 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining
Jul 08, 2023

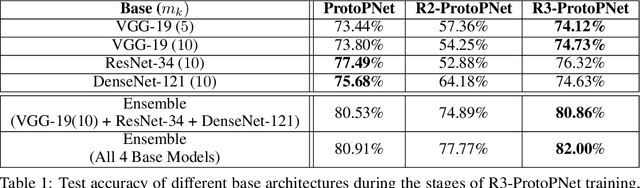
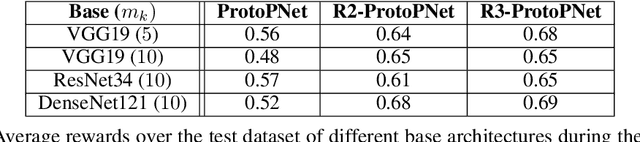
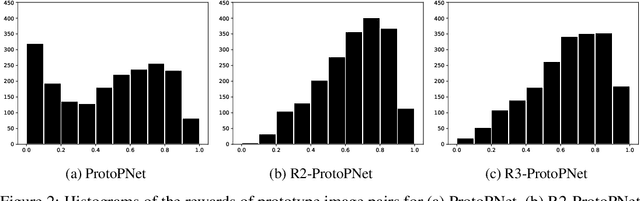
In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model's output to specific features of the data. One such of these methods is the prototypical part network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this method results in interpretable classifications, this method often learns to classify from spurious or inconsistent parts of the image. Hoping to remedy this, we take inspiration from the recent developments in Reinforcement Learning with Human Feedback (RLHF) to fine-tune these prototypes. By collecting human annotations of prototypes quality via a 1-5 scale on the CUB-200-2011 dataset, we construct a reward model that learns to identify non-spurious prototypes. In place of a full RL update, we propose the reweighted, reselected, and retrained prototypical part network (R3-ProtoPNet), which adds an additional three steps to the ProtoPNet training loop. The first two steps are reward-based reweighting and reselection, which align prototypes with human feedback. The final step is retraining to realign the model's features with the updated prototypes. We find that R3-ProtoPNet improves the overall consistency and meaningfulness of the prototypes, but lower the test predictive accuracy when used independently. When multiple R3-ProtoPNets are incorporated into an ensemble, we find an increase in test predictive performance while maintaining interpretability.
A Fully Unsupervised Instance Segmentation Technique for White Blood Cell Images
Jun 26, 2023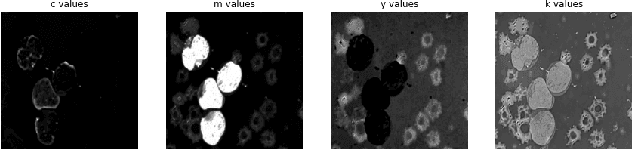
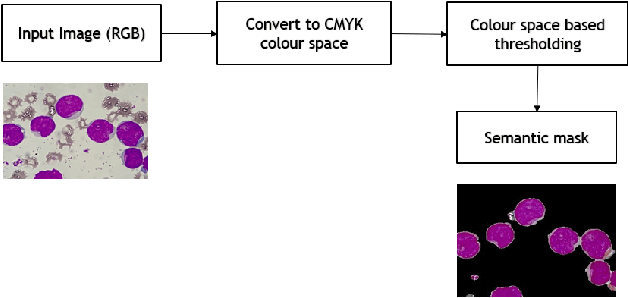
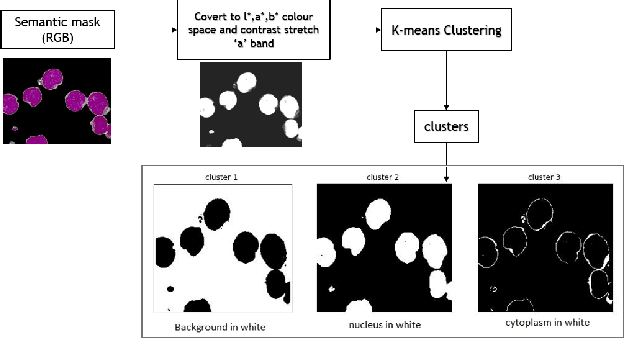
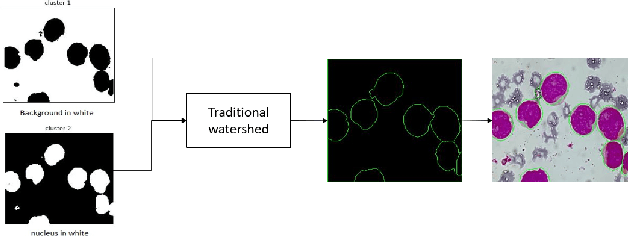
White blood cells, also known as leukocytes are group of heterogeneously nucleated cells which act as salient immune system cells. These are originated in the bone marrow and are found in blood, plasma, and lymph tissues. Leukocytes kill the bacteria, virus and other kind of pathogens which invade human body through phagocytosis that in turn results immunity. Detection of a white blood cell count can reveal camouflaged infections and warn doctors about chronic medical conditions such as autoimmune diseases, immune deficiencies, and blood disorders. Segmentation plays an important role in identification of white blood cells (WBC) from microscopic image analysis. The goal of segmentation in a microscopic image is to divide the image into different distinct regions. In our paper, we tried to propose a novel instance segmentation method for segmenting the WBCs containing both the nucleus and the cytoplasm, from bone marrow images.
