 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLENVIZ: A High-Resolution Low-Exposure Night Vision Benchmark Dataset
Mar 25, 2025



Low-light image enhancement is crucial for a myriad of applications, from night vision and surveillance, to autonomous driving. However, due to the inherent limitations that come in hand with capturing images in low-illumination environments, the task of enhancing such scenes still presents a formidable challenge. To advance research in this field, we introduce our Low Exposure Night Vision (LENVIZ) Dataset, a comprehensive multi-exposure benchmark dataset for low-light image enhancement comprising of over 230K frames showcasing 24K real-world indoor and outdoor, with-and without human, scenes. Captured using 3 different camera sensors, LENVIZ offers a wide range of lighting conditions, noise levels, and scene complexities, making it the largest publicly available up-to 4K resolution benchmark in the field. LENVIZ includes high quality human-generated ground truth, for which each multi-exposure low-light scene has been meticulously curated and edited by expert photographers to ensure optimal image quality. Furthermore, we also conduct a comprehensive analysis of current state-of-the-art low-light image enhancement techniques on our dataset and highlight potential areas of improvement.
Unified-EGformer: Exposure Guided Lightweight Transformer for Mixed-Exposure Image Enhancement
Jul 18, 2024Despite recent strides made by AI in image processing, the issue of mixed exposure, pivotal in many real-world scenarios like surveillance and photography, remains inadequately addressed. Traditional image enhancement techniques and current transformer models are limited with primary focus on either overexposure or underexposure. To bridge this gap, we introduce the Unified-Exposure Guided Transformer (Unified-EGformer). Our proposed solution is built upon advanced transformer architectures, equipped with local pixel-level refinement and global refinement blocks for color correction and image-wide adjustments. We employ a guided attention mechanism to precisely identify exposure-compromised regions, ensuring its adaptability across various real-world conditions. U-EGformer, with a lightweight design featuring a memory footprint (peak memory) of only $\sim$1134 MB (0.1 Million parameters) and an inference time of 95 ms (9.61x faster than the average), is a viable choice for real-time applications such as surveillance and autonomous navigation. Additionally, our model is highly generalizable, requiring minimal fine-tuning to handle multiple tasks and datasets with a single architecture.
On the Effectiveness of Image Manipulation Detection in the Age of Social Media
Apr 19, 2023Image manipulation detection algorithms designed to identify local anomalies often rely on the manipulated regions being ``sufficiently'' different from the rest of the non-tampered regions in the image. However, such anomalies might not be easily identifiable in high-quality manipulations, and their use is often based on the assumption that certain image phenomena are associated with the use of specific editing tools. This makes the task of manipulation detection hard in and of itself, with state-of-the-art detectors only being able to detect a limited number of manipulation types. More importantly, in cases where the anomaly assumption does not hold, the detection of false positives in otherwise non-manipulated images becomes a serious problem. To understand the current state of manipulation detection, we present an in-depth analysis of deep learning-based and learning-free methods, assessing their performance on different benchmark datasets containing tampered and non-tampered samples. We provide a comprehensive study of their suitability for detecting different manipulations as well as their robustness when presented with non-tampered data. Furthermore, we propose a novel deep learning-based pre-processing technique that accentuates the anomalies present in manipulated regions to make them more identifiable by a variety of manipulation detection methods. To this end, we introduce an anomaly enhancement loss that, when used with a residual architecture, improves the performance of different detection algorithms with a minimal introduction of false positives on the non-manipulated data. Lastly, we introduce an open-source manipulation detection toolkit comprising a number of standard detection algorithms.
