 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Segment Any Medical Model Extended
Mar 26, 2024
The Segment Anything Model (SAM) has drawn significant attention from researchers who work on medical image segmentation because of its generalizability. However, researchers have found that SAM may have limited performance on medical images compared to state-of-the-art non-foundation models. Regardless, the community sees potential in extending, fine-tuning, modifying, and evaluating SAM for analysis of medical imaging. An increasing number of works have been published focusing on the mentioned four directions, where variants of SAM are proposed. To this end, a unified platform helps push the boundary of the foundation model for medical images, facilitating the use, modification, and validation of SAM and its variants in medical image segmentation. In this work, we introduce SAMM Extended (SAMME), a platform that integrates new SAM variant models, adopts faster communication protocols, accommodates new interactive modes, and allows for fine-tuning of subcomponents of the models. These features can expand the potential of foundation models like SAM, and the results can be translated to applications such as image-guided therapy, mixed reality interaction, robotic navigation, and data augmentation.
Versatile Defense Against Adversarial Attacks on Image Recognition
Mar 13, 2024
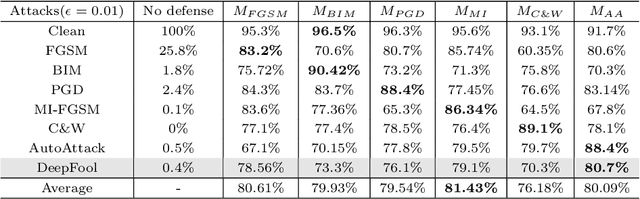
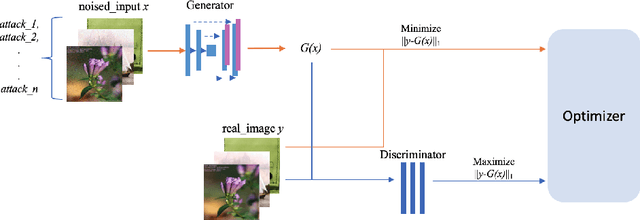
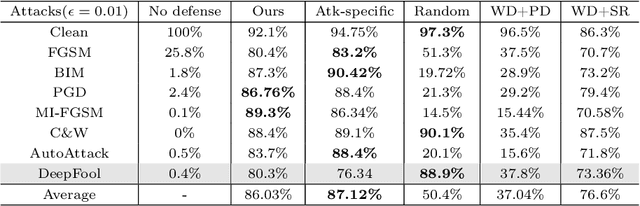
Adversarial attacks present a significant security risk to image recognition tasks. Defending against these attacks in a real-life setting can be compared to the way antivirus software works, with a key consideration being how well the defense can adapt to new and evolving attacks. Another important factor is the resources involved in terms of time and cost for training defense models and updating the model database. Training many models that are specific to each type of attack can be time-consuming and expensive. Ideally, we should be able to train one single model that can handle a wide range of attacks. It appears that a defense method based on image-to-image translation may be capable of this. The proposed versatile defense approach in this paper only requires training one model to effectively resist various unknown adversarial attacks. The trained model has successfully improved the classification accuracy from nearly zero to an average of 86%, performing better than other defense methods proposed in prior studies. When facing the PGD attack and the MI-FGSM attack, versatile defense model even outperforms the attack-specific models trained based on these two attacks. The robustness check also shows that our versatile defense model performs stably regardless with the attack strength.
Modeling uncertainty for Gaussian Splatting
Mar 27, 2024We present Stochastic Gaussian Splatting (SGS): the first framework for uncertainty estimation using Gaussian Splatting (GS). GS recently advanced the novel-view synthesis field by achieving impressive reconstruction quality at a fraction of the computational cost of Neural Radiance Fields (NeRF). However, contrary to the latter, it still lacks the ability to provide information about the confidence associated with their outputs. To address this limitation, in this paper, we introduce a Variational Inference-based approach that seamlessly integrates uncertainty prediction into the common rendering pipeline of GS. Additionally, we introduce the Area Under Sparsification Error (AUSE) as a new term in the loss function, enabling optimization of uncertainty estimation alongside image reconstruction. Experimental results on the LLFF dataset demonstrate that our method outperforms existing approaches in terms of both image rendering quality and uncertainty estimation accuracy. Overall, our framework equips practitioners with valuable insights into the reliability of synthesized views, facilitating safer decision-making in real-world applications.
