 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACOSTE: Exploiting stereo and temporal contexts for surgical instrument segmentation
Sep 14, 2024



Surgical instrument segmentation is instrumental to minimally invasive surgeries and related applications. Most previous methods formulate this task as single-frame-based instance segmentation while ignoring the natural temporal and stereo attributes of a surgical video. As a result, these methods are less robust against the appearance variation through temporal motion and view change. In this work, we propose a novel LACOSTE model that exploits Location-Agnostic COntexts in Stereo and TEmporal images for improved surgical instrument segmentation. Leveraging a query-based segmentation model as core, we design three performance-enhancing modules. Firstly, we design a disparity-guided feature propagation module to enhance depth-aware features explicitly. To generalize well for even only a monocular video, we apply a pseudo stereo scheme to generate complementary right images. Secondly, we propose a stereo-temporal set classifier, which aggregates stereo-temporal contexts in a universal way for making a consolidated prediction and mitigates transient failures. Finally, we propose a location-agnostic classifier to decouple the location bias from mask prediction and enhance the feature semantics. We extensively validate our approach on three public surgical video datasets, including two benchmarks from EndoVis Challenges and one real radical prostatectomy surgery dataset GraSP. Experimental results demonstrate the promising performances of our method, which consistently achieves comparable or favorable results with previous state-of-the-art approaches.
PostoMETRO: Pose Token Enhanced Mesh Transformer for Robust 3D Human Mesh Recovery
Mar 19, 2024With the recent advancements in single-image-based human mesh recovery, there is a growing interest in enhancing its performance in certain extreme scenarios, such as occlusion, while maintaining overall model accuracy. Although obtaining accurately annotated 3D human poses under occlusion is challenging, there is still a wealth of rich and precise 2D pose annotations that can be leveraged. However, existing works mostly focus on directly leveraging 2D pose coordinates to estimate 3D pose and mesh. In this paper, we present PostoMETRO($\textbf{Pos}$e $\textbf{to}$ken enhanced $\textbf{ME}$sh $\textbf{TR}$ansf$\textbf{O}$rmer), which integrates occlusion-resilient 2D pose representation into transformers in a token-wise manner. Utilizing a specialized pose tokenizer, we efficiently condense 2D pose data to a compact sequence of pose tokens and feed them to the transformer together with the image tokens. This process not only ensures a rich depiction of texture from the image but also fosters a robust integration of pose and image information. Subsequently, these combined tokens are queried by vertex and joint tokens to decode 3D coordinates of mesh vertices and human joints. Facilitated by the robust pose token representation and the effective combination, we are able to produce more precise 3D coordinates, even under extreme scenarios like occlusion. Experiments on both standard and occlusion-specific benchmarks demonstrate the effectiveness of PostoMETRO. Qualitative results further illustrate the clarity of how 2D pose can help 3D reconstruction. Code will be made available.
WeakSurg: Weakly supervised surgical instrument segmentation using temporal equivariance and semantic continuity
Mar 14, 2024



Weakly supervised surgical instrument segmentation with only instrument presence labels has been rarely explored in surgical domain. To mitigate the highly under-constrained challenges, we extend a two-stage weakly supervised segmentation paradigm with temporal attributes from two perspectives. From a temporal equivariance perspective, we propose a prototype-based temporal equivariance regulation loss to enhance pixel-wise consistency between adjacent features. From a semantic continuity perspective, we propose a class-aware temporal semantic continuity loss to constrain the semantic consistency between a global view of target frame and local non-discriminative regions of adjacent reference frame. To the best of our knowledge, WeakSurg is the first instrument-presence-only weakly supervised segmentation architecture to take temporal information into account for surgical scenarios. Extensive experiments are validated on Cholec80, an open benchmark for phase and instrument recognition. We annotate instance-wise instrument labels with fixed time-steps which are double checked by a clinician with 3-years experience. Our results show that WeakSurg compares favorably with state-of-the-art methods not only on semantic segmentation metrics but also on instance segmentation metrics.
Sparse-view CT Reconstruction with 3D Gaussian Volumetric Representation
Dec 25, 2023



