 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffGaze: A Diffusion Model for Continuous Gaze Sequence Generation on 360° Images
Mar 26, 2024
We present DiffGaze, a novel method for generating realistic and diverse continuous human gaze sequences on 360{\deg} images based on a conditional score-based denoising diffusion model. Generating human gaze on 360{\deg} images is important for various human-computer interaction and computer graphics applications, e.g. for creating large-scale eye tracking datasets or for realistic animation of virtual humans. However, existing methods are limited to predicting discrete fixation sequences or aggregated saliency maps, thereby neglecting crucial parts of natural gaze behaviour. Our method uses features extracted from 360{\deg} images as condition and uses two transformers to model the temporal and spatial dependencies of continuous human gaze. We evaluate DiffGaze on two 360{\deg} image benchmarks for gaze sequence generation as well as scanpath prediction and saliency prediction. Our evaluations show that DiffGaze outperforms state-of-the-art methods on all tasks on both benchmarks. We also report a 21-participant user study showing that our method generates gaze sequences that are indistinguishable from real human sequences.
ThemeStation: Generating Theme-Aware 3D Assets from Few Exemplars
Mar 22, 2024Real-world applications often require a large gallery of 3D assets that share a consistent theme. While remarkable advances have been made in general 3D content creation from text or image, synthesizing customized 3D assets following the shared theme of input 3D exemplars remains an open and challenging problem. In this work, we present ThemeStation, a novel approach for theme-aware 3D-to-3D generation. ThemeStation synthesizes customized 3D assets based on given few exemplars with two goals: 1) unity for generating 3D assets that thematically align with the given exemplars and 2) diversity for generating 3D assets with a high degree of variations. To this end, we design a two-stage framework that draws a concept image first, followed by a reference-informed 3D modeling stage. We propose a novel dual score distillation (DSD) loss to jointly leverage priors from both the input exemplars and the synthesized concept image. Extensive experiments and user studies confirm that ThemeStation surpasses prior works in producing diverse theme-aware 3D models with impressive quality. ThemeStation also enables various applications such as controllable 3D-to-3D generation.
Ultrasound Imaging based on the Variance of a Diffusion Restoration Model
Mar 22, 2024Despite today's prevalence of ultrasound imaging in medicine, ultrasound signal-to-noise ratio is still affected by several sources of noise and artefacts. Moreover, enhancing ultrasound image quality involves balancing concurrent factors like contrast, resolution, and speckle preservation. Recently, there has been progress in both model-based and learning-based approaches addressing the problem of ultrasound image reconstruction. Bringing the best from both worlds, we propose a hybrid reconstruction method combining an ultrasound linear direct model with a learning-based prior coming from a generative Denoising Diffusion model. More specifically, we rely on the unsupervised fine-tuning of a pre-trained Denoising Diffusion Restoration Model (DDRM). Given the nature of multiplicative noise inherent to ultrasound, this paper proposes an empirical model to characterize the stochasticity of diffusion reconstruction of ultrasound images, and shows the interest of its variance as an echogenicity map estimator. We conduct experiments on synthetic, in-vitro, and in-vivo data, demonstrating the efficacy of our variance imaging approach in achieving high-quality image reconstructions from single plane-wave acquisitions and in comparison to state-of-the-art methods.
