 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Medical Image Deidentification, Cleaning and Compression Using Pylogik
May 03, 2023
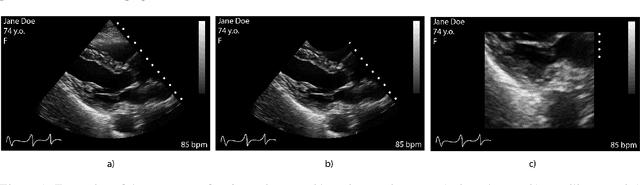

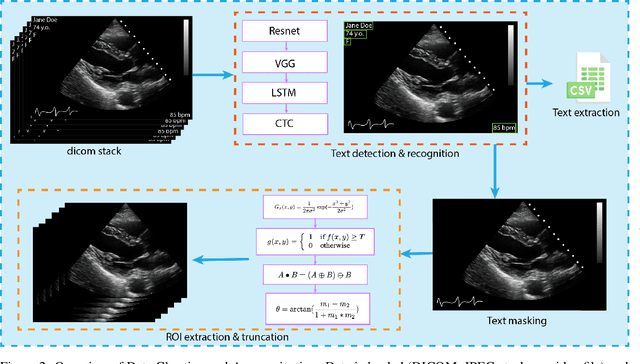
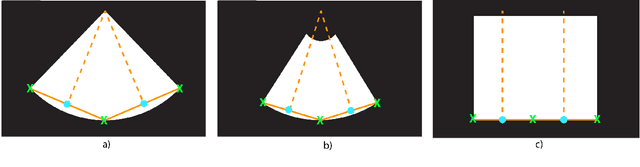
Leveraging medical record information in the era of big data and machine learning comes with the caveat that data must be cleaned and deidentified. Facilitating data sharing and harmonization for multi-center collaborations are particularly difficult when protected health information (PHI) is contained or embedded in image meta-data. We propose a novel library in the Python framework, called PyLogik, to help alleviate this issue for ultrasound images, which are particularly challenging because of the frequent inclusion of PHI directly on the images. PyLogik processes the image volumes through a series of text detection/extraction, filtering, thresholding, morphological and contour comparisons. This methodology deidentifies the images, reduces file sizes, and prepares image volumes for applications in deep learning and data sharing. To evaluate its effectiveness in the identification of regions of interest (ROI), a random sample of 50 cardiac ultrasounds (echocardiograms) were processed through PyLogik, and the outputs were compared with the manual segmentations by an expert user. The Dice coefficient of the two approaches achieved an average value of 0.976. Next, an investigation was conducted to ascertain the degree of information compression achieved using the algorithm. Resultant data was found to be on average approximately 72% smaller after processing by PyLogik. Our results suggest that PyLogik is a viable methodology for ultrasound data cleaning and deidentification, determining ROI, and file compression which will facilitate efficient storage, use, and dissemination of ultrasound data.
COCO-O: A Benchmark for Object Detectors under Natural Distribution Shifts
Aug 02, 2023Practical object detection application can lose its effectiveness on image inputs with natural distribution shifts. This problem leads the research community to pay more attention on the robustness of detectors under Out-Of-Distribution (OOD) inputs. Existing works construct datasets to benchmark the detector's OOD robustness for a specific application scenario, e.g., Autonomous Driving. However, these datasets lack universality and are hard to benchmark general detectors built on common tasks such as COCO. To give a more comprehensive robustness assessment, we introduce COCO-O(ut-of-distribution), a test dataset based on COCO with 6 types of natural distribution shifts. COCO-O has a large distribution gap with training data and results in a significant 55.7% relative performance drop on a Faster R-CNN detector. We leverage COCO-O to conduct experiments on more than 100 modern object detectors to investigate if their improvements are credible or just over-fitting to the COCO test set. Unfortunately, most classic detectors in early years do not exhibit strong OOD generalization. We further study the robustness effect on recent breakthroughs of detector's architecture design, augmentation and pre-training techniques. Some empirical findings are revealed: 1) Compared with detection head or neck, backbone is the most important part for robustness; 2) An end-to-end detection transformer design brings no enhancement, and may even reduce robustness; 3) Large-scale foundation models have made a great leap on robust object detection. We hope our COCO-O could provide a rich testbed for robustness study of object detection. The dataset will be available at https://github.com/alibaba/easyrobust/tree/main/benchmarks/coco_o.
