 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Artifacts for Synthetic Western Blot Source Attribution
Sep 27, 2024



Recent advancements in artificial intelligence have enabled generative models to produce synthetic scientific images that are indistinguishable from pristine ones, posing a challenge even for expert scientists habituated to working with such content. When exploited by organizations known as paper mills, which systematically generate fraudulent articles, these technologies can significantly contribute to the spread of misinformation about ungrounded science, potentially undermining trust in scientific research. While previous studies have explored black-box solutions, such as Convolutional Neural Networks, for identifying synthetic content, only some have addressed the challenge of generalizing across different models and providing insight into the artifacts in synthetic images that inform the detection process. This study aims to identify explainable artifacts generated by state-of-the-art generative models (e.g., Generative Adversarial Networks and Diffusion Models) and leverage them for open-set identification and source attribution (i.e., pointing to the model that created the image).
Localization of Synthetic Manipulations in Western Blot Images
Aug 25, 2024



Recent breakthroughs in deep learning and generative systems have significantly fostered the creation of synthetic media, as well as the local alteration of real content via the insertion of highly realistic synthetic manipulations. Local image manipulation, in particular, poses serious challenges to the integrity of digital content and societal trust. This problem is not only confined to multimedia data, but also extends to biological images included in scientific publications, like images depicting Western blots. In this work, we address the task of localizing synthetic manipulations in Western blot images. To discriminate between pristine and synthetic pixels of an analyzed image, we propose a synthetic detector that operates on small patches extracted from the image. We aggregate patch contributions to estimate a tampering heatmap, highlighting synthetic pixels out of pristine ones. Our methodology proves effective when tested over two manipulated Western blot image datasets, one altered automatically and the other manually by exploiting advanced AI-based image manipulation tools that are unknown at our training stage. We also explore the robustness of our method over an external dataset of other scientific images depicting different semantics, manipulated through unseen generation techniques.
Exploring Saliency Bias in Manipulation Detection
Feb 15, 2024



The social media-fuelled explosion of fake news and misinformation supported by tampered images has led to growth in the development of models and datasets for image manipulation detection. However, existing detection methods mostly treat media objects in isolation, without considering the impact of specific manipulations on viewer perception. Forensic datasets are usually analyzed based on the manipulation operations and corresponding pixel-based masks, but not on the semantics of the manipulation, i.e., type of scene, objects, and viewers' attention to scene content. The semantics of the manipulation play an important role in spreading misinformation through manipulated images. In an attempt to encourage further development of semantic-aware forensic approaches to understand visual misinformation, we propose a framework to analyze the trends of visual and semantic saliency in popular image manipulation datasets and their impact on detection.
The Age of Synthetic Realities: Challenges and Opportunities
Jun 09, 2023



Synthetic realities are digital creations or augmentations that are contextually generated through the use of Artificial Intelligence (AI) methods, leveraging extensive amounts of data to construct new narratives or realities, regardless of the intent to deceive. In this paper, we delve into the concept of synthetic realities and their implications for Digital Forensics and society at large within the rapidly advancing field of AI. We highlight the crucial need for the development of forensic techniques capable of identifying harmful synthetic creations and distinguishing them from reality. This is especially important in scenarios involving the creation and dissemination of fake news, disinformation, and misinformation. Our focus extends to various forms of media, such as images, videos, audio, and text, as we examine how synthetic realities are crafted and explore approaches to detecting these malicious creations. Additionally, we shed light on the key research challenges that lie ahead in this area. This study is of paramount importance due to the rapid progress of AI generative techniques and their impact on the fundamental principles of Forensic Science.
