 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Novel Hybrid-Learning Algorithms for Improved Millimeter-Wave Imaging Systems
Jun 27, 2023
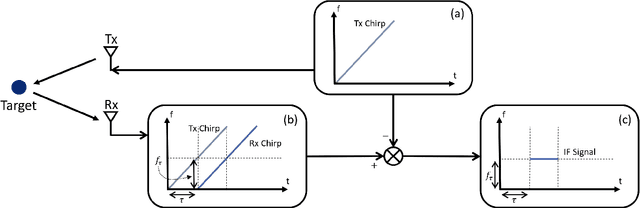
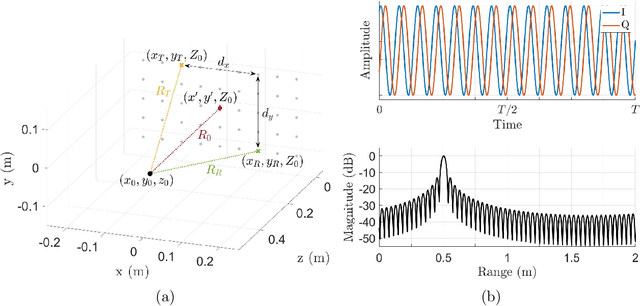

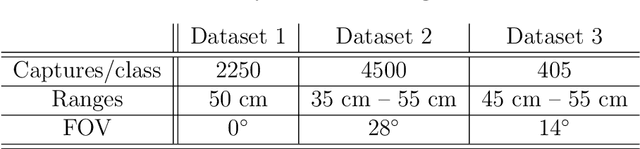
Increasing attention is being paid to millimeter-wave (mmWave), 30 GHz to 300 GHz, and terahertz (THz), 300 GHz to 10 THz, sensing applications including security sensing, industrial packaging, medical imaging, and non-destructive testing. Traditional methods for perception and imaging are challenged by novel data-driven algorithms that offer improved resolution, localization, and detection rates. Over the past decade, deep learning technology has garnered substantial popularity, particularly in perception and computer vision applications. Whereas conventional signal processing techniques are more easily generalized to various applications, hybrid approaches where signal processing and learning-based algorithms are interleaved pose a promising compromise between performance and generalizability. Furthermore, such hybrid algorithms improve model training by leveraging the known characteristics of radio frequency (RF) waveforms, thus yielding more efficiently trained deep learning algorithms and offering higher performance than conventional methods. This dissertation introduces novel hybrid-learning algorithms for improved mmWave imaging systems applicable to a host of problems in perception and sensing. Various problem spaces are explored, including static and dynamic gesture classification; precise hand localization for human computer interaction; high-resolution near-field mmWave imaging using forward synthetic aperture radar (SAR); SAR under irregular scanning geometries; mmWave image super-resolution using deep neural network (DNN) and Vision Transformer (ViT) architectures; and data-level multiband radar fusion using a novel hybrid-learning architecture. Furthermore, we introduce several novel approaches for deep learning model training and dataset synthesis.
Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective
Mar 31, 2023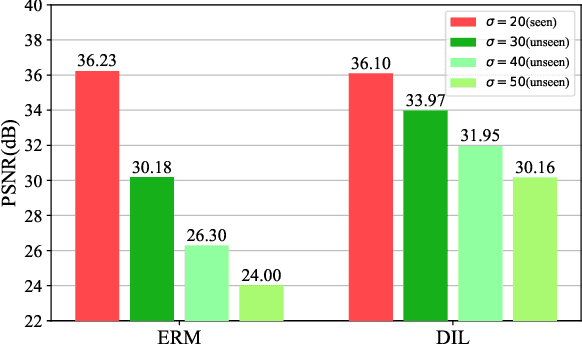
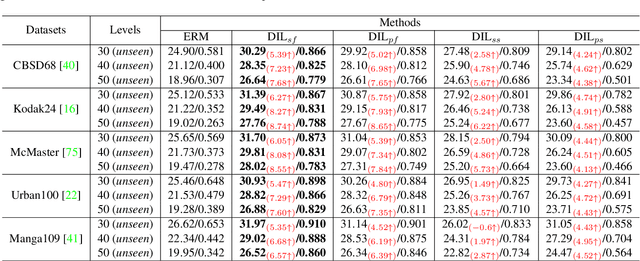
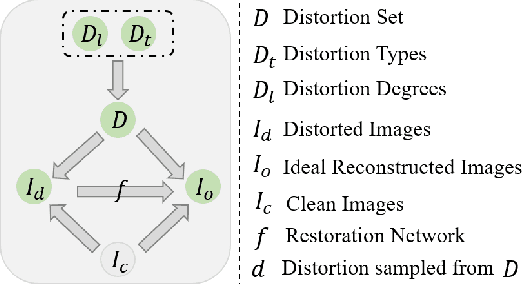
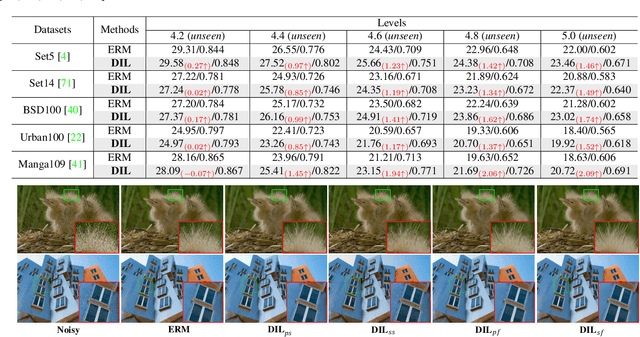
In recent years, we have witnessed the great advancement of Deep neural networks (DNNs) in image restoration. However, a critical limitation is that they cannot generalize well to real-world degradations with different degrees or types. In this paper, we are the first to propose a novel training strategy for image restoration from the causality perspective, to improve the generalization ability of DNNs for unknown degradations. Our method, termed Distortion Invariant representation Learning (DIL), treats each distortion type and degree as one specific confounder, and learns the distortion-invariant representation by eliminating the harmful confounding effect of each degradation. We derive our DIL with the back-door criterion in causality by modeling the interventions of different distortions from the optimization perspective. Particularly, we introduce counterfactual distortion augmentation to simulate the virtual distortion types and degrees as the confounders. Then, we instantiate the intervention of each distortion with a virtual model updating based on corresponding distorted images, and eliminate them from the meta-learning perspective. Extensive experiments demonstrate the effectiveness of our DIL on the generalization capability for unseen distortion types and degrees. Our code will be available at https://github.com/lixinustc/Causal-IR-DIL.
