 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Release of Pre-Trained Models for the Japanese Language
Apr 02, 2024
AI democratization aims to create a world in which the average person can utilize AI techniques. To achieve this goal, numerous research institutes have attempted to make their results accessible to the public. In particular, large pre-trained models trained on large-scale data have shown unprecedented potential, and their release has had a significant impact. However, most of the released models specialize in the English language, and thus, AI democratization in non-English-speaking communities is lagging significantly. To reduce this gap in AI access, we released Generative Pre-trained Transformer (GPT), Contrastive Language and Image Pre-training (CLIP), Stable Diffusion, and Hidden-unit Bidirectional Encoder Representations from Transformers (HuBERT) pre-trained in Japanese. By providing these models, users can freely interface with AI that aligns with Japanese cultural values and ensures the identity of Japanese culture, thus enhancing the democratization of AI. Additionally, experiments showed that pre-trained models specialized for Japanese can efficiently achieve high performance in Japanese tasks.
Fashion Style Editing with Generative Human Prior
Apr 02, 2024Image editing has been a long-standing challenge in the research community with its far-reaching impact on numerous applications. Recently, text-driven methods started to deliver promising results in domains like human faces, but their applications to more complex domains have been relatively limited. In this work, we explore the task of fashion style editing, where we aim to manipulate the fashion style of human imagery using text descriptions. Specifically, we leverage a generative human prior and achieve fashion style editing by navigating its learned latent space. We first verify that the existing text-driven editing methods fall short for our problem due to their overly simplified guidance signal, and propose two directions to reinforce the guidance: textual augmentation and visual referencing. Combined with our empirical findings on the latent space structure, our Fashion Style Editing framework (FaSE) successfully projects abstract fashion concepts onto human images and introduces exciting new applications to the field.
Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
Apr 02, 2024Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
A Comprehensive Survey on AI-based Methods for Patents
Apr 02, 2024Recent advancements in Artificial Intelligence (AI) and machine learning have demonstrated transformative capabilities across diverse domains. This progress extends to the field of patent analysis and innovation, where AI-based tools present opportunities to streamline and enhance important tasks in the patent cycle such as classification, retrieval, and valuation prediction. This not only accelerates the efficiency of patent researchers and applicants but also opens new avenues for technological innovation and discovery. Our survey provides a comprehensive summary of recent AI tools in patent analysis from more than 40 papers from 26 venues between 2017 and 2023. Unlike existing surveys, we include methods that work for patent image and text data. Furthermore, we introduce a novel taxonomy for the categorization based on the tasks in the patent life cycle as well as the specifics of the AI methods. This survey aims to serve as a resource for researchers, practitioners, and patent offices in the domain of AI-powered patent analysis.
VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
Mar 16, 2024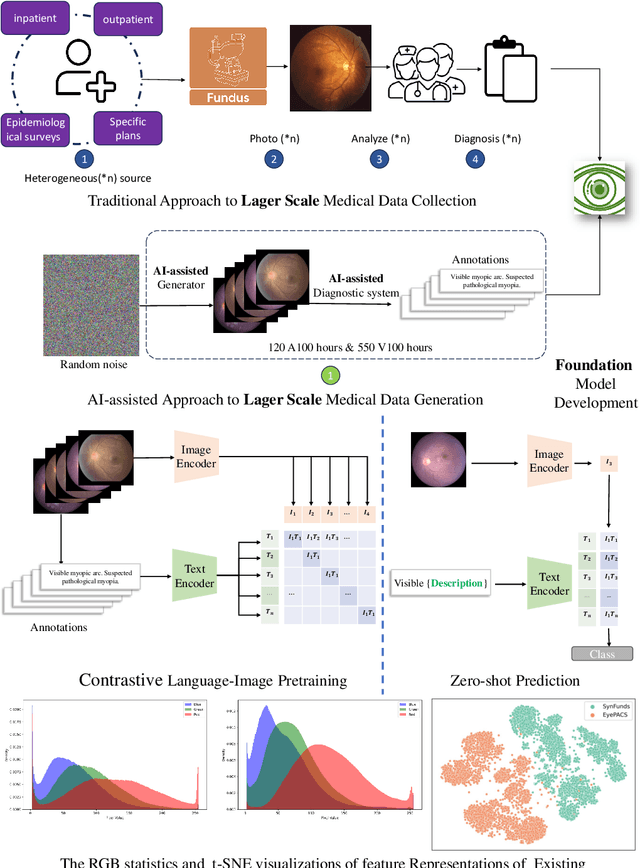
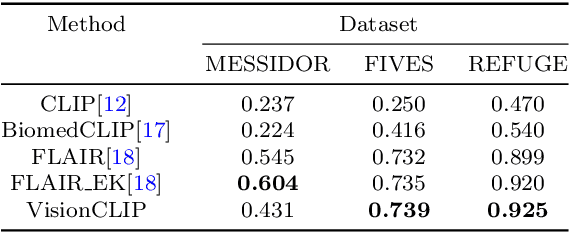
Generalist foundation model has ushered in newfound capabilities in medical domain. However, the contradiction between the growing demand for high-quality annotated data with patient privacy continues to intensify. The utilization of medical artificial intelligence generated content (Med-AIGC) as an inexhaustible resource repository arises as a potential solution to address the aforementioned challenge. Here we harness 1 million open-source synthetic fundus images paired with natural language descriptions, to curate an ethical language-image foundation model for retina image analysis named VisionCLIP. VisionCLIP achieves competitive performance on three external datasets compared with the existing method pre-trained on real-world data in a zero-shot fashion. The employment of artificially synthetic images alongside corresponding textual data for training enables the medical foundation model to successfully assimilate knowledge of disease symptomatology, thereby circumventing potential breaches of patient confidentiality.