On the Effectiveness of Image Manipulation Detection in the Age of Social Media
Apr 19, 2023Image manipulation detection algorithms designed to identify local anomalies often rely on the manipulated regions being ``sufficiently'' different from the rest of the non-tampered regions in the image. However, such anomalies might not be easily identifiable in high-quality manipulations, and their use is often based on the assumption that certain image phenomena are associated with the use of specific editing tools. This makes the task of manipulation detection hard in and of itself, with state-of-the-art detectors only being able to detect a limited number of manipulation types. More importantly, in cases where the anomaly assumption does not hold, the detection of false positives in otherwise non-manipulated images becomes a serious problem. To understand the current state of manipulation detection, we present an in-depth analysis of deep learning-based and learning-free methods, assessing their performance on different benchmark datasets containing tampered and non-tampered samples. We provide a comprehensive study of their suitability for detecting different manipulations as well as their robustness when presented with non-tampered data. Furthermore, we propose a novel deep learning-based pre-processing technique that accentuates the anomalies present in manipulated regions to make them more identifiable by a variety of manipulation detection methods. To this end, we introduce an anomaly enhancement loss that, when used with a residual architecture, improves the performance of different detection algorithms with a minimal introduction of false positives on the non-manipulated data. Lastly, we introduce an open-source manipulation detection toolkit comprising a number of standard detection algorithms.
Human Saliency-Driven Patch-based Matching for Interpretable Post-mortem Iris Recognition
Aug 03, 2022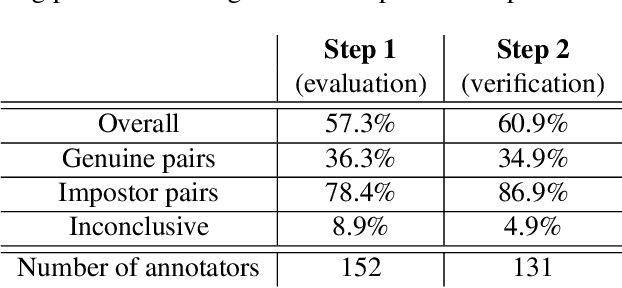
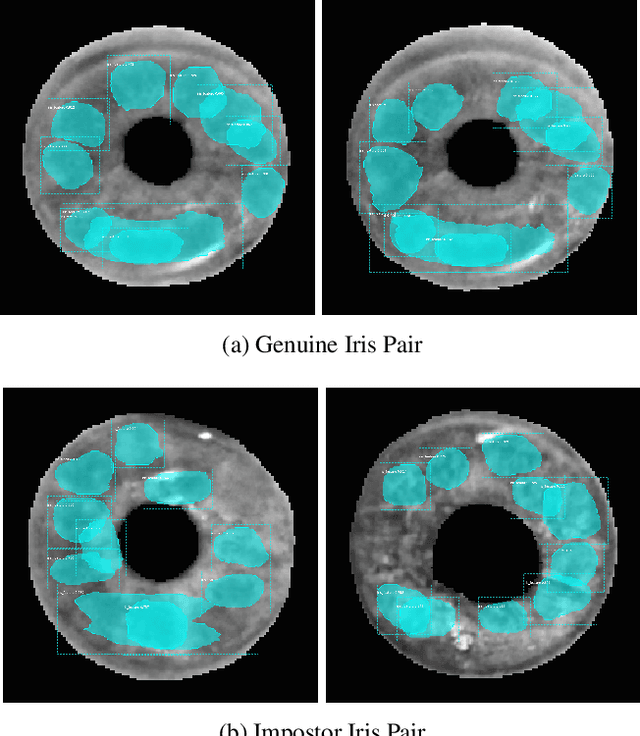
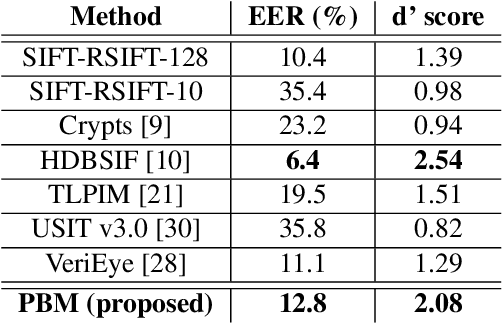
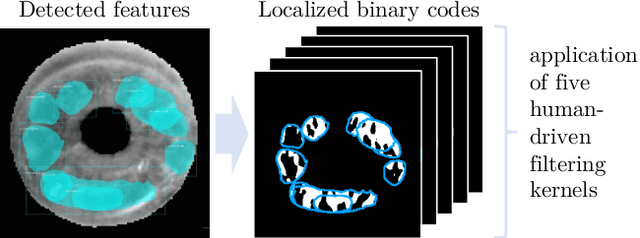
Forensic iris recognition, as opposed to live iris recognition, is an emerging research area that leverages the discriminative power of iris biometrics to aid human examiners in their efforts to identify deceased persons. As a machine learning-based technique in a predominantly human-controlled task, forensic recognition serves as "back-up" to human expertise in the task of post-mortem identification. As such, the machine learning model must be (a) interpretable, and (b) post-mortem-specific, to account for changes in decaying eye tissue. In this work, we propose a method that satisfies