 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Concentration Phenomena of Mean-Field Transformers in the Low-Temperature Regime
May 11, 2026Transformers with self-attention modules as their core components have become an integral architecture in modern large language and foundation models. In this paper, we study the evolution of tokens in deep encoder-only transformers at inference time which is described in the large-token limit by a mean-field continuity equation. Leveraging ideas from the convergence analysis of interacting multi-particle systems, with particles corresponding to tokens, we prove that the token distribution rapidly concentrates onto the push-forward of the initial distribution under a projection map induced by the key, query, and value matrices, and remains metastable for moderate times. Specifically, we show that the Wasserstein distance of the two distributions scales like $\sqrt{{\log(β+1)}/β}\exp(Ct)+\exp(-ct)$ in terms of the temperature parameter $β^{-1}\to 0$ and inference time $t\geq 0$. For the proof, we establish Lyapunov-type estimates for the zero-temperature equation, identify its limit as $t\to\infty$, and employ a stability estimate in Wasserstein space together with a quantitative Laplace principle to couple the two equations. Our result implies that for time scales of order $\logβ$ the token distribution concentrates at the identified limiting distribution. Numerical experiments confirm this and, beyond that, complement our theory by showing that for finite $β$ and large $t$ the dynamics enter a different terminal phase, dominated by the spectrum of the value matrix.
Allure of Craquelure: A Variational-Generative Approach to Crack Detection in Paintings
Feb 10, 2026Recent advances in imaging technologies, deep learning and numerical performance have enabled non-invasive detailed analysis of artworks, supporting their documentation and conservation. In particular, automated detection of craquelure in digitized paintings is crucial for assessing degradation and guiding restoration, yet remains challenging due to the possibly complex scenery and the visual similarity between cracks and crack-like artistic features such as brush strokes or hair. We propose a hybrid approach that models crack detection as an inverse problem, decomposing an observed image into a crack-free painting and a crack component. A deep generative model is employed as powerful prior for the underlying artwork, while crack structures are captured using a Mumford--Shah-type variational functional together with a crack prior. Joint optimization yields a pixel-level map of crack localizations in the painting.
Introduction to Regularization and Learning Methods for Inverse Problems
Aug 25, 2025These lecture notes evolve around mathematical concepts arising in inverse problems. We start by introducing inverse problems through examples such as differentiation, deconvolution, computed tomography and phase retrieval. This then leads us to the framework of well-posedness and first considerations regarding reconstruction and inversion approaches. The second chapter then first deals with classical regularization theory of inverse problems in Hilbert spaces. After introducing the pseudo-inverse, we review the concept of convergent regularization. Within this chapter we then proceed to ask the question of how to realize practical reconstruction algorithms. Here, we mainly focus on Tikhonov and sparsity promoting regularization in finite dimensional spaces. In the third chapter, we dive into modern deep-learning methods, which allow solving inverse problems in a data-dependent approach. The intersection between inverse problems and machine learning is a rapidly growing field and our exposition here restricts itself to a very limited selection of topics. Among them are learned regularization, fully-learned Bayesian estimation, post-processing strategies and plug-n-play methods.
MirrorCBO: A consensus-based optimization method in the spirit of mirror descent
Jan 21, 2025



In this work we propose MirrorCBO, a consensus-based optimization (CBO) method which generalizes standard CBO in the same way that mirror descent generalizes gradient descent. For this we apply the CBO methodology to a swarm of dual particles and retain the primal particle positions by applying the inverse of the mirror map, which we parametrize as the subdifferential of a strongly convex function $\phi$. In this way, we combine the advantages of a derivative-free non-convex optimization algorithm with those of mirror descent. As a special case, the method extends CBO to optimization problems with convex constraints. Assuming bounds on the Bregman distance associated to $\phi$, we provide asymptotic convergence results for MirrorCBO with explicit exponential rate. Another key contribution is an exploratory numerical study of this new algorithm across different application settings, focusing on (i) sparsity-inducing optimization, and (ii) constrained optimization, demonstrating the competitive performance of MirrorCBO. We observe empirically that the method can also be used for optimization on (non-convex) submanifolds of Euclidean space, can be adapted to mirrored versions of other recent CBO variants, and that it inherits from mirror descent the capability to select desirable minimizers, like sparse ones. We also include an overview of recent CBO approaches for constrained optimization and compare their performance to MirrorCBO.
Adversarial flows: A gradient flow characterization of adversarial attacks
Jun 11, 2024A popular method to perform adversarial attacks on neuronal networks is the so-called fast gradient sign method and its iterative variant. In this paper, we interpret this method as an explicit Euler discretization of a differential inclusion, where we also show convergence of the discretization to the associated gradient flow. To do so, we consider the concept of p-curves of maximal slope in the case $p=\infty$. We prove existence of $\infty$-curves of maximum slope and derive an alternative characterization via differential inclusions. Furthermore, we also consider Wasserstein gradient flows for potential energies, where we show that curves in the Wasserstein space can be characterized by a representing measure on the space of curves in the underlying Banach space, which fulfill the differential inclusion. The application of our theory to the finite-dimensional setting is twofold: On the one hand, we show that a whole class of normalized gradient descent methods (in particular signed gradient descent) converge, up to subsequences, to the flow, when sending the step size to zero. On the other hand, in the distributional setting, we show that the inner optimization task of adversarial training objective can be characterized via $\infty$-curves of maximum slope on an appropriate optimal transport space.