Joint Visual-Temporal Embedding for Unsupervised Learning of Actions in Untrimmed Sequences
Feb 06, 2020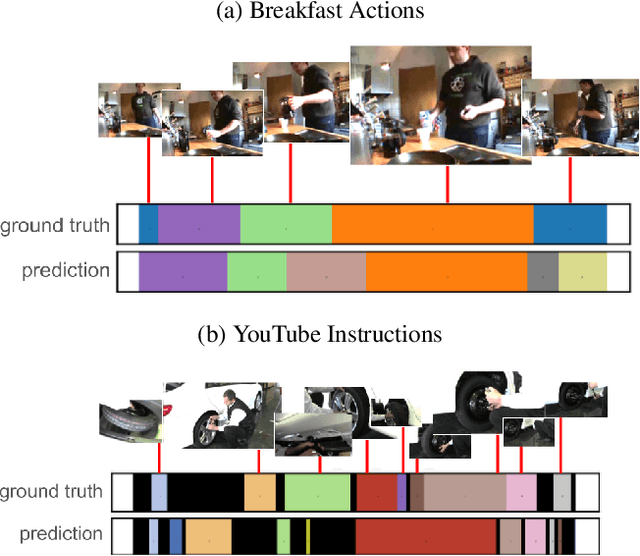
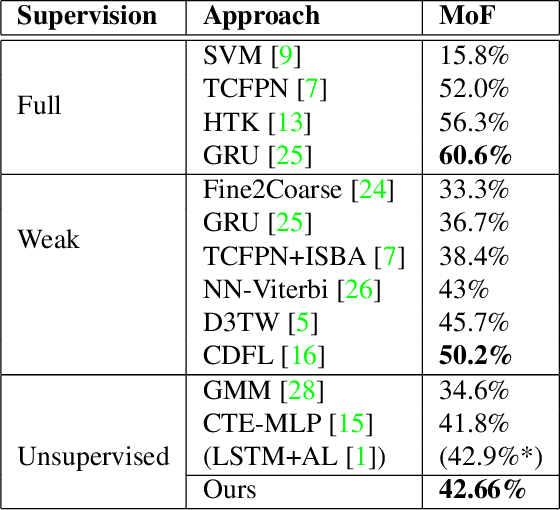
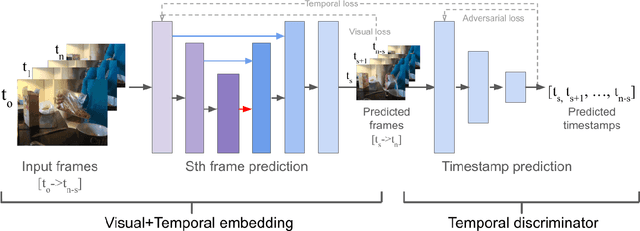
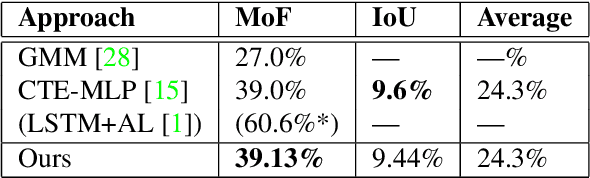
Understanding the structure of complex activities in videos is one of the many challenges faced by action recognition methods. To overcome this challenge, not only do methods need a solid knowledge of the visual structure of underlying features but also a good interpretation of how they could change over time. Consequently, action segmentation tasks must take into account not only the visual cues from individual frames, but their characteristics as a temporal sequence of features. This work presents our findings on the impact of incorporating both visual and temporal learning on an unsupervised action segmentation pipeline. We introduce a novel approach to extract relevant visual and temporal features from untrimmed sequences for the temporal localization of sub-activities within complex actions without any labeling information. Through extensive experimentation on two benchmark datasets -- Breakfast Actions, and YouTube Instructions -- we show that the proposed approach is able to provide a meaningful visual and temporal embedding from the visual cues from contiguous video frames and that it indeed helps in temporal segmentation.
