 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model
Apr 10, 2023
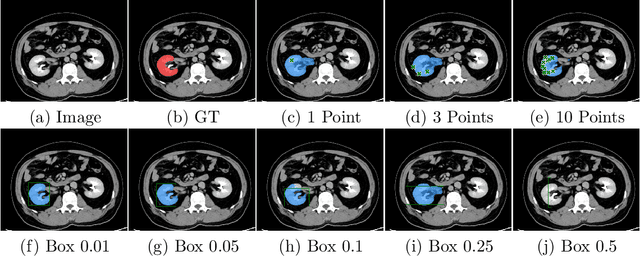
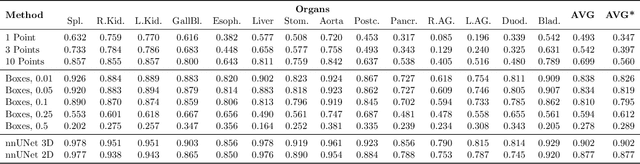
Foundation models have taken over natural language processing and image generation domains due to the flexibility of prompting. With the recent introduction of the Segment Anything Model (SAM), this prompt-driven paradigm has entered image segmentation with a hitherto unexplored abundance of capabilities. The purpose of this paper is to conduct an initial evaluation of the out-of-the-box zero-shot capabilities of SAM for medical image segmentation, by evaluating its performance on an abdominal CT organ segmentation task, via point or bounding box based prompting. We show that SAM generalizes well to CT data, making it a potential catalyst for the advancement of semi-automatic segmentation tools for clinicians. We believe that this foundation model, while not reaching state-of-the-art segmentation performance in our investigations, can serve as a highly potent starting point for further adaptations of such models to the intricacies of the medical domain. Keywords: medical image segmentation, SAM, foundation models, zero-shot learning
1st Solution Places for CVPR 2023 UG$^{\textbf{2}}$+ Challenge Track 2.1-Text Recognition through Atmospheric Turbulence
Jun 15, 2023In this technical report, we present the solution developed by our team VIELab-HUST for text recognition through atmospheric turbulence in Track 2.1 of the CVPR 2023 UG$^{2}$+ challenge. Our solution involves an efficient multi-stage framework that restores a high-quality image from distorted frames. Specifically, a frame selection algorithm based on sharpness is first utilized to select the sharpest set of distorted frames. Next, each frame in the selected frames is aligned to suppress geometric distortion through optical-flow-based image registration. Then, a region-based image fusion method with DT-CWT is utilized to mitigate the blur caused by the turbulence. Finally, a learning-based deartifacts method is applied to remove the artifacts in the fused image, generating a high-quality outuput. Our framework can handle both hot-air text dataset and turbulence text dataset provided in the final testing phase and achieved 1st place in text recognition accuracy. Our code will be available at https://github.com/xsqhust/Turbulence_Removal.
MoViT: Memorizing Vision Transformers for Medical Image Analysis
Apr 04, 2023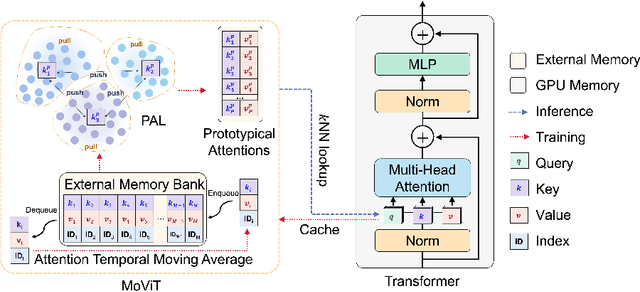
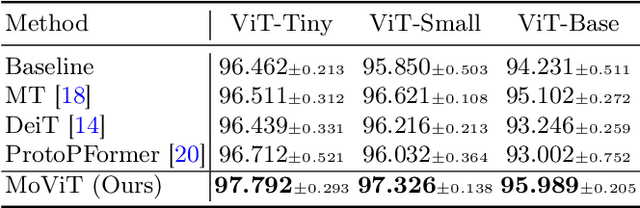
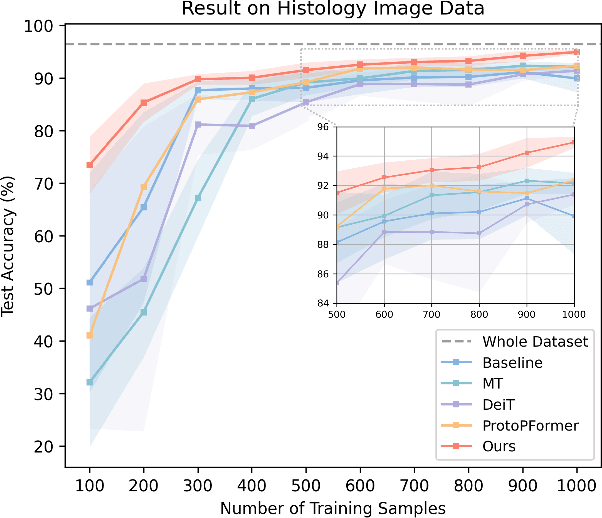
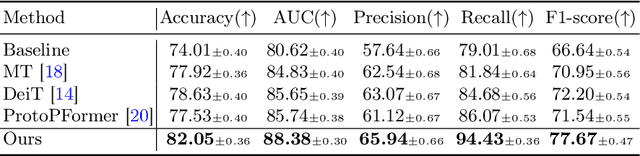