Sparse-view CT is a promising strategy for reducing the radiation dose of traditional CT scans, but reconstructing high-quality images from incomplete and noisy data is challenging. Recently, 3D Gaussian has been applied to model complex natural scenes, demonstrating fast convergence and better rendering of novel views compared to implicit neural representations (INRs). Taking inspiration from the successful application of 3D Gaussians in natural scene modeling and novel view synthesis, we investigate their potential for sparse-view CT reconstruction. We leverage prior information from the filtered-backprojection reconstructed image to initialize the Gaussians; and update their parameters via comparing difference in the projection space. Performance is further enhanced by adaptive density control. Compared to INRs, 3D Gaussians benefit more from prior information to explicitly bypass learning in void spaces and allocate the capacity efficiently, accelerating convergence. 3D Gaussians also efficiently learn high-frequency details. Trained in a self-supervised manner, 3D Gaussians avoid the need for large-scale paired data. Our experiments on the AAPM-Mayo dataset demonstrate that 3D Gaussians can provide superior performance compared to INR-based methods. This work is in progress, and the code will be publicly available.
Unsupervised augmentation optimization for few-shot medical image segmentation
Jun 08, 2023



The augmentation parameters matter to few-shot semantic segmentation since they directly affect the training outcome by feeding the networks with varying perturbated samples. However, searching optimal augmentation parameters for few-shot segmentation models without annotations is a challenge that current methods fail to address. In this paper, we first propose a framework to determine the ``optimal'' parameters without human annotations by solving a distribution-matching problem between the intra-instance and intra-class similarity distribution, with the intra-instance similarity describing the similarity between the original sample of a particular anatomy and its augmented ones and the intra-class similarity representing the similarity between the selected sample and the others in the same class. Extensive experiments demonstrate the superiority of our optimized augmentation in boosting few-shot segmentation models. We greatly improve the top competing method by 1.27\% and 1.11\% on Abd-MRI and Abd-CT datasets, respectively, and even achieve a significant improvement for SSL-ALP on the left kidney by 3.39\% on the Abd-CT dataset.
GDDS: Pulmonary Bronchioles Segmentation with Group Deep Dense Supervision
Mar 16, 2023