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Apr 10, 2023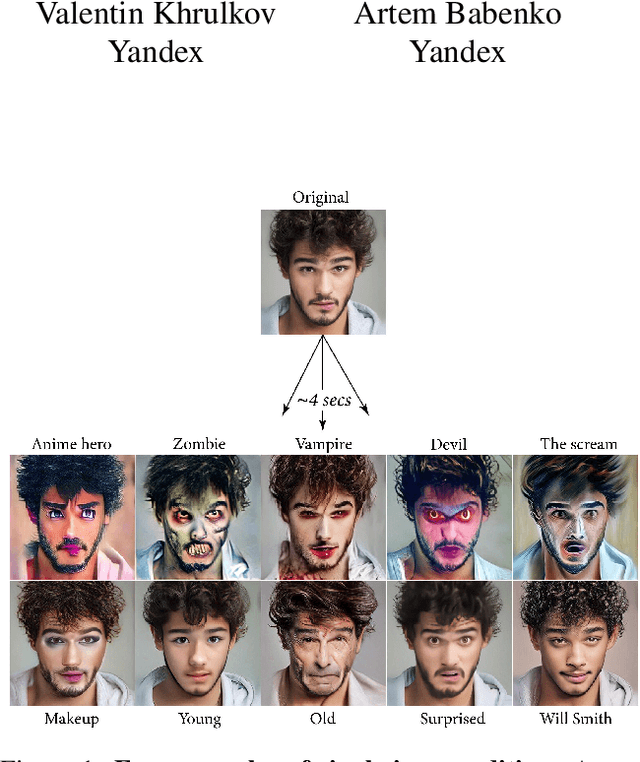
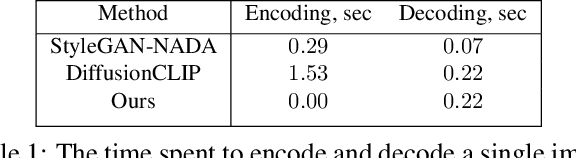
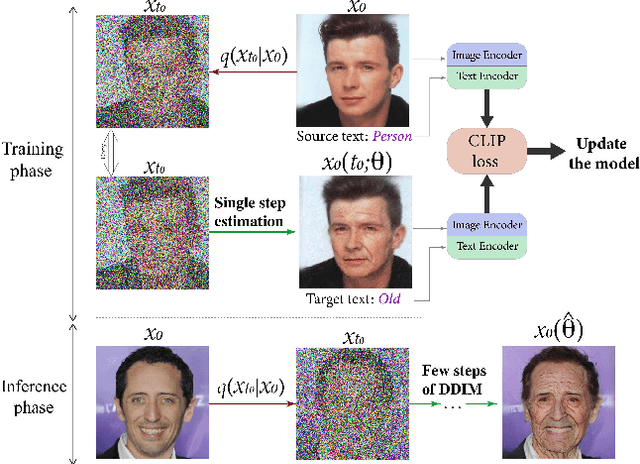
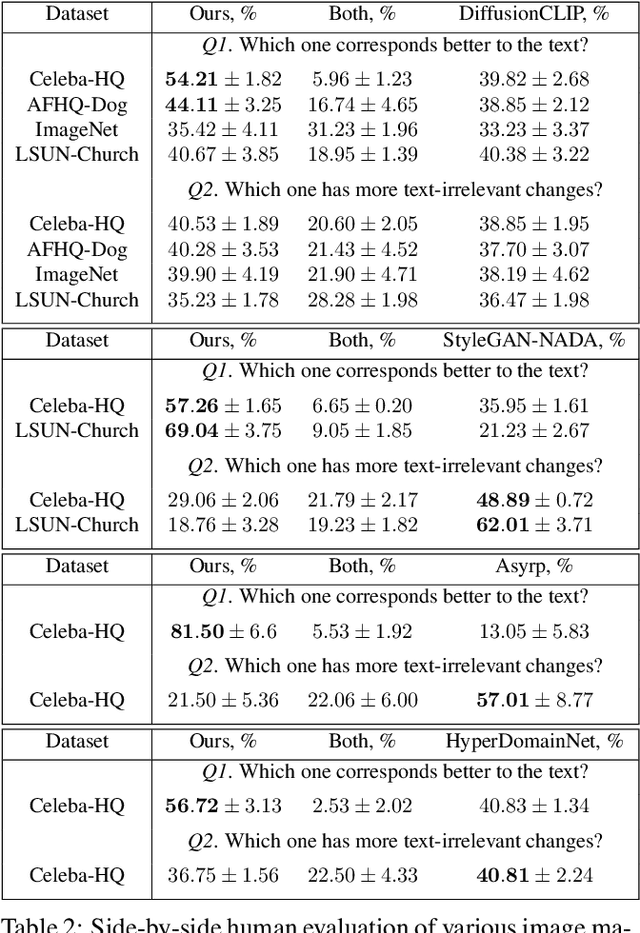
Recent advances in diffusion models enable many powerful instruments for image editing. One of these instruments is text-driven image manipulations: editing semantic attributes of an image according to the provided text description. % Popular text-conditional diffusion models offer various high-quality image manipulation methods for a broad range of text prompts. Existing diffusion-based methods already achieve high-quality image manipulations for a broad range of text prompts. However, in practice, these methods require high computation costs even with a high-end GPU. This greatly limits potential real-world applications of diffusion-based image editing, especially when running on user devices. In this paper, we address efficiency of the recent text-driven editing methods based on unconditional diffusion models and develop a novel algorithm that learns image manipulations 4.5-10 times faster and applies them 8 times faster. We carefully evaluate the visual quality and expressiveness of our approach on multiple datasets using human annotators. Our experiments demonstrate that our algorithm achieves the quality of much more expensive methods. Finally, we show that our approach can adapt the pretrained model to the user-specified image and text description on the fly just for 4 seconds. In this setting, we notice that more compact unconditional diffusion models can be considered as a rational alternative to the popular text-conditional counterparts.