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Mar 04, 2024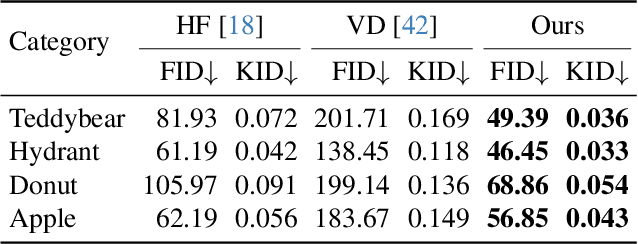
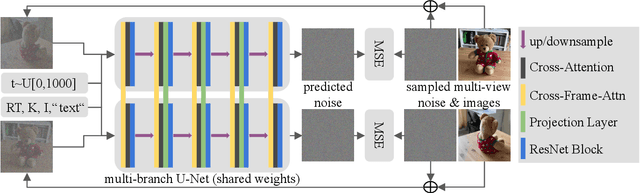

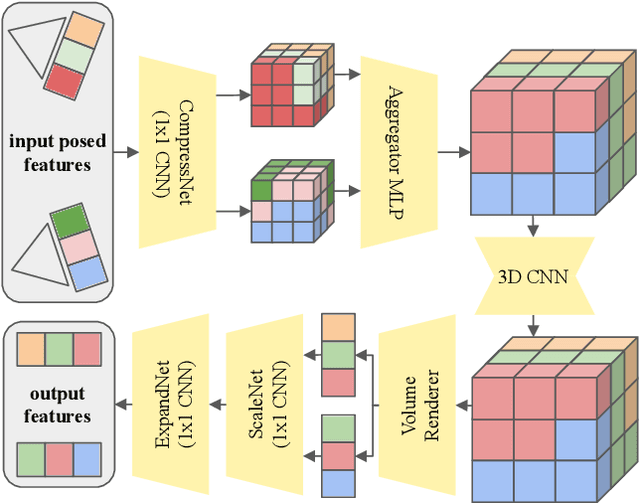
3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).
Segmentation Guided Sparse Transformer for Under-Display Camera Image Restoration
Mar 09, 2024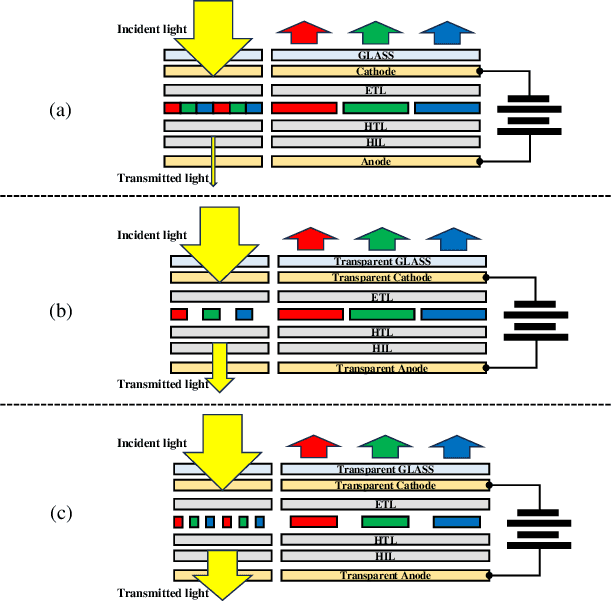

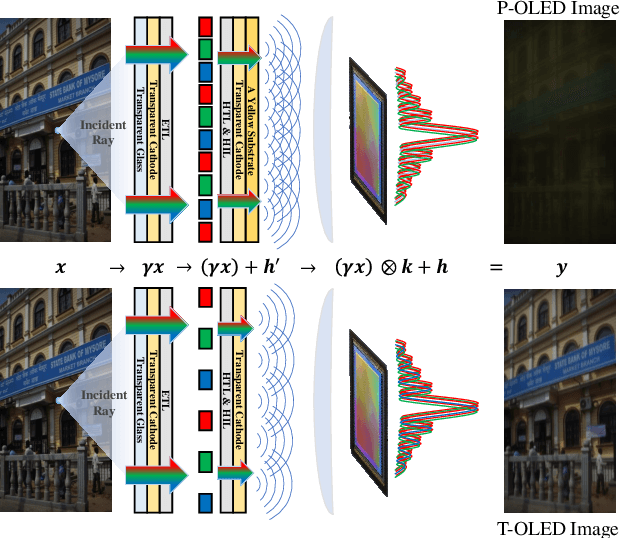

Under-Display Camera (UDC) is an emerging technology that achieves full-screen display via hiding the camera under the display panel. However, the current implementation of UDC causes serious degradation. The incident light required for camera imaging undergoes attenuation and diffraction when passing through the display panel, leading to various artifacts in UDC imaging. Presently, the prevailing UDC image restoration methods predominantly utilize convolutional neural network architectures, whereas Transformer-based methods have exhibited superior performance in the majority of image restoration tasks. This is attributed to the Transformer's capability to sample global features for the local reconstruction of images, thereby achieving high-quality image restoration. In this paper, we observe that when using the Vision Transformer for UDC degraded image restoration, the global attention samples a large amount of redundant information and noise. Furthermore, compared to the ordinary Transformer employing dense attention, the Transformer utilizing sparse attention can alleviate the adverse impact of redundant information and noise. Building upon this discovery, we propose a Segmentation Guided Sparse Transformer method (SGSFormer) for the task of restoring high-quality images from UDC degraded images. Specifically, we utilize sparse self-attention to filter out redundant information and noise, directing the model's attention to focus on the features more relevant to the degraded regions in need of reconstruction. Moreover, we integrate the instance segmentation map as prior information to guide the sparse self-attention in filtering and focusing on the correct regions.