Inherent Consistent Learning for Accurate Semi-supervised Medical Image Segmentation
Mar 24, 2023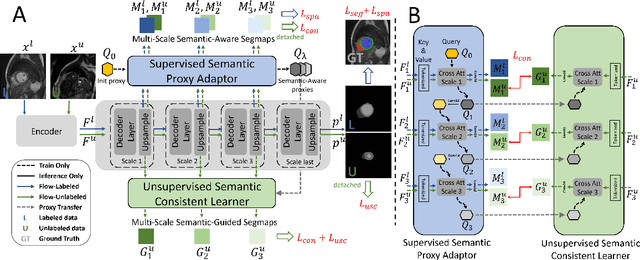
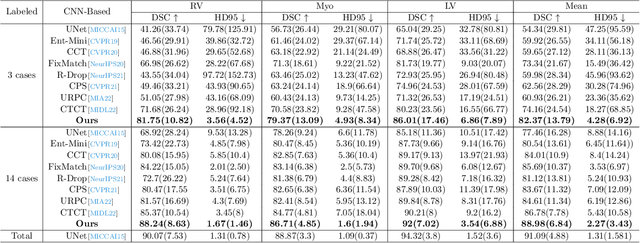
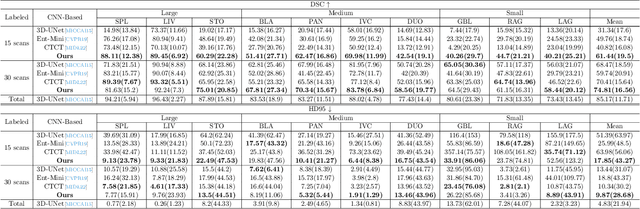
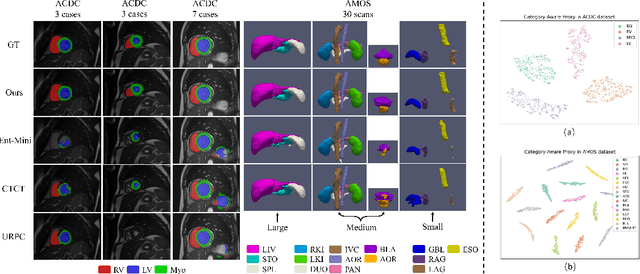
Semi-supervised medical image segmentation has attracted much attention in recent years because of the high cost of medical image annotations. In this paper, we propose a novel Inherent Consistent Learning (ICL) method, which aims to learn robust semantic category representations through the semantic consistency guidance of labeled and unlabeled data to help segmentation. In practice, we introduce two external modules namely Supervised Semantic Proxy Adaptor (SSPA) and Unsupervised Semantic Consistent Learner (USCL) that based on the attention mechanism to align the semantic category representations of labeled and unlabeled data, as well as update the global semantic representations over the entire training set. The proposed ICL is a plug-and-play scheme for various network architectures and the two modules are not involved in the testing stage. Experimental results on three public benchmarks show that the proposed method can outperform the state-of-the-art especially when the number of annotated data is extremely limited. Code is available at: https://github.com/zhuye98/ICL.git.
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
Jun 12, 2023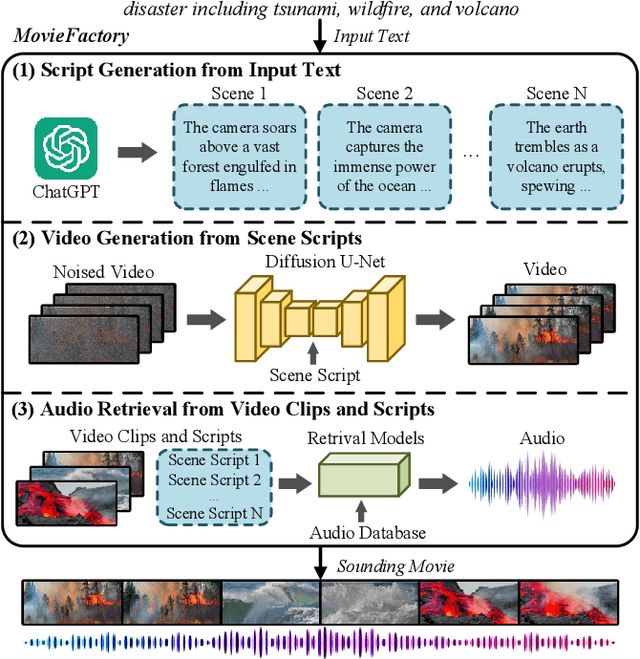
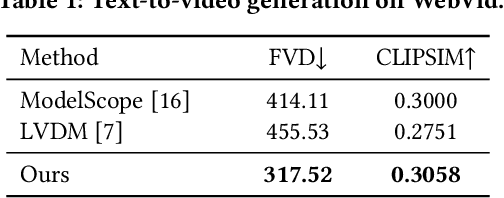
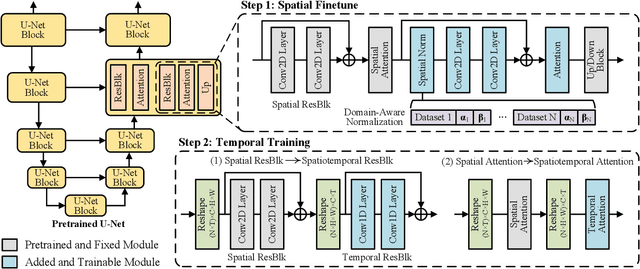

In this paper, we present MovieFactory, a powerful framework to generate cinematic-picture (3072$\times$1280), film-style (multi-scene), and multi-modality (sounding) movies on the demand of natural languages. As the first fully automated movie generation model to the best of our knowledge, our approach empowers users to create captivating movies with smooth transitions using simple text inputs, surpassing existing methods that produce soundless videos limited to a single scene of modest quality. To facilitate this distinctive functionality, we leverage ChatGPT to expand user-provided text into detailed sequential scripts for movie generation. Then we bring scripts to life visually and acoustically through vision generation and audio