Riesz feature representation: scale equivariant scattering network for classification tasks
Jul 17, 2023
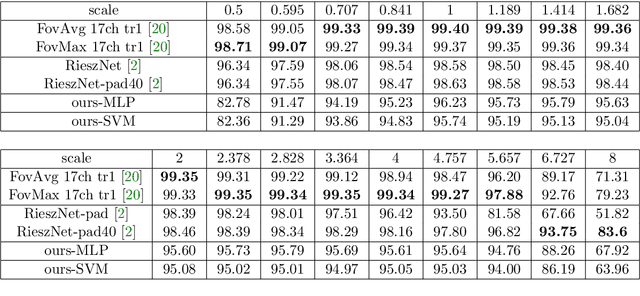

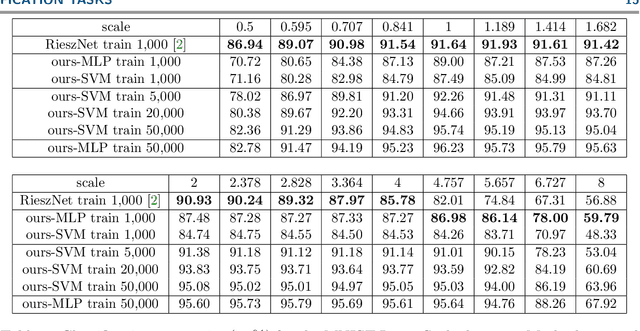
Scattering networks yield powerful and robust hierarchical image descriptors which do not require lengthy training and which work well with very few training data. However, they rely on sampling the scale dimension. Hence, they become sensitive to scale variations and are unable to generalize to unseen scales. In this work, we define an alternative feature representation based on the Riesz transform. We detail and analyze the mathematical foundations behind this representation. In particular, it inherits scale equivariance from the Riesz transform and completely avoids sampling of the scale dimension. Additionally, the number of features in the representation is reduced by a factor four compared to scattering networks. Nevertheless, our representation performs comparably well for texture classification with an interesting addition: scale equivariance. Our method yields superior performance when dealing with scales outside of those covered by the training dataset. The usefulness of the equivariance property is demonstrated on the digit classification task, where accuracy remains stable even for scales four times larger than the one chosen for training. As a second example, we consider classification of textures.