both requirements, and that approaches the creation of a post-mortem-specific feature extractor in a novel way employing human perception. We first train a deep learning-based feature detector on post-mortem iris images, using annotations of image regions highlighted by humans as salient for their decision making. In effect, the method learns interpretable features directly from humans, rather than purely data-driven features. Second, regional iris codes (again, with human-driven filtering kernels) are used to pair detected iris patches, which are translated into pairwise, patch-based comparison scores. In this way, our method presents human examiners with human-understandable visual cues in order to justify the identification decision and corresponding confidence score. When tested on a dataset of post-mortem iris images collected from 259 deceased subjects, the proposed method places among the three best iris matchers, demonstrating better results than the commercial (non-human-interpretable) VeriEye approach. We propose a unique post-mortem iris recognition method trained with human saliency to give fully-interpretable comparison outcomes for use in the context of forensic examination, achieving state-of-the-art recognition performance.
Motif Mining: Finding and Summarizing Remixed Image Content
Mar 17, 2022
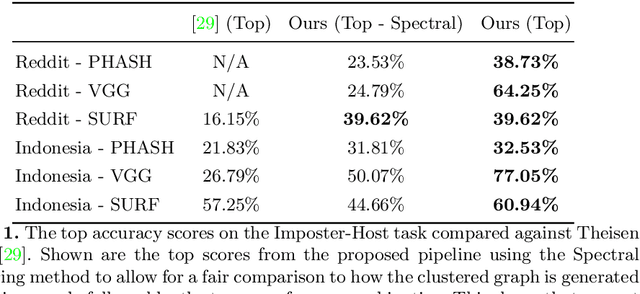
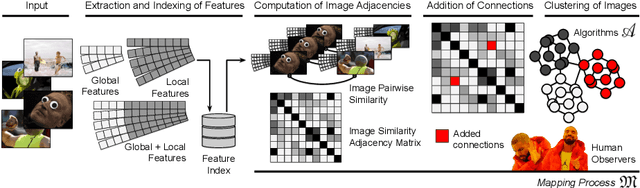
On the internet, images are no longer static; they have become dynamic content. Thanks to the availability of smartphones with cameras and easy-to-use editing software, images can be remixed (i.e., redacted, edited, and recombined with other content) on-the-fly and with a world-wide audience that can repeat the process. From digital art to memes, the evolution of images through time is now an important topic of study for digital humanists, social scientists, and media forensics specialists. However, because typical data sets in computer vision are composed of static content, the development of automated algorithms to analyze remixed content has been limited. In this paper, we introduce the idea of Motif Mining - the process of finding and summarizing remixed image content in large collections of unlabeled and unsorted data. In this paper, this idea is formalized and a reference implementation is introduced. Experiments are conducted on three meme-style data sets, including a newly collected set associated with the information war in the Russo-Ukrainian conflict. The proposed motif mining approach is able to identify related remixed content that, when compared to similar approaches, more closely aligns with the preferences and expectations of human observers.