The synergy of long-range dependencies from transformers and local representations of image content from convolutional neural networks (CNNs) has led to advanced architectures and increased performance for various medical image analysis tasks due to their complementary benefits. However, compared with CNNs, transformers require considerably more training data, due to a larger number of parameters and an absence of inductive bias. The need for increasingly large datasets continues to be problematic, particularly in the context of medical imaging, where both annotation efforts and data protection result in limited data availability. In this work, inspired by the human decision-making process of correlating new ``evidence'' with previously memorized ``experience'', we propose a Memorizing Vision Transformer (MoViT) to alleviate the need for large-scale datasets to successfully train and deploy transformer-based architectures. MoViT leverages an external memory structure to cache history attention snapshots during the training stage. To prevent overfitting, we incorporate an innovative memory update scheme, attention temporal moving average, to update the stored external memories with the historical moving average. For inference speedup, we design a prototypical attention learning method to distill the external memory into smaller representative subsets. We evaluate our method on a public histology image dataset and an in-house MRI dataset, demonstrating that MoViT applied to varied medical image analysis tasks, can outperform vanilla transformer models across varied data regimes, especially in cases where only a small amount of annotated data is available. More importantly, MoViT can reach a competitive performance of ViT with only 3.0% of the training data.
Expressive Text-to-Image Generation with Rich Text
Apr 13, 2023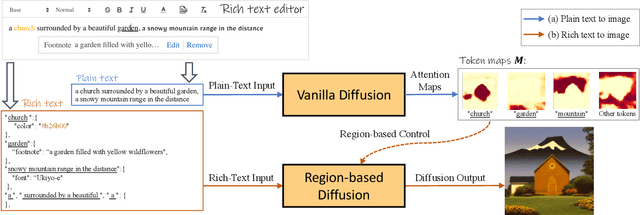


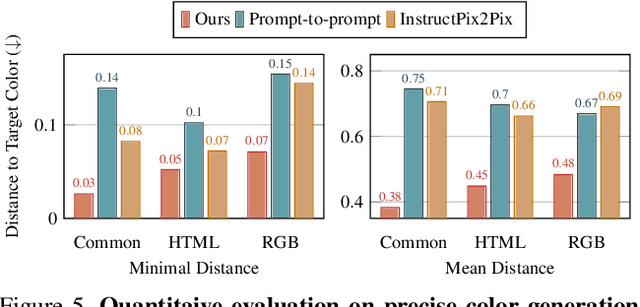
Plain text has become a prevalent interface for text-to-image synthesis. However, its limited customization options hinder users from accurately describing desired outputs. For example, plain text makes it hard to specify continuous quantities, such as the precise RGB color value or importance of each word. Furthermore, creating detailed text prompts for complex scenes is tedious for humans to write and challenging for text encoders to interpret. To address these challenges, we propose using a rich-text editor supporting formats such as font style, size, color, and footnote. We extract each word's attributes from rich text to enable local style control, explicit token reweighting, precise color rendering, and detailed region synthesis. We achieve these capabilities through a region-based diffusion process. We first obtain each word's region based on cross-attention maps of a vanilla diffusion process using plain text. For each region, we enforce its text attributes by creating region-specific detailed prompts and applying region-specific guidance. We present various examples of image generation from rich text and demonstrate that our method outperforms strong baselines with quantitative evaluations.