A Novel Multi-Task Model Imitating Dermatologists for Accurate Differential Diagnosis of Skin Diseases in Clinical Images
Jul 17, 2023
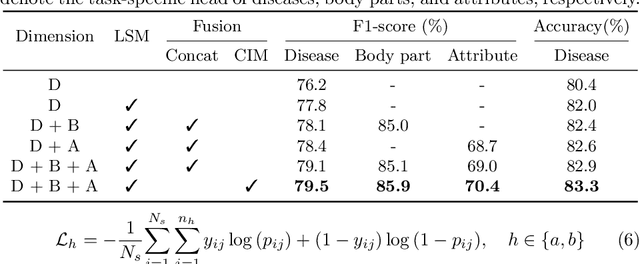
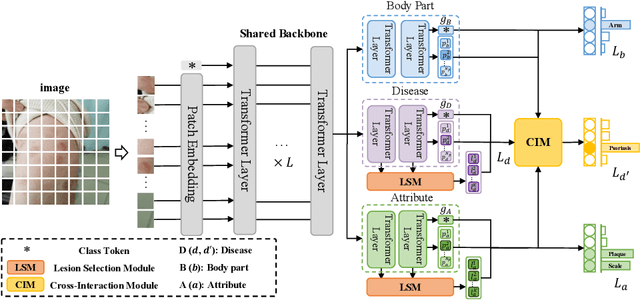
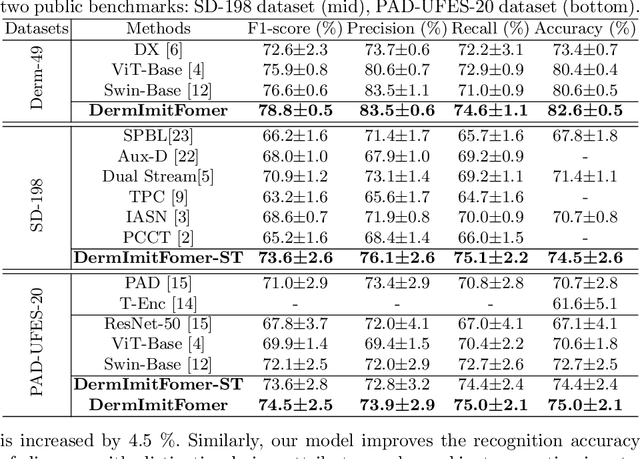
Skin diseases are among the most prevalent health issues, and accurate computer-aided diagnosis methods are of importance for both dermatologists and patients. However, most of the existing methods overlook the essential domain knowledge required for skin disease diagnosis. A novel multi-task model, namely DermImitFormer, is proposed to fill this gap by imitating dermatologists' diagnostic procedures and strategies. Through multi-task learning, the model simultaneously predicts body parts and lesion attributes in addition to the disease itself, enhancing diagnosis accuracy and improving diagnosis interpretability. The designed lesion selection module mimics dermatologists' zoom-in action, effectively highlighting the local lesion features from noisy backgrounds. Additionally, the presented cross-interaction module explicitly models the complicated diagnostic reasoning between body parts, lesion attributes, and diseases. To provide a more robust evaluation of the proposed method, a large-scale clinical image dataset of skin diseases with significantly more cases than existing datasets has been established. Extensive experiments on three different datasets consistently demonstrate the state-of-the-art recognition performance of the proposed approach.
Uncertainty-aware State Space Transformer for Egocentric 3D Hand Trajectory Forecasting
Jul 17, 2023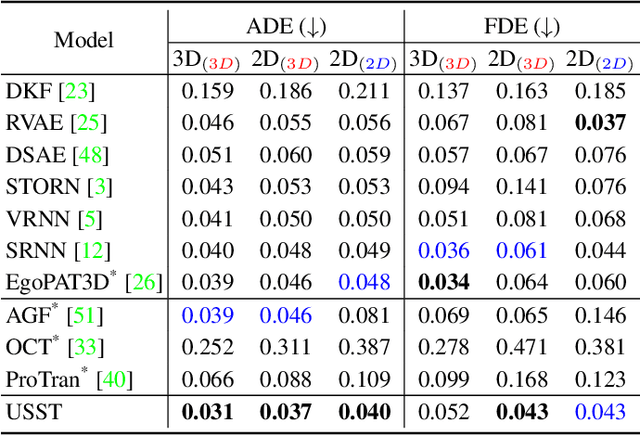
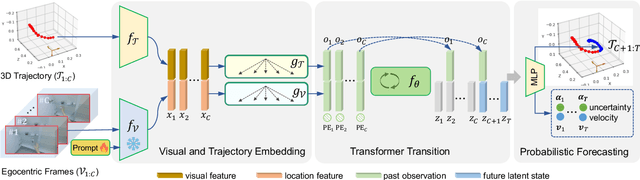
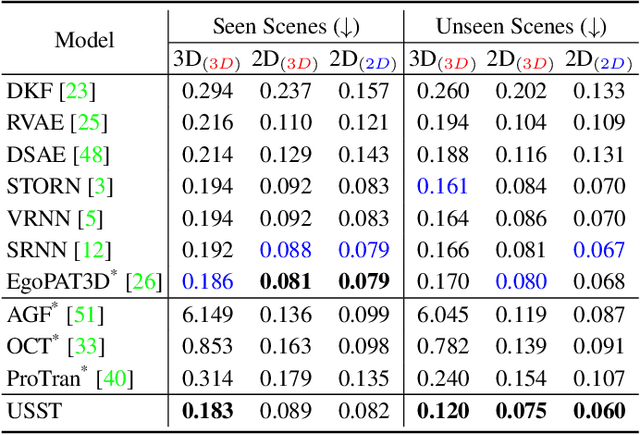
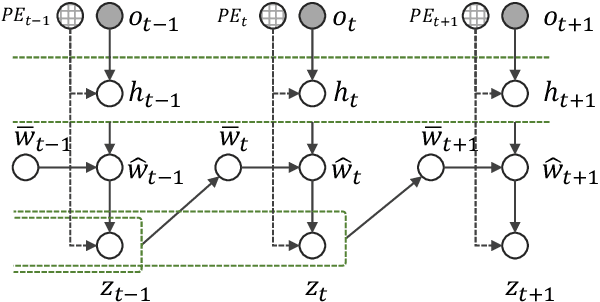
Hand trajectory forecasting from egocentric views is crucial for enabling a prompt understanding of human intentions when interacting with AR/VR systems. However, existing methods handle this problem in a 2D image space which is inadequate for 3D real-world applications. In this paper, we set up an egocentric 3D hand trajectory forecasting