Airway segmentation, especially bronchioles segmentation, is an important but challenging task because distal bronchus are sparsely distributed and of a fine scale. Existing neural networks usually exploit sparse topology to learn the connectivity of bronchioles and inefficient shallow features to capture such high-frequency information, leading to the breakage or missed detection of individual thin branches. To address these problems, we contribute a new bronchial segmentation method based on Group Deep Dense Supervision (GDDS) that emphasizes fine-scale bronchioles segmentation in a simple-but-effective manner. First, Deep Dense Supervision (DDS) is proposed by constructing local dense topology skillfully and implementing dense topological learning on a specific shallow feature layer. GDDS further empowers the shallow features with better perception ability to detect bronchioles, even the ones that are not easily discernible to the naked eye. Extensive experiments on the BAS benchmark dataset have shown that our method promotes the network to have a high sensitivity in capturing fine-scale branches and outperforms state-of-the-art methods by a large margin (+12.8 % in BD and +8.8 % in TD) while only introducing a small number of extra parameters.
FairAdaBN: Mitigating unfairness with adaptive batch normalization and its application to dermatological disease classification
Mar 15, 2023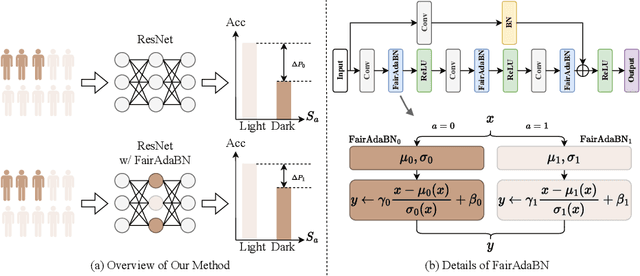
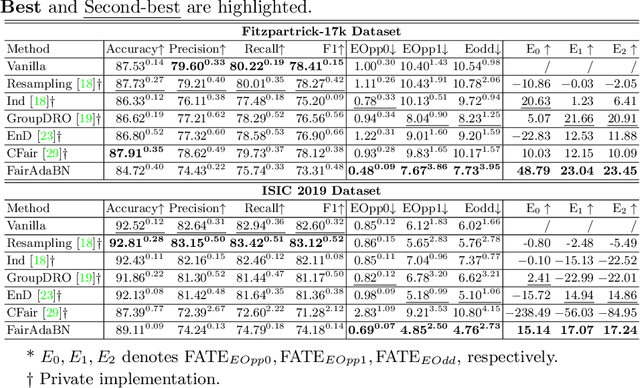
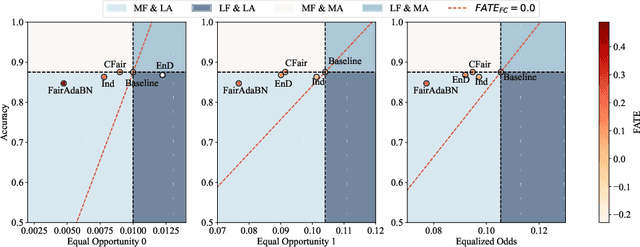
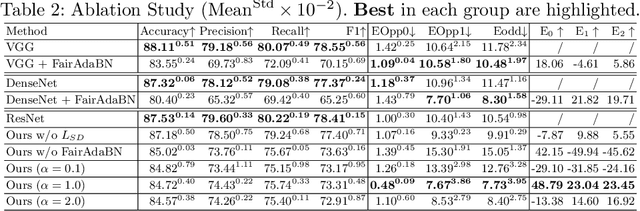
Deep learning is becoming increasingly ubiquitous in medical research and applications while involving sensitive information and even critical diagnosis decisions. Researchers observe a significant performance disparity among subgroups with different demographic attributes, which is called model unfairness, and put lots of effort into carefully designing elegant architectures to address unfairness, which poses heavy training burden, brings poor generalization, and reveals the trade-off between model performance and fairness. To tackle these issues, we propose FairAdaBN by making batch normalization adaptive to sensitive attribute. This simple but effective design can be adopted to several classification backbones that are originally unaware of fairness. Additionally, we derive a novel loss function that restrains statistical parity between subgroups on mini-batches, encouraging the model to converge with considerable fairness. In order to evaluate the trade-off between model performance and fairness, we propose a new metric, named Fairness-Accuracy Trade-off Efficiency (FATE), to compute normalized fairness improvement over accuracy drop. Experiments on two dermatological datasets show that our proposed method outperforms other methods on fairness criteria and FATE.
MURPHY: Relations Matter in Surgical Workflow Analysis
Dec 24, 2022Autonomous robotic surgery has advanced significantly based on analysis of visual and temporal cues in surgical workflow, but relational cues from domain knowledge remain under investigation. Complex relations in surgical annotations can be divided into intra- and inter-relations, both valuable to autonomous systems to comprehend surgical workflows. Intra- and inter-relations describe the relevance of various categories within a particular annotation type and the relevance of different annotation types, respectively. This paper aims to systematically investigate the importance of relational cues in surgery. First, we contribute the RLLS12M dataset, a large-scale collection of robotic left lateral sectionectomy (RLLS), by curating 50 videos of 50 patients operated by 5 surgeons and annotating a hierarchical workflow, which consists of 3 inter- and 6 intra-relations, 6 steps, 15 tasks, and 38 activities represented as the triplet of 11 instruments, 8 actions, and 16 objects, totaling 2,113,510 video frames and 12,681,060 annotation entities. Correspondingly, we propose a multi-relation purification hybrid network (MURPHY), which aptly incorporates novel relation modules to augment the feature representation by purifying relational features using the intra- and inter-relations embodied in annotations. The intra-relation module leverages a R-GCN to implant visual features in different graph relations, which are aggregated using a targeted relation purification with affinity information measuring label consistency and feature similarity. The inter-relation module is motivated by attention mechanisms to regularize the influence of relational features based on the hierarchy of annotation types from the domain knowledge. Extensive experimental results on the curated RLLS dataset confirm the effectiveness of our approach, demonstrating that relations matter in surgical workflow analysis.
Active CT Reconstruction with a Learned Sampling Policy
Nov 03, 2022



