 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovEvolve: Ask AlphaEvolve to Improve the Input Solution and Then Improvise
Feb 10, 2026Recent advances in LLM-guided evolutionary computation, particularly AlphaEvolve, have demonstrated remarkable success in discovering novel mathematical constructions and solving challenging optimization problems. In this article, we present ImprovEvolve, a simple yet effective technique for enhancing LLM-based evolutionary approaches such as AlphaEvolve. Given an optimization problem, the standard approach is to evolve program code that, when executed, produces a solution close to the optimum. We propose an alternative program parameterization that maintains the ability to construct optimal solutions while reducing the cognitive load on the LLM. Specifically, we evolve a program (implementing, e.g., a Python class with a prescribed interface) that provides the following functionality: (1) propose a valid initial solution, (2) improve any given solution in terms of fitness, and (3) perturb a solution with a specified intensity. The optimum can then be approached by iteratively applying improve() and perturb() with a scheduled intensity. We evaluate ImprovEvolve on challenging problems from the AlphaEvolve paper: hexagon packing in a hexagon and the second autocorrelation inequality. For hexagon packing, the evolved program achieves new state-of-the-art results for 11, 12, 15, and 16 hexagons; a lightly human-edited variant further improves results for 14, 17, and 23 hexagons. For the second autocorrelation inequality, the human-edited program achieves a new state-of-the-art lower bound of 0.96258, improving upon AlphaEvolve's 0.96102.
CoMa: Contextual Massing Generation with Vision-Language Models
Jan 13, 2026The conceptual design phase in architecture and urban planning, particularly building massing, is complex and heavily reliant on designer intuition and manual effort. To address this, we propose an automated framework for generating building massing based on functional requirements and site context. A primary obstacle to such data-driven methods has been the lack of suitable datasets. Consequently, we introduce the CoMa-20K dataset, a comprehensive collection that includes detailed massing geometries, associated economical and programmatic data, and visual representations of the development site within its existing urban context. We benchmark this dataset by formulating massing generation as a conditional task for Vision-Language Models (VLMs), evaluating both fine-tuned and large zero-shot models. Our experiments reveal the inherent complexity of the task while demonstrating the potential of VLMs to produce context-sensitive massing options. The dataset and analysis establish a foundational benchmark and highlight significant opportunities for future research in data-driven architectural design.
Multi-Agent GraphRAG: A Text-to-Cypher Framework for Labeled Property Graphs
Nov 11, 2025While Retrieval-Augmented Generation (RAG) methods commonly draw information from unstructured documents, the emerging paradigm of GraphRAG aims to leverage structured data such as knowledge graphs. Most existing GraphRAG efforts focus on Resource Description Framework (RDF) knowledge graphs, relying on triple representations and SPARQL queries. However, the potential of Cypher and Labeled Property Graph (LPG) databases to serve as scalable and effective reasoning engines within GraphRAG pipelines remains underexplored in current research literature. To fill this gap, we propose Multi-Agent GraphRAG, a modular LLM agentic system for text-to-Cypher query generation serving as a natural language interface to LPG-based graph data. Our proof-of-concept system features an LLM-based workflow for automated Cypher queries generation and execution, using Memgraph as the graph database backend. Iterative content-aware correction and normalization, reinforced by an aggregated feedback loop, ensures both semantic and syntactic refinement of generated queries. We evaluate our system on the CypherBench graph dataset covering several general domains with diverse types of queries. In addition, we demonstrate performance of the proposed workflow on a property graph derived from the IFC (Industry Foundation Classes) data, representing a digital twin of a building. This highlights how such an approach can bridge AI with real-world applications at scale, enabling industrial digital automation use cases.