DPAF: Image Synthesis via Differentially Private Aggregation in Forward Phase
Apr 20, 2023
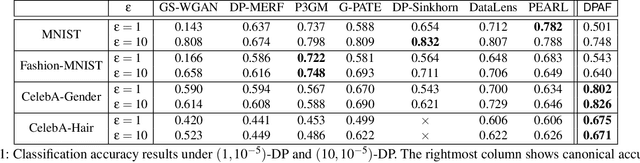
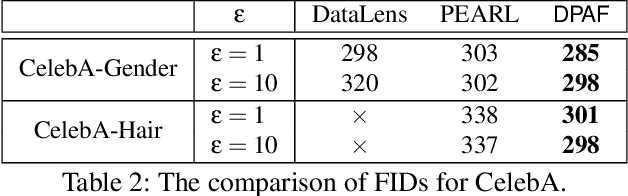
Differentially private synthetic data is a promising alternative for sensitive data release. Many differentially private generative models have been proposed in the literature. Unfortunately, they all suffer from the low utility of the synthetic data, particularly for images of high resolutions. Here, we propose DPAF, an effective differentially private generative model for high-dimensional image synthesis. Different from the prior private stochastic gradient descent-based methods that add Gaussian noises in the backward phase during the model training, DPAF adds a differentially private feature aggregation in the forward phase, bringing advantages, including the reduction of information loss in gradient clipping and low sensitivity for the aggregation. Moreover, as an improper batch size has an adverse impact on the utility of synthetic data, DPAF also tackles the problem of setting a proper batch size by proposing a novel training strategy that asymmetrically trains different parts of the discriminator. We extensively evaluate different methods on multiple image datasets (up to images of 128x128 resolution) to demonstrate the performance of DPAF.
Hierarchical Fine-Grained Image Forgery Detection and Localization
Mar 30, 2023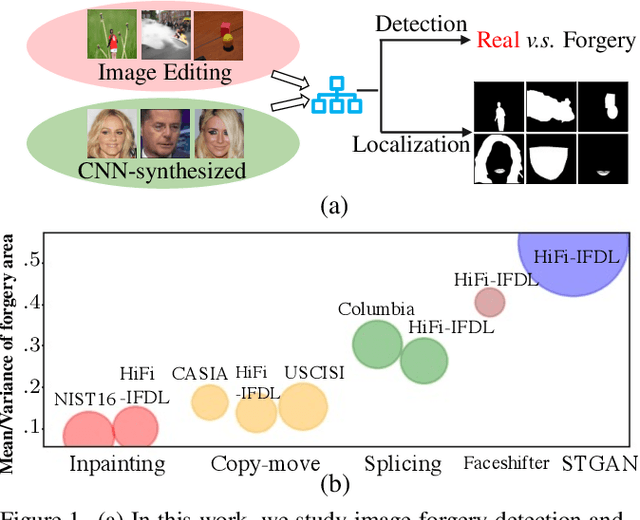
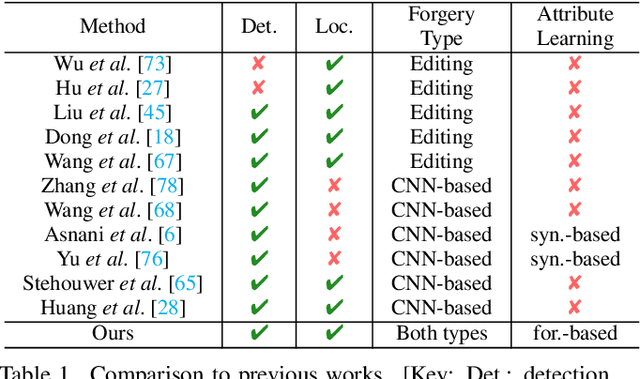
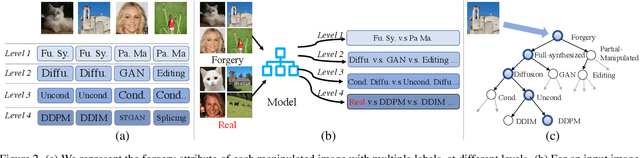
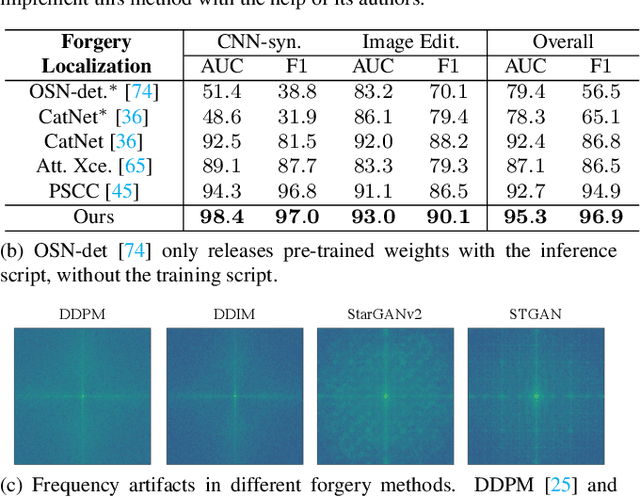
Differences in forgery attributes of images generated in CNN-synthesized and image-editing domains are large, and such differences make a unified image forgery detection and localization (IFDL) challenging. To this end, we present a hierarchical fine-grained formulation for IFDL representation learning. Specifically, we first represent forgery attributes of a manipulated image with multiple labels at different levels. Then we