Histogram Layers for Neural Engineered Features
Mar 25, 2024In the computer vision literature, many effective histogram-based features have been developed. These engineered features include local binary patterns and edge histogram descriptors among others and they have been shown to be informative features for a variety of computer vision tasks. In this paper, we explore whether these features can be learned through histogram layers embedded in a neural network and, therefore, be leveraged within deep learning frameworks. By using histogram features, local statistics of the feature maps from the convolution neural networks can be used to better represent the data. We present neural versions of local binary pattern and edge histogram descriptors that jointly improve the feature representation and perform image classification. Experiments are presented on benchmark and real-world datasets.
Assessing the Performance of Deep Learning for Automated Gleason Grading in Prostate Cancer
Mar 25, 2024Prostate cancer is a dominant health concern calling for advanced diagnostic tools. Utilizing digital pathology and artificial intelligence, this study explores the potential of 11 deep neural network architectures for automated Gleason grading in prostate carcinoma focusing on comparing traditional and recent architectures. A standardized image classification pipeline, based on the AUCMEDI framework, facilitated robust evaluation using an in-house dataset consisting of 34,264 annotated tissue tiles. The results indicated varying sensitivity across architectures, with ConvNeXt demonstrating the strongest performance. Notably, newer architectures achieved superior performance, even though with challenges in differentiating closely related Gleason grades. The ConvNeXt model was capable of learning a balance between complexity and generalizability. Overall, this study lays the groundwork for enhanced Gleason grading systems, potentially improving diagnostic efficiency for prostate cancer.
Multi-Task Learning with Multi-Task Optimization
Mar 24, 2024Multi-task learning solves multiple correlated tasks. However, conflicts may exist between them. In such circumstances, a single solution can rarely optimize all the tasks, leading to performance trade-offs. To arrive at a set of optimized yet well-distributed models that collectively embody different trade-offs in one algorithmic pass, this paper proposes to view Pareto multi-task learning through the lens of multi-task optimization. Multi-task learning is first cast as a multi-objective optimization problem, which is then decomposed into a diverse set of unconstrained scalar-valued subproblems. These subproblems are solved jointly using a novel multi-task gradient descent method, whose uniqueness lies in the iterative transfer of model parameters among the subproblems during the course of optimization. A theorem proving faster convergence through the inclusion of such transfers is presented. We investigate the proposed multi-task learning with multi-task optimization for solving various problem settings including image classification, scene understanding, and multi-target regression. Comprehensive experiments confirm that the proposed method significantly advances the state-of-the-art in discovering sets of Pareto-optimized models. Notably, on the large image dataset we tested on, namely NYUv2, the hypervolume convergence achieved by our method was found to be nearly two times faster than the next-best among the state-of-the-art.