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024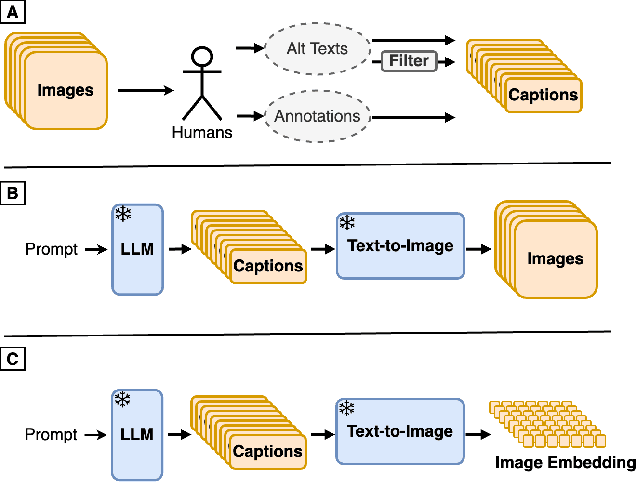

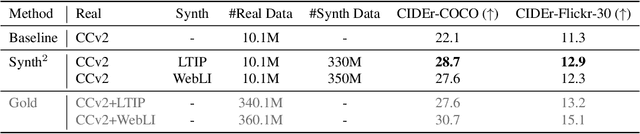
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
Break-for-Make: Modular Low-Rank Adaptations for Composable Content-Style Customization
Mar 31, 2024
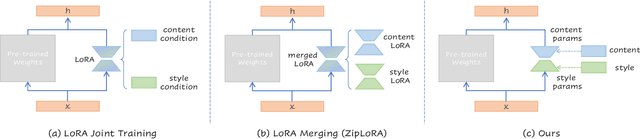
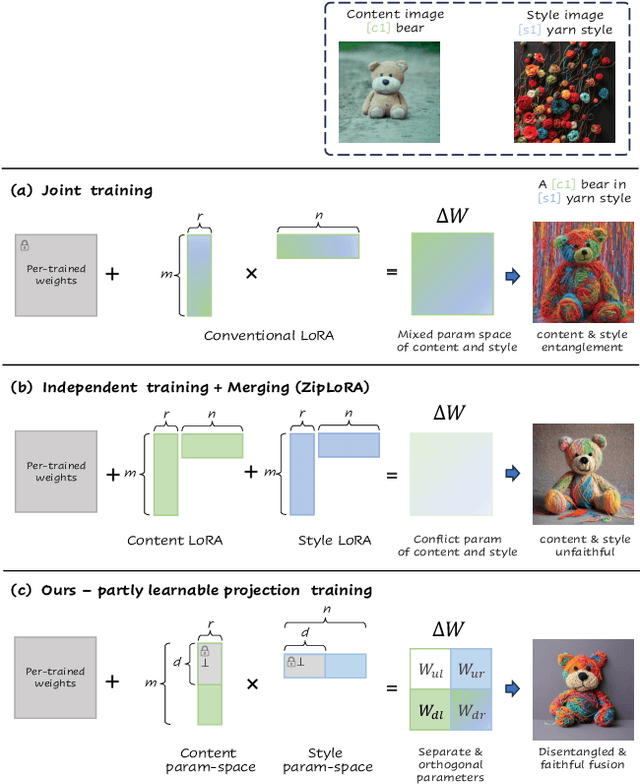
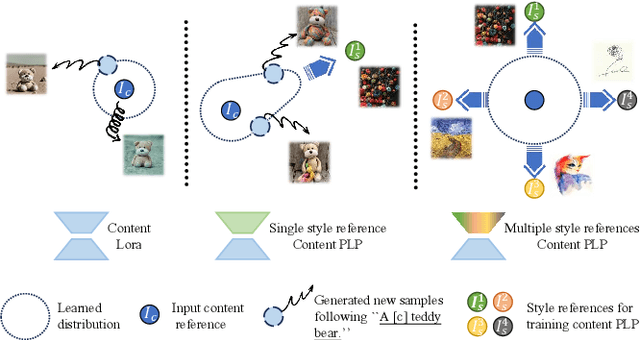
Personalized generation paradigms empower designers to customize visual intellectual properties with the help of textual descriptions by tuning or adapting pre-trained text-to-image models on a few images. Recent works explore approaches for concurrently customizing both content and detailed visual style appearance. However, these existing approaches often generate images where the content and style are entangled. In this study, we reconsider the customization of content and style concepts from the perspective of parameter space construction. Unlike existing methods that utilize a shared parameter space for content and style, we propose a learning framework that separates the parameter space to facilitate individual learning of content and style, thereby enabling disentangled content and style. To achieve this goal, we introduce "partly learnable projection" (PLP) matrices to separate the original adapters into divided sub-parameter spaces. We propose "break-for-make" customization learning pipeline based on PLP, which is simple yet effective. We break the original adapters into "up projection" and "down projection", train content and style PLPs individually with the guidance of corresponding textual prompts in the separate adapters, and maintain generalization by employing a multi-correspondence projection learning strategy. Based on the adapters broken apart for separate training content and style, we then make the entity parameter space by reconstructing the content and style PLPs matrices, followed by fine-tuning the combined adapter to generate the target object with the desired appearance. Experiments on various styles, including textures, materials, and artistic style, show that our method outperforms state-of-the-art single/multiple concept learning pipelines in terms of content-style-prompt alignment.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
Denoising Monte Carlo Renders With Diffusion Models