Segment Anything Model for Road Network Graph Extraction
Mar 31, 2024We propose SAM-Road, an adaptation of the Segment Anything Model (SAM) for extracting large-scale, vectorized road network graphs from satellite imagery. To predict graph geometry, we formulate it as a dense semantic segmentation task, leveraging the inherent strengths of SAM. The image encoder of SAM is fine-tuned to produce probability masks for roads and intersections, from which the graph vertices are extracted via simple non-maximum suppression. To predict graph topology, we designed a lightweight transformer-based graph neural network, which leverages the SAM image embeddings to estimate the edge existence probabilities between vertices. Our approach directly predicts the graph vertices and edges for large regions without expensive and complex post-processing heuristics, and is capable of building complete road network graphs spanning multiple square kilometers in a matter of seconds. With its simple, straightforward, and minimalist design, SAM-Road achieves comparable accuracy with the state-of-the-art method RNGDet++, while being 40 times faster on the City-scale dataset. We thus demonstrate the power of a foundational vision model when applied to a graph learning task. The code is available at https://github.com/htcr/sam_road.
Fuzzy Rank-based Late Fusion Technique for Cytology image Segmentation
Mar 16, 2024
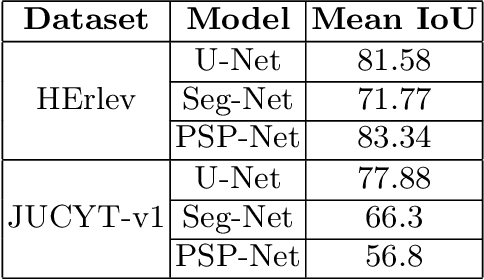
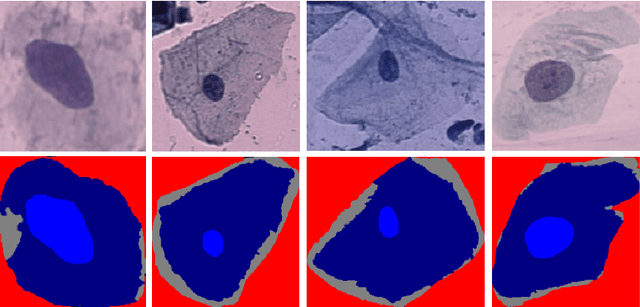
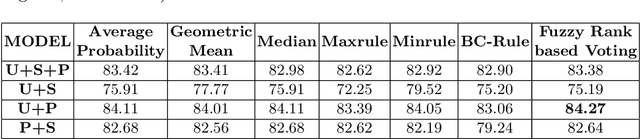
Cytology image segmentation is quite challenging due to its complex cellular structure and multiple overlapping regions. On the other hand, for supervised machine learning techniques, we need a large amount of annotated data, which is costly. In recent years, late fusion techniques have given some promising performances in the field of image classification. In this paper, we have explored a fuzzy-based late fusion techniques for cytology image segmentation. This fusion rule integrates three traditional semantic segmentation models UNet, SegNet, and PSPNet. The technique is applied on two cytology image datasets, i.e., cervical cytology(HErlev) and breast cytology(JUCYT-v1) image datasets. We have achieved maximum MeanIoU score 84.27% and 83.79% on the HErlev dataset and JUCYT-v1 dataset after the proposed late fusion technique, respectively which are better than that of the traditional fusion rules such as average probability, geometric mean, Borda Count, etc. The codes of the proposed model are available on GitHub.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024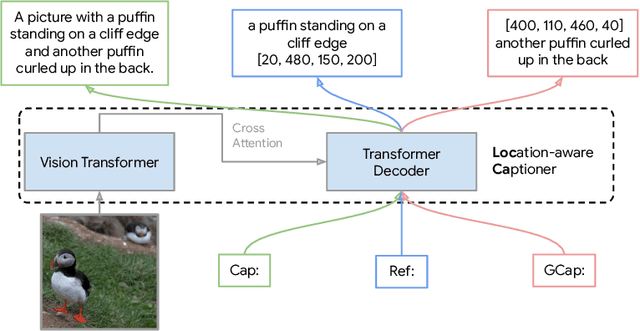
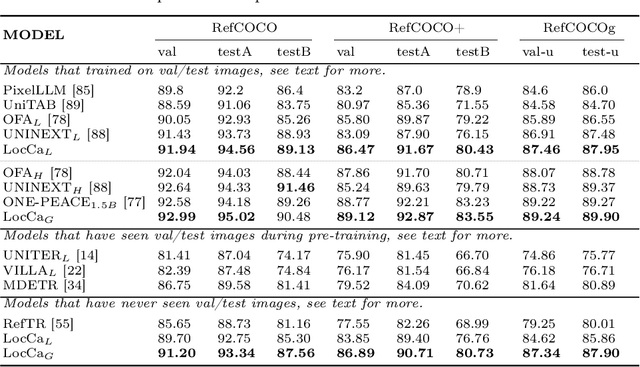
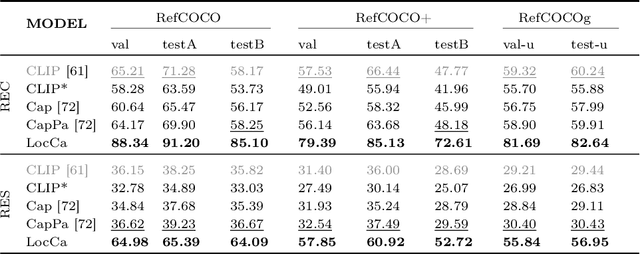
