 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023
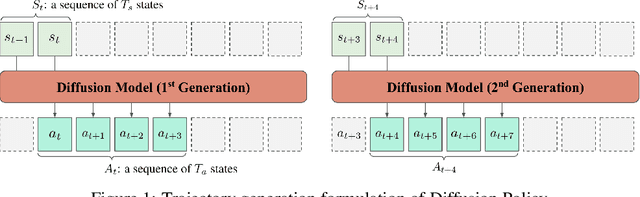

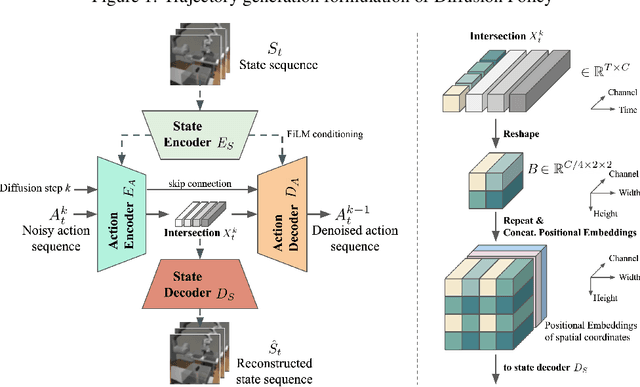

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.
Interpretable Computer Vision Models through Adversarial Training: Unveiling the Robustness-Interpretability Connection
Jul 04, 2023
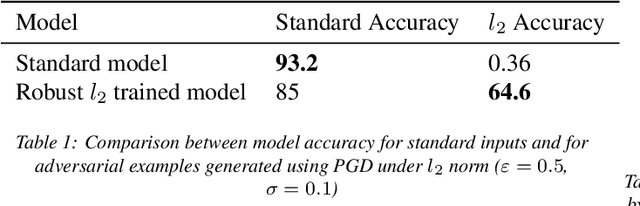


With the perpetual increase of complexity of the state-of-the-art deep neural networks, it becomes a more and more challenging task to maintain their interpretability. Our work aims to evaluate the effects of adversarial training utilized to produce robust models - less vulnerable to adversarial attacks. It has been shown to make computer vision models more interpretable. Interpretability is as essential as robustness when we deploy the models to the real world. To prove the correlation between these two problems, we extensively examine the models using local feature-importance methods (SHAP, Integrated Gradients) and feature visualization techniques (Representation Inversion, Class Specific Image Generation). Standard models, compared to robust are more susceptible to adversarial attacks, and their learned representations are less meaningful to humans. Conversely, these models focus on distinctive regions of the images which support their predictions. Moreover, the features learned by the robust model are closer to the real ones.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023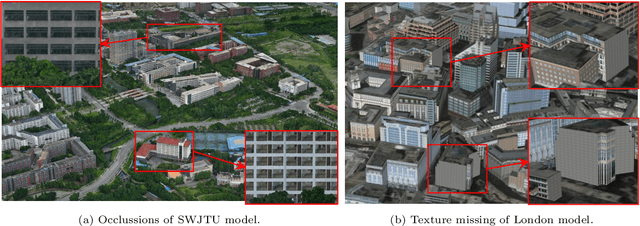