retrieval. To generate videos, we extend the capabilities of a pretrained text-to-image diffusion model through a two-stage process. Firstly, we employ spatial finetuning to bridge the gap between the pretrained image model and the new video dataset. Subsequently, we introduce temporal learning to capture object motion. In terms of audio, we leverage sophisticated retrieval models to select and align audio elements that correspond to the plot and visual content of the movie. Extensive experiments demonstrate that our MovieFactory produces movies with realistic visuals, diverse scenes, and seamlessly fitting audio, offering users a novel and immersive experience. Generated samples can be found in YouTube or Bilibili (1080P).
RB-Dust -- A Reference-based Dataset for Vision-based Dust Removal
Jun 12, 2023
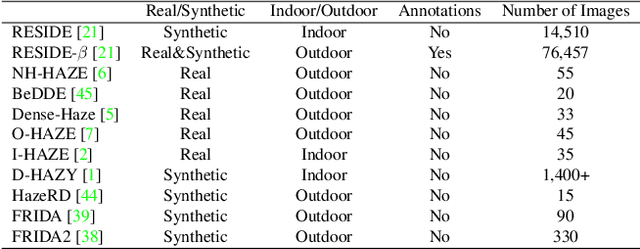


Dust in the agricultural landscape is a significant challenge and influences, for example, the environmental perception of autonomous agricultural machines. Image enhancement algorithms can be used to reduce dust. However, these require dusty and dust-free images of the same environment for validation. In fact, to date, there is no dataset that we are aware of that addresses this issue. Therefore, we present the agriscapes RB-Dust dataset, which is named after its purpose of reference-based dust removal. It is not possible to take pictures from the cabin during tillage, as this would cause shifts in the images. Because of this, we built a setup from which it is possible to take images from a stationary position close to the passing tractor. The test setup was based on a half-sided gate through which the tractor could drive. The field tests were carried out on a farm in Bavaria, Germany, during tillage. During the field tests, other parameters such as soil moisture and wind speed were controlled, as these significantly affect dust development. We validated our dataset with contrast enhancement and image dehazing algorithms and analyzed the generalizability from recordings from the moving tractor. Finally, we demonstrate the application of dust removal based on a high-level vision task, such as person classification. Our empirical study confirms the validity of RB-Dust for vision-based dust removal in agriculture.