perform fine-grained classification at these levels using the hierarchical dependency between them. As a result, the algorithm is encouraged to learn both comprehensive features and inherent hierarchical nature of different forgery attributes, thereby improving the IFDL representation. Our proposed IFDL framework contains three components: multi-branch feature extractor, localization and classification modules. Each branch of the feature extractor learns to classify forgery attributes at one level, while localization and classification modules segment the pixel-level forgery region and detect image-level forgery, respectively. Lastly, we construct a hierarchical fine-grained dataset to facilitate our study. We demonstrate the effectiveness of our method on $7$ different benchmarks, for both tasks of IFDL and forgery attribute classification. Our source code and dataset can be found: \href{https://github.com/CHELSEA234/HiFi_IFDL}{github.com/CHELSEA234/HiFi-IFDL}.
Unsupervised Image Denoising with Score Function
Apr 17, 2023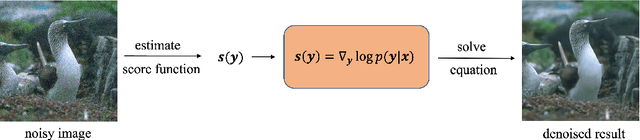

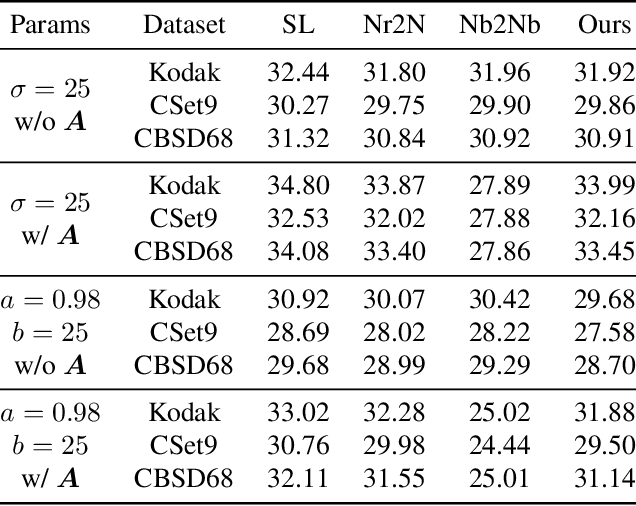
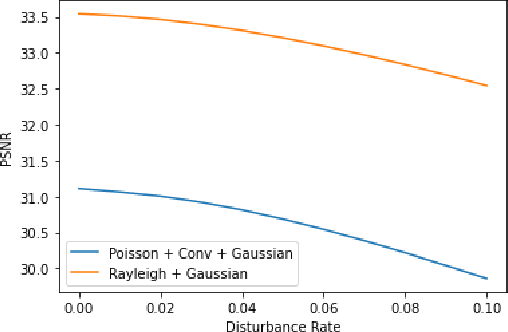
Though achieving excellent performance in some cases, current unsupervised learning methods for single image denoising usually have constraints in applications. In this paper, we propose a new approach which is more general and applicable to complicated noise models. Utilizing the property of score function, the gradient of logarithmic probability, we define a solving system for denoising. Once the score function of noisy images has been estimated, the denoised result can be obtained through the solving system. Our approach can be applied to multiple noise models, such as the mixture of multiplicative and additive noise combined with structured correlation. Experimental results show that our method is comparable when the noise model is simple, and has good performance in complicated cases where other methods are not applicable or perform poorly.
