 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physically Grounded Vision-Language Models for Robotic Manipulation
Sep 05, 2023
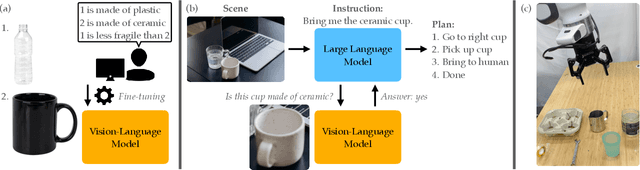

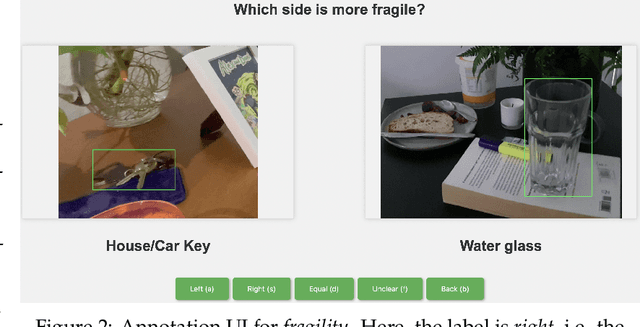
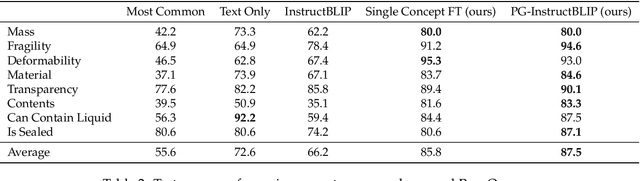
Recent advances in vision-language models (VLMs) have led to improved performance on tasks such as visual question answering and image captioning. Consequently, these models are now well-positioned to reason about the physical world, particularly within domains such as robotic manipulation. However, current VLMs are limited in their understanding of the physical concepts (e.g., material, fragility) of common objects, which restricts their usefulness for robotic manipulation tasks that involve interaction and physical reasoning about such objects. To address this limitation, we propose PhysObjects, an object-centric dataset of 36.9K crowd-sourced and 417K automated physical concept annotations of common household objects. We demonstrate that fine-tuning a VLM on PhysObjects improves its understanding of physical object concepts, by capturing human priors of these concepts from visual appearance. We incorporate this physically-grounded VLM in an interactive framework with a large language model-based robotic planner, and show improved planning performance on tasks that require reasoning about physical object concepts, compared to baselines that do not leverage physically-grounded VLMs. We additionally illustrate the benefits of our physically-grounded VLM on a real robot, where it improves task success rates. We release our dataset and provide further details and visualizations of our results at https://iliad.stanford.edu/pg-vlm/.
Evaluation Kidney Layer Segmentation on Whole Slide Imaging using Convolutional Neural Networks and Transformers