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 27, 2024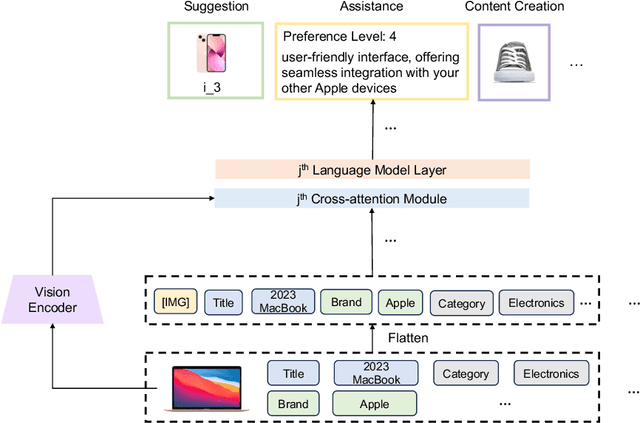
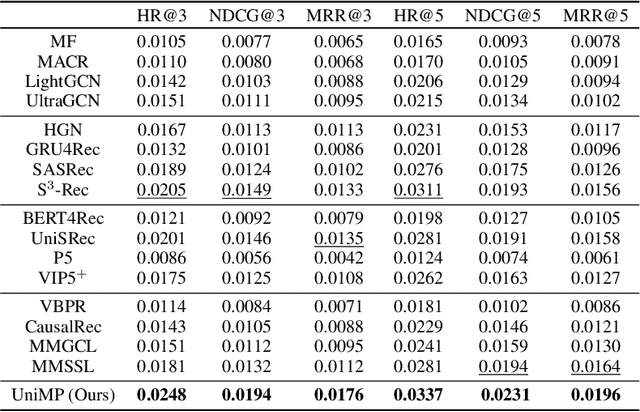
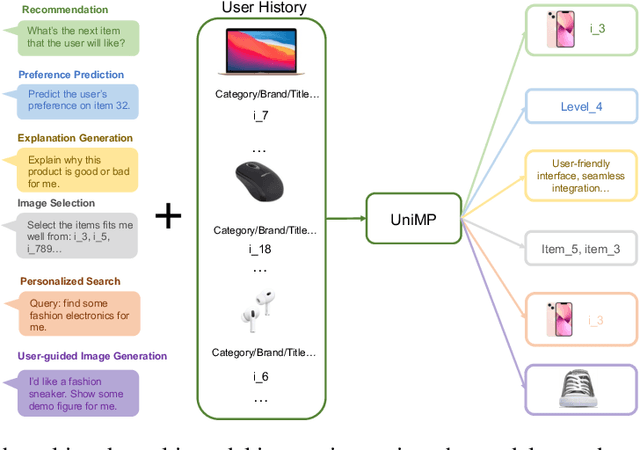
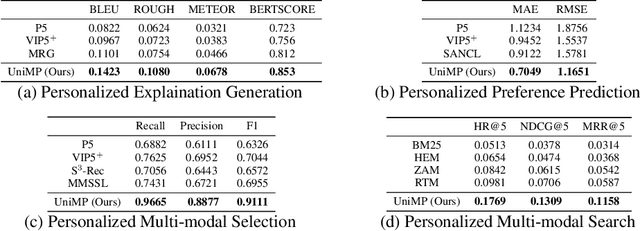
Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.
Deep Learning for Robust and Explainable Models in Computer Vision
Mar 27, 2024Recent breakthroughs in machine and deep learning (ML and DL) research have provided excellent tools for leveraging enormous amounts of data and optimizing huge models with millions of parameters to obtain accurate networks for image processing. These developments open up tremendous opportunities for using artificial intelligence (AI) in the automation and human assisted AI industry. However, as more and more models are deployed and used in practice, many challenges have emerged. This thesis presents various approaches that address robustness and explainability challenges for using ML and DL in practice. Robustness and reliability are the critical components of any model before certification and deployment in practice. Deep convolutional neural networks (CNNs) exhibit vulnerability to transformations of their inputs, such as rotation and scaling, or intentional manipulations as described in the adversarial attack literature. In addition, building trust in AI-based models requires a better understanding of current models and developing methods that are more explainable and interpretable a priori. This thesis presents developments in computer vision models' robustness and explainability. Furthermore, this thesis offers an example of using vision models' feature response visualization (models' interpretations) to improve robustness despite interpretability and robustness being seemingly unrelated in the related research. Besides methodological developments for robust and explainable vision models, a key message of this thesis is introducing model interpretation techniques as a tool for understanding vision models and improving their design and robustness. In addition to the theoretical developments, this thesis demonstrates several applications of ML and DL in different contexts, such as medical imaging and affective computing.
* 150 pages, 37 figures, 12 tables