DQ-Det: Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 23, 2023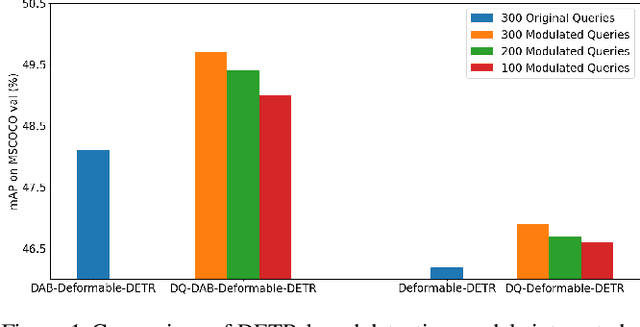

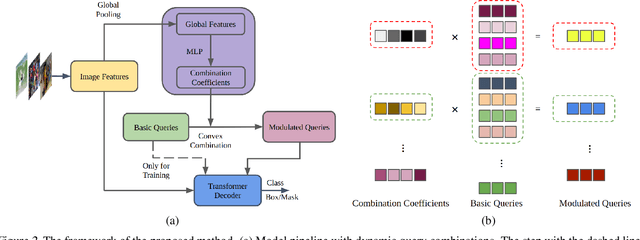
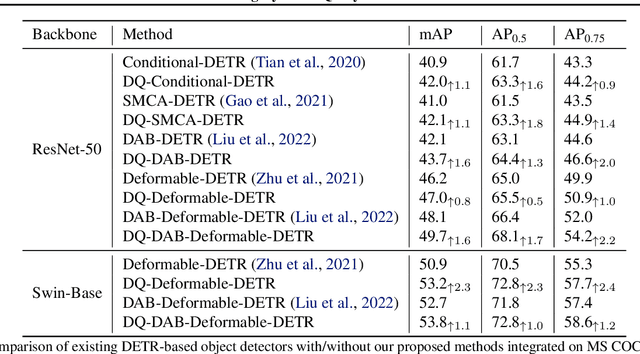
Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
Scene Graph as Pivoting: Inference-time Image-free Unsupervised Multimodal Machine Translation with Visual Scene Hallucination
May 25, 2023
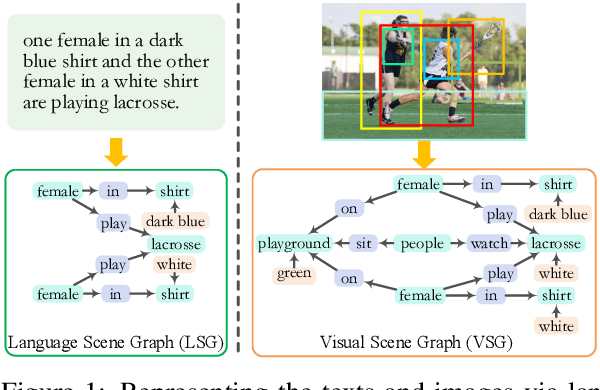
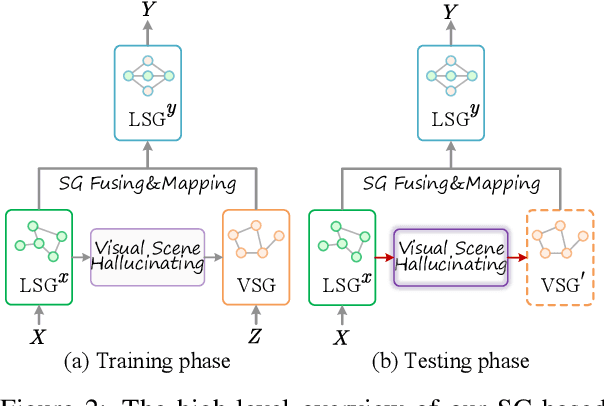
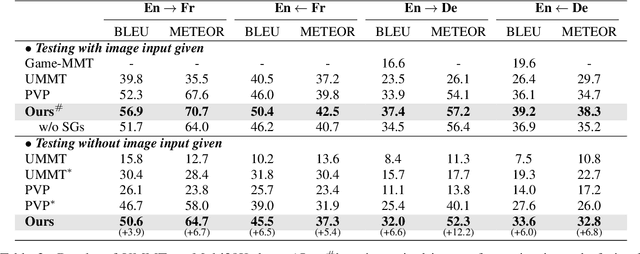
In this work, we investigate a more realistic unsupervised multimodal machine translation (UMMT) setup, inference-time image-free UMMT, where the model is trained with source-text image pairs, and tested with only source-text inputs. First, we represent the input images and texts with the visual and language scene graphs (SG), where such fine-grained vision-language features ensure a holistic understanding of the semantics. To enable pure-text input during inference, we devise a visual scene hallucination mechanism that dynamically generates pseudo visual SG from the given textual SG. Several SG-pivoting based learning objectives are introduced for unsupervised translation training. On the benchmark Multi30K data, our SG-based method outperforms the best-performing baseline by significant BLEU scores on the task and setup, helping yield translations with better completeness, relevance and fluency without relying on paired images. Further in-depth analyses reveal how our model advances in the task setting.