Report on UG^2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms
Jul 26, 2019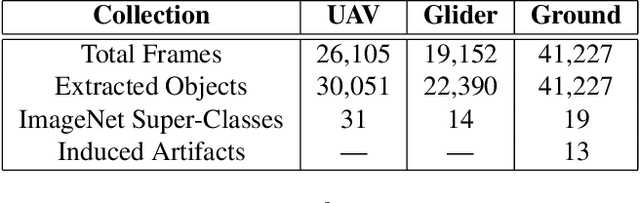
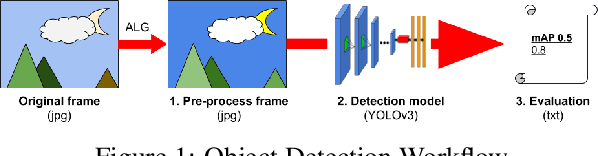
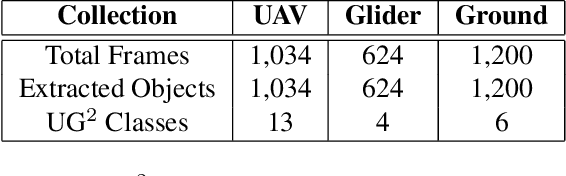
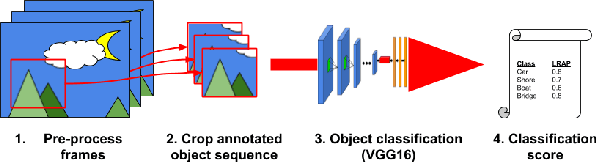
How can we effectively engineer a computer vision system that is able to interpret videos from unconstrained mobility platforms like UAVs? One promising option is to make use of image restoration and enhancement algorithms from the area of computational photography to improve the quality of the underlying frames in a way that also improves automatic visual recognition. Along these lines, exploratory work is needed to find out which image pre-processing algorithms, in combination with the strongest features and supervised machine learning approaches, are good candidates for difficult scenarios like motion blur, weather, and mis-focus --- all common artifacts in UAV acquired images. This paper summarizes the protocols and results of Track 1 of the UG^2+ Challenge held in conjunction with IEEE/CVF CVPR 2019. The challenge looked at two separate problems: (1) object detection improvement in video, and (2) object classification improvement in video. The challenge made use of the UG^2 (UAV, Glider, Ground) dataset, which is an established benchmark for assessing the interplay between image restoration and enhancement and visual recognition. 16 algorithms were submitted by academic and corporate teams, and a detailed analysis of how they performed on each challenge problem is reported here.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019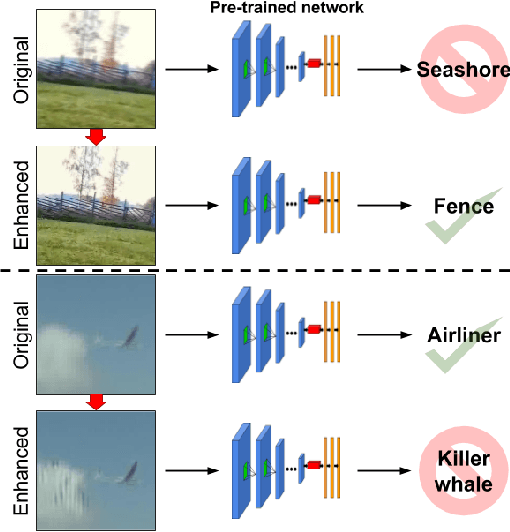
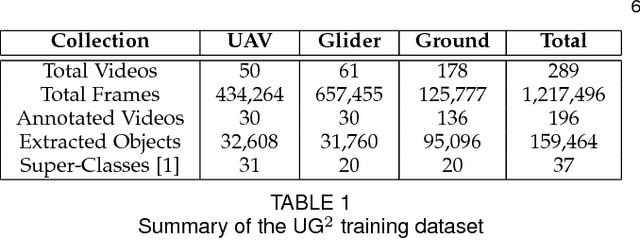

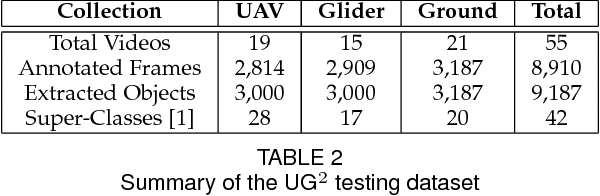
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.