Mar 30, 2024Physically-based renderings contain Monte-Carlo noise, with variance that increases as the number of rays per pixel decreases. This noise, while zero-mean for good modern renderers, can have heavy tails (most notably, for scenes containing specular or refractive objects). Learned methods for restoring low fidelity renders are highly developed, because suppressing render noise means one can save compute and use fast renders with few rays per pixel. We demonstrate that a diffusion model can denoise low fidelity renders successfully. Furthermore, our method can be conditioned on a variety of natural render information, and this conditioning helps performance. Quantitative experiments show that our method is competitive with SOTA across a range of sampling rates, but current metrics slightly favor competitor methods. Qualitative examination of the reconstructions suggests that the metrics themselves may not be reliable. The image prior applied by a diffusion method strongly favors reconstructions that are "like" real images -- so have straight shadow boundaries, curved specularities, no "fireflies" and the like -- and metrics do not account for this. We show numerous examples where methods preferred by current metrics produce qualitatively weaker reconstructions than ours.
T-Pixel2Mesh: Combining Global and Local Transformer for 3D Mesh Generation from a Single Image
Mar 20, 2024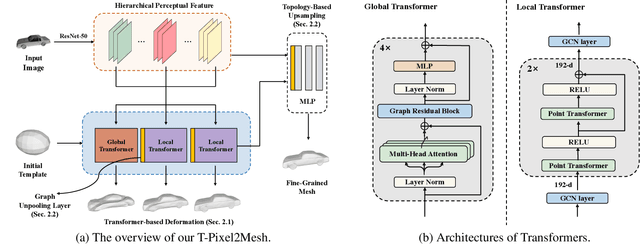
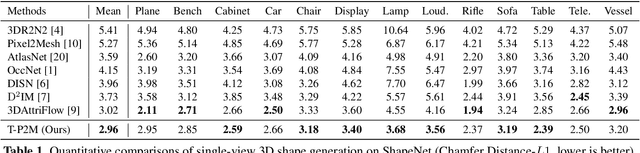
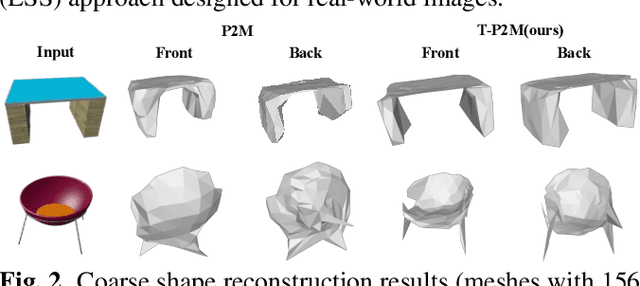
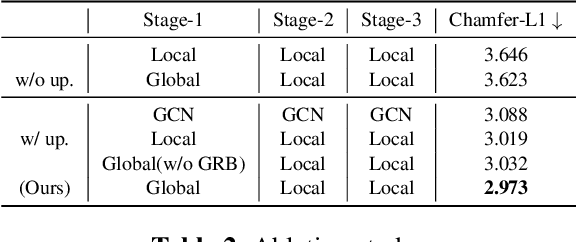
Pixel2Mesh (P2M) is a classical approach for reconstructing 3D shapes from a single color image through coarse-to-fine mesh deformation. Although P2M is capable of generating plausible global shapes, its Graph Convolution Network (GCN) often produces overly smooth results, causing the loss of fine-grained geometry details. Moreover, P2M generates non-credible features for occluded regions and struggles with the domain gap from synthetic data to real-world images, which is a common challenge for single-view 3D reconstruction methods. To address these challenges, we propose a novel Transformer-boosted architecture, named T-Pixel2Mesh, inspired by the coarse-to-fine approach of P2M. Specifically, we use a global Transformer to control the holistic shape and a local Transformer to progressively refine the local geometry details with graph-based point upsampling. To enhance real-world reconstruction, we present the simple yet effective Linear Scale Search (LSS), which serves as prompt tuning during the input preprocessing. Our experiments on ShapeNet demonstrate state-of-the-art performance, while results on real-world data show the generalization capability.