task that aims to predict hand trajectories in a 3D space from early observed RGB videos in a first-person view. To fulfill this goal, we propose an uncertainty-aware state space Transformer (USST) that takes the merits of the attention mechanism and aleatoric uncertainty within the framework of the classical state-space model. The model can be further enhanced by the velocity constraint and visual prompt tuning (VPT) on large vision transformers. Moreover, we develop an annotation workflow to collect 3D hand trajectories with high quality. Experimental results on H2O and EgoPAT3D datasets demonstrate the superiority of USST for both 2D and 3D trajectory forecasting. The code and datasets are publicly released: https://github.com/Cogito2012/USST.
Study of Vision Transformers for Covid-19 Detection from Chest X-rays
Jul 17, 2023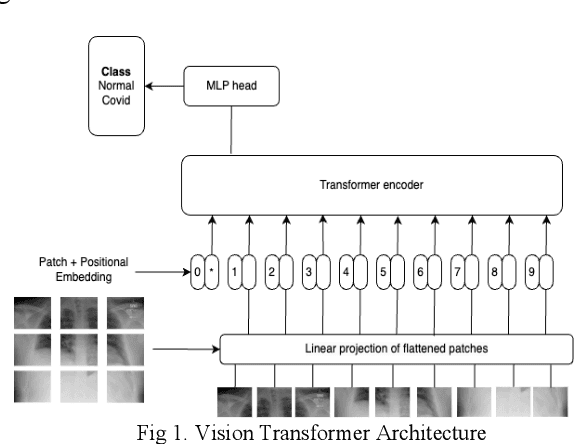
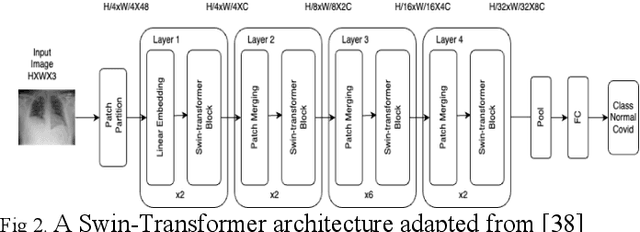
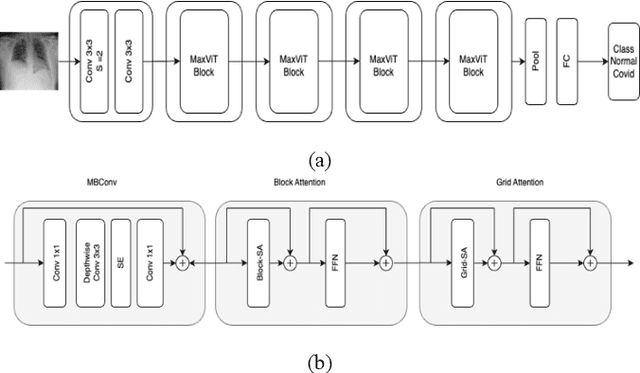
The COVID-19 pandemic has led to a global health crisis, highlighting the need for rapid and accurate virus detection. This research paper examines transfer learning with vision transformers for COVID-19 detection, known for its excellent performance in image recognition tasks. We leverage the capability of Vision Transformers to capture global context and learn complex patterns from chest X-ray images. In this work, we explored the recent state-of-art transformer models to detect Covid-19 using CXR images such as vision transformer (ViT), Swin-transformer, Max vision transformer (MViT), and Pyramid Vision transformer (PVT). Through the utilization of transfer learning with IMAGENET weights, the models achieved an impressive accuracy range of 98.75% to 99.5%. Our experiments demonstrate that Vision Transformers achieve state-of-the-art performance in COVID-19 detection, outperforming traditional methods and even Convolutional Neural Networks (CNNs). The results highlight the potential of Vision Transformers as a powerful tool for COVID-19 detection, with implications for improving the efficiency and accuracy of screening and diagnosis in clinical settings.
