 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 07, 2023
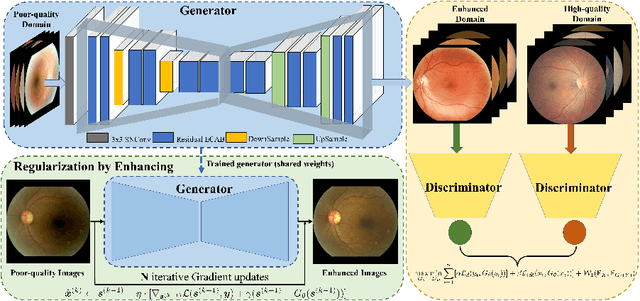
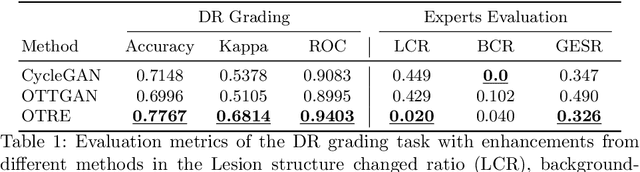
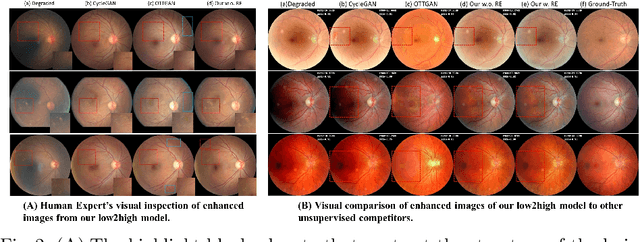
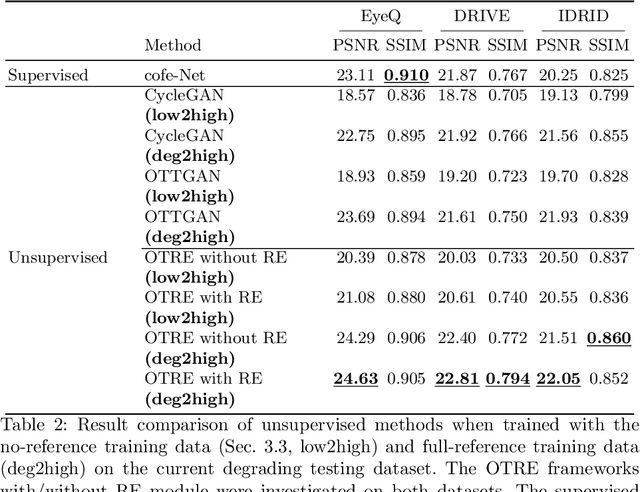
Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Steered Mixture of Experts Regression for Image Denoising with Multi-Model-Inference
Mar 30, 2023
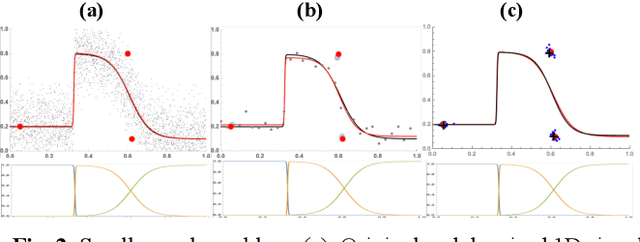
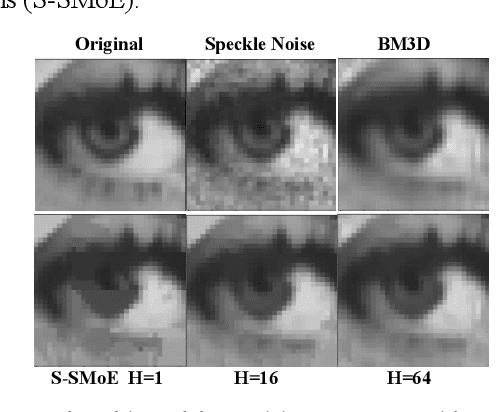
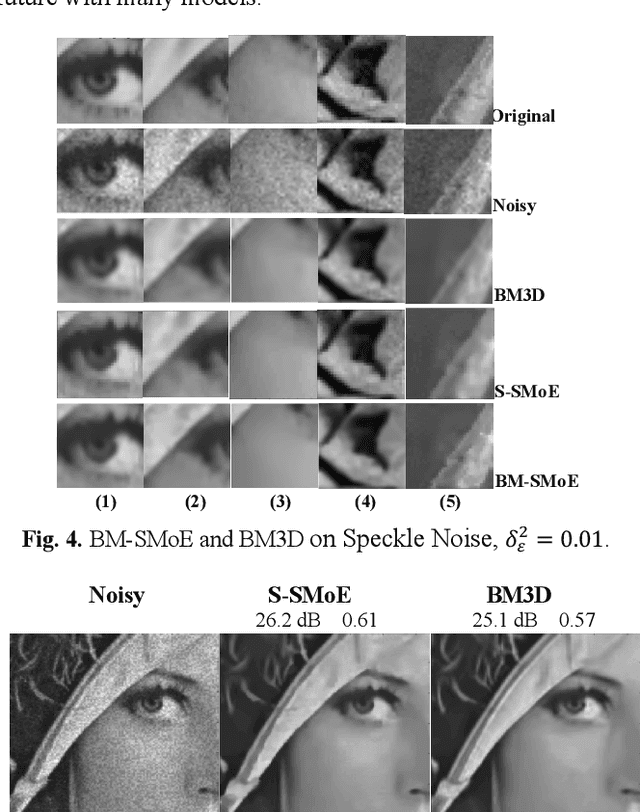
In this paper we introduce a novel block-based regression strategy for image denoising based on edge-aware Steered-Mixture-of-Experts (SMoE) models. SMoEs provide very sparse image representations, able to model sharp edges as well as smooth transitions in images efficiently with few parameters. A multi-model inference strategy is developed that improves significantly the denoising capacity of single SMoE models. We show that the important edge reconstruction properties of SMoEs are well preserved, even when many models are fused under severe noise. We investigate model-inference from local neighborhood blocks as well as