Sep 05, 2023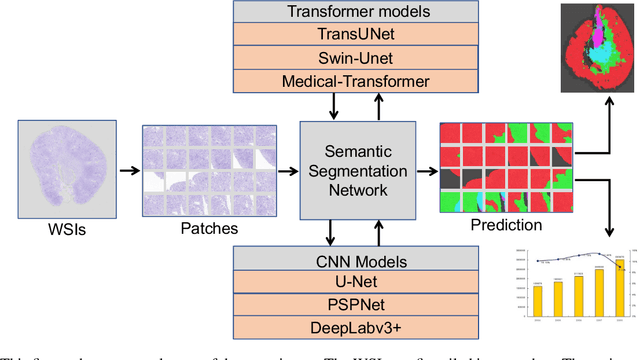
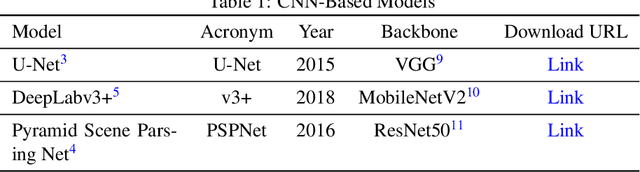
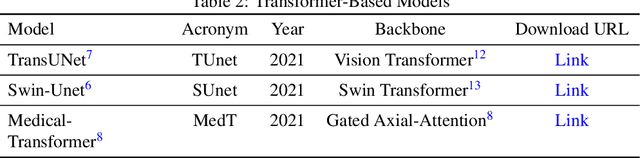
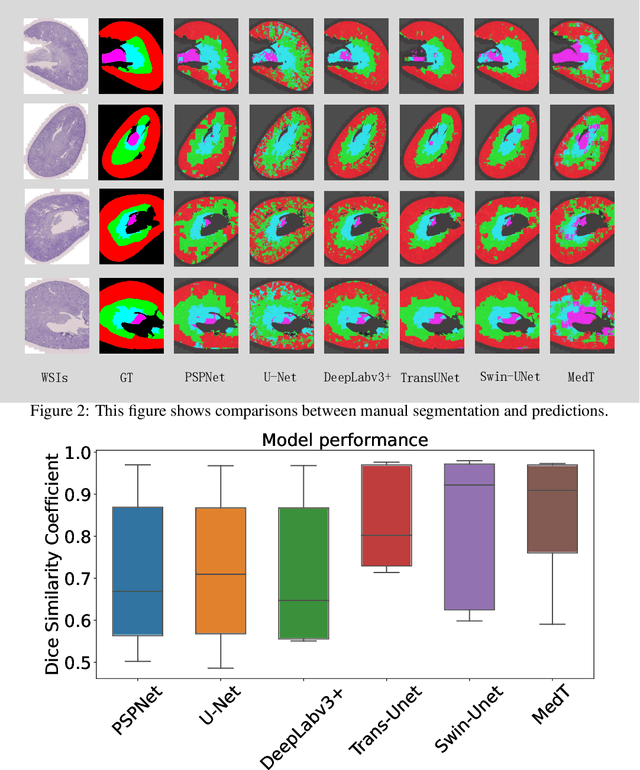
The segmentation of kidney layer structures, including cortex, outer stripe, inner stripe, and inner medulla within human kidney whole slide images (WSI) plays an essential role in automated image analysis in renal pathology. However, the current manual segmentation process proves labor-intensive and infeasible for handling the extensive digital pathology images encountered at a large scale. In response, the realm of digital renal pathology has seen the emergence of deep learning-based methodologies. However, very few, if any, deep learning based approaches have been applied to kidney layer structure segmentation. Addressing this gap, this paper assesses the feasibility of performing deep learning based approaches on kidney layer structure segmetnation. This study employs the representative convolutional neural network (CNN) and Transformer segmentation approaches, including Swin-Unet, Medical-Transformer, TransUNet, U-Net, PSPNet, and DeepLabv3+. We quantitatively evaluated six prevalent deep learning models on renal cortex layer segmentation using mice kidney WSIs. The empirical results stemming from our approach exhibit compelling advancements, as evidenced by a decent Mean Intersection over Union (mIoU) index. The results demonstrate that Transformer models generally outperform CNN-based models. By enabling a quantitative evaluation of renal cortical structures, deep learning approaches are promising to empower these medical professionals to make more informed kidney layer segmentation.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


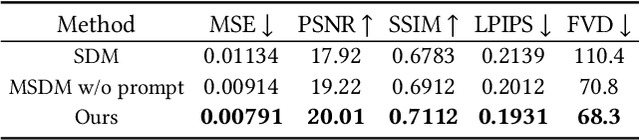
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.