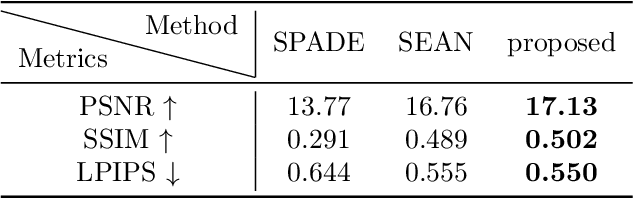
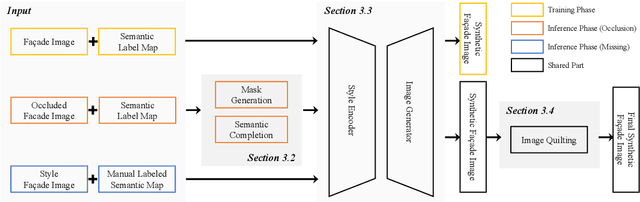

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Unsupervised augmentation optimization for few-shot medical image segmentation
Jun 08, 2023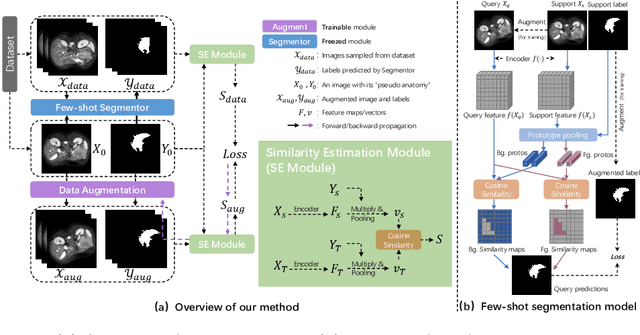
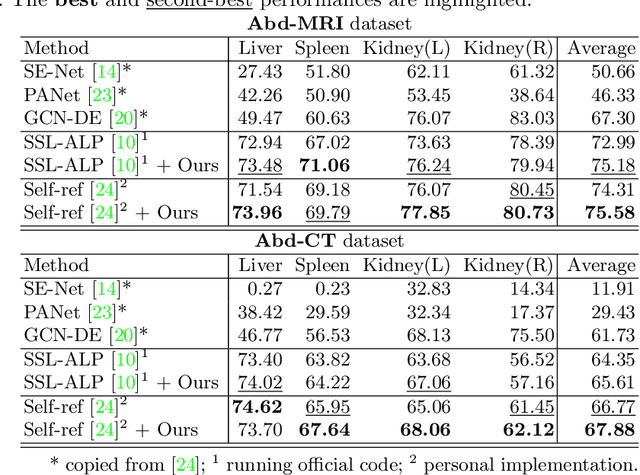
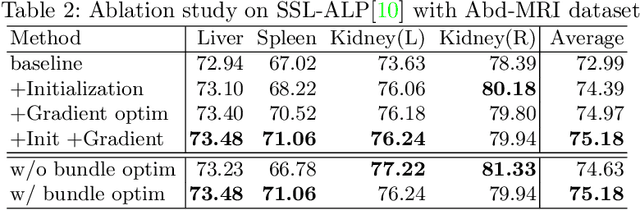
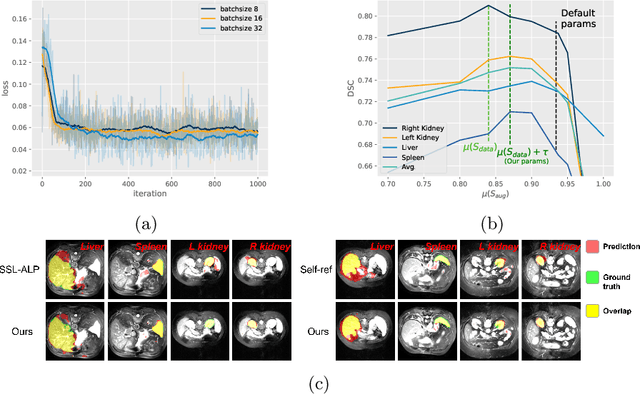
The augmentation parameters matter to few-shot semantic segmentation since they directly affect the training outcome by feeding the networks with varying perturbated samples. However, searching optimal augmentation parameters for few-shot segmentation models without annotations is a challenge that current methods fail to address. In this paper, we first propose a framework to determine the ``optimal'' parameters without human annotations by solving a distribution-matching problem between the intra-instance and intra-class similarity distribution, with the intra-instance similarity describing the similarity between the original sample of a particular anatomy and its augmented ones and the intra-class similarity representing the similarity between the selected sample and the others in the same class. Extensive experiments demonstrate the superiority of our optimized augmentation in boosting few-shot segmentation models. We greatly improve the top competing method by 1.27\% and 1.11\% on Abd-MRI and Abd-CT datasets, respectively, and even achieve a significant improvement for SSL-ALP on the left kidney by 3.39\% on the Abd-CT dataset.