Switti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Dec 03, 2024



This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
YaART: Yet Another ART Rendering Technology
Apr 08, 2024



In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Apr 10, 2023



Recent advances in diffusion models enable many powerful instruments for image editing. One of these instruments is text-driven image manipulations: editing semantic attributes of an image according to the provided text description. % Popular text-conditional diffusion models offer various high-quality image manipulation methods for a broad range of text prompts. Existing diffusion-based methods already achieve high-quality image manipulations for a broad range of text prompts. However, in practice, these methods require high computation costs even with a high-end GPU. This greatly limits potential real-world applications of diffusion-based image editing, especially when running on user devices. In this paper, we address efficiency of the recent text-driven editing methods based on unconditional diffusion models and develop a novel algorithm that learns image manipulations 4.5-10 times faster and applies them 8 times faster. We carefully evaluate the visual quality and expressiveness of our approach on multiple datasets using human annotators. Our experiments demonstrate that our algorithm achieves the quality of much more expensive methods. Finally, we show that our approach can adapt the pretrained model to the user-specified image and text description on the fly just for 4 seconds. In this setting, we notice that more compact unconditional diffusion models can be considered as a rational alternative to the popular text-conditional counterparts.
Hyperbolic Vision Transformers: Combining Improvements in Metric Learning
Mar 22, 2022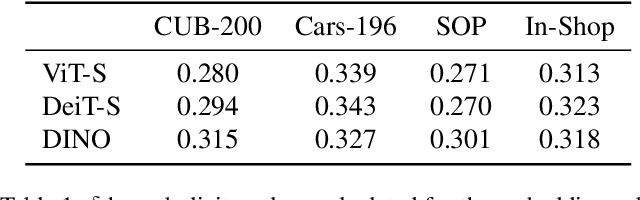

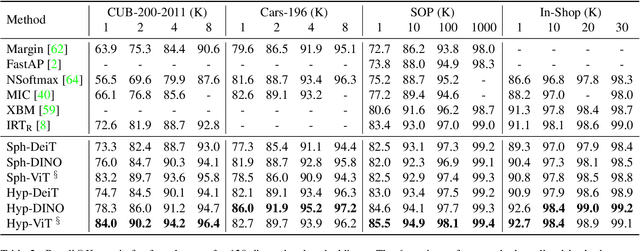
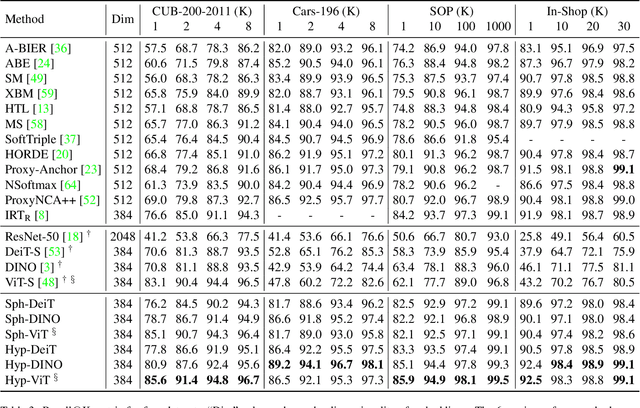
Metric learning aims to learn a highly discriminative model encouraging the embeddings of similar classes to be close in the chosen metrics and pushed apart for dissimilar ones. The common recipe is to use an encoder to extract embeddings and a distance-based loss function to match the representations -- usually, the Euclidean distance is utilized. An emerging interest in learning hyperbolic data embeddings suggests that hyperbolic geometry can be beneficial for natural data. Following this line of work, we propose a new hyperbolic-based model for metric learning. At the core of our method is a vision transformer with output embeddings mapped to hyperbolic space. These embeddings are directly optimized using modified pairwise cross-entropy loss. We evaluate the proposed model with six different formulations on four datasets achieving the new state-of-the-art performance. The source code is available at https://github.com/htdt/hyp_metric.