A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking
Sep 05, 2023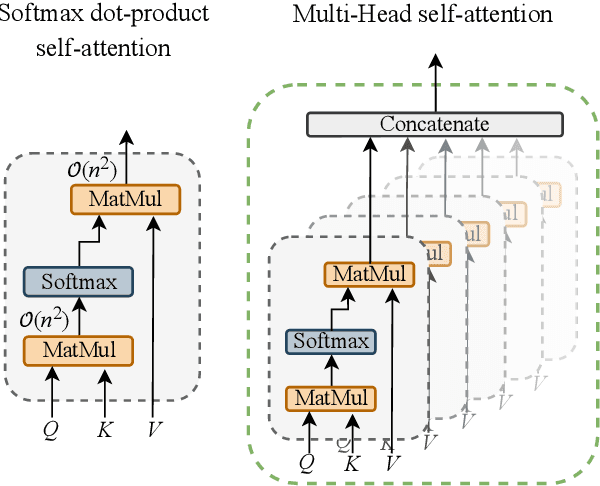

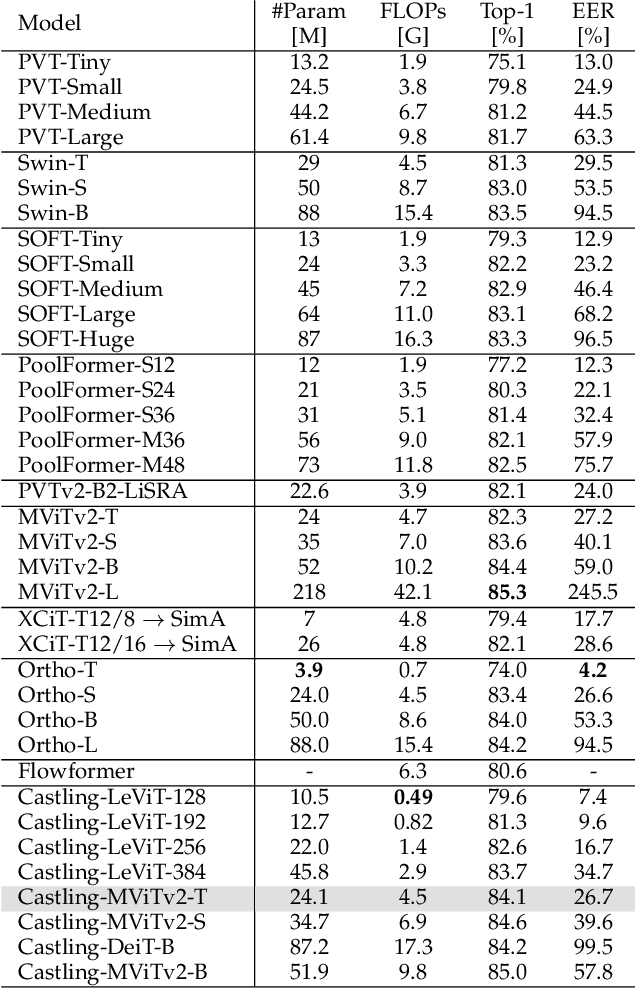
Vision Transformer (ViT) architectures are becoming increasingly popular and widely employed to tackle computer vision applications. Their main feature is the capacity to extract global information through the self-attention mechanism, outperforming earlier convolutional neural networks. However, ViT deployment and performance have grown steadily with their size, number of trainable parameters, and operations. Furthermore, self-attention's computational and memory cost quadratically increases with the image resolution. Generally speaking, it is challenging to employ these architectures in real-world applications due to many hardware and environmental restrictions, such as processing and computational capabilities. Therefore, this survey investigates the most efficient methodologies to ensure sub-optimal estimation performances. More in detail, four efficient categories will be analyzed: compact architecture, pruning, knowledge distillation, and quantization strategies. Moreover, a new metric called Efficient Error Rate has been introduced in order to normalize and compare models' features that affect hardware devices at inference time, such as the number of parameters, bits, FLOPs, and model size. Summarizing, this paper firstly mathematically defines the strategies used to make Vision Transformer efficient, describes and discusses state-of-the-art methodologies, and analyzes their performances over different application scenarios. Toward the end of this paper, we also discuss open challenges and promising research directions.
