 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Generalizability of Image-to-Image Translation for Enhanced Adversarial Defense
Apr 02, 2025



In the rapidly evolving field of artificial intelligence, machine learning emerges as a key technology characterized by its vast potential and inherent risks. The stability and reliability of these models are important, as they are frequent targets of security threats. Adversarial attacks, first rigorously defined by Ian Goodfellow et al. in 2013, highlight a critical vulnerability: they can trick machine learning models into making incorrect predictions by applying nearly invisible perturbations to images. Although many studies have focused on constructing sophisticated defensive mechanisms to mitigate such attacks, they often overlook the substantial time and computational costs of training and maintaining these models. Ideally, a defense method should be able to generalize across various, even unseen, adversarial attacks with minimal overhead. Building on our previous work on image-to-image translation-based defenses, this study introduces an improved model that incorporates residual blocks to enhance generalizability. The proposed method requires training only a single model, effectively defends against diverse attack types, and is well-transferable between different target models. Experiments show that our model can restore the classification accuracy from near zero to an average of 72\% while maintaining competitive performance compared to state-of-the-art methods.
A Review on Machine Unlearning
Nov 18, 2024Recently, an increasing number of laws have governed the useability of users' privacy. For example, Article 17 of the General Data Protection Regulation (GDPR), the right to be forgotten, requires machine learning applications to remove a portion of data from a dataset and retrain it if the user makes such a request. Furthermore, from the security perspective, training data for machine learning models, i.e., data that may contain user privacy, should be effectively protected, including appropriate erasure. Therefore, researchers propose various privacy-preserving methods to deal with such issues as machine unlearning. This paper provides an in-depth review of the security and privacy concerns in machine learning models. First, we present how machine learning can use users' private data in daily life and the role that the GDPR plays in this problem. Then, we introduce the concept of machine unlearning by describing the security threats in machine learning models and how to protect users' privacy from being violated using machine learning platforms. As the core content of the paper, we introduce and analyze current machine unlearning approaches and several representative research results and discuss them in the context of the data lineage. Furthermore, we also discuss the future research challenges in this field.
Trustworthy Federated Learning: Privacy, Security, and Beyond
Nov 03, 2024



While recent years have witnessed the advancement in big data and Artificial Intelligence (AI), it is of much importance to safeguard data privacy and security. As an innovative approach, Federated Learning (FL) addresses these concerns by facilitating collaborative model training across distributed data sources without transferring raw data. However, the challenges of robust security and privacy across decentralized networks catch significant attention in dealing with the distributed data in FL. In this paper, we conduct an extensive survey of the security and privacy issues prevalent in FL, underscoring the vulnerability of communication links and the potential for cyber threats. We delve into various defensive strategies to mitigate these risks, explore the applications of FL across different sectors, and propose research directions. We identify the intricate security challenges that arise within the FL frameworks, aiming to contribute to the development of secure and efficient FL systems.
PAD-FT: A Lightweight Defense for Backdoor Attacks via Data Purification and Fine-Tuning
Sep 18, 2024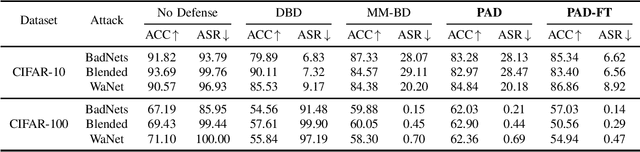
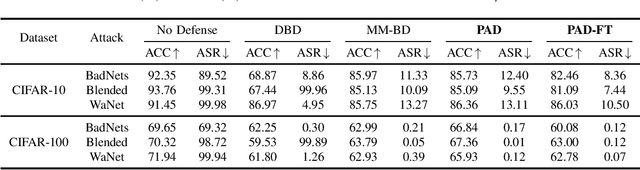

