 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
Jun 29, 2023

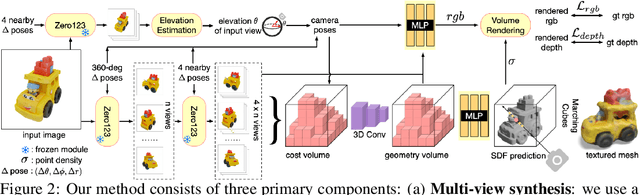
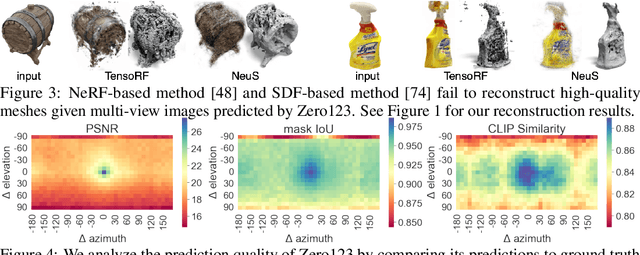

Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
Improving 3D Pose Estimation for Sign Language
Aug 18, 2023
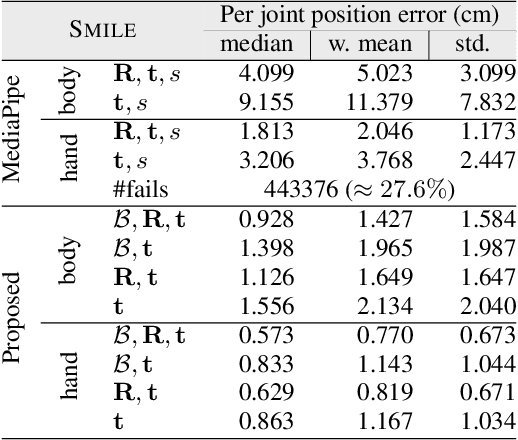
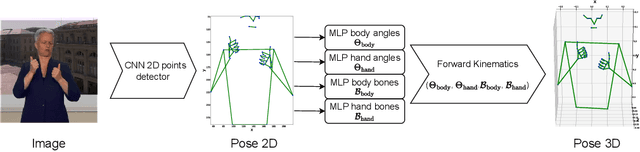
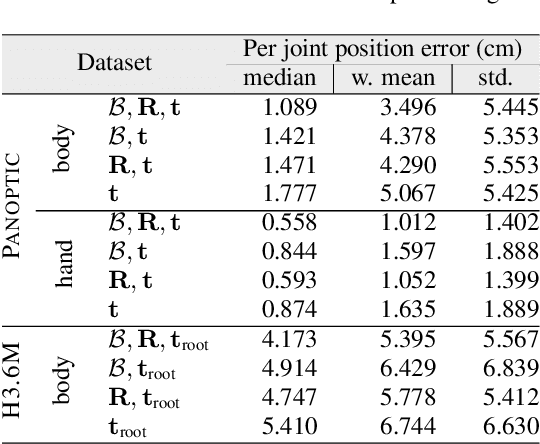
This work addresses 3D human pose reconstruction in single images. We present a method that combines Forward Kinematics (FK) with neural networks to ensure a fast and valid prediction of 3D pose. Pose is represented as a hierarchical tree/graph with nodes corresponding to human joints that model their physical limits. Given a 2D detection of keypoints in the image, we lift the skeleton to 3D using neural networks to predict both the joint rotations and bone lengths. These predictions are then combined with skeletal constraints using an FK layer implemented as a network layer in PyTorch. The result is a fast and accurate approach to the estimation of 3D skeletal pose. Through quantitative and qualitative evaluation, we demonstrate the method is significantly more accurate than MediaPipe in terms of both per joint positional error and visual appearance. Furthermore, we demonstrate generalization over different datasets. The implementation in PyTorch runs at between 100-200 milliseconds per image (including CNN detection) using CPU only.