Understanding DDPM Latent Codes Through Optimal Transport
Feb 14, 2022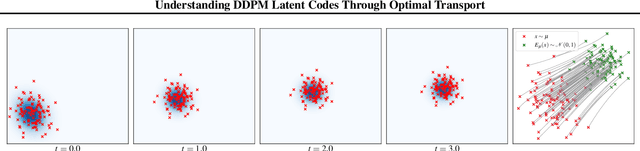
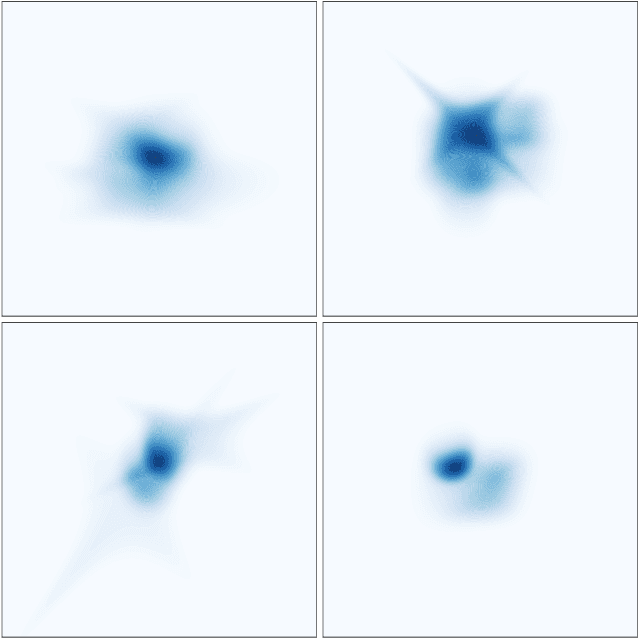
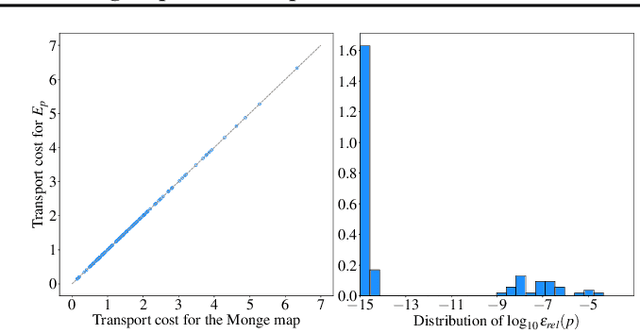
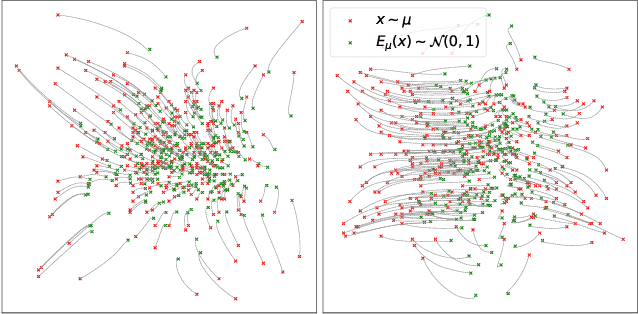
Diffusion models have recently outperformed alternative approaches to model the distribution of natural images, such as GANs. Such diffusion models allow for deterministic sampling via the probability flow ODE, giving rise to a latent space and an encoder map. While having important practical applications, such as estimation of the likelihood, the theoretical properties of this map are not yet fully understood. In the present work, we partially address this question for the popular case of the VP SDE (DDPM) approach. We show that, perhaps surprisingly, the DDPM encoder map coincides with the optimal transport map for common distributions; we support this claim theoretically and by extensive numerical experiments.
