 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReAge3D: Re-Aging 3D Faces with View Consistency
Jun 16, 2026We present a novel framework for realistic and controllable 3D face re-aging which produces highly detailed, identity-preserving results. Existing 3D editing methods, while effective for coarse semantic changes, are not well suited for re-aging, as even small inconsistencies across re-aged 2D views can lead to over-smoothing of subtle but perceptually important age-related details. To address this challenge, we first introduce a 2D diffusion-based re-aging model, DiffReaging, trained on synthetically generated image pairs. We further propose a center-out editing propagation strategy that leverages this re-aging model to reconstruct multi-view-consistent re-aged images. Specifically, starting from a re-aged frontal pivot view, we reconstruct the remaining views through warping and our proposed Masked-DiffReaging process. By injecting existing content at every step of the diffusion process, Masked-DiffReaging ensures that the reconstructed regions remain coherent with existing pixels. The resulting consistent set of re-aged views supervises the optimization of the re-aged 3D representation. Our method outperforms existing 3D editing techniques both visually and quantitatively, enabling smooth, fine-grained control over age transformations in 3D face models.
Analyzing and Improving the Skin Tone Consistency and Bias in Implicit 3D Relightable Face Generators
Nov 18, 2024With the advances in generative adversarial networks (GANs) and neural rendering, 3D relightable face generation has received significant attention. Among the existing methods, a particularly successful technique uses an implicit lighting representation and generates relit images through the product of synthesized albedo and light-dependent shading images. While this approach produces high-quality results with intricate shading details, it often has difficulty producing relit images with consistent skin tones, particularly when the lighting condition is extracted from images of individuals with dark skin. Additionally, this technique is biased towards producing albedo images with lighter skin tones. Our main observation is that this problem is rooted in the biased spherical harmonics (SH) coefficients, used during training. Following this observation, we conduct an analysis and demonstrate that the bias appears not only in band 0 (DC term), but also in the other bands of the estimated SH coefficients. We then propose a simple, but effective, strategy to mitigate the problem. Specifically, we normalize the SH coefficients by their DC term to eliminate the inherent magnitude bias, while statistically align the coefficients in the other bands to alleviate the directional bias. We also propose a scaling strategy to match the distribution of illumination magnitude in the generated images with the training data. Through extensive experiments, we demonstrate the effectiveness of our solution in increasing the skin tone consistency and mitigating bias.
Uncertainty-aware State Space Transformer for Egocentric 3D Hand Trajectory Forecasting
Jul 17, 2023



Hand trajectory forecasting from egocentric views is crucial for enabling a prompt understanding of human intentions when interacting with AR/VR systems. However, existing methods handle this problem in a 2D image space which is inadequate for 3D real-world applications. In this paper, we set up an egocentric 3D hand trajectory forecasting task that aims to predict hand trajectories in a 3D space from early observed RGB videos in a first-person view. To fulfill this goal, we propose an uncertainty-aware state space Transformer (USST) that takes the merits of the attention mechanism and aleatoric uncertainty within the framework of the classical state-space model. The model can be further enhanced by the velocity constraint and visual prompt tuning (VPT) on large vision transformers. Moreover, we develop an annotation workflow to collect 3D hand trajectories with high quality. Experimental results on H2O and EgoPAT3D datasets demonstrate the superiority of USST for both 2D and 3D trajectory forecasting. The code and datasets are publicly released: https://github.com/Cogito2012/USST.
MyStyle++: A Controllable Personalized Generative Prior
Jun 09, 2023