Scale-Rotation-Equivariant Lie Group Convolution Neural Networks (Lie Group-CNNs)
Jun 12, 2023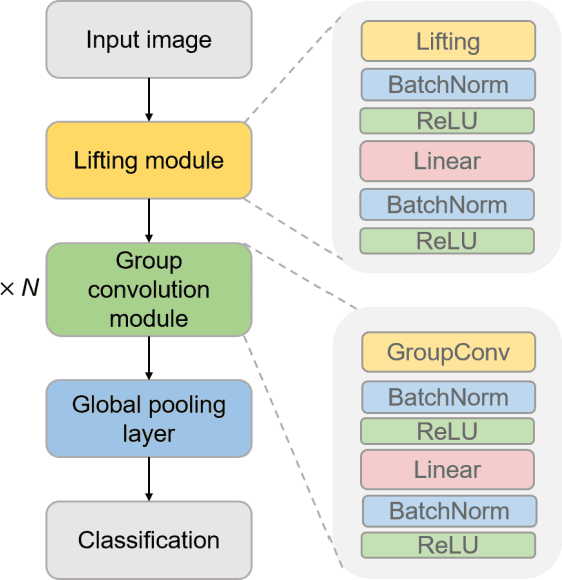
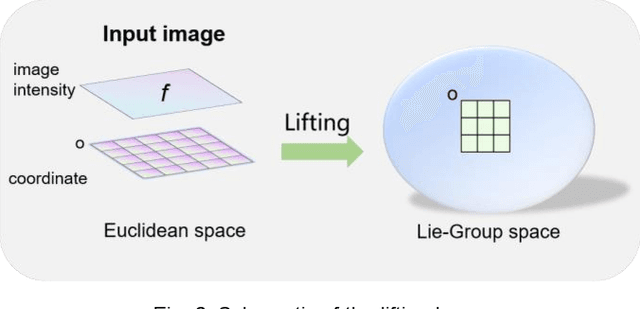

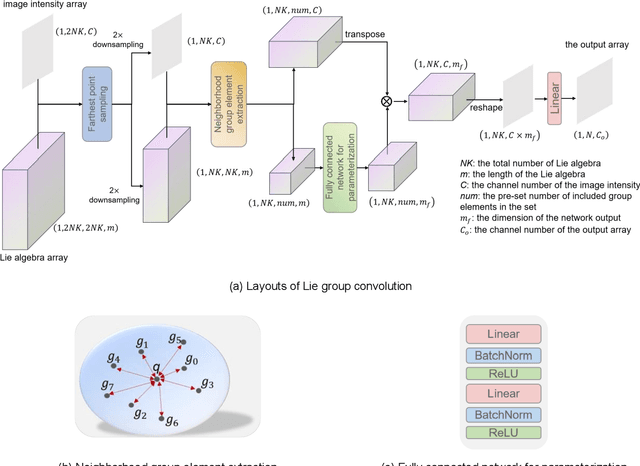
The weight-sharing mechanism of convolutional kernels ensures translation-equivariance of convolution neural networks (CNNs). Recently, rotation-equivariance has been investigated. However, research on scale-equivariance or simultaneous scale-rotation-equivariance is insufficient. This study proposes a Lie group-CNN, which can keep scale-rotation-equivariance for image classification tasks. The Lie group-CNN includes a lifting module, a series of group convolution modules, a global pooling layer, and a classification layer. The lifting module transfers the input image from Euclidean space to Lie group space, and the group convolution is parameterized through a fully connected network using Lie-algebra of Lie-group elements as inputs to achieve scale-rotation-equivariance. The Lie group SIM(2) is utilized to establish the Lie group-CNN with scale-rotation-equivariance. Scale-rotation-equivariance of Lie group-CNN is verified and achieves the best recognition accuracy on the blood cell dataset (97.50%) and the HAM10000 dataset (77.90%) superior to Lie algebra convolution network, dilation convolution, spatial transformer network, and scale-equivariant steerable network. In addition, the generalization ability of the Lie group-CNN on SIM(2) on rotation-equivariance is verified on rotated-MNIST and rotated-CIFAR10, and the robustness of the network is verified on SO(2) and SE(2). Therefore, the Lie group-CNN can successfully extract geometric features and performs equivariant recognition on images with rotation and scale transformations.