SG-GAN: Fine Stereoscopic-Aware Generation for 3D Brain Point Cloud Up-sampling from a Single Image
May 22, 2023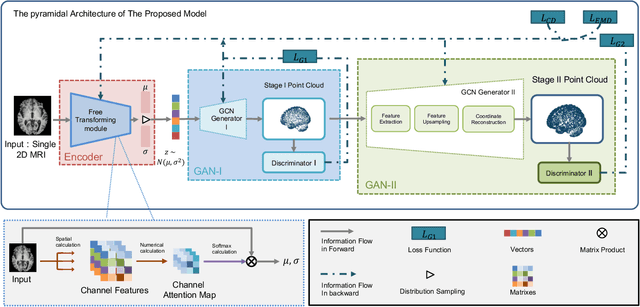
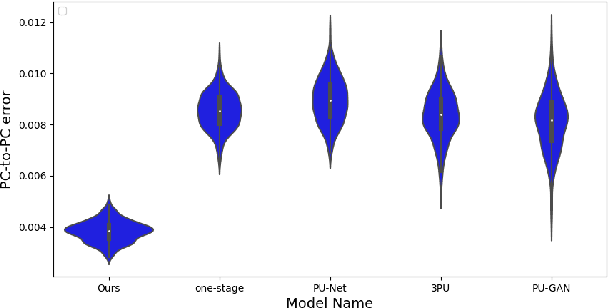
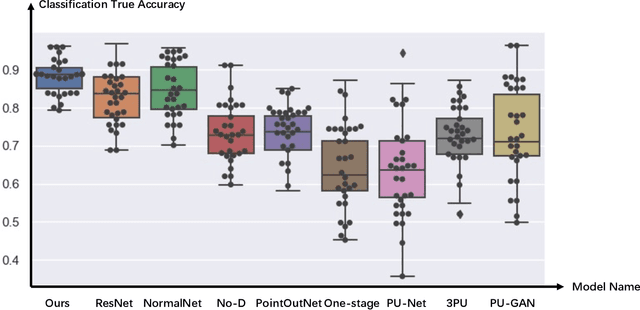
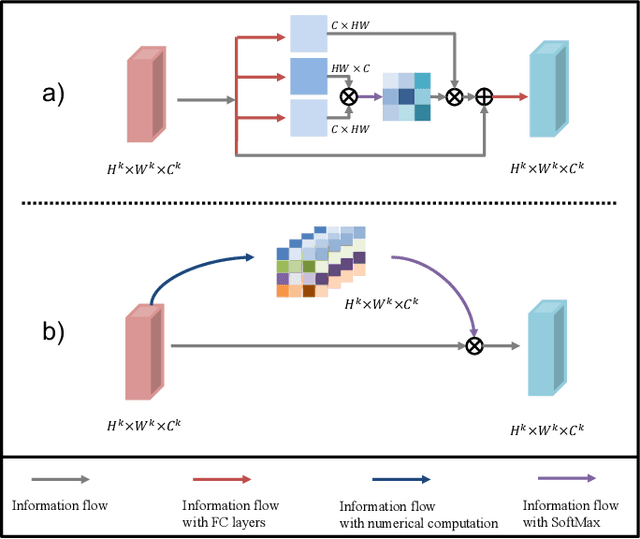
In minimally-invasive brain surgeries with indirect and narrow operating environments, 3D brain reconstruction is crucial. However, as requirements of accuracy for some new minimally-invasive surgeries (such as brain-computer interface surgery) are higher and higher, the outputs of conventional 3D reconstruction, such as point cloud (PC), are facing the challenges that sample points are too sparse and the precision is insufficient. On the other hand, there is a scarcity of high-density point cloud datasets, which makes it challenging to train models for direct reconstruction of high-density brain point clouds. In this work, a novel model named stereoscopic-aware graph generative adversarial network (SG-GAN) with two stages is proposed to generate fine high-density PC conditioned on a single image. The Stage-I GAN sketches the primitive shape and basic structure of the organ based on the given image, yielding Stage-I point clouds. The Stage-II GAN takes the results from Stage-I and generates high-density point clouds with detailed features. The Stage-II GAN is capable of correcting defects and restoring the detailed features of the region of interest (ROI) through the up-sampling process. Furthermore, a parameter-free-attention-based free-transforming module is developed to learn the efficient features of input, while upholding a promising performance. Comparing with the existing methods, the SG-GAN model shows superior performance in terms of visual quality, objective measurements, and performance in classification, as demonstrated by comprehensive results measured by several evaluation metrics including PC-to-PC error and Chamfer distance.