Transferring Knowledge for Food Image Segmentation using Transformers and Convolutions
Jun 15, 2023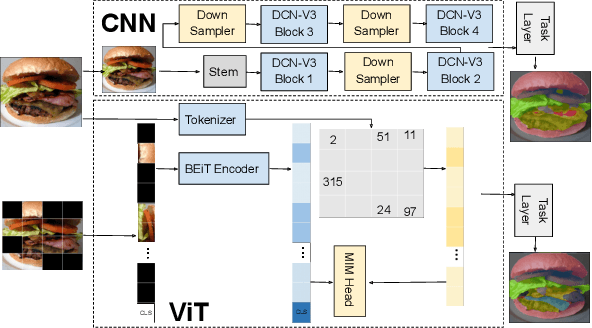
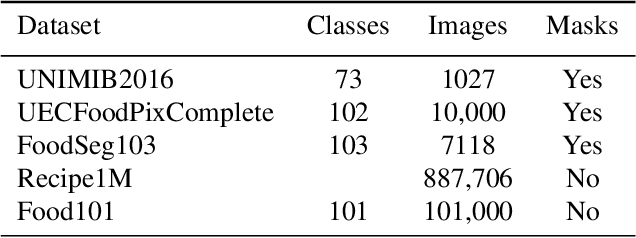

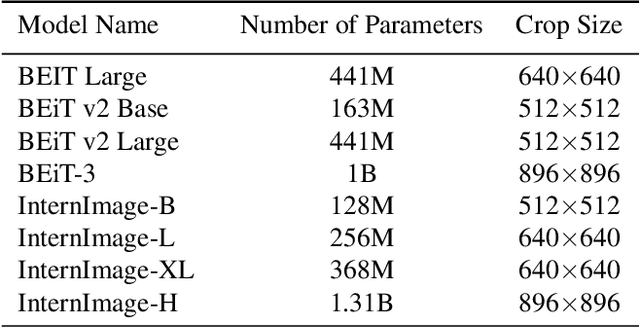
Food image segmentation is an important task that has ubiquitous applications, such as estimating the nutritional value of a plate of food. Although machine learning models have been used for segmentation in this domain, food images pose several challenges. One challenge is that food items can overlap and mix, making them difficult to distinguish. Another challenge is the degree of inter-class similarity and intra-class variability, which is caused by the varying preparation methods and dishes a food item may be served in. Additionally, class imbalance is an inevitable issue in food datasets. To address these issues, two models are trained and compared, one based on convolutional neural networks and the other on Bidirectional Encoder representation for Image Transformers (BEiT). The models are trained and valuated using the FoodSeg103 dataset, which is identified as a robust benchmark for food image segmentation. The BEiT model outperforms the previous state-of-the-art model by achieving a mean intersection over union of 49.4 on FoodSeg103. This study provides insights into transfering knowledge using convolution and Transformer-based approaches in the food image domain.
ACE-HetEM for ab initio Heterogenous Cryo-EM 3D Reconstruction
Aug 09, 2023Due to the extremely low signal-to-noise ratio (SNR) and unknown poses (projection angles and image translation) in cryo-EM experiments, reconstructing 3D structures from 2D images is very challenging. On top of these challenges, heterogeneous cryo-EM reconstruction also has an additional requirement: conformation classification. An emerging solution to this problem is called amortized inference, implemented using the autoencoder architecture or its variants. Instead of searching for the correct image-to-pose/conformation mapping for every image in the dataset as in non-amortized methods, amortized inference only needs to train an encoder that maps images to appropriate latent spaces representing poses or conformations. Unfortunately, standard amortized-inference-based methods with entangled latent spaces have difficulty learning the distribution of conformations and poses from cryo-EM images. In this paper, we propose an unsupervised deep learning architecture called "ACE-HetEM" based on amortized inference. To explicitly enforce the disentanglement of conformation classifications and pose estimations, we designed two alternating training tasks in our method: image-to-image task and pose-to-pose task. Results on simulated datasets show that ACE-HetEM has comparable accuracy in pose estimation and produces even better reconstruction resolution than non-amortized methods. Furthermore, we show that ACE-HetEM is also applicable to real experimental datasets.