Privacy Preserving Federated Learning with Convolutional Variational Bottlenecks
Sep 08, 2023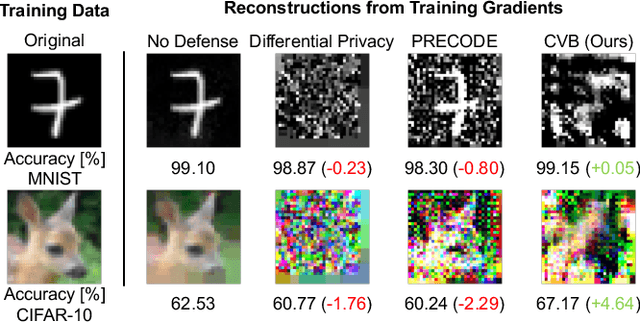
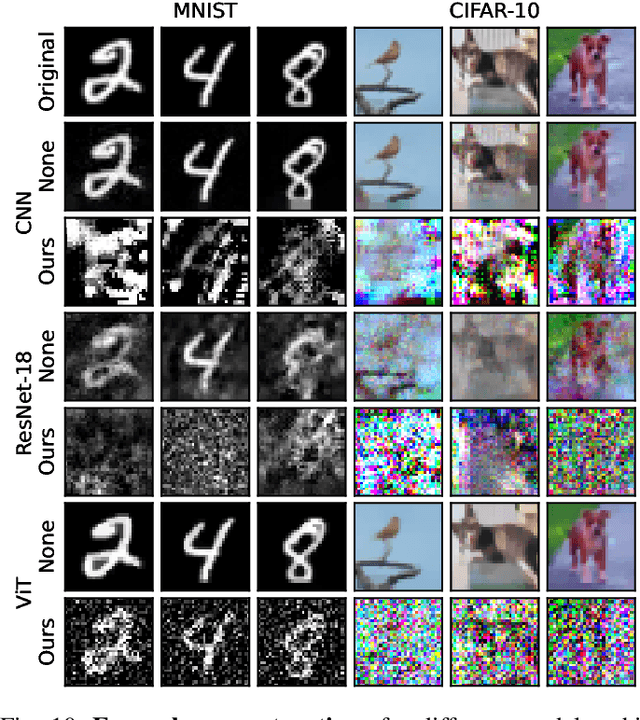
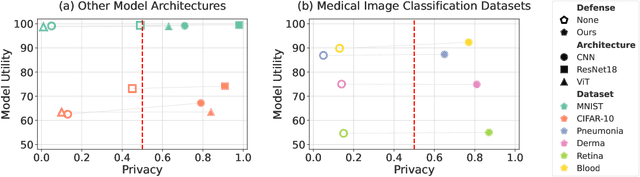

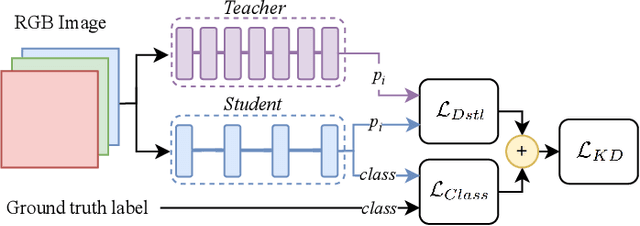
Gradient inversion attacks are an ubiquitous threat in federated learning as they exploit gradient leakage to reconstruct supposedly private training data. Recent work has proposed to prevent gradient leakage without loss of model utility by incorporating a PRivacy EnhanCing mODulE (PRECODE) based on variational modeling. Without further analysis, it was shown that PRECODE successfully protects against gradient inversion attacks. In this paper, we make multiple contributions. First, we investigate the effect of PRECODE on gradient inversion attacks to reveal its underlying working principle. We show that variational modeling introduces stochasticity into the gradients of PRECODE and the subsequent layers in a neural network. The stochastic gradients of these layers prevent iterative gradient inversion attacks from converging. Second, we formulate an attack that disables the privacy preserving effect of PRECODE by purposefully omitting stochastic gradients during attack optimization. To preserve the privacy preserving effect of PRECODE, our analysis reveals that variational modeling must be placed early in the network. However, early placement of PRECODE is typically not feasible due to reduced model utility and the exploding number of additional model parameters. Therefore, as a third contribution, we propose a novel privacy module -- the Convolutional Variational Bottleneck (CVB) -- that can be placed early in a neural network without suffering from these drawbacks. We conduct an extensive empirical study on three seminal model architectures and six image classification datasets. We find that all architectures are susceptible to gradient leakage attacks, which can be prevented by our proposed CVB. Compared to PRECODE, we show that our novel privacy module requires fewer trainable parameters, and thus computational and communication costs, to effectively preserve privacy.