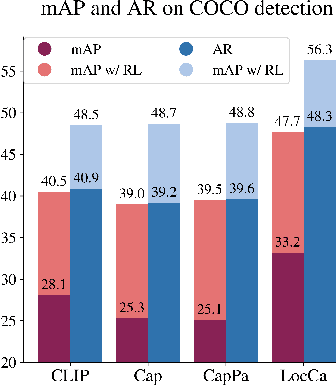
Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
Bidirectional Consistency Models
Mar 30, 2024Diffusion models (DMs) are capable of generating remarkably high-quality samples by iteratively denoising a random vector, a process that corresponds to moving along the probability flow ordinary differential equation (PF ODE). Interestingly, DMs can also invert an input image to noise by moving backward along the PF ODE, a key operation for downstream tasks such as interpolation and image editing. However, the iterative nature of this process restricts its speed, hindering its broader application. Recently, Consistency Models (CMs) have emerged to address this challenge by approximating the integral of the PF ODE, largely reducing the number of iterations. Yet, the absence of an explicit ODE solver complicates the inversion process. To resolve this, we introduce the Bidirectional Consistency Model (BCM), which learns a single neural network that enables both forward and backward traversal along the PF ODE, efficiently unifying generation and inversion tasks within one framework. Notably, our proposed method enables one-step generation and inversion while also allowing the use of additional steps to enhance generation quality or reduce reconstruction error. Furthermore, by leveraging our model's bidirectional consistency, we introduce a sampling strategy that can enhance FID while preserving the generated image content. We further showcase our model's capabilities in several downstream tasks, such as interpolation and inpainting, and present demonstrations of potential applications, including blind restoration of compressed images and defending black-box adversarial attacks.
Towards 3D Vision with Low-Cost Single-Photon Cameras
Mar 29, 2024We present a method for reconstructing 3D shape of arbitrary Lambertian objects based on measurements by miniature, energy-efficient, low-cost single-photon cameras. These cameras, operating as time resolved image sensors, illuminate the scene with a very fast pulse of diffuse light and record the shape of that pulse as it returns back from the scene at a high temporal resolution. We propose to model this image formation process, account for its non-idealities, and adapt neural rendering to reconstruct 3D geometry from a set of spatially distributed sensors with known poses. We show that our approach can successfully recover complex 3D shapes from simulated data. We further demonstrate 3D object reconstruction from real-world captures, utilizing measurements from a commodity proximity sensor. Our work draws a connection between image-based modeling and active range scanning and is a step towards 3D vision with single-photon cameras.