SCAN: Semantic Communication with Adaptive Channel Feedback
Jun 27, 2023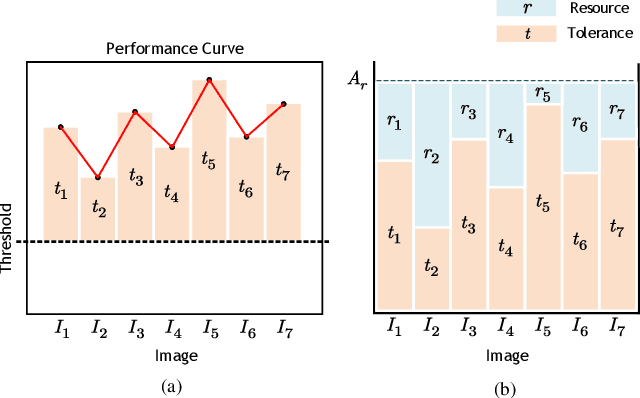
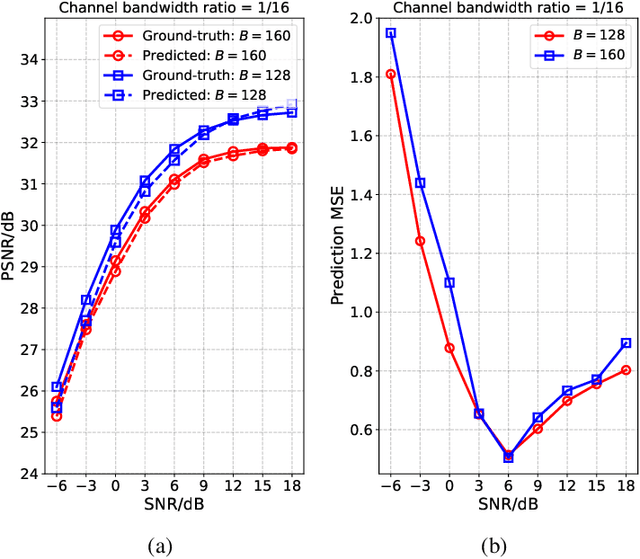
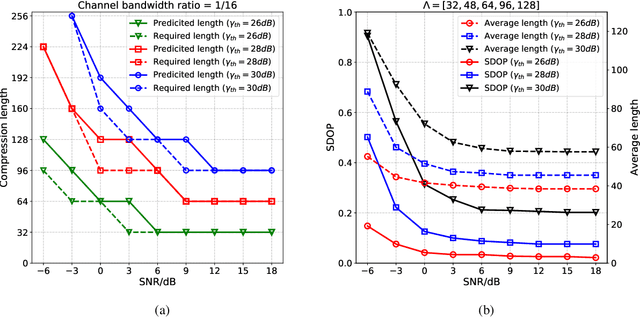
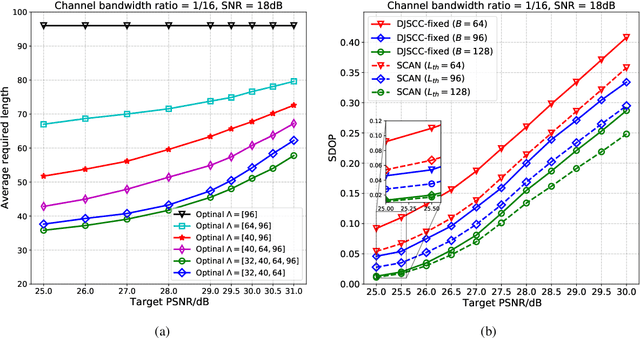
In existing semantic communication systems for image transmission, some images are generally reconstructed with considerably low quality. As a result, the reliable transmission of each image cannot be guaranteed, bringing significant uncertainty to semantic communication systems. To address this issue, we propose a novel performance metric to characterize the reliability of semantic communication systems termed semantic distortion outage probability (SDOP), which is defined as the probability of the instantaneous distortion larger than a given target threshold. Then, since the images with lower reconstruction quality are generally less robust and need to be allocated with more communication resources, we propose a novel framework of Semantic Communication with Adaptive chaNnel feedback (SCAN). It can reduce SDOP by adaptively adjusting the overhead of channel feedback for images with different reconstruction qualities, thereby enhancing transmission reliability. To realize SCAN, we first develop a deep learning-enabled semantic communication system for multiple-input multiple-output (MIMO) channels (DeepSC-MIMO) by leveraging the channel state information (CSI) and noise variance in the model design. We then develop a performance evaluator to predict the reconstruction quality of each image at the transmitter by distilling knowledge from DeepSC-MIMO. In this way, images with lower predicted reconstruction quality will be allocated with a longer CSI codeword to guarantee the reconstruction quality. We perform extensive experiments to demonstrate that the proposed scheme can significantly improve the reliability of image transmission while greatly reducing the feedback overhead.
