 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Locally Attentional SDF Diffusion for Controllable 3D Shape Generation
May 09, 2023

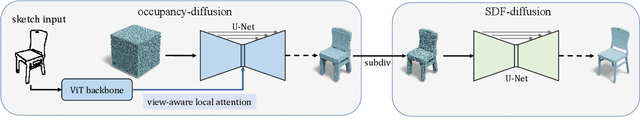
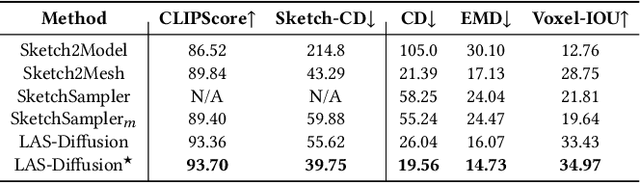
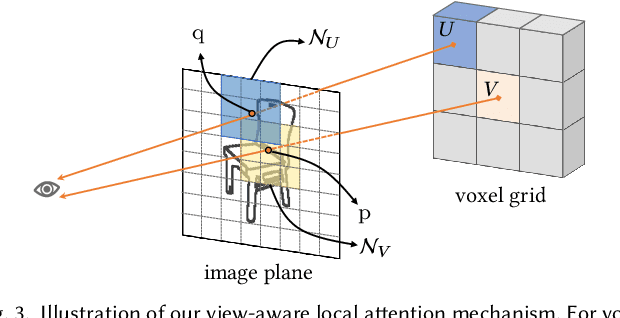
Although the recent rapid evolution of 3D generative neural networks greatly improves 3D shape generation, it is still not convenient for ordinary users to create 3D shapes and control the local geometry of generated shapes. To address these challenges, we propose a diffusion-based 3D generation framework -- locally attentional SDF diffusion, to model plausible 3D shapes, via 2D sketch image input. Our method is built on a two-stage diffusion model. The first stage, named occupancy-diffusion, aims to generate a low-resolution occupancy field to approximate the shape shell. The second stage, named SDF-diffusion, synthesizes a high-resolution signed distance field within the occupied voxels determined by the first stage to extract fine geometry. Our model is empowered by a novel view-aware local attention mechanism for image-conditioned shape generation, which takes advantage of 2D image patch features to guide 3D voxel feature learning, greatly improving local controllability and model generalizability. Through extensive experiments in sketch-conditioned and category-conditioned 3D shape generation tasks, we validate and demonstrate the ability of our method to provide plausible and diverse 3D shapes, as well as its superior controllability and generalizability over existing work. Our code and trained models are available at https://zhengxinyang.github.io/projects/LAS-Diffusion.html
* Accepted to SIGGRAPH 2023 (Journal version)
TcGAN: Semantic-Aware and Structure-Preserved GANs with Individual Vision Transformer for Fast Arbitrary One-Shot Image Generation
Feb 16, 2023



One-shot image generation (OSG) with generative adversarial networks that learn from the internal patches of a given image has attracted world wide attention. In recent studies, scholars have primarily focused on extracting features of images from probabilistically distributed inputs with pure convolutional neural networks (CNNs). However, it is quite difficult for CNNs with limited receptive domain to extract and maintain the global structural information. Therefore, in this paper, we propose a novel structure-preserved method TcGAN with individual vision transformer to overcome the shortcomings of the existing one-shot image generation methods. Specifically, TcGAN preserves global structure of an image during training to be compatible with local details while maintaining the integrity of semantic-aware information by exploiting the powerful long-range dependencies modeling capability of the transformer. We also propose a new scaling formula having scale-invariance during the calculation period, which effectively improves the generated image quality of the OSG model on image super-resolution tasks. We present the design of the TcGAN converter framework, comprehensive experimental as well as ablation studies demonstrating the ability of TcGAN to achieve arbitrary image generation with the fastest running time. Lastly, TcGAN achieves the most excellent performance in terms of applying it to other image processing tasks, e.g., super-resolution as well as image harmonization, the results further prove its superiority.