Forensic Analysis of Synthetically Generated Scientific Images
Dec 16, 2021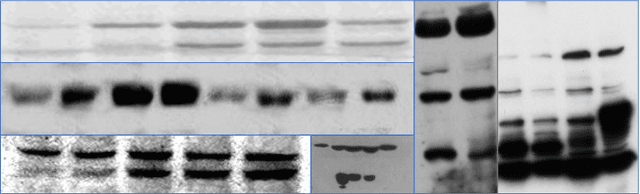
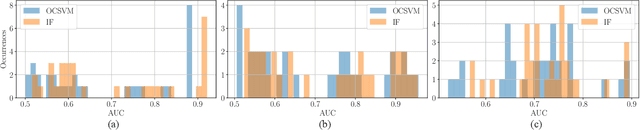
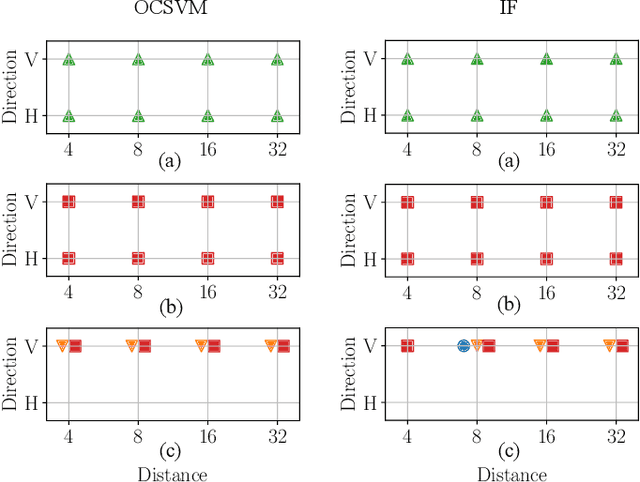

The widespread diffusion of synthetically generated content is a serious threat that needs urgent countermeasures. The generation of synthetic content is not restricted to multimedia data like videos, photographs, or audio sequences, but covers a significantly vast area that can include biological images as well, such as western-blot and microscopic images. In this paper, we focus on the detection of synthetically generated western-blot images. Western-blot images are largely explored in the biomedical literature and it has been already shown how these images can be easily counterfeited with few hope to spot manipulations by visual inspection or by standard forensics detectors. To overcome the absence of a publicly available dataset, we create a new dataset comprising more than 14K original western-blot images and 18K synthetic western-blot images, generated by three different state-of-the-art generation methods. Then, we investigate different strategies to detect synthetic western blots, exploring binary classification methods as well as one-class detectors. In both scenarios, we never exploit synthetic western-blot images at training stage. The achieved results show that synthetically generated western-blot images can be spot with good accuracy, even though the exploited detectors are not optimized over synthetic versions of these scientific images.
Automatic Discovery of Political Meme Genres with Diverse Appearances
Jan 17, 2020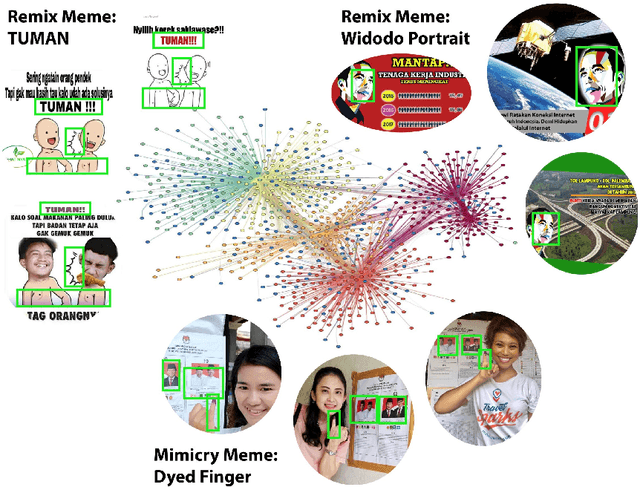
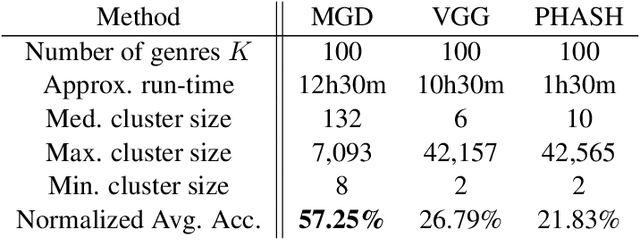

Forms of human communication are not static --- we expect some evolution in the way information is conveyed over time because of advances in technology. One example of this phenomenon is the image-based meme, which has emerged as a dominant form of political messaging in the past decade. While originally used to spread jokes on social media, memes are now having an outsized impact on public perception of world events. A significant challenge in automatic meme analysis has been the development of a strategy to match memes from within a single genre when the appearances of the images vary. Such variation is especially common in memes exhibiting mimicry. For example, when