What's in a Name? Beyond Class Indices for Image Recognition
Apr 05, 2023

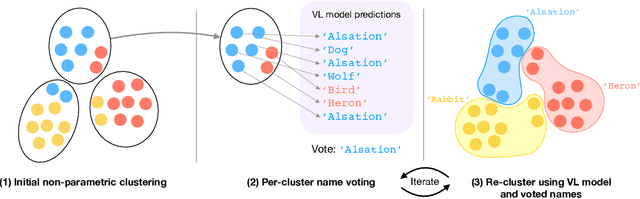

Existing machine learning models demonstrate excellent performance in image object recognition after training on a large-scale dataset under full supervision. However, these models only learn to map an image to a predefined class index, without revealing the actual semantic meaning of the object in the image. In contrast, vision-language models like CLIP are able to assign semantic class names to unseen objects in a `zero-shot' manner, although they still rely on a predefined set of candidate names at test time. In this paper, we reconsider the recognition problem and task a vision-language model to assign class names to images given only a large and essentially unconstrained vocabulary of categories as prior information. We use non-parametric methods to establish relationships between images which allow the model to automatically narrow down the set of possible candidate names. Specifically, we propose iteratively clustering the data and voting on class names within them, showing that this enables a roughly 50\% improvement over the baseline on ImageNet. Furthermore, we tackle this problem both in unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary.
Learned Image Compression with Mixed Transformer-CNN Architectures
Mar 27, 2023
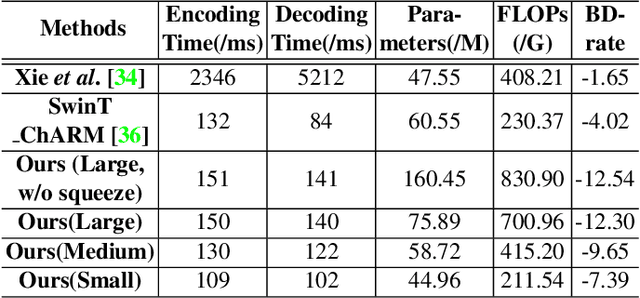
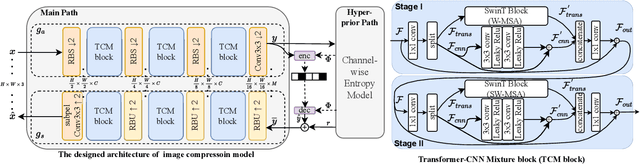
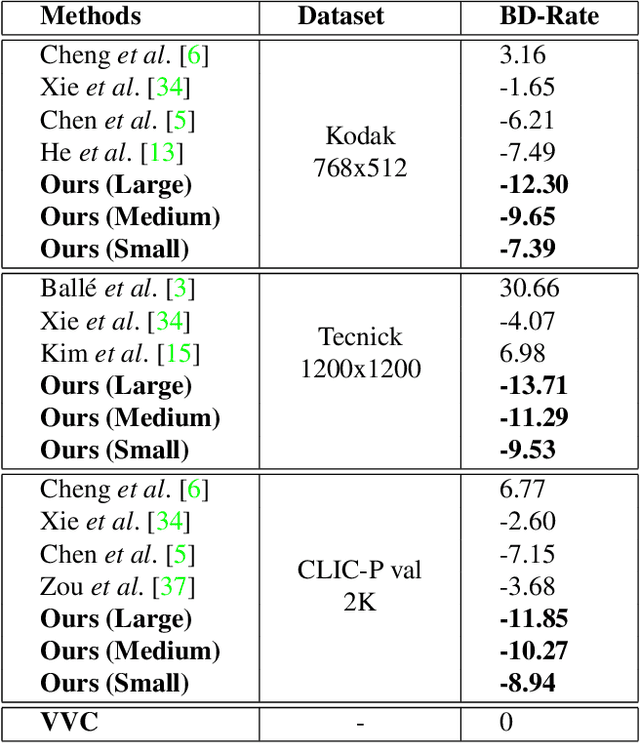
Learned image compression (LIC) methods have exhibited promising progress and superior rate-distortion performance compared with classical image compression standards. Most existing LIC methods are Convolutional Neural Networks-based (CNN-based) or Transformer-based, which have different advantages. Exploiting both advantages is a point worth exploring, which has two challenges: 1) how to effectively fuse the two methods? 2) how to achieve higher performance with a suitable complexity? In this paper, we propose an efficient parallel Transformer-CNN Mixture (TCM) block with a controllable complexity to incorporate the local modeling ability of CNN and the non-local modeling ability of transformers to improve the overall architecture of image compression models. Besides, inspired by the recent progress of entropy estimation models and attention modules, we propose a channel-wise entropy model with parameter-efficient swin-transformer-based attention (SWAtten) modules by using channel squeezing. Experimental results demonstrate our proposed method achieves state-of-the-art rate-distortion performances on three different resolution datasets (i.e., Kodak, Tecnick, CLIC Professional Validation) compared to existing LIC methods. The code is at https://github.com/jmliu206/LIC_TCM.