The contribution of T2 relaxation time to diffusion MRI quantification and its clinical implications: a hypothesis
Jun 03, 2023Considering liver as the reference, that both fast diffusion (PF) and slow diffusion (Dslow) of the spleen are much underestimated is likely due to the MRI properties of the spleen such as the much longer T2 relaxation time. It is possible that longer T2 relaxation time partially mitigates the signal decay effect of various gradients on diffusion weighted image. This phenomenon will not be limited to the spleen. Most liver tumors have a longer T2 relaxation time than their native normal tissue and this is considered to be associated with oedema. On the other hand, most tumors are measured with lower MRI diffusion (despite being oedematous). The reason why malignant tumors have lower diffusion value [apparent diffusion coefficient (ADC) and Dslow] are poorly understood but has been proposed to be related to a combination of higher cellularity, tissue disorganization, and increased extracellular space tortuosity. These explanations may be true, but it is also possible to that many tumors have MRI properties similar to the spleen such as longer T2 (relative to the liver) and these MRI properties may also contribute to the lower MRI measured ADC and Dslow . In other words, if we could hypothetically plant a piece of spleen tissue in the liver, MRI would recognize this planted spleen tissue as being similar to a tumor and measure it to have lower diffusion than the liver.
CVGG-Net: Ship Recognition for SAR Images Based on Complex-Valued Convolutional Neural Network
May 13, 2023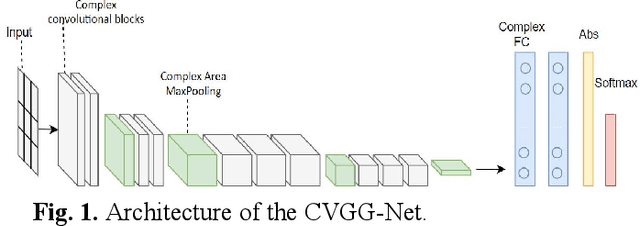
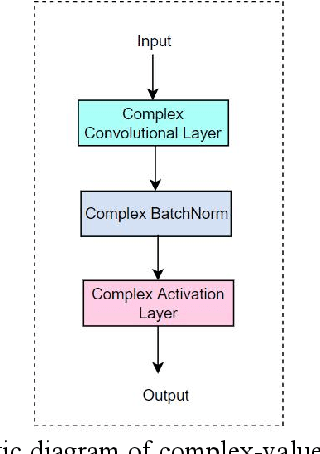
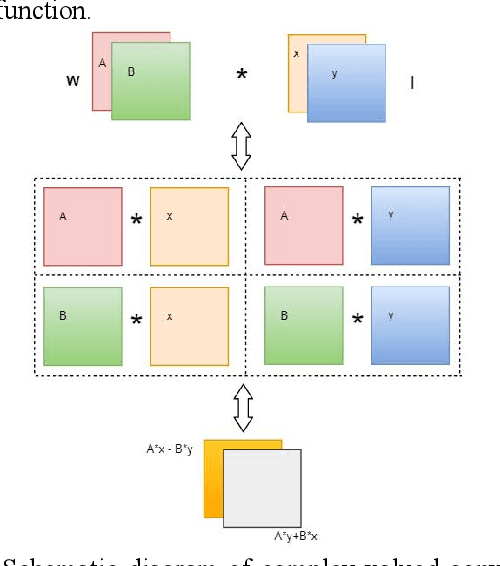
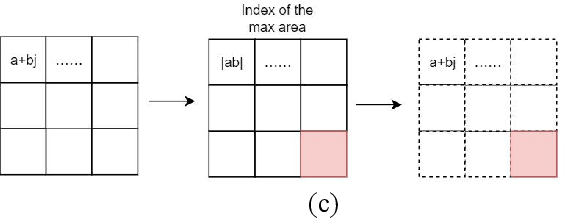
Ship target recognition is a vital task in synthetic aperture radar (SAR) imaging applications. Although convolutional neural networks have been successfully employed for SAR image target recognition, surpassing traditional algorithms, most existing research concentrates on the amplitude domain and neglects the essential phase information. Furthermore, several complex-valued neural networks utilize average pooling to achieve full complex values, resulting in suboptimal performance. To address these concerns, this paper introduces a Complex-valued Convolutional Neural Network (CVGG-Net) specifically designed for SAR image ship recognition. CVGG-Net effectively leverages both the amplitude and phase information in complex-valued SAR data. Additionally, this study examines the impact of various widely-used complex activation functions on network performance and presents a novel complex max-pooling method, called Complex Area Max-Pooling. Experimental results from two measured SAR datasets demonstrate that the proposed algorithm outperforms conventional real-valued convolutional neural networks. The proposed framework is validated on several SAR datasets.