from distant blocks using block-matching as in BM3D. Our initial results indicate that SMoE multi-model regression can provide promising results compared to state-of-the-art BM3D with excellent edge quality.
Resolution-Invariant Image Classification based on Fourier Neural Operators
Apr 02, 2023
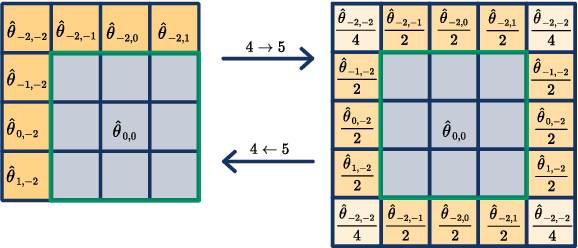
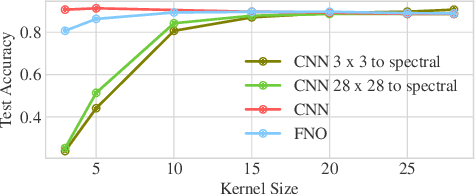
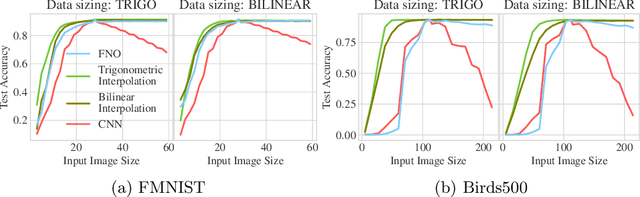
In this paper we investigate the use of Fourier Neural Operators (FNOs) for image classification in comparison to standard Convolutional Neural Networks (CNNs). Neural operators are a discretization-invariant generalization of neural networks to approximate operators between infinite dimensional function spaces. FNOs - which are neural operators with a specific parametrization - have been applied successfully in the context of parametric PDEs. We derive the FNO architecture as an example for continuous and Fr\'echet-differentiable neural operators on Lebesgue spaces. We further show how CNNs can be converted into FNOs and vice versa and propose an interpolation-equivariant adaptation of the architecture.