POCO: 3D Pose and Shape Estimation with Confidence
Aug 24, 2023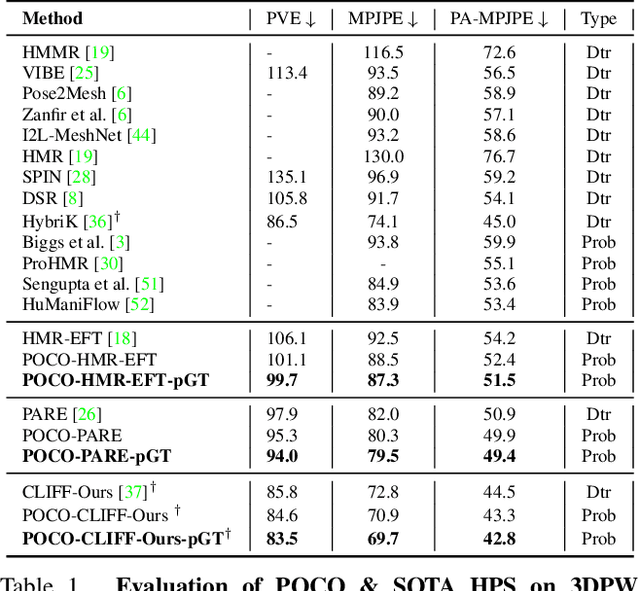
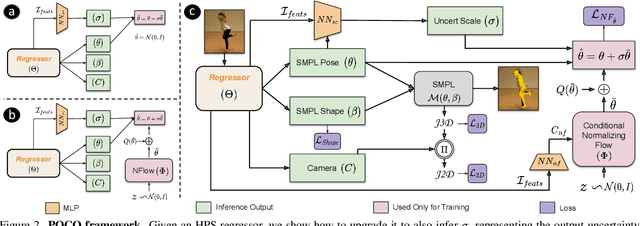
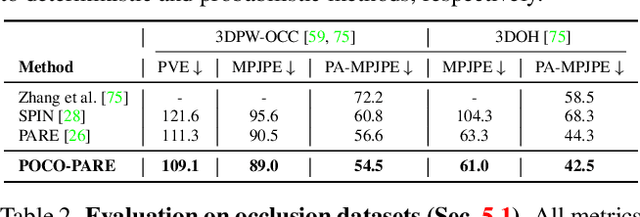
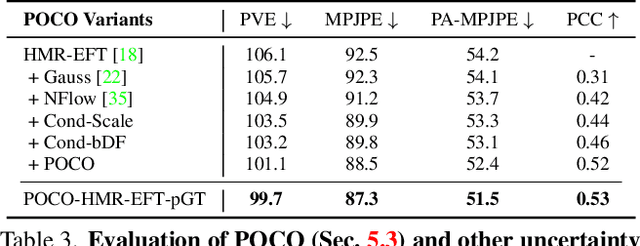
The regression of 3D Human Pose and Shape (HPS) from an image is becoming increasingly accurate. This makes the results useful for downstream tasks like human action recognition or 3D graphics. Yet, no regressor is perfect, and accuracy can be affected by ambiguous image evidence or by poses and appearance that are unseen during training. Most current HPS regressors, however, do not report the confidence of their outputs, meaning that downstream tasks cannot differentiate accurate estimates from inaccurate ones. To address this, we develop POCO, a novel framework for training HPS regressors to estimate not only a 3D human body, but also their confidence, in a single feed-forward pass. Specifically, POCO estimates both the 3D body pose and a per-sample variance. The key idea is to introduce a Dual Conditioning Strategy (DCS) for regressing uncertainty that is highly correlated to pose reconstruction quality. The POCO framework can be applied to any HPS regressor and here we evaluate it by modifying HMR, PARE, and CLIFF. In all cases, training the network to reason about uncertainty helps it learn to more accurately estimate 3D pose. While this was not our goal, the improvement is modest but consistent. Our main motivation is to provide uncertainty estimates for downstream tasks; we demonstrate this in two ways: (1) We use the confidence estimates to bootstrap HPS training. Given unlabelled image data, we take the confident estimates of a POCO-trained regressor as pseudo ground truth. Retraining with this automatically-curated data improves accuracy. (2) We exploit uncertainty in video pose estimation by automatically identifying uncertain frames (e.g. due to occlusion) and inpainting these from confident frames. Code and models will be available for research at https://poco.is.tue.mpg.de.