Disentangled Pre-training for Image Matting
Apr 03, 2023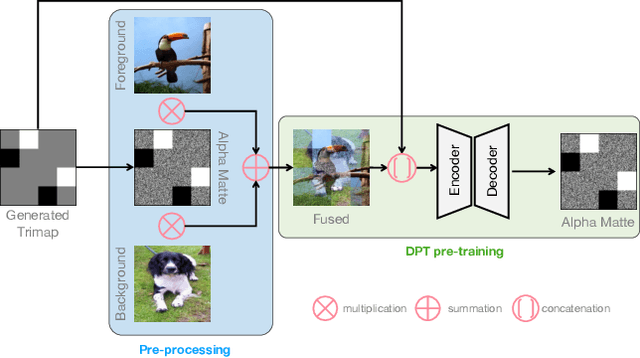
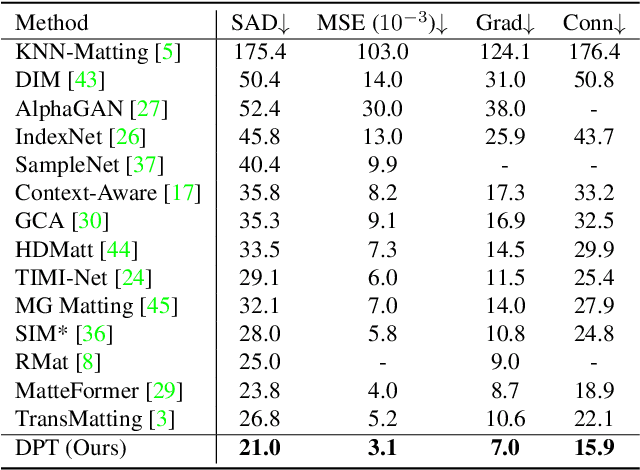

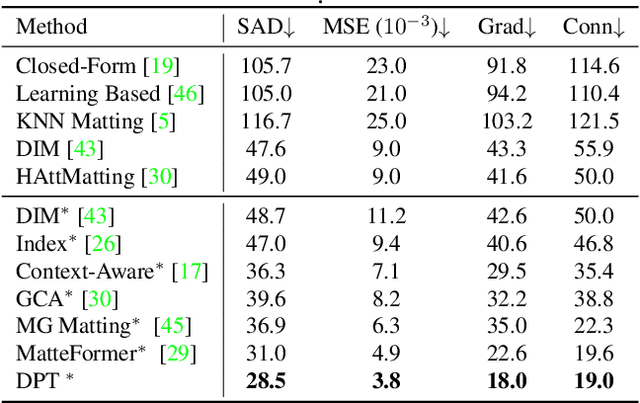
Image matting requires high-quality pixel-level human annotations to support the training of a deep model in recent literature. Whereas such annotation is costly and hard to scale, significantly holding back the development of the research. In this work, we make the first attempt towards addressing this problem, by proposing a self-supervised pre-training approach that can leverage infinite numbers of data to boost the matting performance. The pre-training task is designed in a similar manner as image matting, where random trimap and alpha matte are generated to achieve an image disentanglement objective. The pre-trained model is then used as an initialisation of the downstream matting task for fine-tuning. Extensive experimental evaluations show that the proposed approach outperforms both the state-of-the-art matting methods and other alternative self-supervised initialisation approaches by a large margin. We also show the robustness of the proposed approach over different backbone architectures. The code and models will be publicly available.