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023
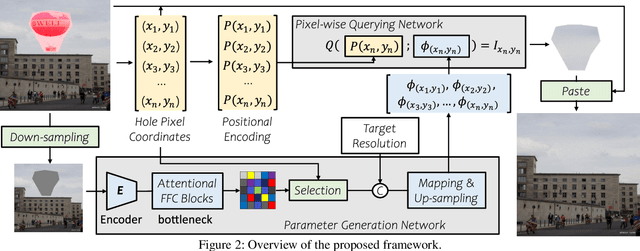
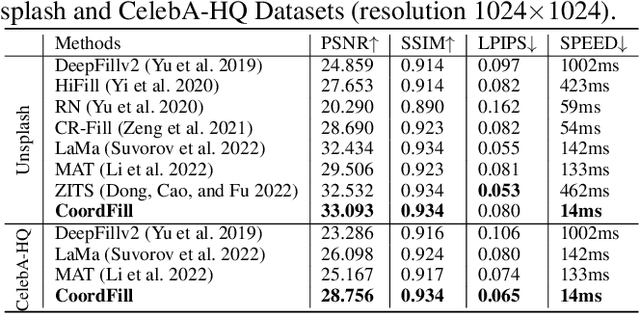
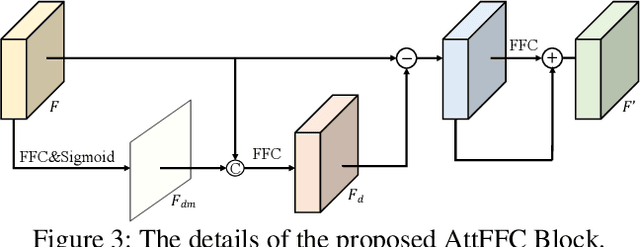
Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.
XTransCT: Ultra-Fast Volumetric CT Reconstruction using Two Orthogonal X-Ray Projections via a Transformer Network
May 31, 2023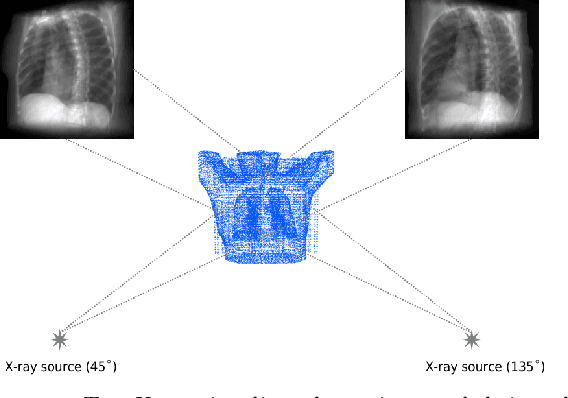
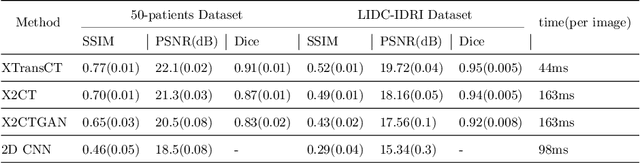
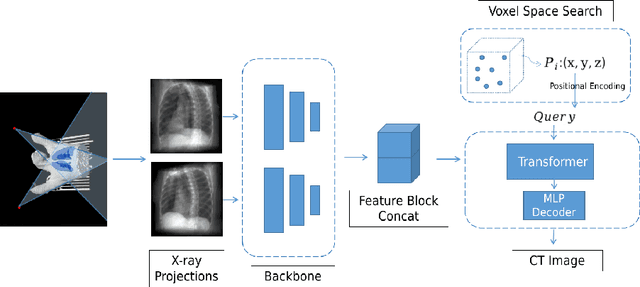
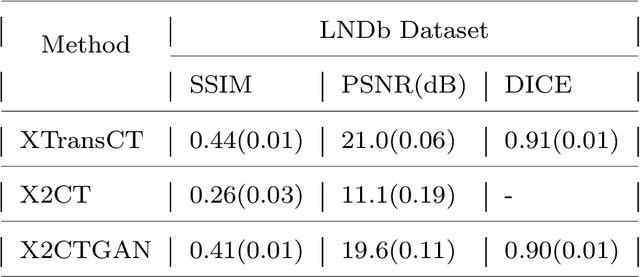
Computed tomography (CT) scans offer a detailed, three-dimensional representation of patients' internal organs. However, conventional CT reconstruction techniques necessitate acquiring hundreds or thousands of x-ray projections through a complete rotational scan of the body, making navigation or positioning during surgery infeasible. In image-guided radiation therapy, a method that reconstructs ultra-sparse X-ray projections into CT images, we can exploit the substantially reduced radiation dose and minimize equipment burden for localization and navigation. In this study, we introduce a novel Transformer architecture, termed XTransCT, devised to facilitate real-time reconstruction of CT images from two-dimensional X-ray images. We assess our approach regarding image quality and structural reliability using a dataset of fifty patients, supplied by a hospital, as well as the larger public dataset LIDC-IDRI, which encompasses thousands of patients. Additionally, we validated our algorithm's generalizability on the LNDb dataset. Our findings indicate that our algorithm surpasses other methods in image quality, structural precision, and generalizability. Moreover, in comparison to previous 3D convolution-based approaches, we note a substantial speed increase of approximately 300 $\%$, achieving 44 ms per 3D image reconstruction. To guarantee the replicability of our results, we have made our code publicly available.
Spotlight Attention: Robust Object-Centric Learning With a Spatial Locality Prior
May 31, 2023



