 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Sampling in Diffusion Models with Marginal Preserving Particle Guidance
May 07, 2026We present EDDY (Exact-marginal Diversification via Divergence-free dYnamics), a guidance mechanism for diffusion and flow matching models that promotes diversity among samples generated while maintaining quality. EDDY exploits symmetries of the Fokker-Planck equation, using drift perturbations that change particle trajectories while preserving the evolving marginal distribution. We instantiate this principle through kernel-based anti-symmetric pairwise matrix fields, constructed from the repulsive directions. The resulting divergence-free dynamics promote diversity at the joint particle level while preserving each particle's marginal distribution without any additional training. As computing the guidance can be computationally expensive in cases such as text-to-image generation with perceptual embeddings, we propose practical approximations as an effective and efficient solution. Experiments on synthetic distributions and text-to-image generation show that EDDY improves diversity while maintaining strong distributional fidelity compared to common baselines.
Few-Shot Speech Deepfake Detection Adaptation with Gaussian Processes
May 29, 2025


Recent advancements in Text-to-Speech (TTS) models, particularly in voice cloning, have intensified the demand for adaptable and efficient deepfake detection methods. As TTS systems continue to evolve, detection models must be able to efficiently adapt to previously unseen generation models with minimal data. This paper introduces ADD-GP, a few-shot adaptive framework based on a Gaussian Process (GP) classifier for Audio Deepfake Detection (ADD). We show how the combination of a powerful deep embedding model with the Gaussian processes flexibility can achieve strong performance and adaptability. Additionally, we show this approach can also be used for personalized detection, with greater robustness to new TTS models and one-shot adaptability. To support our evaluation, a benchmark dataset is constructed for this task using new state-of-the-art voice cloning models.
Inverse Problem Sampling in Latent Space Using Sequential Monte Carlo
Feb 09, 2025



In image processing, solving inverse problems is the task of finding plausible reconstructions of an image that was corrupted by some (usually known) degradation model. Commonly, this process is done using a generative image model that can guide the reconstruction towards solutions that appear natural. The success of diffusion models over the last few years has made them a leading candidate for this task. However, the sequential nature of diffusion models makes this conditional sampling process challenging. Furthermore, since diffusion models are often defined in the latent space of an autoencoder, the encoder-decoder transformations introduce additional difficulties. Here, we suggest a novel sampling method based on sequential Monte Carlo (SMC) in the latent space of diffusion models. We use the forward process of the diffusion model to add additional auxiliary observations and then perform an SMC sampling as part of the backward process. Empirical evaluations on ImageNet and FFHQ show the benefits of our approach over competing methods on various inverse problem tasks.
Efficient Image Restoration via Latent Consistency Flow Matching
Feb 05, 2025



Recent advances in generative image restoration (IR) have demonstrated impressive results. However, these methods are hindered by their substantial size and computational demands, rendering them unsuitable for deployment on edge devices. This work introduces ELIR, an Efficient Latent Image Restoration method. ELIR operates in latent space by first predicting the latent representation of the minimum mean square error (MMSE) estimator and then transporting this estimate to high-quality images using a latent consistency flow-based model. Consequently, ELIR is more than 4x faster compared to the state-of-the-art diffusion and flow-based approaches. Moreover, ELIR is also more than 4x smaller, making it well-suited for deployment on resource-constrained edge devices. Comprehensive evaluations of various image restoration tasks show that ELIR achieves competitive results, effectively balancing distortion and perceptual quality metrics while offering improved efficiency in terms of memory and computation.
Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors
Jun 04, 2024Generating 3D visual scenes is at the forefront of visual generative AI, but current 3D generation techniques struggle with generating scenes with multiple high-resolution objects. Here we introduce Lay-A-Scene, which solves the task of Open-set 3D Object Arrangement, effectively arranging unseen objects. Given a set of 3D objects, the task is to find a plausible arrangement of these objects in a scene. We address this task by leveraging pre-trained text-to-image models. We personalize the model and explain how to generate images of a scene that contains multiple predefined objects without neglecting any of them. Then, we describe how to infer the 3D poses and arrangement of objects from a 2D generated image by finding a consistent projection of objects onto the 2D scene. We evaluate the quality of Lay-A-Scene using 3D objects from Objaverse and human raters and find that it often generates coherent and feasible 3D object arrangements.
Bayesian Uncertainty for Gradient Aggregation in Multi-Task Learning
Feb 06, 2024