Label-Efficient Semantic Segmentation with Diffusion Models
Dec 27, 2021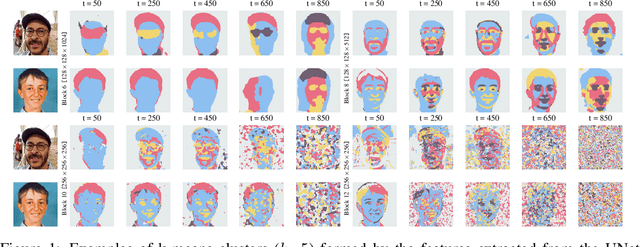
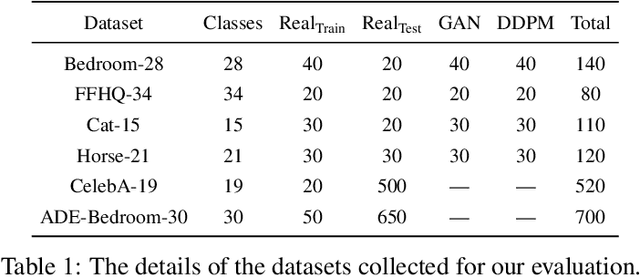
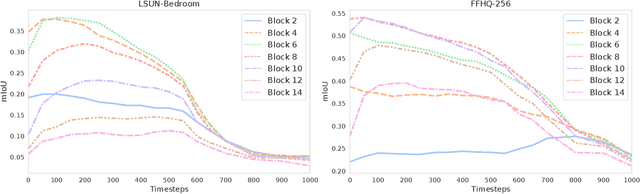
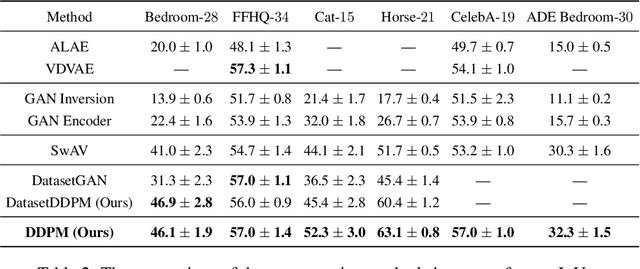
Denoising diffusion probabilistic models have recently received much research attention since they outperform alternative approaches, such as GANs, and currently provide state-of-the-art generative performance. The superior performance of diffusion models has made them an appealing tool in several applications, including inpainting, super-resolution, and semantic editing. In this paper, we demonstrate that diffusion models can also serve as an instrument for semantic segmentation, especially in the setup when labeled data is scarce. In particular, for several pretrained diffusion models, we investigate the intermediate activations from the networks that perform the Markov step of the reverse diffusion process. We show that these activations effectively capture the semantic information from an input image and appear to be excellent pixel-level representations for the segmentation problem. Based on these observations, we describe a simple segmentation method, which can work even if only a few training images are provided. Our approach significantly outperforms the existing alternatives on several datasets for the same amount of human supervision.
Latent Transformations via NeuralODEs for GAN-based Image Editing
Nov 29, 2021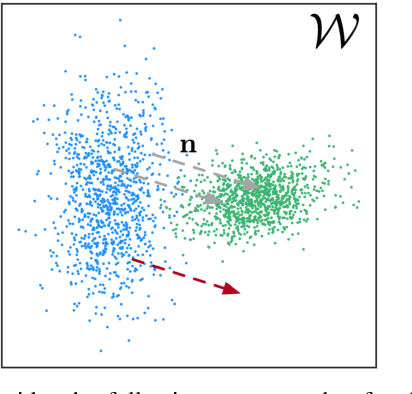

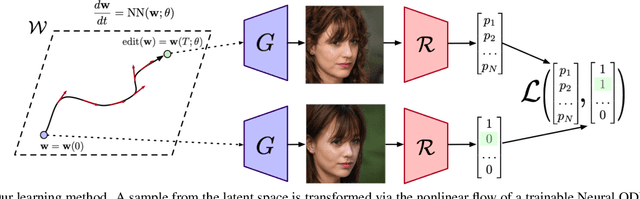
Recent advances in high-fidelity semantic image editing heavily rely on the presumably disentangled latent spaces of the state-of-the-art generative models, such as StyleGAN. Specifically, recent works show that it is possible to achieve decent controllability of attributes in face images via linear shifts along with latent directions. Several recent methods address the discovery of such directions, implicitly assuming that the state-of-the-art GANs learn the latent spaces with inherently linearly separable attribute distributions and semantic vector arithmetic properties. In our work, we show that nonlinear latent code manipulations realized as flows of a trainable Neural ODE are beneficial for many practical non-face image domains with more complex non-textured factors of variation. In particular, we investigate a large number of datasets with known attributes and demonstrate that certain attribute manipulations are challenging to obtain with linear shifts only.