Hyperspectral Image Segmentation: A Preliminary Study on the Oral and Dental Spectral Image Database (ODSI-DB)
Mar 14, 2023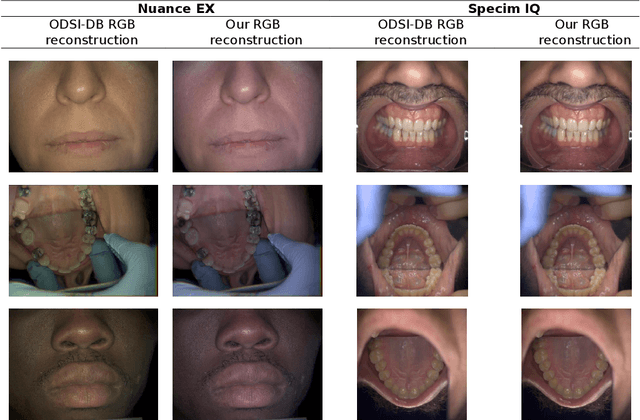
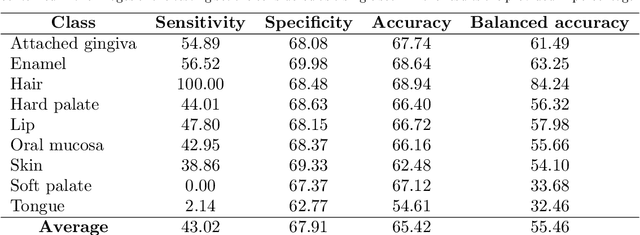
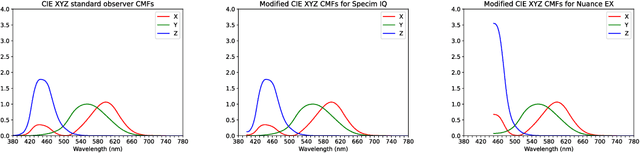
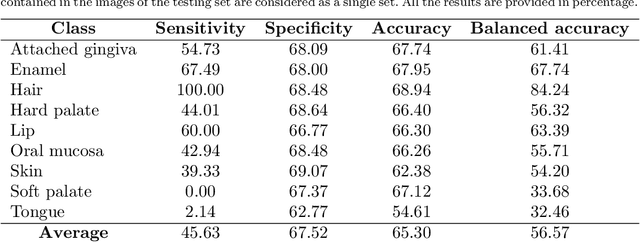
Visual discrimination of clinical tissue types remains challenging, with traditional RGB imaging providing limited contrast for such tasks. Hyperspectral imaging (HSI) is a promising technology providing rich spectral information that can extend far beyond three-channel RGB imaging. Moreover, recently developed snapshot HSI cameras enable real-time imaging with significant potential for clinical applications. Despite this, the investigation into the relative performance of HSI over RGB imaging for semantic segmentation purposes has been limited, particularly in the context of medical imaging. Here we compare the performance of state-of-the-art deep learning image segmentation methods when trained on hyperspectral images, RGB images, hyperspectral pixels (minus spatial context), and RGB pixels (disregarding spatial context). To achieve this, we employ the recently released Oral and Dental Spectral Image Database (ODSI-DB), which consists of 215 manually segmented dental reflectance spectral images with 35 different classes across 30 human subjects. The recent development of snapshot HSI cameras has made real-time clinical HSI a distinct possibility, though successful application requires a comprehensive understanding of the additional information HSI offers. Our work highlights the relative importance of spectral resolution, spectral range, and spatial information to both guide the development of HSI cameras and inform future clinical HSI applications.