In-Context Learning Unlocked for Diffusion Models
May 01, 2023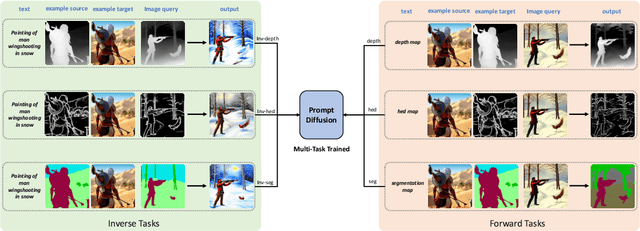
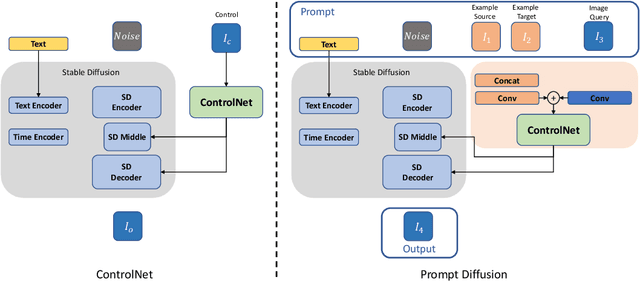


We present Prompt Diffusion, a framework for enabling in-context learning in diffusion-based generative models. Given a pair of task-specific example images, such as depth from/to image and scribble from/to image, and a text guidance, our model automatically understands the underlying task and performs the same task on a new query image following the text guidance. To achieve this, we propose a vision-language prompt that can model a wide range of vision-language tasks and a diffusion model that takes it as input. The diffusion model is trained jointly over six different tasks using these prompts. The resulting Prompt Diffusion model is the first diffusion-based vision-language foundation model capable of in-context learning. It demonstrates high-quality in-context generation on the trained tasks and generalizes effectively to new, unseen vision tasks with their respective prompts. Our model also shows compelling text-guided image editing results. Our framework, with code publicly available at https://github.com/Zhendong-Wang/Prompt-Diffusion, aims to facilitate research into in-context learning for computer vision.
Bridging the Domain Gap: Self-Supervised 3D Scene Understanding with Foundation Models
May 16, 2023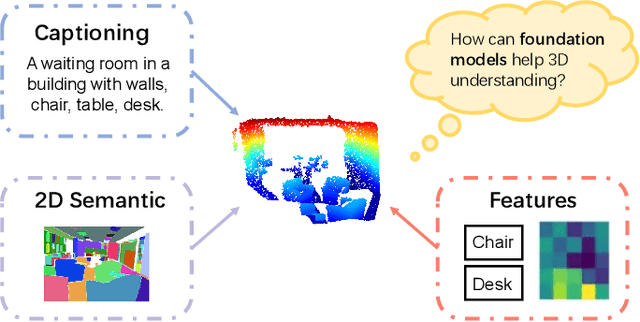
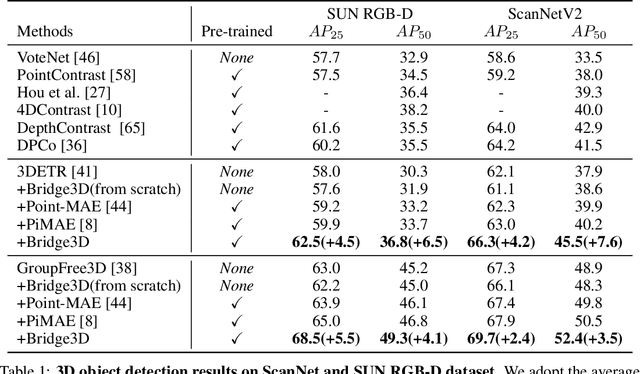
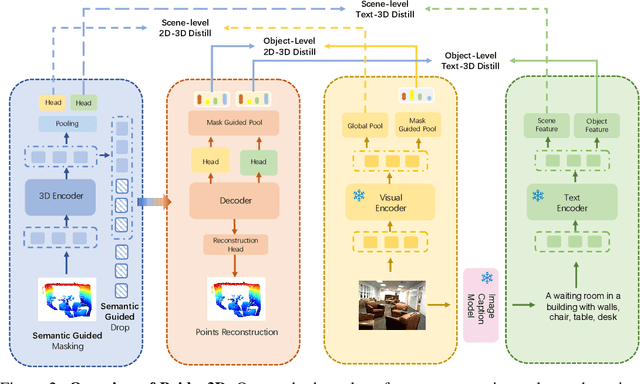
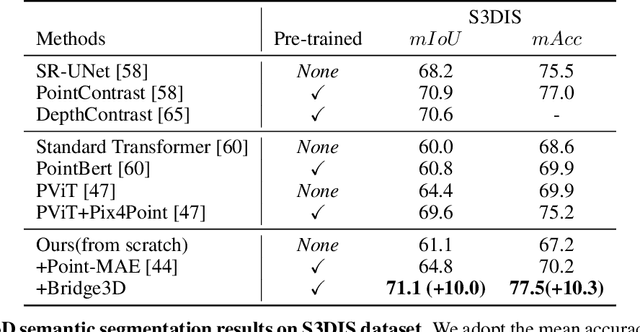
Foundation models have made significant strides in 2D and language tasks such as image segmentation, object detection, and visual-language understanding. Nevertheless, their potential to enhance 3D scene representation learning remains largely untapped due to the domain gap. In this paper, we propose an innovative methodology Bridge3D to address this gap, pre-training 3D models using features, semantic masks, and captions sourced from foundation models. Specifically, our approach utilizes semantic masks from these models to guide the masking and reconstruction process in the masked autoencoder. This strategy enables the network to concentrate more on foreground objects, thereby enhancing 3D representation learning. Additionally, we bridge the 3D-text gap at the scene level by harnessing