Localized Questions in Medical Visual Question Answering
Jul 03, 2023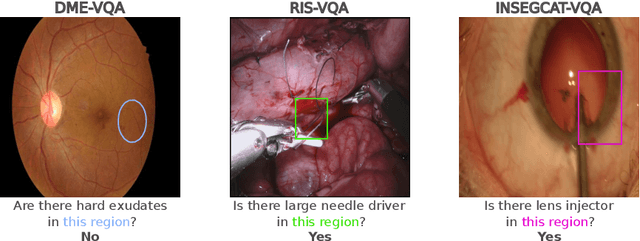
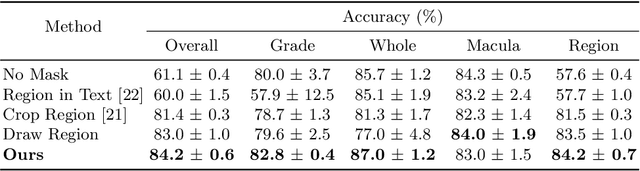
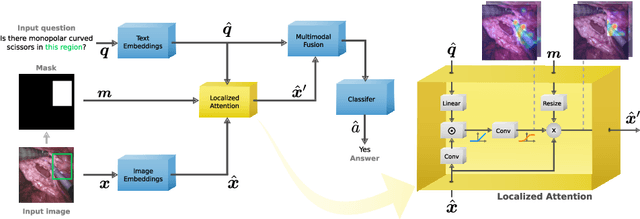
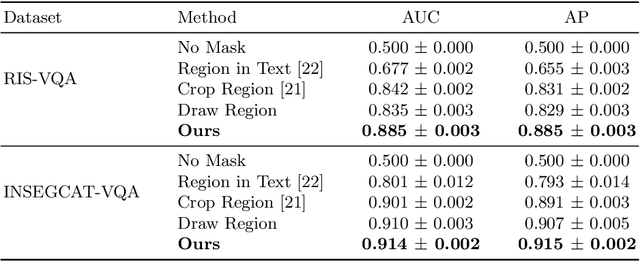
Visual Question Answering (VQA) models aim to answer natural language questions about given images. Due to its ability to ask questions that differ from those used when training the model, medical VQA has received substantial attention in recent years. However, existing medical VQA models typically focus on answering questions that refer to an entire image rather than where the relevant content may be located in the image. Consequently, VQA models are limited in their interpretability power and the possibility to probe the model about specific image regions. This paper proposes a novel approach for medical VQA that addresses this limitation by developing a model that can answer questions about image regions while considering the context necessary to answer the questions. Our experimental results demonstrate the effectiveness of our proposed model, outperforming existing methods on three datasets. Our code and data are available at https://github.com/sergiotasconmorales/locvqa.