Ladder Fine-tuning approach for SAM integrating complementary network
Jun 22, 2023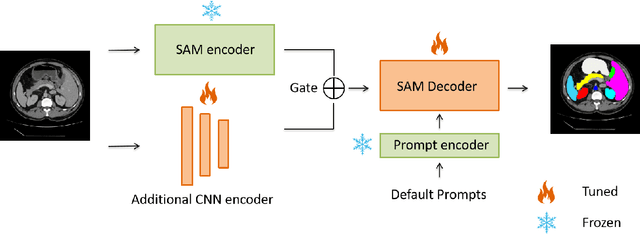
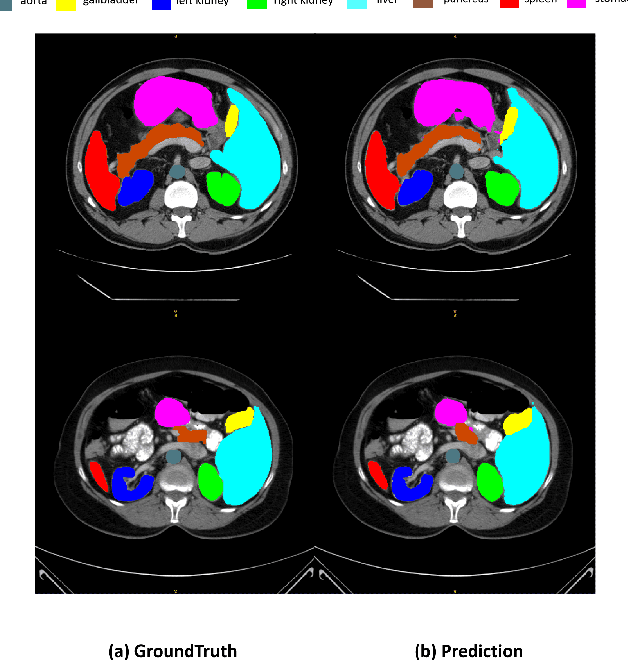
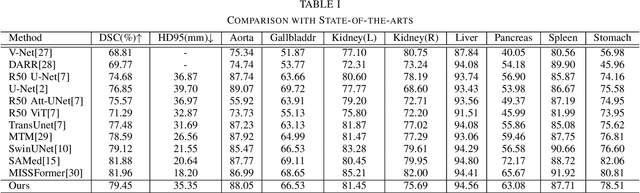
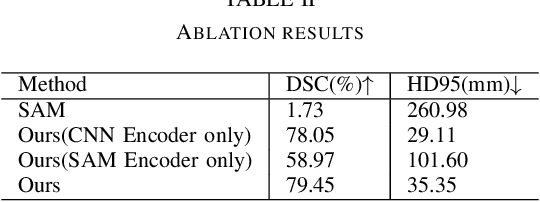
Recently, foundation models have been introduced demonstrating various tasks in the field of computer vision. These models such as Segment Anything Model (SAM) are generalized models trained using huge datasets. Currently, ongoing research focuses on exploring the effective utilization of these generalized models for specific domains, such as medical imaging. However, in medical imaging, the lack of training samples due to privacy concerns and other factors presents a major challenge for applying these generalized models to medical image segmentation task. To address this issue, the effective fine tuning of these models is crucial to ensure their optimal utilization. In this study, we propose to combine a complementary Convolutional Neural Network (CNN) along with the standard SAM network for medical image segmentation. To reduce the burden of fine tuning large foundation model and implement cost-efficient trainnig scheme, we focus only on fine-tuning the additional CNN network and SAM decoder part. This strategy significantly reduces trainnig time and achieves competitive results on publicly available dataset. The code is available at https://github.com/11yxk/SAM-LST.