image captioning foundation models. To further facilitate knowledge distillation from well-learned 2D and text representations to the 3D model, we introduce a novel method that employs foundation models to generate highly accurate object-level masks and semantic text information at the object level. Our approach notably outshines state-of-the-art methods in 3D object detection and semantic segmentation tasks. For instance, on the ScanNet dataset, our method surpasses the previous state-of-the-art method, PiMAE, by a significant margin of 5.3%.
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
May 16, 2023
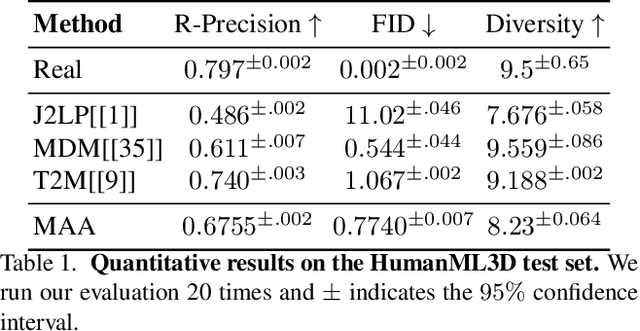
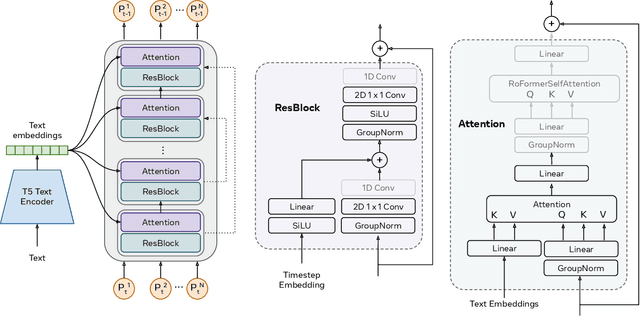
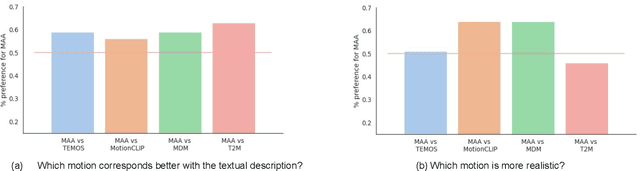
Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small-scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation, a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
Alternating Gradient Descent and Mixture-of-Experts for Integrated Multimodal Perception
May 10, 2023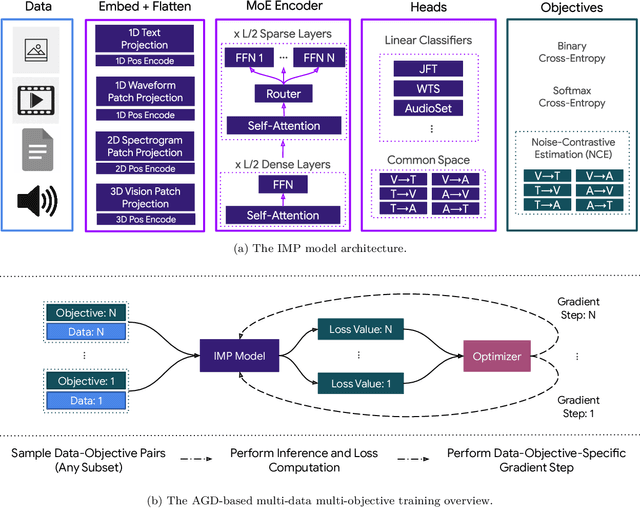

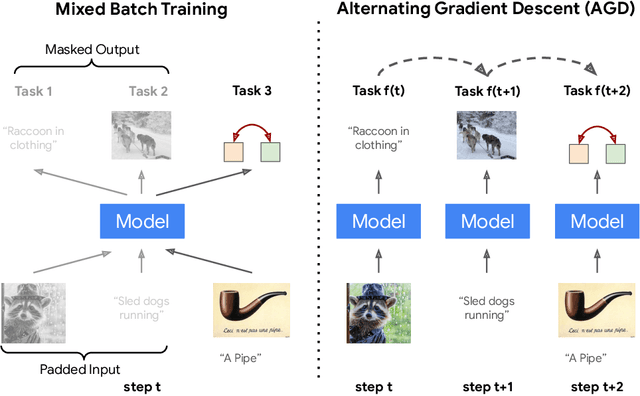
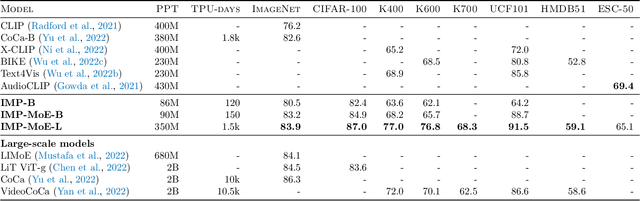
We present Integrated Multimodal Perception (IMP), a simple and scalable multimodal multi-task training and modeling approach. IMP integrates multimodal inputs including image, video, text, and audio into a single Transformer encoder with minimal modality-specific components. IMP makes use of a novel design that combines Alternating Gradient Descent (AGD) and Mixture-of-Experts (MoE) for efficient model \& task scaling. We conduct extensive empirical studies about IMP and reveal the following key insights: 1) performing gradient descent updates by alternating on diverse heterogeneous modalities, loss functions, and tasks, while also varying input resolutions, efficiently improves multimodal understanding. 2) model sparsification with MoE on a single modality-agnostic encoder substantially improves the performance, outperforming dense models that use modality-specific encoders or additional fusion layers and greatly mitigating the conflicts between modalities. IMP achieves competitive performance on a wide range of downstream tasks including image classification, video classification, image-text, and video-text retrieval. Most notably, we train a sparse IMP-MoE-L focusing on video tasks that achieves new state-of-the-art in zero-shot video classification. Our model achieves 77.0% on Kinetics-400, 76.8% on Kinetics-600, and 76.8% on Kinetics-700 zero-shot classification accuracy, improving the previous state-of-the-art by +5%, +6.7%, and +5.8%, respectively, while using only 15% of their total training computational cost.