Low Rank Groupwise Deformations for Motion Tracking in Cardiac Cine MRI
Mar 24, 2024Diffeomorphic image registration is a commonly used method to deform one image to resemble another. While warping a single image to another is useful, it can be advantageous to warp multiple images simultaneously, such as in tracking the motion of the heart across a sequence of images. In this paper, our objective is to propose a novel method capable of registering a group or sequence of images to a target image, resulting in registered images that appear identical and therefore have a low rank. Moreover, we aim for these registered images to closely resemble the target image. Through experimental evidence, we will demonstrate our method's superior efficacy in producing low-rank groupwise deformations compared to other state-of-the-art approaches.
Codebook Transfer with Part-of-Speech for Vector-Quantized Image Modeling
Mar 15, 2024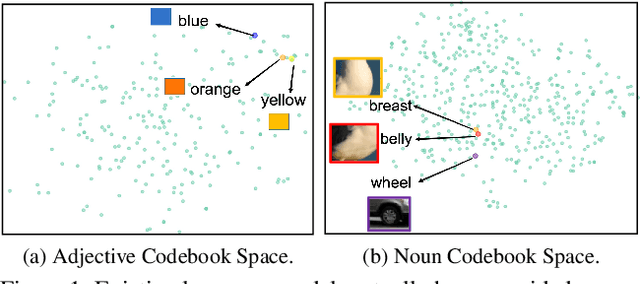

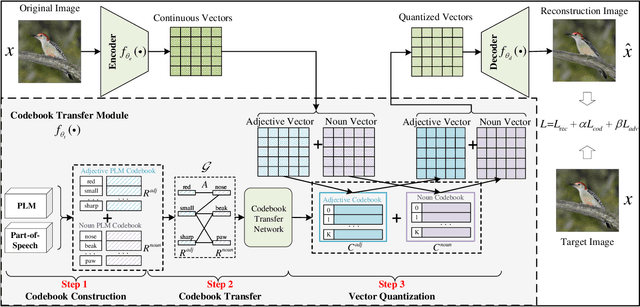
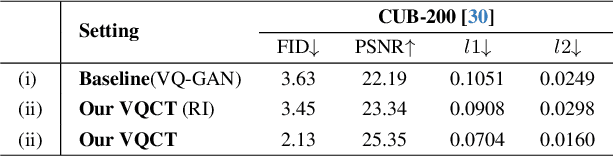
Vector-Quantized Image Modeling (VQIM) is a fundamental research problem in image synthesis, which aims to represent an image with a discrete token sequence. Existing studies effectively address this problem by learning a discrete codebook from scratch and in a code-independent manner to quantize continuous representations into discrete tokens. However, learning a codebook from scratch and in a code-independent manner is highly challenging, which may be a key reason causing codebook collapse, i.e., some code vectors can rarely be optimized without regard to the relationship between codes and good codebook priors such that die off finally. In this paper, inspired by pretrained language models, we find that these language models have actually pretrained a superior codebook via a large number of text corpus, but such information is rarely exploited in VQIM. To this end, we propose a novel codebook transfer framework with part-of-speech, called VQCT, which aims to transfer a well-trained codebook from pretrained language models to VQIM for robust codebook learning. Specifically, we first introduce a pretrained codebook from language models and part-of-speech knowledge as priors. Then, we construct a vision-related codebook with these priors for achieving codebook transfer. Finally, a novel codebook transfer network is designed to exploit abundant semantic relationships between codes contained in pretrained codebooks for robust VQIM codebook learning. Experimental results on four datasets show that our VQCT method achieves superior VQIM performance over previous state-of-the-art methods.