The aim of object-centric vision is to construct an explicit representation of the objects in a scene. This representation is obtained via a set of interchangeable modules called \emph{slots} or \emph{object files} that compete for local patches of an image. The competition has a weak inductive bias to preserve spatial continuity; consequently, one slot may claim patches scattered diffusely throughout the image. In contrast, the inductive bias of human vision is strong, to the degree that attention has classically been described with a spotlight metaphor. We incorporate a spatial-locality prior into state-of-the-art object-centric vision models and obtain significant improvements in segmenting objects in both synthetic and real-world datasets. Similar to human visual attention, the combination of image content and spatial constraints yield robust unsupervised object-centric learning, including less sensitivity to model hyperparameters.
Semantic Image Attack for Visual Model Diagnosis
Mar 23, 2023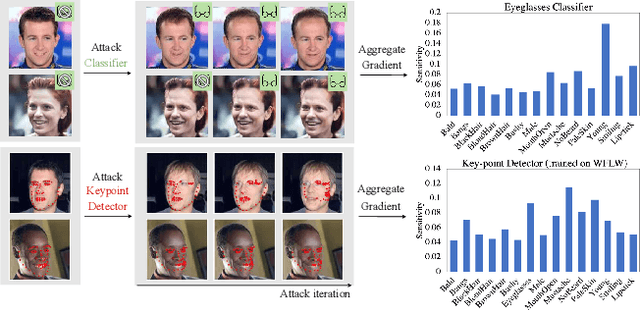

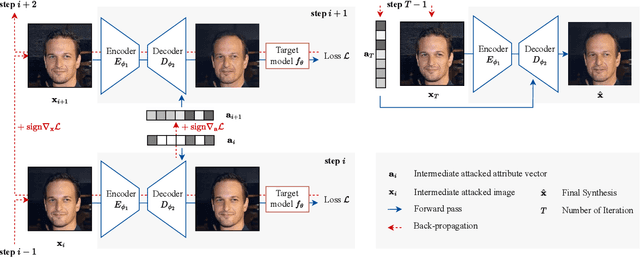
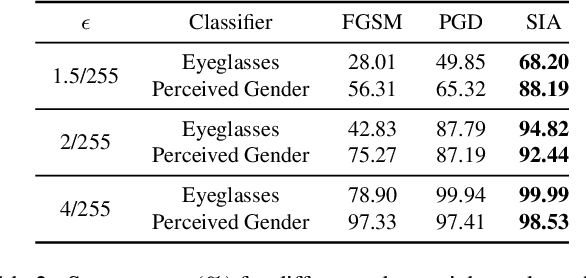
In practice, metric analysis on a specific train and test dataset does not guarantee reliable or fair ML models. This is partially due to the fact that obtaining a balanced, diverse, and perfectly labeled dataset is typically expensive, time-consuming, and error-prone. Rather than relying on a carefully designed test set to assess ML models' failures, fairness, or robustness, this paper proposes Semantic Image Attack (SIA), a method based on the adversarial attack that provides semantic adversarial images to allow model diagnosis, interpretability, and robustness. Traditional adversarial training is a popular methodology for robustifying ML models against attacks. However, existing adversarial methods do not combine the two aspects that enable the interpretation and analysis of the model's flaws: semantic traceability and perceptual quality. SIA combines the two features via iterative gradient ascent on a predefined semantic attribute