Integrating Geometric Control into Text-to-Image Diffusion Models for High-Quality Detection Data Generation via Text Prompt
Jun 28, 2023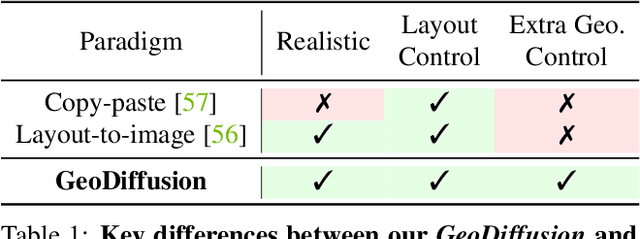
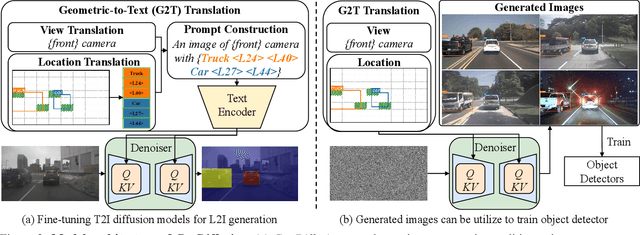
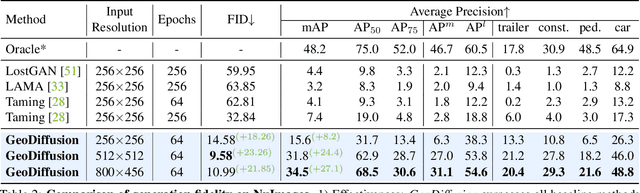
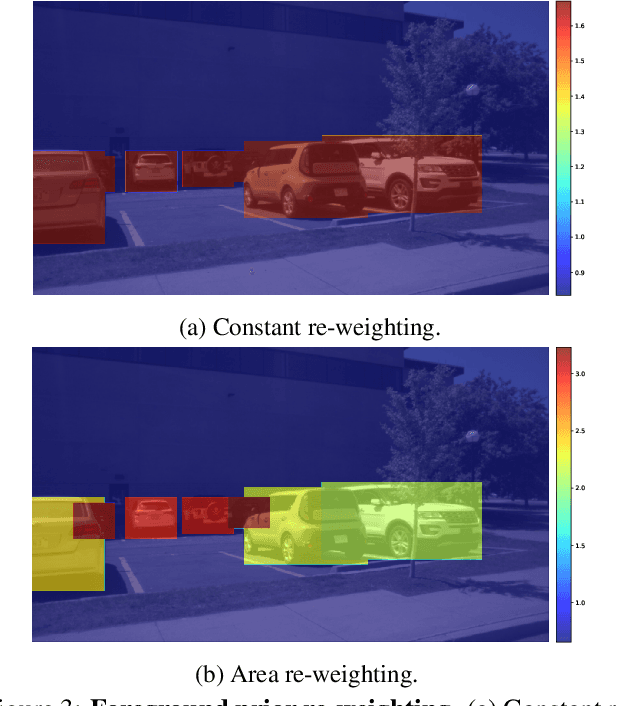
Diffusion models have attracted significant attention due to their remarkable ability to create content and generate data for tasks such as image classification. However, the usage of diffusion models to generate high-quality object detection data remains an underexplored area, where not only the image-level perceptual quality but also geometric conditions such as bounding boxes and camera views are essential. Previous studies have utilized either copy-paste synthesis or layout-to-image (L2I) generation with specifically designed modules to encode semantic layouts. In this paper, we propose GeoDiffusion, a simple framework that can flexibly translate various geometric conditions into text prompts and empower the pre-trained text-to-image (T2I) diffusion models for high-quality detection data generation. Unlike previous L2I methods, our GeoDiffusion is able to encode not only bounding boxes but also extra geometric conditions such as camera views in self-driving scenes. Extensive experiments demonstrate GeoDiffusion outperforms previous L2I methods while maintaining 4x training time faster. To the best of our knowledge, this is the first work to adopt diffusion models for layout-to-image generation with geometric conditions and demonstrate that L2I-generated images can be beneficial for improving the performance of object detectors.
Towards Vision-Language Mechanistic Interpretability: A Causal Tracing Tool for BLIP
Aug 27, 2023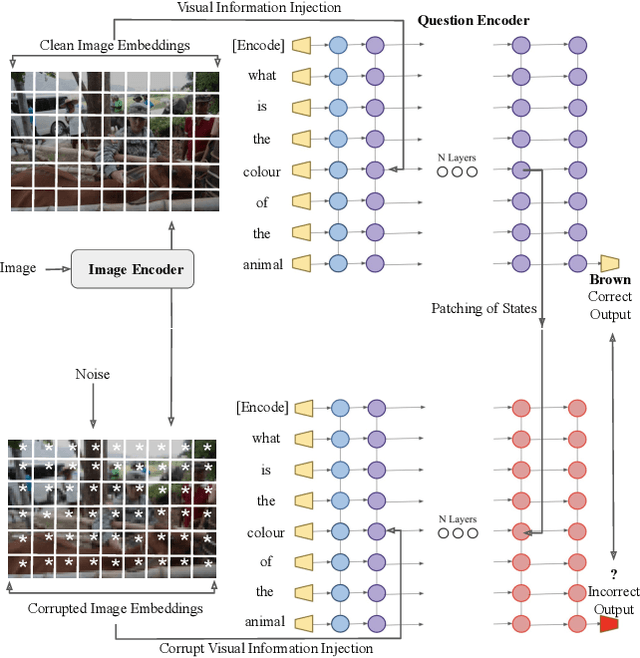

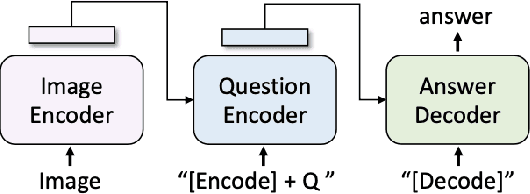

Mechanistic interpretability seeks to understand the neural mechanisms that enable specific behaviors in Large Language Models (LLMs) by leveraging causality-based methods. While these approaches have identified neural circuits that copy spans of text, capture factual knowledge, and more, they remain unusable for multimodal models since adapting these tools to the vision-language domain requires considerable architectural changes. In this work, we adapt a unimodal causal tracing tool to BLIP to enable the study of the neural mechanisms underlying image-conditioned text generation. We demonstrate our approach on a visual question answering dataset, highlighting the causal relevance of later layer representations for all tokens. Furthermore, we release our BLIP causal tracing tool as open source to enable further experimentation in vision-language mechanistic interpretability by the community. Our code is available at https://github.com/vedantpalit/Towards-Vision-Language-Mechanistic-Interpretability.