Semantic Contrastive Bootstrapping for Single-positive Multi-label Recognition
Jul 15, 2023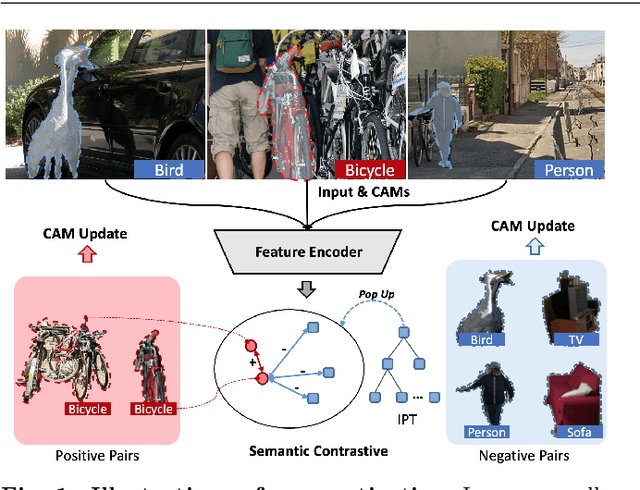
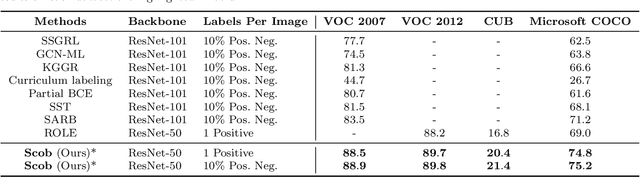
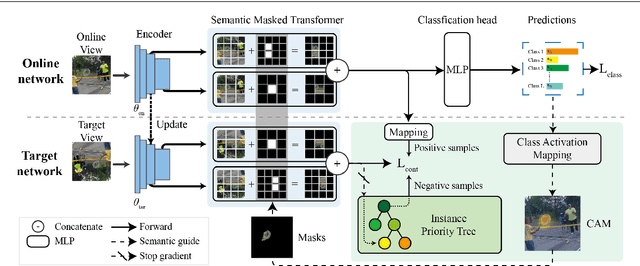
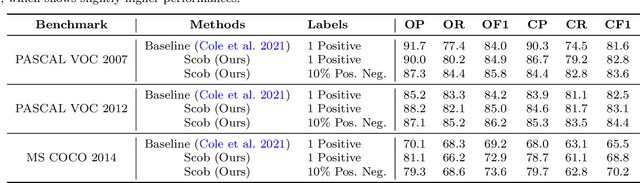
Learning multi-label image recognition with incomplete annotation is gaining popularity due to its superior performance and significant labor savings when compared to training with fully labeled datasets. Existing literature mainly focuses on label completion and co-occurrence learning while facing difficulties with the most common single-positive label manner. To tackle this problem, we present a semantic contrastive bootstrapping (Scob) approach to gradually recover the cross-object relationships by introducing class activation as semantic guidance. With this learning guidance, we then propose a recurrent semantic masked transformer to extract iconic object-level representations and delve into the contrastive learning problems on multi-label classification tasks. We further propose a bootstrapping framework in an Expectation-Maximization fashion that iteratively optimizes the network parameters and refines semantic guidance to alleviate possible disturbance caused by wrong semantic guidance. Extensive experimental results demonstrate that the proposed joint learning framework surpasses the state-of-the-art models by a large margin on four public multi-label image recognition benchmarks. Codes can be found at https://github.com/iCVTEAM/Scob.
OpenAL: An Efficient Deep Active Learning Framework for Open-Set Pathology Image Classification
Jul 11, 2023Active learning (AL) is an effective approach to select the most informative samples to label so as to reduce the annotation cost. Existing AL methods typically work under the closed-set assumption, i.e., all classes existing in the unlabeled sample pool need to be classified by the target model. However, in some practical clinical tasks, the unlabeled pool may contain not only the target classes that need to be fine-grainedly classified, but also non-target classes that are irrelevant to the clinical tasks. Existing AL methods cannot work well in this scenario because they tend to select a large number of non-target samples. In this paper, we formulate this scenario as an open-set AL problem and propose an efficient framework, OpenAL, to address the challenge of querying samples from an unlabeled pool with both target class and non-target class samples. Experiments on fine-grained classification of pathology images show that OpenAL can significantly improve the query quality of target class samples and achieve higher performance than current state-of-the-art AL methods. Code is available at https://github.com/miccaiif/OpenAL.