Dealing with Small Datasets for Deep Learning in Medical Imaging: An Evaluation of Self-Supervised Pre-Training on CT Scans Comparing Contrastive and Masked Autoencoder Methods for Convolutional Models
Aug 24, 2023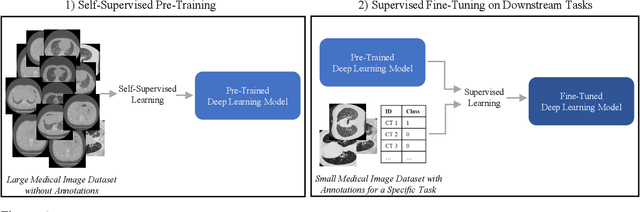
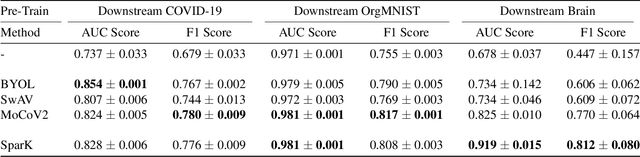
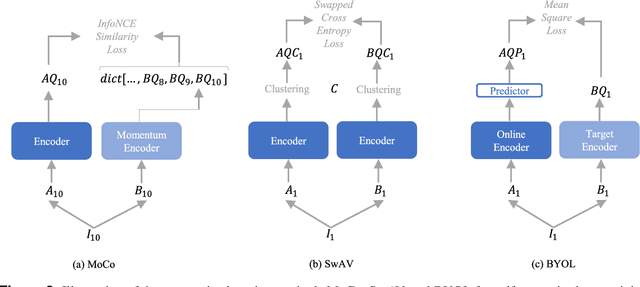
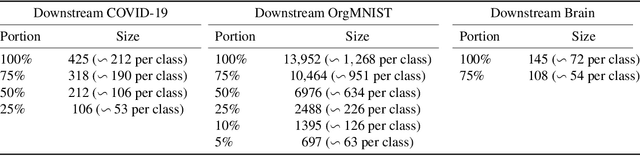
Deep learning in medical imaging has the potential to minimize the risk of diagnostic errors, reduce radiologist workload, and accelerate diagnosis. Training such deep learning models requires large and accurate datasets, with annotations for all training samples. However, in the medical imaging domain, annotated datasets for specific tasks are often small due to the high complexity of annotations, limited access, or the rarity of diseases. To address this challenge, deep learning models can be pre-trained on large image datasets without annotations using methods from the field of self-supervised learning. After pre-training, small annotated datasets are sufficient to fine-tune the models for a specific task. The most popular self-supervised pre-training approaches in medical imaging are based on contrastive learning. However, recent studies in natural image processing indicate a strong potential for masked autoencoder approaches. Our work compares state-of-the-art contrastive learning methods with the recently introduced masked autoencoder approach "SparK" for convolutional neural networks (CNNs) on medical images. Therefore we pre-train on a large unannotated CT image dataset and fine-tune on several CT classification tasks. Due to the challenge of obtaining sufficient annotated training data in medical imaging, it is of particular interest to evaluate how the self-supervised pre-training methods perform when fine-tuning on small datasets. By experimenting with gradually reducing the training dataset size for fine-tuning, we find that the reduction has different effects depending on the type of pre-training chosen. The SparK pre-training method is more robust to the training dataset size than the contrastive methods. Based on our results, we propose the SparK pre-training for medical imaging tasks with only small annotated datasets.
Correcting Motion Distortion for LIDAR HD-Map Localization
Aug 25, 2023Because scanning-LIDAR sensors require finite time to create a point cloud, sensor motion during a scan warps the resulting image, a phenomenon known as motion distortion or rolling shutter. Motion-distortion correction methods exist, but they rely on external measurements or Bayesian filtering over multiple LIDAR scans. In this paper we propose a novel algorithm that performs snapshot processing to obtain a motion-distortion correction. Snapshot processing, which registers a current LIDAR scan to a reference image without using external sensors or Bayesian filtering, is particularly relevant for localization to a high-definition (HD) map. Our approach, which we call Velocity-corrected Iterative Compact Ellipsoidal Transformation (VICET), extends the well-known Normal Distributions Transform (NDT) algorithm to solve jointly for both a 6 Degree-of-Freedom (DOF) rigid transform between two LIDAR scans and a set of 6DOF motion states that describe distortion within the current LIDAR scan. Using experiments, we show that VICET achieves significantly higher accuracy than NDT or Iterative Closest Point (ICP) algorithms when localizing a distorted raw LIDAR scan against an undistorted HD Map. We recommend the reader explore our open-source code and visualizations at https://github.com/mcdermatt/VICET, which supplements this manuscript.