A Dataset for Deep Learning-based Bone Structure Analyses in Total Hip Arthroplasty
Jun 07, 2023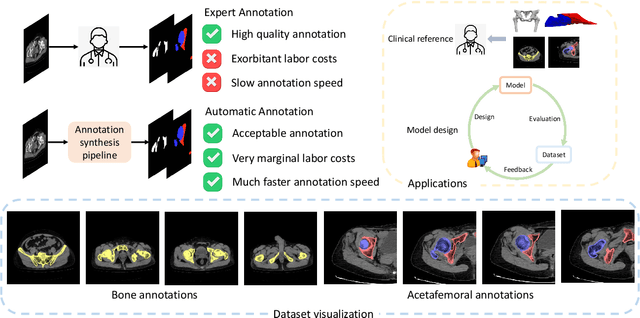


Total hip arthroplasty (THA) is a widely used surgical procedure in orthopedics. For THA, it is of clinical significance to analyze the bone structure from the CT images, especially to observe the structure of the acetabulum and femoral head, before the surgical procedure. For such bone structure analyses, deep learning technologies are promising but require high-quality labeled data for the learning, while the data labeling is costly. We address this issue and propose an efficient data annotation pipeline for producing a deep learning-oriented dataset. Our pipeline consists of non-learning-based bone extraction (BE) and acetabulum and femoral head segmentation (AFS) and active-learning-based annotation refinement (AAR). For BE we use the classic graph-cut algorithm. For AFS we propose an improved algorithm, including femoral head boundary localization using first-order and second-order gradient regularization, line-based non-maximum suppression, and anatomy prior-based femoral head extraction. For AAR, we refine the algorithm-produced pseudo labels with the help of trained deep models: we measure the uncertainty based on the disagreement between the original pseudo labels and the deep model predictions, and then find out the samples with the largest uncertainty to ask for manual labeling. Using the proposed pipeline, we construct a large-scale bone structure analyses dataset from more than 300 clinical and diverse CT scans. We perform careful manual labeling for the test set of our data. We then benchmark multiple state-of-the art deep learning-based methods of medical image segmentation using the training and test sets of our data. The extensive experimental results validate the efficacy of the proposed data annotation pipeline. The dataset, related codes and models will be publicly available at https://github.com/hitachinsk/THA.
