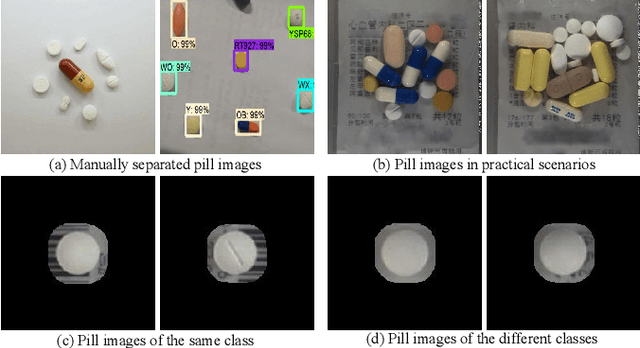
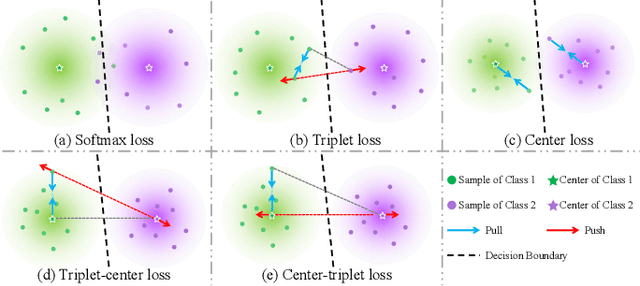

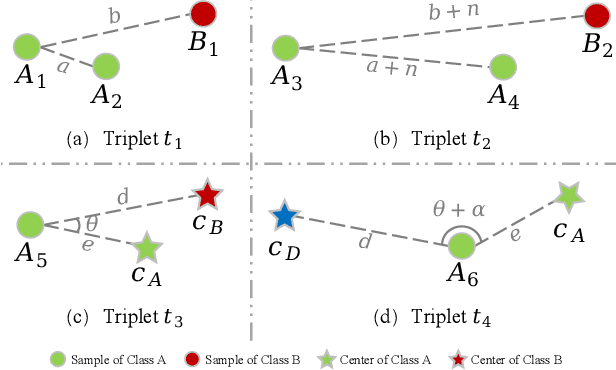
The automatic pill recognition system is of great significance in improving the efficiency of the hospital, helping people with visual impairment, and avoiding cross-infection. However, most existing pill recognition systems based on deep learning can merely perform pill classification on the learned pill categories with sufficient training data. In practice, the expensive cost of data annotation and the continuously increasing categories of new pills make it meaningful to develop a few-shot class-incremental pill recognition system. In this paper, we develop the first few-shot class-incremental pill recognition system, which adopts decoupled learning strategy of representations and classifiers. In learning representations, we propose the novel Center-Triplet loss function, which can promote intra-class compactness and inter-class separability. In learning classifiers, we propose a specialized pseudo pill image construction strategy to train the Graph Attention Network to obtain the adaptation model. Moreover, we construct two new pill image datasets for few-shot class-incremental learning. The experimental results show that our framework outperforms the state-of-the-art methods.
Explicit Correspondence Matching for Generalizable Neural Radiance Fields
Apr 24, 2023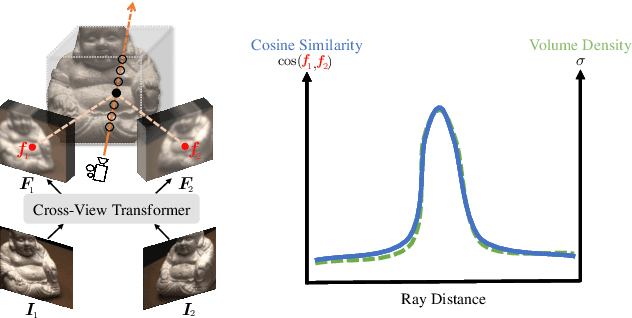

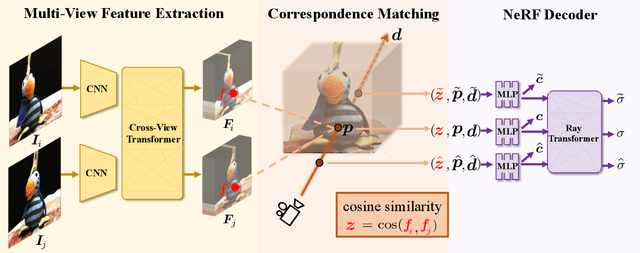
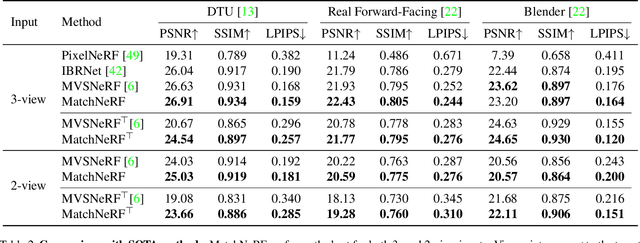
We present a new generalizable NeRF method that is able to directly generalize to new unseen scenarios and perform novel view synthesis with as few as two source views. The key to our approach lies in the explicitly modeled correspondence matching information, so as to provide the geometry prior to the prediction of NeRF color and density for volume rendering. The explicit correspondence matching is quantified with the cosine similarity between image features sampled at the 2D projections of a 3D point on different views, which is able to provide reliable cues about the surface geometry. Unlike previous methods where image features are extracted independently for each view, we consider modeling the cross-view interactions via Transformer cross-attention, which greatly improves the feature matching quality. Our method achieves state-of-the-art results on different evaluation settings, with the experiments showing a strong correlation between our learned cosine feature similarity and volume density, demonstrating the effectiveness and superiority of our proposed method. Code is at https://github.com/donydchen/matchnerf