 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
Mar 16, 2024Generalist foundation model has ushered in newfound capabilities in medical domain. However, the contradiction between the growing demand for high-quality annotated data with patient privacy continues to intensify. The utilization of medical artificial intelligence generated content (Med-AIGC) as an inexhaustible resource repository arises as a potential solution to address the aforementioned challenge. Here we harness 1 million open-source synthetic fundus images paired with natural language descriptions, to curate an ethical language-image foundation model for retina image analysis named VisionCLIP. VisionCLIP achieves competitive performance on three external datasets compared with the existing method pre-trained on real-world data in a zero-shot fashion. The employment of artificially synthetic images alongside corresponding textual data for training enables the medical foundation model to successfully assimilate knowledge of disease symptomatology, thereby circumventing potential breaches of patient confidentiality.
Leveraging Multimodal Fusion for Enhanced Diagnosis of Multiple Retinal Diseases in Ultra-wide OCTA
Nov 17, 2023



Ultra-wide optical coherence tomography angiography (UW-OCTA) is an emerging imaging technique that offers significant advantages over traditional OCTA by providing an exceptionally wide scanning range of up to 24 x 20 $mm^{2}$, covering both the anterior and posterior regions of the retina. However, the currently accessible UW-OCTA datasets suffer from limited comprehensive hierarchical information and corresponding disease annotations. To address this limitation, we have curated the pioneering M3OCTA dataset, which is the first multimodal (i.e., multilayer), multi-disease, and widest field-of-view UW-OCTA dataset. Furthermore, the effective utilization of multi-layer ultra-wide ocular vasculature information from UW-OCTA remains underdeveloped. To tackle this challenge, we propose the first cross-modal fusion framework that leverages multi-modal information for diagnosing multiple diseases. Through extensive experiments conducted on our openly available M3OCTA dataset, we demonstrate the effectiveness and superior performance of our method, both in fixed and varying modalities settings. The construction of the M3OCTA dataset, the first multimodal OCTA dataset encompassing multiple diseases, aims to advance research in the ophthalmic image analysis community.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023



We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
CauDR: A Causality-inspired Domain Generalization Framework for Fundus-based Diabetic Retinopathy Grading
Sep 27, 2023Diabetic retinopathy (DR) is the most common diabetic complication, which usually leads to retinal damage, vision loss, and even blindness. A computer-aided DR grading system has a significant impact on helping ophthalmologists with rapid screening and diagnosis. Recent advances in fundus photography have precipitated the development of novel retinal imaging cameras and their subsequent implementation in clinical practice. However, most deep learning-based algorithms for DR grading demonstrate limited generalization across domains. This inferior performance stems from variance in imaging protocols and devices inducing domain shifts. We posit that declining model performance between domains arises from learning spurious correlations in the data. Incorporating do-operations from causality analysis into model architectures may mitigate this issue and improve generalizability. Specifically, a novel universal structural causal model (SCM) was proposed to analyze spurious correlations in fundus imaging. Building on this, a causality-inspired diabetic retinopathy grading framework named CauDR was developed to eliminate spurious correlations and achieve more generalizable DR diagnostics. Furthermore, existing datasets were reorganized into 4DR benchmark for DG scenario. Results demonstrate the effectiveness and the state-of-the-art (SOTA) performance of CauDR.
A One-dimensional HEVC video steganalysis method using the Optimality of Predicted Motion Vectors
Aug 12, 2023Among steganalysis techniques, detection against motion vector (MV) domain-based video steganography in High Efficiency Video Coding (HEVC) standard remains a hot and challenging issue. For the purpose of improving the detection performance, this paper proposes a steganalysis feature based on the optimality of predicted MVs with a dimension of one. Firstly, we point out that the motion vector prediction (MVP) of the prediction unit (PU) encoded using the Advanced Motion Vector Prediction (AMVP) technique satisfies the local optimality in the cover video. Secondly, we analyze that in HEVC video, message embedding either using MVP index or motion vector differences (MVD) may destroy the above optimality of MVP. And then, we define the optimal rate of MVP in HEVC video as a steganalysis feature. Finally, we conduct steganalysis detection experiments on two general datasets for three popular steganography methods and compare the performance with four state-of-the-art steganalysis methods. The experimental results show that the proposed optimal rate of MVP for all cover videos is 100\%, while the optimal rate of MVP for all stego videos is less than 100\%. Therefore, the proposed steganography scheme can accurately distinguish between cover videos and stego videos, and it is efficiently applied to practical scenarios with no model training and low computational complexity.
Rectifying Noisy Labels with Sequential Prior: Multi-Scale Temporal Feature Affinity Learning for Robust Video Segmentation
Jul 12, 2023