On the Effectiveness of Image Manipulation Detection in the Age of Social Media
Apr 19, 2023
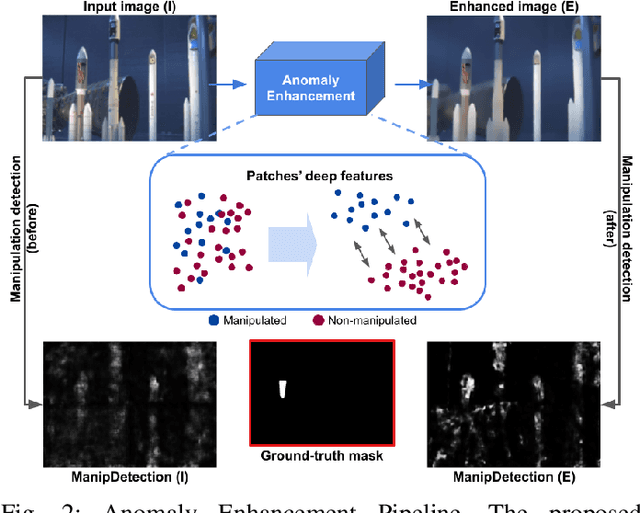
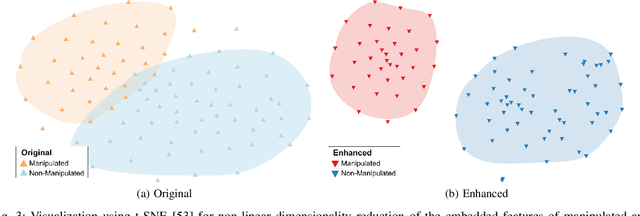

Image manipulation detection algorithms designed to identify local anomalies often rely on the manipulated regions being ``sufficiently'' different from the rest of the non-tampered regions in the image. However, such anomalies might not be easily identifiable in high-quality manipulations, and their use is often based on the assumption that certain image phenomena are associated with the use of specific editing tools. This makes the task of manipulation detection hard in and of itself, with state-of-the-art detectors only being able to detect a limited number of manipulation types. More importantly, in cases where the anomaly assumption does not hold, the detection of false positives in otherwise non-manipulated images becomes a serious problem. To understand the current state of manipulation detection, we present an in-depth analysis of deep learning-based and learning-free methods, assessing their performance on different benchmark datasets containing tampered and non-tampered samples. We provide a comprehensive study of their suitability for detecting different manipulations as well as their robustness when presented with non-tampered data. Furthermore, we propose a novel deep learning-based pre-processing technique that accentuates the anomalies present in manipulated regions to make them more identifiable by a variety of manipulation detection methods. To this end, we introduce an anomaly enhancement loss that, when used with a residual architecture, improves the performance of different detection algorithms with a minimal introduction of false positives on the non-manipulated data. Lastly, we introduce an open-source manipulation detection toolkit comprising a number of standard detection algorithms.
ViTEraser: Harnessing the Power of Vision Transformers for Scene Text Removal with SegMIM Pretraining
Jun 21, 2023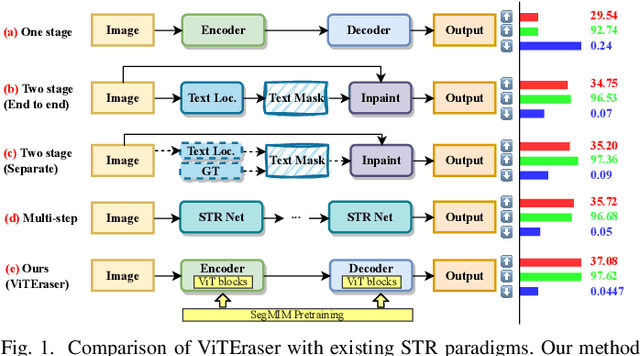

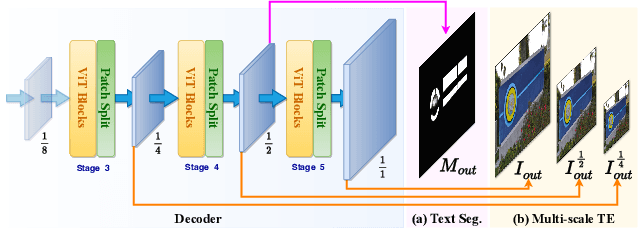

Scene text removal (STR) aims at replacing text strokes in natural scenes with visually coherent backgrounds. Recent STR approaches rely on iterative refinements or explicit text masks, resulting in higher complexity and sensitivity to the accuracy of text localization. Moreover, most existing STR methods utilize convolutional neural networks (CNNs) for feature representation while the potential of vision Transformers (ViTs) remains largely unexplored. In this paper, we propose a simple-yet-effective ViT-based text eraser, dubbed ViTEraser. Following a concise encoder-decoder framework, different types of ViTs can be easily integrated into ViTEraser to enhance the long-range dependencies and global reasoning. Specifically, the encoder hierarchically maps the input image into the hidden space through ViT blocks and patch embedding layers, while the decoder gradually upsamples the hidden features to the text-erased image with ViT blocks and patch splitting layers. As ViTEraser implicitly integrates text localization and inpainting, we propose a novel end-to-end pretraining method, termed SegMIM, which focuses the encoder and decoder on the text box segmentation and masked image modeling tasks, respectively. To verify the effectiveness of the proposed methods, we comprehensively explore the architecture, pretraining, and scalability of the ViT-based encoder-decoder for STR, which provides deep insights into the application of ViT to STR. Experimental results demonstrate that ViTEraser with SegMIM achieves state-of-the-art performance on STR by a substantial margin. Furthermore, the extended experiment on tampered scene text detection demonstrates the generality of ViTEraser to other tasks. We believe this paper can inspire more research on ViT-based STR approaches. Code will be available at https://github.com/shannanyinxiang/ViTEraser.