As machine learning becomes more prominent there is a growing demand to perform several inference tasks in parallel. Running a dedicated model for each task is computationally expensive and therefore there is a great interest in multi-task learning (MTL). MTL aims at learning a single model that solves several tasks efficiently. Optimizing MTL models is often achieved by computing a single gradient per task and aggregating them for obtaining a combined update direction. However, these approaches do not consider an important aspect, the sensitivity in the gradient dimensions. Here, we introduce a novel gradient aggregation approach using Bayesian inference. We place a probability distribution over the task-specific parameters, which in turn induce a distribution over the gradients of the tasks. This additional valuable information allows us to quantify the uncertainty in each of the gradients dimensions, which can then be factored in when aggregating them. We empirically demonstrate the benefits of our approach in a variety of datasets, achieving state-of-the-art performance.
De-Confusing Pseudo-Labels in Source-Free Domain Adaptation
Jan 03, 2024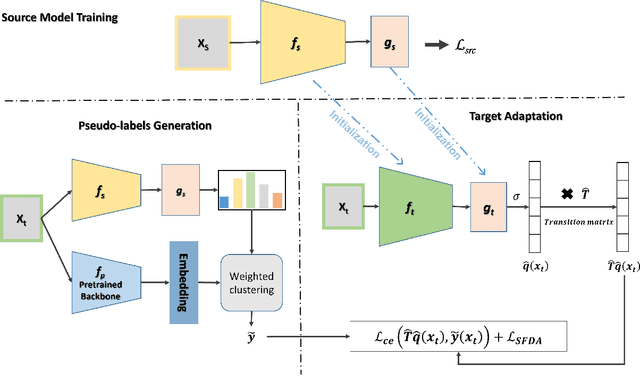
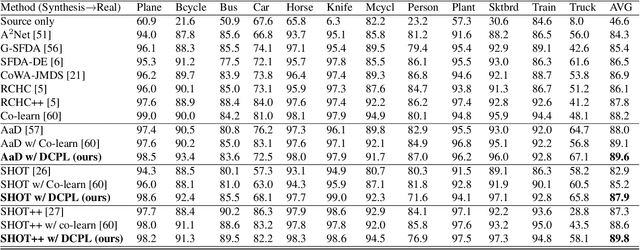
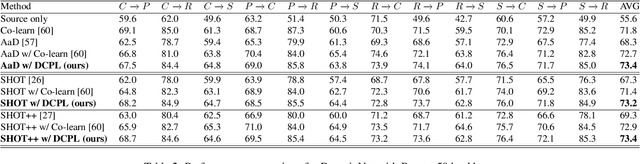
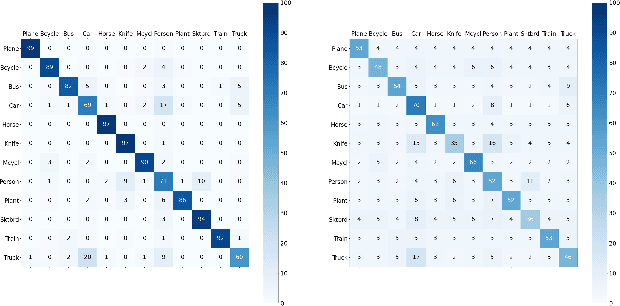
Source-free domain adaptation (SFDA) aims to transfer knowledge learned from a source domain to an unlabeled target domain, where the source data is unavailable during adaptation. Existing approaches for SFDA focus on self-training usually including well-established entropy minimization and pseudo-labeling techniques. Recent work suggested a co-learning strategy to improve the quality of the generated target pseudo-labels using robust pretrained networks such as Swin-B. However, since the generated pseudo-labels depend on the source model, they may be noisy due to domain shift. In this paper, we view SFDA from the perspective of label noise learning and learn to de-confuse the pseudo-labels. More specifically, we learn a noise transition matrix of the pseudo-labels to capture the label corruption of each class and learn the underlying true label distribution. Estimating the noise transition matrix enables a better true class-posterior estimation results with better prediction accuracy. We demonstrate the effectiveness of our approach applied with several SFDA methods: SHOT, SHOT++, and AaD. We obtain state-of-the-art results on three domain adaptation datasets: VisDA, DomainNet, and OfficeHome.
Data Augmentations in Deep Weight Spaces
Nov 15, 2023Learning in weight spaces, where neural networks process the weights of other deep neural networks, has emerged as a promising research direction with applications in various fields, from analyzing and editing neural fields and implicit neural representations, to network pruning and quantization. Recent works designed architectures for effective learning in that space, which takes into account its unique, permutation-equivariant, structure. Unfortunately, so far these architectures suffer from severe overfitting and were shown to benefit from large datasets. This poses a significant challenge because generating data for this learning setup is laborious and time-consuming since each data sample is a full set of network weights that has to be trained. In this paper, we address this difficulty by investigating data augmentations for weight spaces, a set of techniques that enable generating new data examples on the fly without having to train additional input weight space elements. We first review several recently proposed data augmentation schemes %that were proposed recently and divide them into categories. We then introduce a novel augmentation scheme based on the Mixup method. We evaluate the performance of these techniques on existing benchmarks as well as new benchmarks we generate, which can be valuable for future studies.
GD-VDM: Generated Depth for better Diffusion-based Video Generation
Jun 19, 2023



The field of generative models has recently witnessed significant progress, with diffusion models showing remarkable performance in image generation. In light of this success, there is a growing interest in exploring the application of diffusion models to other modalities. One such challenge is the generation of coherent videos of complex scenes, which poses several technical difficulties, such as capturing temporal dependencies and generating long, high-resolution videos. This paper proposes GD-VDM, a novel diffusion model for video generation, demonstrating promising results. GD-VDM is based on a two-phase generation process involving generating depth videos followed by a novel diffusion Vid2Vid model that generates a coherent real-world video. We evaluated GD-VDM on the Cityscapes dataset and found that it generates more diverse and complex scenes compared to natural baselines, demonstrating the efficacy of our approach.
Guided Deep Kernel Learning
Feb 19, 2023Combining Gaussian processes with the expressive power of deep neural networks is commonly done nowadays through deep kernel learning (DKL). Unfortunately, due to the kernel optimization process, this often results in losing their Bayesian benefits. In this study, we present a novel approach for learning deep kernels by utilizing infinite-width neural networks. We propose to use the Neural Network Gaussian Process (NNGP) model as a guide to the DKL model in the optimization process. Our approach harnesses the reliable uncertainty estimation of the NNGPs to adapt the DKL target confidence when it encounters novel data points. As a result, we get the best of both worlds, we leverage the Bayesian behavior of the NNGP, namely its robustness to overfitting, and accurate uncertainty estimation, while maintaining the generalization abilities, scalability, and flexibility of deep kernels. Empirically, we show on multiple benchmark datasets of varying sizes and dimensionality, that our method is robust to overfitting, has good predictive performance, and provides reliable uncertainty estimations.