Learning a Sparse Representation of Barron Functions with the Inverse Scale Space Flow
Dec 05, 2023This paper presents a method for finding a sparse representation of Barron functions. Specifically, given an $L^2$ function $f$, the inverse scale space flow is used to find a sparse measure $\mu$ minimising the $L^2$ loss between the Barron function associated to the measure $\mu$ and the function $f$. The convergence properties of this method are analysed in an ideal setting and in the cases of measurement noise and sampling bias. In an ideal setting the objective decreases strictly monotone in time to a minimizer with $\mathcal{O}(1/t)$, and in the case of measurement noise or sampling bias the optimum is achieved up to a multiplicative or additive constant. This convergence is preserved on discretization of the parameter space, and the minimizers on increasingly fine discretizations converge to the optimum on the full parameter space.
Resolution-Invariant Image Classification based on Fourier Neural Operators
Apr 02, 2023In this paper we investigate the use of Fourier Neural Operators (FNOs) for image classification in comparison to standard Convolutional Neural Networks (CNNs). Neural operators are a discretization-invariant generalization of neural networks to approximate operators between infinite dimensional function spaces. FNOs - which are neural operators with a specific parametrization - have been applied successfully in the context of parametric PDEs. We derive the FNO architecture as an example for continuous and Fr\'echet-differentiable neural operators on Lebesgue spaces. We further show how CNNs can be converted into FNOs and vice versa and propose an interpolation-equivariant adaptation of the architecture.
Uniform Convergence Rates for Lipschitz Learning on Graphs
Nov 24, 2021
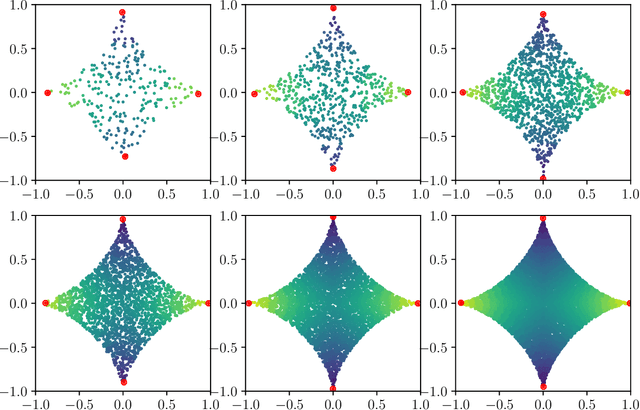
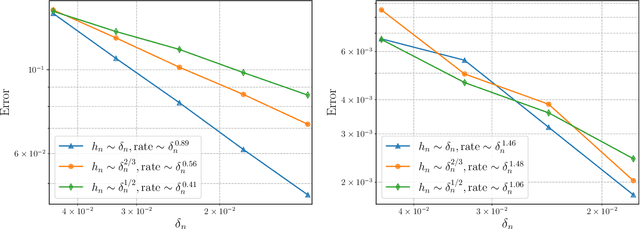
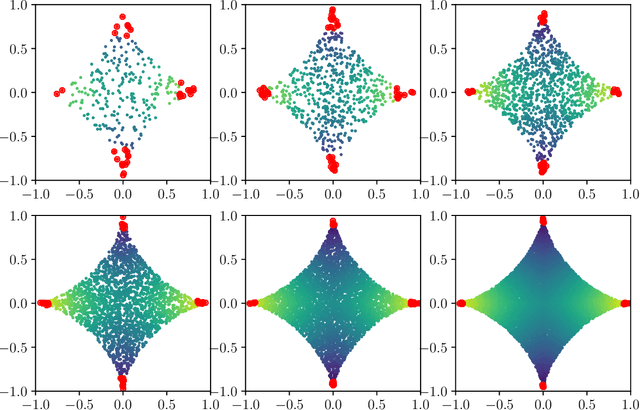
Lipschitz learning is a graph-based semi-supervised learning method where one extends labels from a labeled to an unlabeled data set by solving the infinity Laplace equation on a weighted graph. In this work we prove uniform convergence rates for solutions of the graph infinity Laplace equation as the number of vertices grows to infinity. Their continuum limits are absolutely minimizing Lipschitz extensions with respect to the geodesic metric of the domain where the graph vertices are sampled from. We work under very general assumptions on the graph weights, the set of labeled vertices, and the continuum domain. Our main contribution is that we obtain quantitative convergence rates even for very sparsely connected graphs, as they typically appear in applications like semi-supervised learning. In particular, our framework allows for graph bandwidths down to the connectivity radius. For proving this we first show a quantitative convergence statement for graph distance functions to geodesic distance functions in the continuum. Using the "comparison with distance functions" principle, we can pass these convergence statements to infinity harmonic functions and absolutely minimizing Lipschitz extensions.