voters perform a common hand gesture to signal their support for a candidate. In this paper we introduce a scalable automated visual recognition pipeline for discovering political meme genres of diverse appearance. This pipeline can ingest meme images from a social network, apply computer vision-based techniques to extract local features and index new images into a database, and then organize the memes into related genres. To validate this approach, we perform a large case study on the 2019 Indonesian Presidential Election using a new dataset of over two million images collected from Twitter and Instagram. Results show that this approach can discover new meme genres with visually diverse images that share common stylistic elements, paving the way forward for further work in semantic analysis and content attribution.
Learning Transformation-Aware Embeddings for Image Forensics
Jan 13, 2020
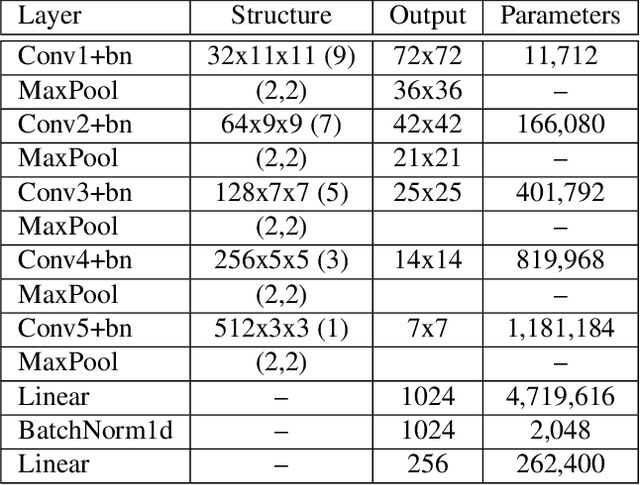

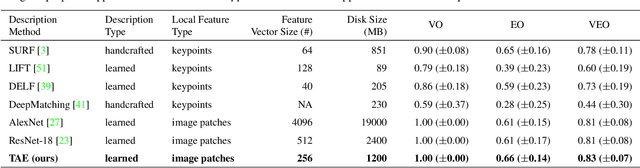
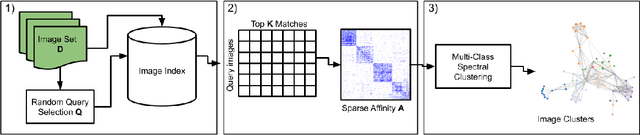
A dramatic rise in the flow of manipulated image content on the Internet has led to an aggressive response from the media forensics research community. New efforts have incorporated increased usage of techniques from computer vision and machine learning to detect and profile the space of image manipulations. This paper addresses Image Provenance Analysis, which aims at discovering relationships among different manipulated image versions that share content. One of the main sub-problems for provenance analysis that has not yet been addressed directly is the edit ordering of images that share full content or are near-duplicates. The existing large networks that generate image descriptors for tasks such as object recognition may not encode the subtle differences between these image covariates. This paper introduces a novel deep learning-based approach to provide a plausible ordering to images that have been generated from a single image through transformations. Our approach learns transformation-aware descriptors using weak supervision via composited transformations and a rank-based quadruplet loss. To establish the efficacy of the proposed approach, comparisons with state-of-the-art handcrafted and deep learning-based descriptors, and image matching approaches are made. Further experimentation validates the proposed approach in the context of image provenance analysis.