Backdoor attacks pose a significant threat to deep neural networks, particularly as recent advancements have led to increasingly subtle implantation, making the defense more challenging. Existing defense mechanisms typically rely on an additional clean dataset as a standard reference and involve retraining an auxiliary model or fine-tuning the entire victim model. However, these approaches are often computationally expensive and not always feasible in practical applications. In this paper, we propose a novel and lightweight defense mechanism, termed PAD-FT, that does not require an additional clean dataset and fine-tunes only a very small part of the model to disinfect the victim model. To achieve this, our approach first introduces a simple data purification process to identify and select the most-likely clean data from the poisoned training dataset. The self-purified clean dataset is then used for activation clipping and fine-tuning only the last classification layer of the victim model. By integrating data purification, activation clipping, and classifier fine-tuning, our mechanism PAD-FT demonstrates superior effectiveness across multiple backdoor attack methods and datasets, as confirmed through extensive experimental evaluation.
FreeMark: A Non-Invasive White-Box Watermarking for Deep Neural Networks
Sep 16, 2024Deep neural networks (DNNs) have achieved significant success in real-world applications. However, safeguarding their intellectual property (IP) remains extremely challenging. Existing DNN watermarking for IP protection often require modifying DNN models, which reduces model performance and limits their practicality. This paper introduces FreeMark, a novel DNN watermarking framework that leverages cryptographic principles without altering the original host DNN model, thereby avoiding any reduction in model performance. Unlike traditional DNN watermarking methods, FreeMark innovatively generates secret keys from a pre-generated watermark vector and the host model using gradient descent. These secret keys, used to extract watermark from the model's activation values, are securely stored with a trusted third party, enabling reliable watermark extraction from suspect models. Extensive experiments demonstrate that FreeMark effectively resists various watermark removal attacks while maintaining high watermark capacity.
The Impact of Prompts on Zero-Shot Detection of AI-Generated Text
Mar 29, 2024In recent years, there have been significant advancements in the development of Large Language Models (LLMs). While their practical applications are now widespread, their potential for misuse, such as generating fake news and committing plagiarism, has posed significant concerns. To address this issue, detectors have been developed to evaluate whether a given text is human-generated or AI-generated. Among others, zero-shot detectors stand out as effective approaches that do not require additional training data and are often likelihood-based. In chat-based applications, users commonly input prompts and utilize the AI-generated texts. However, zero-shot detectors typically analyze these texts in isolation, neglecting the impact of the original prompts. It is conceivable that this approach may lead to a discrepancy in likelihood assessments between the text generation phase and the detection phase. So far, there remains an unverified gap concerning how the presence or absence of prompts impacts detection accuracy for zero-shot detectors. In this paper, we introduce an evaluative framework to empirically analyze the impact of prompts on the detection accuracy of AI-generated text. We assess various zero-shot detectors using both white-box detection, which leverages the prompt, and black-box detection, which operates without prompt information. Our experiments reveal the significant influence of prompts on detection accuracy. Remarkably, compared with black-box detection without prompts, the white-box methods using prompts demonstrate an increase in AUC of at least $0.1$ across all zero-shot detectors tested. Code is available: \url{https://github.com/kaito25atugich/Detector}.
Versatile Defense Against Adversarial Attacks on Image Recognition
Mar 13, 2024Adversarial attacks present a significant security risk to image recognition tasks. Defending against these attacks in a real-life setting can be compared to the way antivirus software works, with a key consideration being how well the defense can adapt to new and evolving attacks. Another important factor is the resources involved in terms of time and cost for training defense models and updating the model database. Training many models that are specific to each type of attack can be time-consuming and expensive. Ideally, we should be able to train one single model that can handle a wide range of attacks. It appears that a defense method based on image-to-image translation may be capable of this. The proposed versatile defense approach in this paper only requires training one model to effectively resist various unknown adversarial attacks. The trained model has successfully improved the classification accuracy from nearly zero to an average of 86%, performing better than other defense methods proposed in prior studies. When facing the PGD attack and the MI-FGSM attack, versatile defense model even outperforms the attack-specific models trained based on these two attacks. The robustness check also shows that our versatile defense model performs stably regardless with the attack strength.
Attacking Convolutional Neural Network using Differential Evolution
Apr 19, 2018
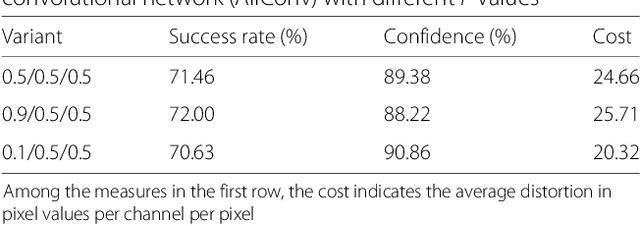

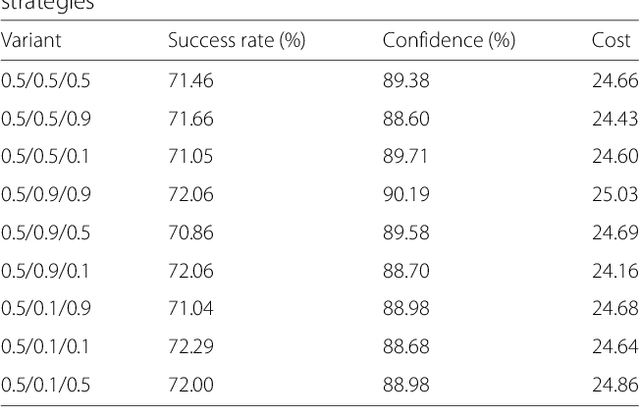
The output of Convolutional Neural Networks (CNN) has been shown to be discontinuous which can make the CNN image classifier vulnerable to small well-tuned artificial perturbations. That is, images modified by adding such perturbations(i.e. adversarial perturbations) that make little difference to human eyes, can completely alter the CNN classification results. In this paper, we propose a practical attack using differential evolution(DE) for generating effective adversarial perturbations. We comprehensively evaluate the effectiveness of different types of DEs for conducting the attack on different network structures. The proposed method is a black-box attack which only requires the miracle feedback of the target CNN systems. The results show that under strict constraints which simultaneously control the number of pixels changed and overall perturbation strength, attacking can achieve 72.29%, 78.24% and 61.28% non-targeted attack success rates, with 88.68%, 99.85% and 73.07% confidence on average, on three common types of CNNs. The attack only requires modifying 5 pixels with 20.44, 14.76 and 22.98 pixel values distortion. Thus, the result shows that the current DNNs are also vulnerable to such simpler black-box attacks even under very limited attack conditions.
Lightweight Classification of IoT Malware based on Image Recognition
Feb 11, 2018



The Internet of Things (IoT) is an extension of the traditional Internet, which allows a very large number of smart devices, such as home appliances, network cameras, sensors and controllers to connect to one another to share information and improve user experiences. Current IoT devices are typically micro-computers for domain-specific computations rather than traditional functionspecific embedded devices. Therefore, many existing attacks, targeted at traditional computers connected to the Internet, may also be directed at IoT devices. For example, DDoS attacks have become very common in IoT environments, as these environments currently lack basic security monitoring and protection mechanisms, as shown by the recent Mirai and Brickerbot IoT botnets. In this paper, we propose a novel light-weight approach for detecting DDos malware in IoT environments.We firstly extract one-channel gray-scale images converted from binaries, and then utilize a lightweight convolutional neural network for classifying IoT malware families. The experimental results show that the proposed system can achieve 94.0% accuracy for the classification of goodware and DDoS malware, and 81.8% accuracy for the classification of goodware and two main malware families.