Deep image prior inpainting of ancient frescoes in the Mediterranean Alpine arc
Jun 25, 2023

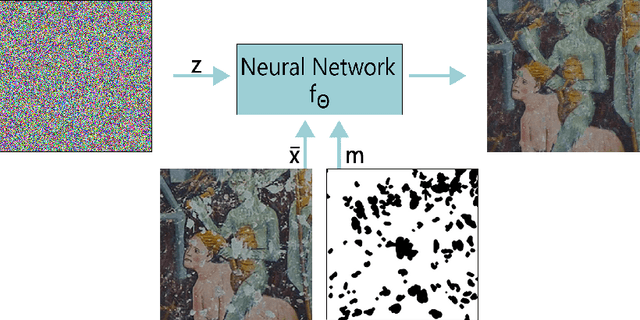
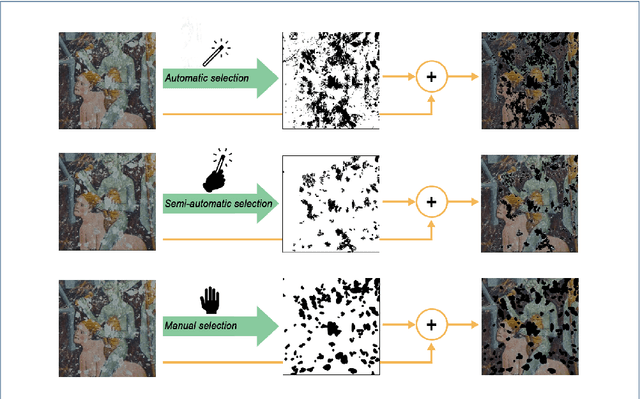
The unprecedented success of image reconstruction approaches based on deep neural networks has revolutionised both the processing and the analysis paradigms in several applied disciplines. In the field of digital humanities, the task of digital reconstruction of ancient frescoes is particularly challenging due to the scarce amount of available training data caused by ageing, wear, tear and retouching over time. To overcome these difficulties, we consider the Deep Image Prior (DIP) inpainting approach which computes appropriate reconstructions by relying on the progressive updating of an untrained convolutional neural network so as to match the reliable piece of information in the image at hand while promoting regularisation elsewhere. In comparison with state-of-the-art approaches (based on variational/PDEs and patch-based methods), DIP-based inpainting reduces artefacts and better adapts to contextual/non-local information, thus providing a valuable and effective tool for art historians. As a case study, we apply such approach to reconstruct missing image contents in a dataset of highly damaged digital images of medieval paintings located into several chapels in the Mediterranean Alpine Arc and provide a detailed description on how visible and invisible (e.g., infrared) information can be integrated for identifying and reconstructing damaged image regions.
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF
Sep 04, 2023Deep neural networks (DNNs) have been proven extremely susceptible to adversarial examples, which raises special safety-critical concerns for DNN-based autonomous driving stacks (i.e., 3D object detection). Although there are extensive works on image-level attacks, most are restricted to 2D pixel spaces, and such attacks are not always physically realistic in our 3D world. Here we present Adv3D, the first exploration of modeling adversarial examples as Neural Radiance Fields (NeRFs). Advances in NeRF provide photorealistic appearances and 3D accurate generation, yielding a more realistic and realizable adversarial example. We train our adversarial NeRF by minimizing the surrounding objects' confidence predicted by 3D detectors on the training set. Then we evaluate Adv3D on the unseen validation set and show that it can cause a large performance reduction when rendering NeRF in any sampled pose. To generate physically realizable adversarial examples, we propose primitive-aware sampling and semantic-guided regularization that enable 3D patch attacks with camouflage adversarial texture. Experimental results demonstrate that the trained adversarial NeRF generalizes well to different poses, scenes, and 3D detectors. Finally, we provide a defense method to our attacks that involves adversarial training through data augmentation. Project page: https://len-li.github.io/adv3d-web