Noisy label problems are inevitably in existence within medical image segmentation causing severe performance degradation. Previous segmentation methods for noisy label problems only utilize a single image while the potential of leveraging the correlation between images has been overlooked. Especially for video segmentation, adjacent frames contain rich contextual information beneficial in cognizing noisy labels. Based on two insights, we propose a Multi-Scale Temporal Feature Affinity Learning (MS-TFAL) framework to resolve noisy-labeled medical video segmentation issues. First, we argue the sequential prior of videos is an effective reference, i.e., pixel-level features from adjacent frames are close in distance for the same class and far in distance otherwise. Therefore, Temporal Feature Affinity Learning (TFAL) is devised to indicate possible noisy labels by evaluating the affinity between pixels in two adjacent frames. We also notice that the noise distribution exhibits considerable variations across video, image, and pixel levels. In this way, we introduce Multi-Scale Supervision (MSS) to supervise the network from three different perspectives by re-weighting and refining the samples. This design enables the network to concentrate on clean samples in a coarse-to-fine manner. Experiments with both synthetic and real-world label noise demonstrate that our method outperforms recent state-of-the-art robust segmentation approaches. Code is available at https://github.com/BeileiCui/MS-TFAL.
Generative Steganography by Sampling
Apr 26, 2018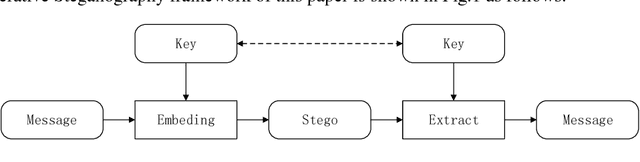
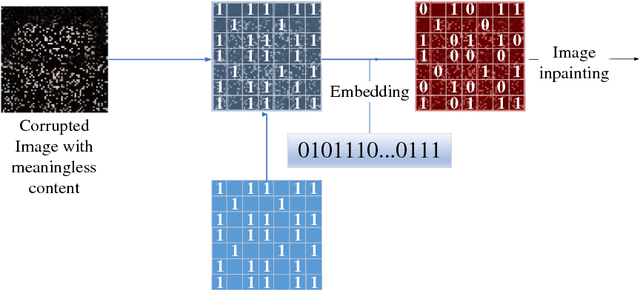
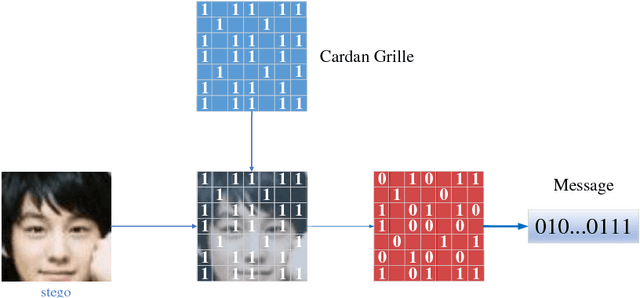

In this paper, a new data-driven information hiding scheme called generative steganography by sampling (GSS) is proposed. The stego is directly sampled by a powerful generator without an explicit cover. Secret key shared by both parties is used for message embedding and extraction, respectively. Jensen-Shannon Divergence is introduced as new criteria for evaluation of the security of the generative steganography. Based on these principles, a simple practical generative steganography method is proposed using semantic image inpainting. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated stego images.