GD-VDM: Generated Depth for better Diffusion-based Video Generation
Jun 19, 2023
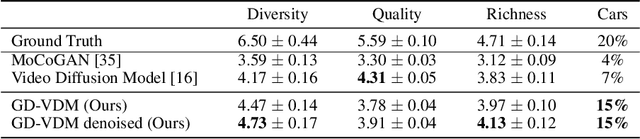
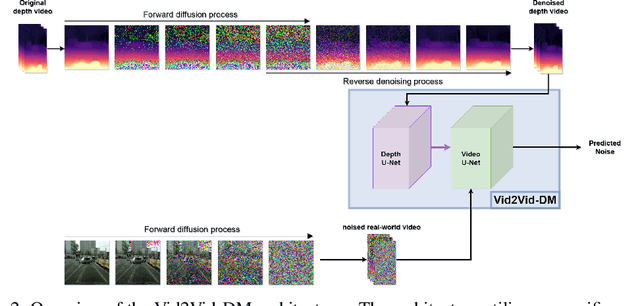

The field of generative models has recently witnessed significant progress, with diffusion models showing remarkable performance in image generation. In light of this success, there is a growing interest in exploring the application of diffusion models to other modalities. One such challenge is the generation of coherent videos of complex scenes, which poses several technical difficulties, such as capturing temporal dependencies and generating long, high-resolution videos. This paper proposes GD-VDM, a novel diffusion model for video generation, demonstrating promising results. GD-VDM is based on a two-phase generation process involving generating depth videos followed by a novel diffusion Vid2Vid model that generates a coherent real-world video. We evaluated GD-VDM on the Cityscapes dataset and found that it generates more diverse and complex scenes compared to natural baselines, demonstrating the efficacy of our approach.
Training Transformers with 4-bit Integers
Jun 22, 2023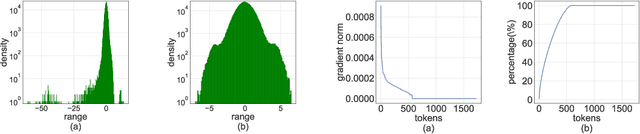
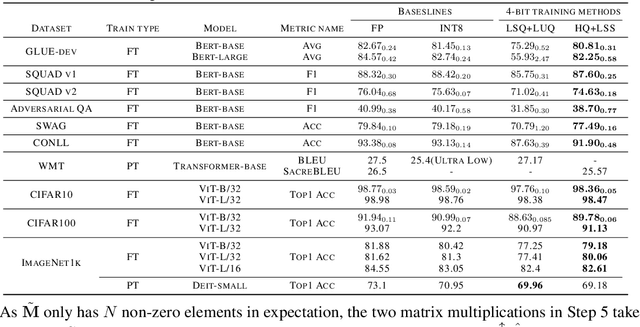
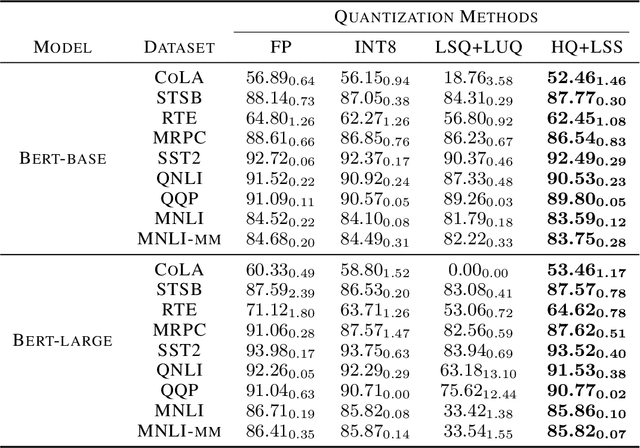
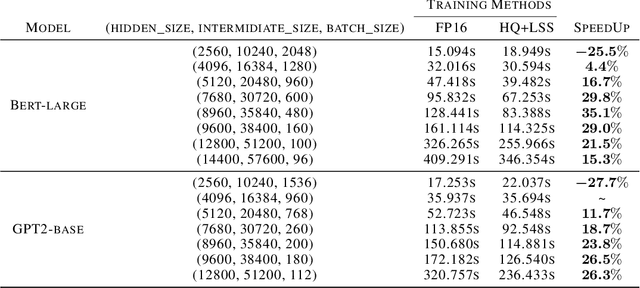
Quantizing the activation, weight, and gradient to 4-bit is promising to accelerate neural network training. However, existing 4-bit training methods require custom numerical formats which are not supported by contemporary hardware. In this work, we propose a training method for transformers with all matrix multiplications implemented with the INT4 arithmetic. Training with an ultra-low INT4 precision is challenging. To achieve this, we carefully analyze the specific structures of activation and gradients in transformers to propose dedicated quantizers for them. For forward propagation, we identify the challenge of outliers and propose a Hadamard quantizer to suppress the outliers. For backpropagation, we leverage the structural sparsity of gradients by proposing bit splitting and leverage score sampling techniques to quantize gradients accurately. Our algorithm achieves competitive accuracy on a wide range of tasks including natural language understanding, machine translation, and image classification. Unlike previous 4-bit training methods, our algorithm can be implemented on the current generation of GPUs. Our prototypical linear operator implementation is up to 2.2 times faster than the FP16 counterparts and speeds up the training by up to 35.1%.