Sulcal Pattern Matching with the Wasserstein Distance
Jul 01, 2023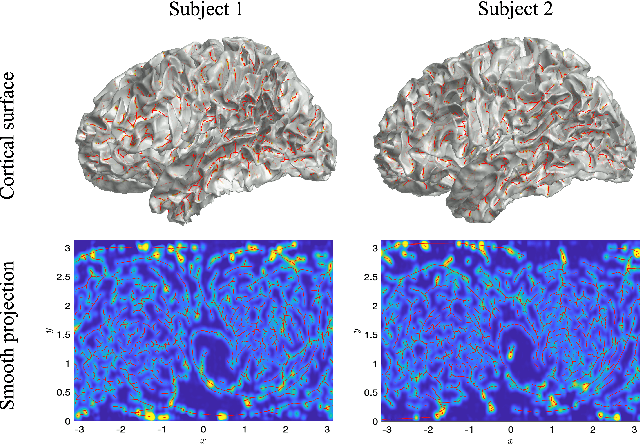
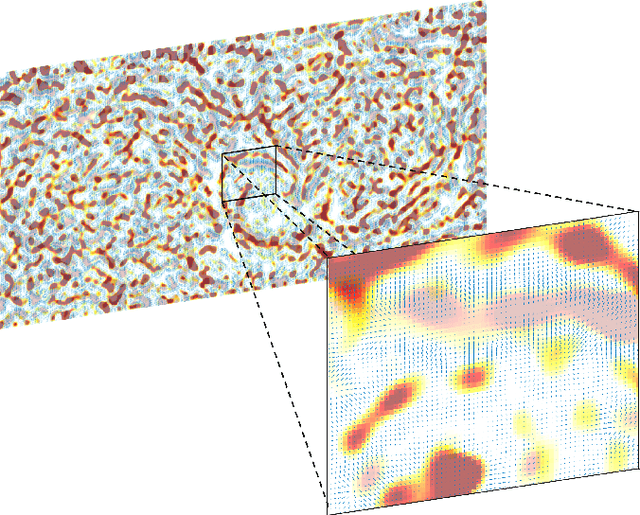
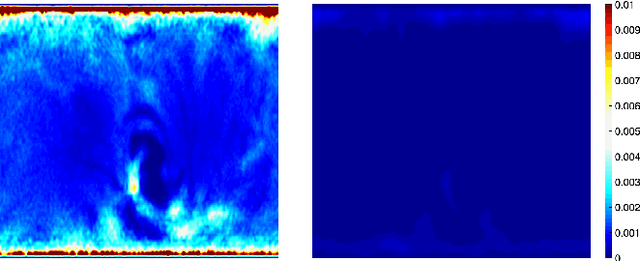
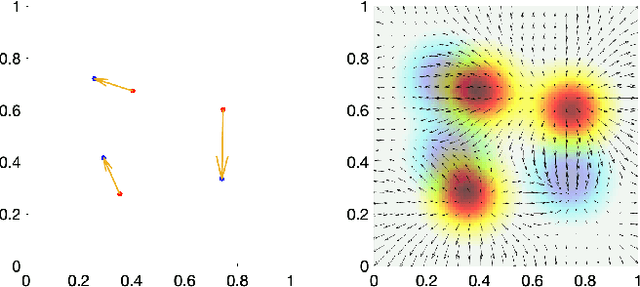
We present the unified computational framework for modeling the sulcal patterns of human brain obtained from the magnetic resonance images. The Wasserstein distance is used to align the sulcal patterns nonlinearly. These patterns are topologically different across subjects making the pattern matching a challenge. We work out the mathematical details and develop the gradient descent algorithms for estimating the deformation field. We further quantify the image registration performance. This method is applied in identifying the differences between male and female sulcal patterns.