StyleStegan: Leak-free Style Transfer Based on Feature Steganography
Jul 01, 2023

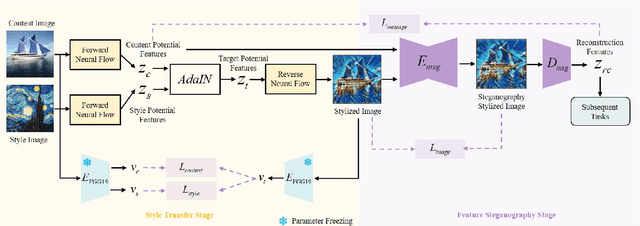
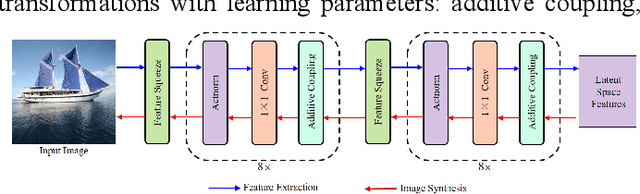
In modern social networks, existing style transfer methods suffer from a serious content leakage issue, which hampers the ability to achieve serial and reversible stylization, thereby hindering the further propagation of stylized images in social networks. To address this problem, we propose a leak-free style transfer method based on feature steganography. Our method consists of two main components: a style transfer method that accomplishes artistic stylization on the original image and an image steganography method that embeds content feature secrets on the stylized image. The main contributions of our work are as follows: 1) We identify and explain the phenomenon of content leakage and its underlying causes, which arise from content inconsistencies between the original image and its subsequent stylized image. 2) We design a neural flow model for achieving loss-free and biased-free style transfer. 3) We introduce steganography to hide content feature information on the stylized image and control the subsequent usage rights. 4) We conduct comprehensive experimental validation using publicly available datasets MS-COCO and Wikiart. The results demonstrate that StyleStegan successfully mitigates the content leakage issue in serial and reversible style transfer tasks. The SSIM performance metrics for these tasks are 14.98% and 7.28% higher, respectively, compared to a suboptimal baseline model.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023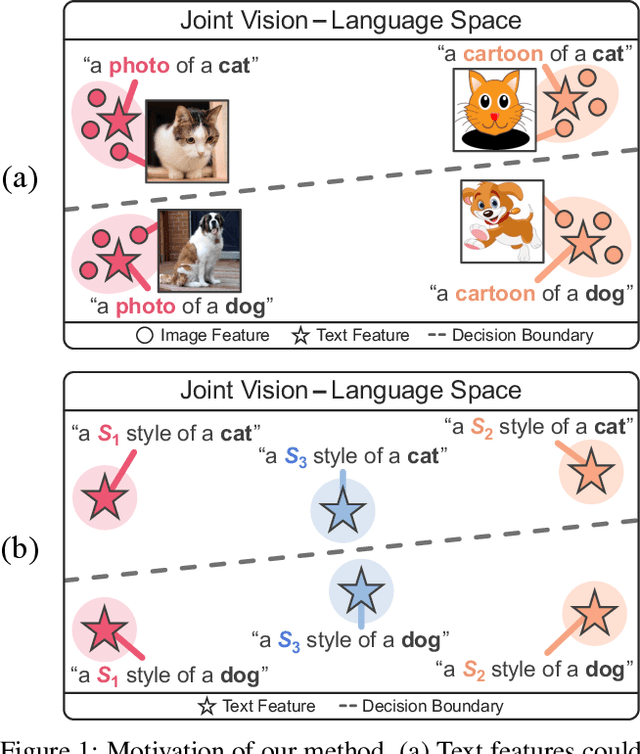