space and the image space. We illustrate the validity of our approach in three scenarios for keypoint detection and classification. (1) Model diagnosis: SIA generates a histogram of attributes that highlights the semantic vulnerability of the ML model (i.e., attributes that make the model fail). (2) Stronger attacks: SIA generates adversarial examples with visually interpretable attributes that lead to higher attack success rates than baseline methods. The adversarial training on SIA improves the transferable robustness across different gradient-based attacks. (3) Robustness to imbalanced datasets: we use SIA to augment the underrepresented classes, which outperforms strong augmentation and re-balancing baselines.
Controllable Textual Inversion for Personalized Text-to-Image Generation
Apr 12, 2023
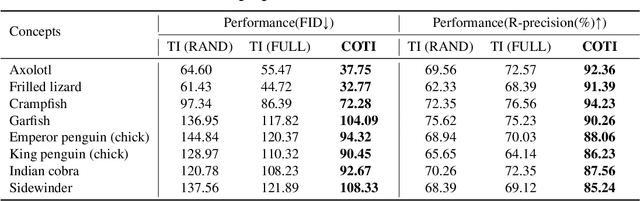
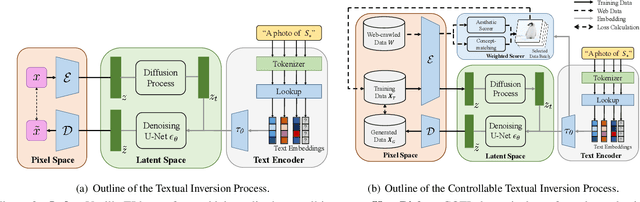
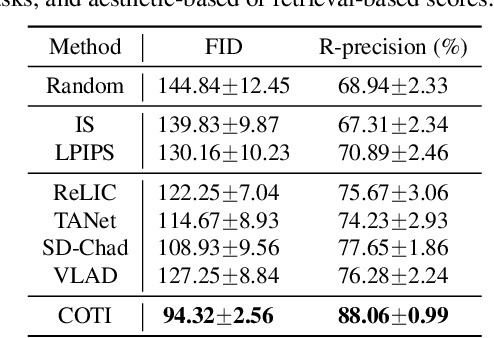
The recent large-scale generative modeling has attained unprecedented performance especially in producing high-fidelity images driven by text prompts. Text inversion (TI), alongside the text-to-image model backbones, is proposed as an effective technique in personalizing the generation when the prompts contain user-defined, unseen or long-tail concept tokens. Despite that, we find and show that the deployment of TI remains full of "dark-magics" -- to name a few, the harsh requirement of additional datasets, arduous human efforts in the loop and lack of robustness. In this work, we propose a much-enhanced version of TI, dubbed Controllable Textual Inversion (COTI), in resolving all the aforementioned problems and in turn delivering a robust, data-efficient and easy-to-use framework. The core to COTI is a theoretically-guided loss objective instantiated with a comprehensive and novel weighted scoring mechanism, encapsulated by an active-learning paradigm. The extensive results show that COTI significantly outperforms the prior TI-related approaches with a 26.05 decrease in the FID score and a 23.00% boost in the R-precision.
Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
Jun 06, 2023
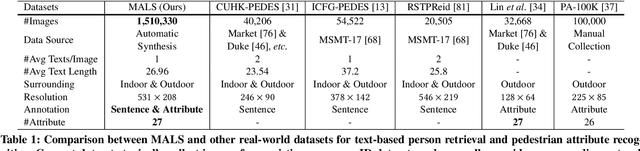
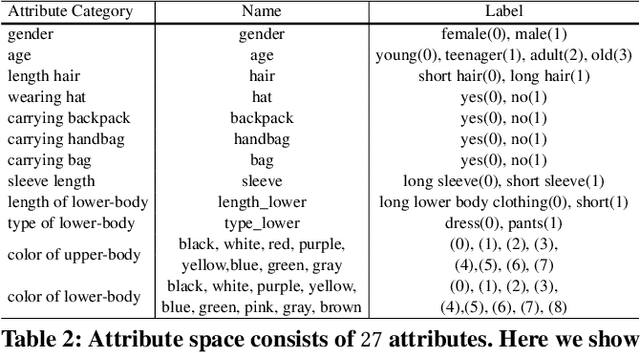

In this paper, we introduce a large Multi-Attribute and Language Search dataset for text-based person retrieval, called MALS, and explore the feasibility of performing pre-training on both attribute recognition and image-text matching tasks in one stone. In particular, MALS contains 1,510,330 image-text pairs, which is about 37.5 times larger than prevailing CUHK-PEDES, and all images are annotated with 27 attributes. Considering the privacy concerns and annotation costs, we leverage the off-the-shelf diffusion models to generate the dataset. To verify the feasibility of learning from the generated data, we develop a new joint Attribute Prompt Learning and Text Matching Learning (APTM) framework, considering the shared knowledge between attribute and text. As the name implies, APTM contains an attribute prompt learning stream and a text matching learning stream. (1) The attribute prompt learning leverages the attribute prompts for image-attribute alignment, which enhances the text matching learning. (2) The text matching learning facilitates the representation learning on fine-grained details, and in turn, boosts the attribute prompt learning. Extensive experiments validate the effectiveness of the pre-training on MALS, achieving state-of-the-art retrieval performance via APTM on three challenging real-world benchmarks. In particular, APTM achieves a consistent improvement of +6.60%, +7.39%, and +15.90% Recall@1 accuracy on CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets by a clear margin, respectively.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023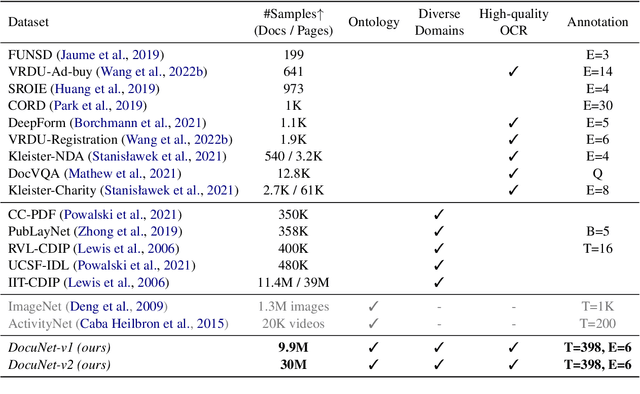


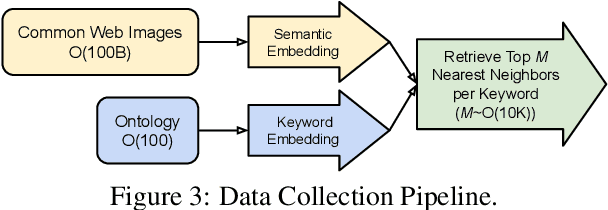
Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.