Visual Language Pretrained Multiple Instance Zero-Shot Transfer for Histopathology Images
Jun 13, 2023Contrastive visual language pretraining has emerged as a powerful method for either training new language-aware image encoders or augmenting existing pretrained models with zero-shot visual recognition capabilities. However, existing works typically train on large datasets of image-text pairs and have been designed to perform downstream tasks involving only small to medium sized-images, neither of which are applicable to the emerging field of computational pathology where there are limited publicly available paired image-text datasets and each image can span up to 100,000 x 100,000 pixels. In this paper we present MI-Zero, a simple and intuitive framework for unleashing the zero-shot transfer capabilities of contrastively aligned image and text models on gigapixel histopathology whole slide images, enabling multiple downstream diagnostic tasks to be carried out by pretrained encoders without requiring any additional labels. MI-Zero reformulates zero-shot transfer under the framework of multiple instance learning to overcome the computational challenge of inference on extremely large images. We used over 550k pathology reports and other available in-domain text corpora to pre-train our text encoder. By effectively leveraging strong pre-trained encoders, our best model pretrained on over 33k histopathology image-caption pairs achieves an average median zero-shot accuracy of 70.2% across three different real-world cancer subtyping tasks. Our code is available at: https://github.com/mahmoodlab/MI-Zero.
Astronomical image time series classification using CONVolutional attENTION (ConvEntion)
Apr 03, 2023
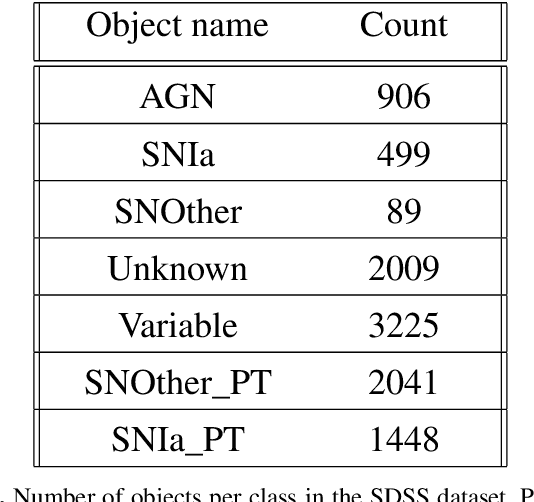
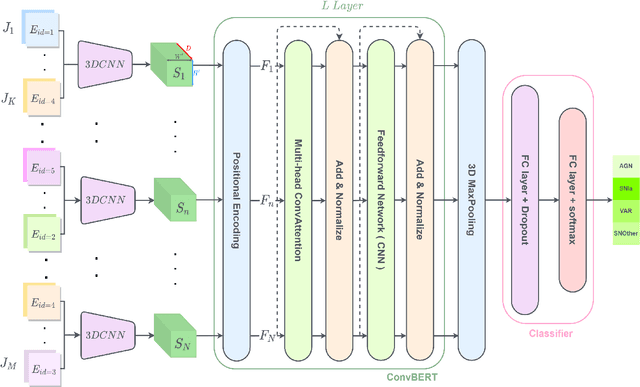
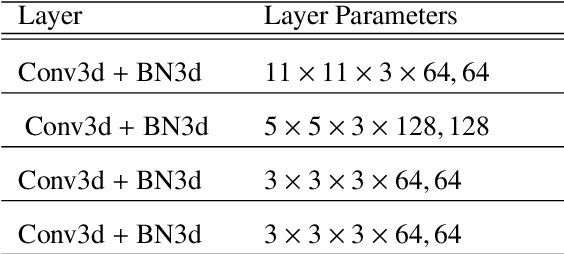
Aims. The treatment of astronomical image time series has won increasing attention in recent years. Indeed, numerous surveys following up on transient objects are in progress or under construction, such as the Vera Rubin Observatory Legacy Survey for Space and Time (LSST), which is poised to produce huge amounts of these time series. The associated scientific topics are extensive, ranging from the study of objects in our galaxy to the observation of the most distant supernovae for measuring the expansion of the universe. With such a large amount of data available, the need for robust automatic tools to detect and classify celestial objects is growing steadily. Methods. This study is based on the assumption that astronomical images contain more information than light curves. In this paper, we propose a novel approach based on deep learning for classifying different types of space objects directly using images. We named our approach ConvEntion, which stands for CONVolutional attENTION. It is based on convolutions and transformers, which are new approaches for the treatment of astronomical image time series. Our solution integrates spatio-temporal features and can be applied to various types of image datasets with any number of bands. Results. In this work, we solved various problems the datasets tend to suffer from and we present new results for classifications using astronomical image time series with an increase in accuracy of 13%, compared to state-of-the-art approaches that use image time series, and a 12% increase, compared to approaches that use light curves.