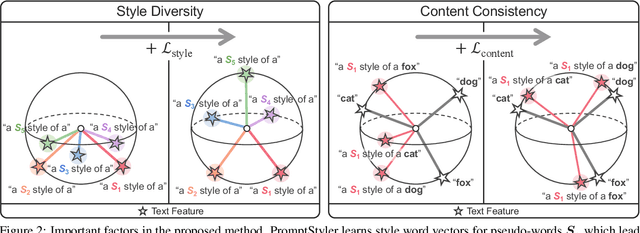
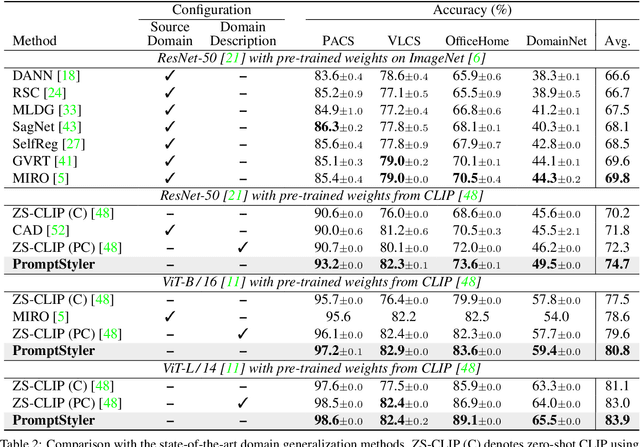
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
Diverse Inpainting and Editing with GAN Inversion
Jul 27, 2023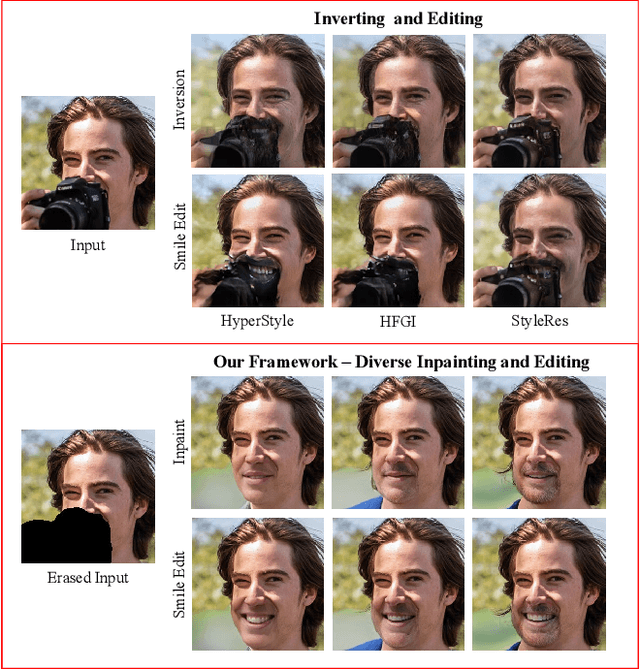
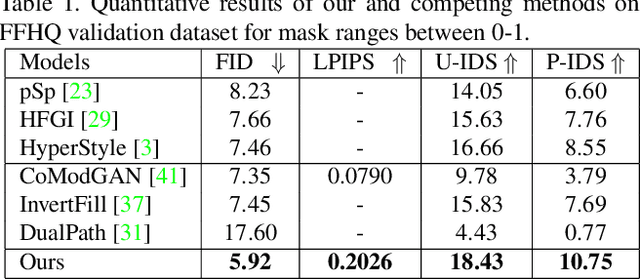
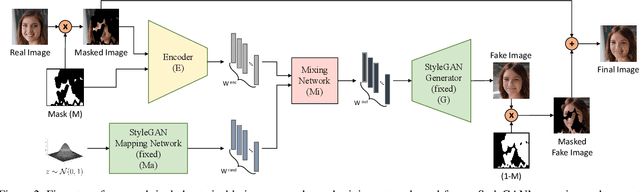
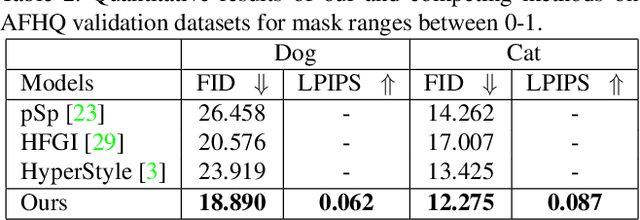
Recent inversion methods have shown that real images can be inverted into StyleGAN's latent space and numerous edits can be achieved on those images thanks to the semantically rich feature representations of well-trained GAN models. However, extensive research has also shown that image inversion is challenging due to the trade-off between high-fidelity reconstruction and editability. In this paper, we tackle an even more difficult task, inverting erased images into GAN's latent space for realistic inpaintings and editings. Furthermore, by augmenting inverted latent codes with different latent samples, we achieve diverse inpaintings. Specifically, we propose to learn an encoder and mixing network to combine encoded features from erased images with StyleGAN's mapped features from random samples. To encourage the mixing network to utilize both inputs, we train the networks with generated data via a novel set-up. We also utilize higher-rate features to prevent color inconsistencies between the inpainted and unerased parts. We run extensive experiments and compare our method with state-of-the-art inversion and inpainting methods. Qualitative metrics and visual comparisons show significant improvements.