In this paper, we propose an approach to obtain a personalized generative prior with explicit control over a set of attributes. We build upon MyStyle, a recently introduced method, that tunes the weights of a pre-trained StyleGAN face generator on a few images of an individual. This system allows synthesizing, editing, and enhancing images of the target individual with high fidelity to their facial features. However, MyStyle does not demonstrate precise control over the attributes of the generated images. We propose to address this problem through a novel optimization system that organizes the latent space in addition to tuning the generator. Our key contribution is to formulate a loss that arranges the latent codes, corresponding to the input images, along a set of specific directions according to their attributes. We demonstrate that our approach, dubbed MyStyle++, is able to synthesize, edit, and enhance images of an individual with great control over the attributes, while preserving the unique facial characteristics of that individual.
Multi-Stage Raw Video Denoising with Adversarial Loss and Gradient Mask
Mar 05, 2021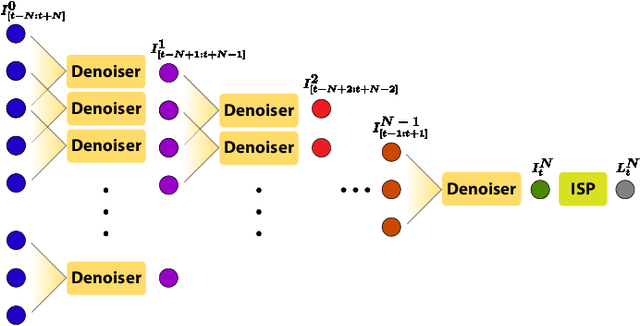
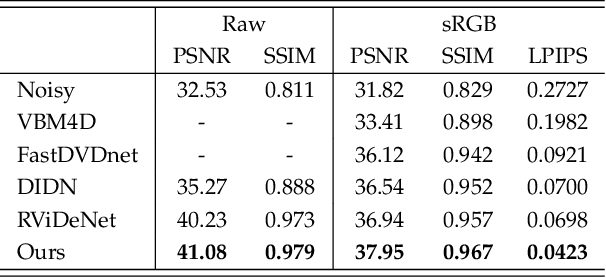

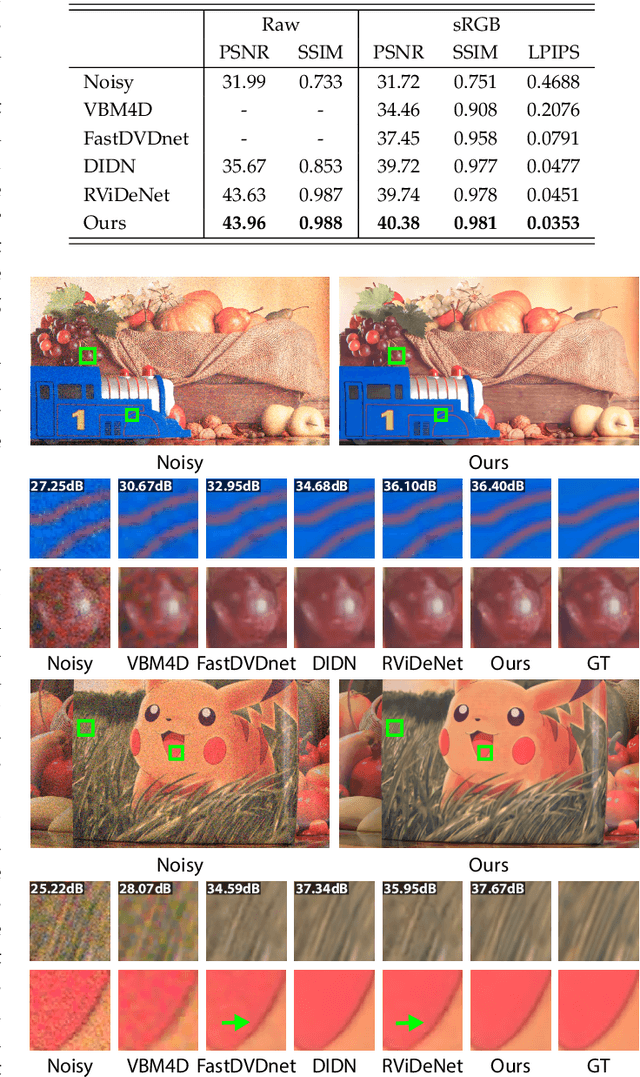
In this paper, we propose a learning-based approach for denoising raw videos captured under low lighting conditions. We propose to do this by first explicitly aligning the neighboring frames to the current frame using a convolutional neural network (CNN). We then fuse the registered frames using another CNN to obtain the final denoised frame. To avoid directly aligning the temporally distant frames, we perform the two processes of alignment and fusion in multiple stages. Specifically, at each stage, we perform the denoising process on three consecutive input frames to generate the intermediate denoised frames which are then passed as the input to the next stage. By performing the process in multiple stages, we can effectively utilize the information of neighboring frames without directly aligning the temporally distant frames. We train our multi-stage system using an adversarial loss with a conditional discriminator. Specifically, we condition the discriminator on a soft gradient mask to prevent introducing high-frequency artifacts in smooth regions. We show that our system is able to produce temporally coherent videos with realistic details. Furthermore, we demonstrate through extensive experiments that our approach outperforms state-of-the-art image and video denoising methods both numerically and visually.