Pruning the Unlabeled Data to Improve Semi-Supervised Learning
Aug 27, 2023In the domain of semi-supervised learning (SSL), the conventional approach involves training a learner with a limited amount of labeled data alongside a substantial volume of unlabeled data, both drawn from the same underlying distribution. However, for deep learning models, this standard practice may not yield optimal results. In this research, we propose an alternative perspective, suggesting that distributions that are more readily separable could offer superior benefits to the learner as compared to the original distribution. To achieve this, we present PruneSSL, a practical technique for selectively removing examples from the original unlabeled dataset to enhance its separability. We present an empirical study, showing that although PruneSSL reduces the quantity of available training data for the learner, it significantly improves the performance of various competitive SSL algorithms, thereby achieving state-of-the-art results across several image classification tasks.
Joint learning of images and videos with a single Vision Transformer
Aug 21, 2023In this study, we propose a method for jointly learning of images and videos using a single model. In general, images and videos are often trained by separate models. We propose in this paper a method that takes a batch of images as input to Vision Transformer IV-ViT, and also a set of video frames with temporal aggregation by late fusion. Experimental results on two image datasets and two action recognition datasets are presented.
Bang and the Artefacts are Gone! Rapid Artefact Removal and Tissue Segmentation in Haematoxylin and Eosin Stained Biopsies
Aug 25, 2023We present H&E Otsu thresholding, a scheme for rapidly detecting tissue in whole-slide images (WSIs) that eliminates a wide range of undesirable artefacts such as pen marks and scanning artefacts. Our method involves obtaining a bid-modal representation of a low-magnification RGB overview image which enables simple Otsu thresholding to separate tissue from background and artefacts. We demonstrate our method on WSIs prepared from a wide range of institutions and WSI digital scanners, each containing substantial artefacts that cause other methods to fail. The beauty of our approach lies in its simplicity: manipulating RGB colour space and using Otsu thresholding allows for the rapid removal of artefacts and segmentation of tissue.
DISGO: Automatic End-to-End Evaluation for Scene Text OCR
Aug 25, 2023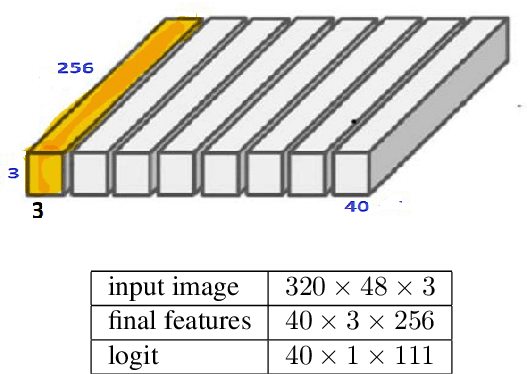


This paper discusses the challenges of optical character recognition (OCR) on natural scenes, which is harder than OCR on documents due to the wild content and various image backgrounds. We propose to uniformly use word error rates (WER) as a new measurement for evaluating scene-text OCR, both end-to-end (e2e) performance and individual system component performances. Particularly for the e2e metric, we name it DISGO WER as it considers Deletion, Insertion, Substitution, and Grouping/Ordering errors. Finally we propose to utilize the concept of super blocks to automatically compute BLEU scores for e2e OCR machine translation. The small SCUT public test set is used to demonstrate WER performance by a modularized OCR system.