Computed tomography (CT) is a widely-used imaging technology that assists clinical decision-making with high-quality human body representations. To reduce the radiation dose posed by CT, sparse-view and limited-angle CT are developed with preserved image quality. However, these methods are still stuck with a fixed or uniform sampling strategy, which inhibits the possibility of acquiring a better image with an even reduced dose. In this paper, we explore this possibility via learning an active sampling policy that optimizes the sampling positions for patient-specific, high-quality reconstruction. To this end, we design an \textit{intelligent agent} for active recommendation of sampling positions based on on-the-fly reconstruction with obtained sinograms in a progressive fashion. With such a design, we achieve better performances on the NIH-AAPM dataset over popular uniform sampling, especially when the number of views is small. Finally, such a design also enables RoI-aware reconstruction with improved reconstruction quality within regions of interest (RoI's) that are clinically important. Experiments on the VerSe dataset demonstrate this ability of our sampling policy, which is difficult to achieve based on uniform sampling.
3D endoscopic depth estimation using 3D surface-aware constraints
Mar 04, 2022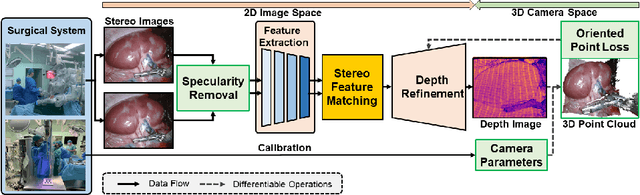
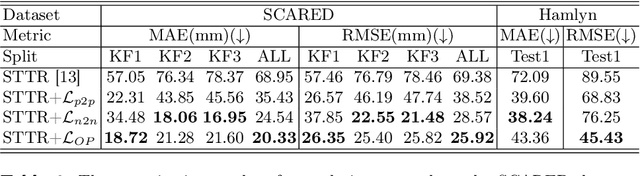
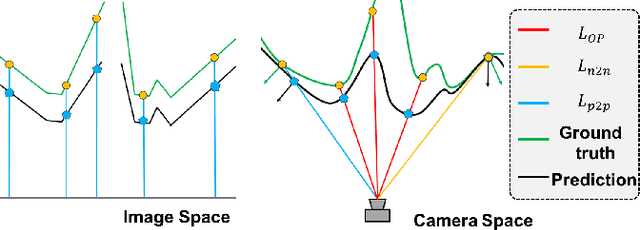

Robotic-assisted surgery allows surgeons to conduct precise surgical operations with stereo vision and flexible motor control. However, the lack of 3D spatial perception limits situational awareness during procedures and hinders mastering surgical skills in the narrow abdominal space. Depth estimation, as a representative perception task, is typically defined as an image reconstruction problem. In this work, we show that depth estimation can be reformed from a 3D surface perspective. We propose a loss function for depth estimation that integrates the surface-aware constraints, leading to a faster and better convergence with the valid information from spatial information. In addition, camera parameters are incorporated into the training pipeline to increase the control and transparency of the depth estimation. We also integrate a specularity removal module to recover more buried image information. Quantitative experimental results on endoscopic datasets and user studies with medical professionals demonstrate the effectiveness of our method.