Neural Architecture Search via Bregman Iterations
Jun 04, 2021

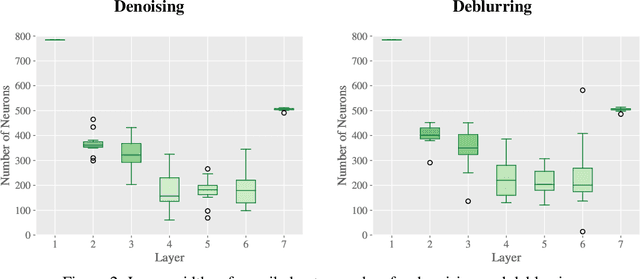
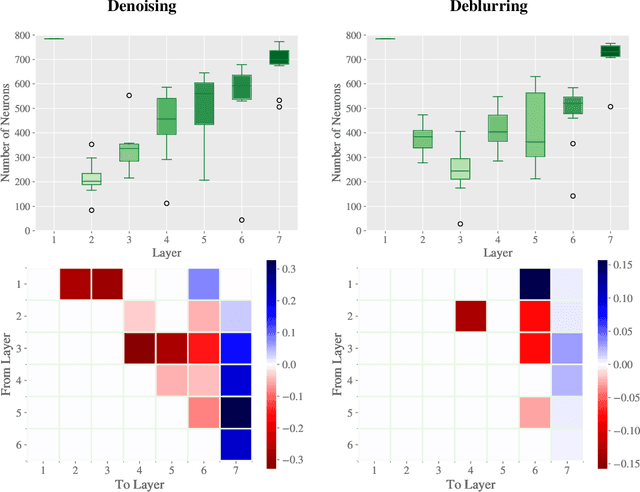
We propose a novel strategy for Neural Architecture Search (NAS) based on Bregman iterations. Starting from a sparse neural network our gradient-based one-shot algorithm gradually adds relevant parameters in an inverse scale space manner. This allows the network to choose the best architecture in the search space which makes it well-designed for a given task, e.g., by adding neurons or skip connections. We demonstrate that using our approach one can unveil, for instance, residual autoencoders for denoising, deblurring, and classification tasks. Code is available at https://github.com/TimRoith/BregmanLearning.
A Bregman Learning Framework for Sparse Neural Networks
May 17, 2021

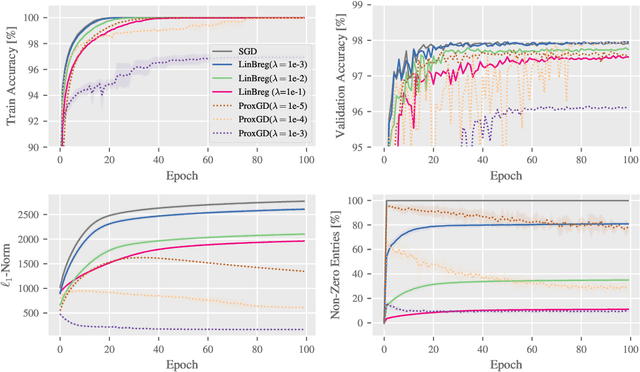
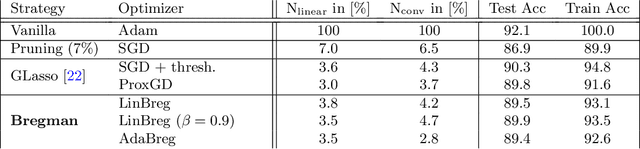
We propose a learning framework based on stochastic Bregman iterations to train sparse neural networks with an inverse scale space approach. We derive a baseline algorithm called LinBreg, an accelerated version using momentum, and AdaBreg, which is a Bregmanized generalization of the Adam algorithm. In contrast to established methods for sparse training the proposed family of algorithms constitutes a regrowth strategy for neural networks that is solely optimization-based without additional heuristics. Our Bregman learning framework starts the training with very few initial parameters, successively adding only significant ones to obtain a sparse and expressive network. The proposed approach is extremely easy and efficient, yet supported by the rich mathematical theory of inverse scale space methods. We derive a statistically profound sparse parameter initialization strategy and provide a rigorous stochastic convergence analysis of the loss decay and additional convergence proofs in the convex regime. Using only 3.4% of the parameters of ResNet-18 we achieve 90.2% test accuracy on CIFAR-10, compared to 93.6% using the dense network. Our algorithm also unveils an autoencoder architecture for a denoising task. The proposed framework also has a huge potential for integrating sparse backpropagation and resource-friendly training.