Single-Stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data
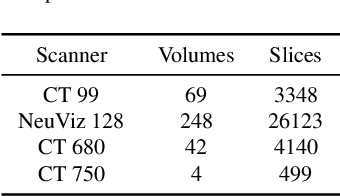
Jun 05, 2023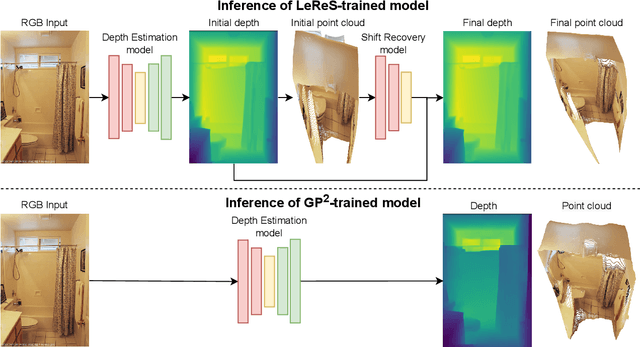
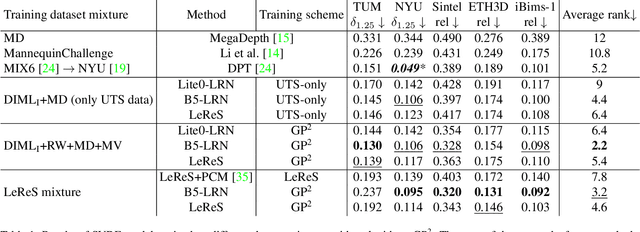
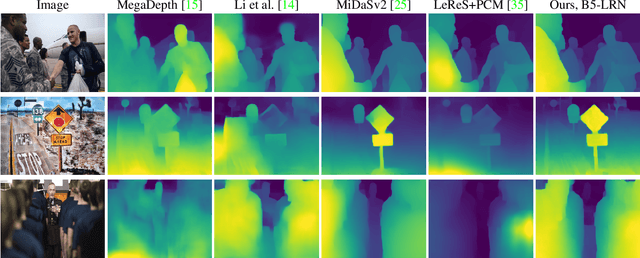

Nowadays, robotics, AR, and 3D modeling applications attract considerable attention to single-view depth estimation (SVDE) as it allows estimating scene geometry from a single RGB image. Recent works have demonstrated that the accuracy of an SVDE method hugely depends on the diversity and volume of the training data. However, RGB-D datasets obtained via depth capturing or 3D reconstruction are typically small, synthetic datasets are not photorealistic enough, and all these datasets lack diversity. The large-scale and diverse data can be sourced from stereo images or stereo videos from the web. Typically being uncalibrated, stereo data provides disparities up to unknown shift (geometrically incomplete data), so stereo-trained SVDE methods cannot recover 3D geometry. It was recently shown that the distorted point clouds obtained with a stereo-trained SVDE method can be corrected with additional point cloud modules (PCM) separately trained on the geometrically complete data. On the contrary, we propose GP$^{2}$, General-Purpose and Geometry-Preserving training scheme, and show that conventional SVDE models can learn correct shifts themselves without any post-processing, benefiting from using stereo data even in the geometry-preserving setting. Through experiments on different dataset mixtures, we prove that GP$^{2}$-trained models outperform methods relying on PCM in both accuracy and speed, and report the state-of-the-art results in the general-purpose geometry-preserving SVDE. Moreover, we show that SVDE models can learn to predict geometrically correct depth even when geometrically complete data comprises the minor part of the training set.