One-shot and Partially-Supervised Cell Image Segmentation Using Small Visual Prompt
Apr 17, 2023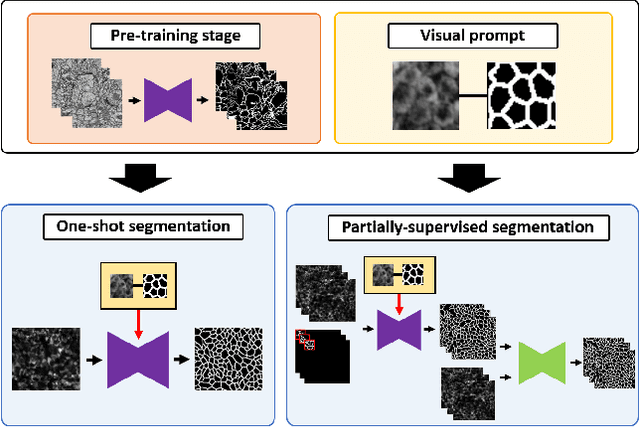
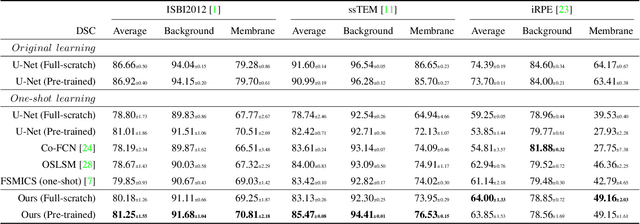
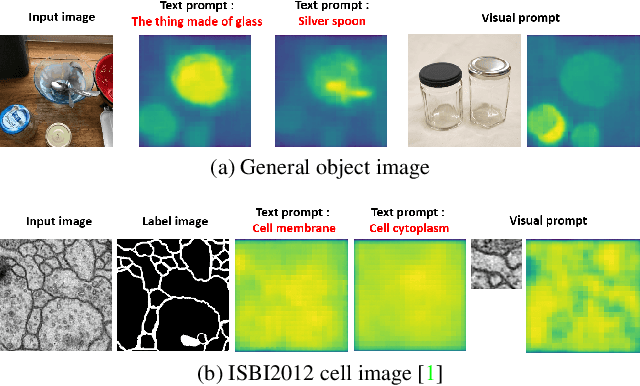
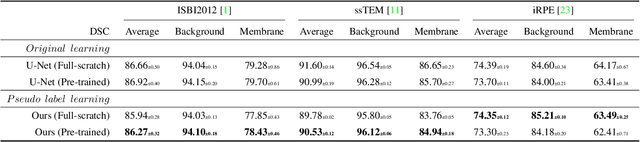
Semantic segmentation of microscopic cell images using deep learning is an important technique, however, it requires a large number of images and ground truth labels for training. To address the above problem, we consider an efficient learning framework with as little data as possible, and we propose two types of learning strategies: One-shot segmentation which can learn with only one training sample, and Partially-supervised segmentation which assigns annotations to only a part of images. Furthermore, we introduce novel segmentation methods using the small prompt images inspired by prompt learning in recent studies. Our proposed methods use a pre-trained model based on only cell images and teach the information of the prompt pairs to the target image to be segmented by the attention mechanism, which allows for efficient learning while reducing the burden of annotation costs. Through experiments conducted on three types of microscopic cell image datasets, we confirmed that the proposed method improved the Dice score coefficient (DSC) in comparison with the conventional methods.