Squeeze, Recover and Relabel: Dataset Condensation at ImageNet Scale From A New Perspective
Jun 22, 2023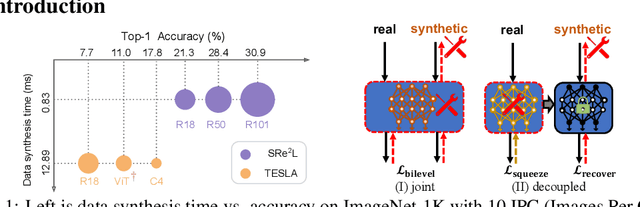
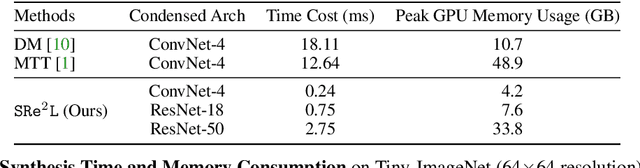
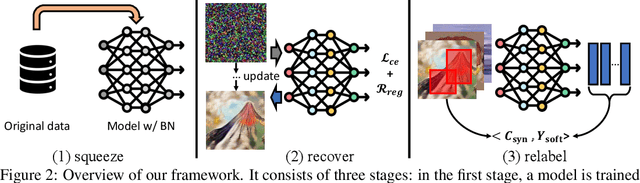
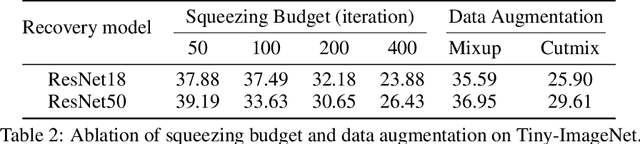
We present a new dataset condensation framework termed Squeeze, Recover and Relabel (SRe$^2$L) that decouples the bilevel optimization of model and synthetic data during training, to handle varying scales of datasets, model architectures and image resolutions for effective dataset condensation. The proposed method demonstrates flexibility across diverse dataset scales and exhibits multiple advantages in terms of arbitrary resolutions of synthesized images, low training cost and memory consumption with high-resolution training, and the ability to scale up to arbitrary evaluation network architectures. Extensive experiments are conducted on Tiny-ImageNet and full ImageNet-1K datasets. Under 50 IPC, our approach achieves the highest 42.5% and 60.8% validation accuracy on Tiny-ImageNet and ImageNet-1K, outperforming all previous state-of-the-art methods by margins of 14.5% and 32.9%, respectively. Our approach also outperforms MTT by approximately 52$\times$ (ConvNet-4) and 16$\times$ (ResNet-18) faster in speed with less memory consumption of 11.6$\times$ and 6.4$\times$ during data synthesis. Our code and condensed datasets of 50, 200 IPC with 4K recovery budget are available at https://zeyuanyin.github.io/projects/SRe2L/.