 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding Light on Depth: Explainability Assessment in Monocular Depth Estimation
Sep 19, 2025



Explainable artificial intelligence is increasingly employed to understand the decision-making process of deep learning models and create trustworthiness in their adoption. However, the explainability of Monocular Depth Estimation (MDE) remains largely unexplored despite its wide deployment in real-world applications. In this work, we study how to analyze MDE networks to map the input image to the predicted depth map. More in detail, we investigate well-established feature attribution methods, Saliency Maps, Integrated Gradients, and Attention Rollout on different computationally complex models for MDE: METER, a lightweight network, and PixelFormer, a deep network. We assess the quality of the generated visual explanations by selectively perturbing the most relevant and irrelevant pixels, as identified by the explainability methods, and analyzing the impact of these perturbations on the model's output. Moreover, since existing evaluation metrics can have some limitations in measuring the validity of visual explanations for MDE, we additionally introduce the Attribution Fidelity. This metric evaluates the reliability of the feature attribution by assessing their consistency with the predicted depth map. Experimental results demonstrate that Saliency Maps and Integrated Gradients have good performance in highlighting the most important input features for MDE lightweight and deep models, respectively. Furthermore, we show that Attribution Fidelity effectively identifies whether an explainability method fails to produce reliable visual maps, even in scenarios where conventional metrics might suggest satisfactory results.
Enhancing Ground-to-Aerial Image Matching for Visual Misinformation Detection Using Semantic Segmentation
Feb 10, 2025



The recent advancements in generative AI techniques, which have significantly increased the online dissemination of altered images and videos, have raised serious concerns about the credibility of digital media available on the Internet and distributed through information channels and social networks. This issue particularly affects domains that rely heavily on trustworthy data, such as journalism, forensic analysis, and Earth observation. To address these concerns, the ability to geolocate a non-geo-tagged ground-view image without external information, such as GPS coordinates, has become increasingly critical. This study tackles the challenge of linking a ground-view image, potentially exhibiting varying fields of view (FoV), to its corresponding satellite image without the aid of GPS data. To achieve this, we propose a novel four-stream Siamese-like architecture, the Quadruple Semantic Align Net (SAN-QUAD), which extends previous state-of-the-art (SOTA) approaches by leveraging semantic segmentation applied to both ground and satellite imagery. Experimental results on a subset of the CVUSA dataset demonstrate significant improvements of up to 9.8\% over prior methods across various FoV settings.
Beyond adaptive gradient: Fast-Controlled Minibatch Algorithm for large-scale optimization
Nov 24, 2024

Adaptive gradient methods have been increasingly adopted by deep learning community due to their fast convergence and reduced sensitivity to hyper-parameters. However, these methods come with limitations, such as increased memory requirements for elements like moving averages and a poorly understood convergence theory. To overcome these challenges, we introduce F-CMA, a Fast-Controlled Mini-batch Algorithm with a random reshuffling method featuring a sufficient decrease condition and a line-search procedure to ensure loss reduction per epoch, along with its deterministic proof of global convergence to a stationary point. To evaluate the F-CMA, we integrate it into conventional training protocols for classification tasks involving both convolutional neural networks and vision transformer models, allowing for a direct comparison with popular optimizers. Computational tests show significant improvements, including a decrease in the overall training time by up to 68%, an increase in per-epoch efficiency by up to 20%, and in model accuracy by up to 5%.
On the impact of key design aspects in simulated Hybrid Quantum Neural Networks for Earth Observation
Oct 11, 2024



Quantum computing has introduced novel perspectives for tackling and improving machine learning tasks. Moreover, the integration of quantum technologies together with well-known deep learning (DL) architectures has emerged as a potential research trend gaining attraction across various domains, such as Earth Observation (EO) and many other research fields. However, prior related works in EO literature have mainly focused on convolutional architectural advancements, leaving several essential topics unexplored. Consequently, this research investigates through three cases of study fundamental aspects of hybrid quantum machine models for EO tasks aiming to provide a solid groundwork for future research studies towards more adequate simulations and looking at the post-NISQ era. More in detail, we firstly (1) investigate how different quantum libraries behave when training hybrid quantum models, assessing their computational efficiency and effectiveness. Secondly, (2) we analyze the stability/sensitivity to initialization values (i.e., seed values) in both traditional model and quantum-enhanced counterparts. Finally, (3) we explore the benefits of hybrid quantum attention-based models in EO applications, examining how integrating quantum circuits into ViTs can improve model performance.
Adversarial Data Poisoning for Fake News Detection: How to Make a Model Misclassify a Target News without Modifying It
Jan 04, 2024


Fake news detection models are critical to countering disinformation but can be manipulated through adversarial attacks. In this position paper, we analyze how an attacker can compromise the performance of an online learning detector on specific news content without being able to manipulate the original target news. In some contexts, such as social networks, where the attacker cannot exert complete control over all the information, this scenario can indeed be quite plausible. Therefore, we show how an attacker could potentially introduce poisoning data into the training data to manipulate the behavior of an online learning method. Our initial findings reveal varying susceptibility of logistic regression models based on complexity and attack type.
Diffusion Models for Earth Observation Use-cases: from cloud removal to urban change detection
Nov 10, 2023



The advancements in the state of the art of generative Artificial Intelligence (AI) brought by diffusion models can be highly beneficial in novel contexts involving Earth observation data. After introducing this new family of generative models, this work proposes and analyses three use cases which demonstrate the potential of diffusion-based approaches for satellite image data. Namely, we tackle cloud removal and inpainting, dataset generation for change-detection tasks, and urban replanning.
* Presented at Big Data from Space 2023 (BiDS)
A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking
Sep 05, 2023



Vision Transformer (ViT) architectures are becoming increasingly popular and widely employed to tackle computer vision applications. Their main feature is the capacity to extract global information through the self-attention mechanism, outperforming earlier convolutional neural networks. However, ViT deployment and performance have grown steadily with their size, number of trainable parameters, and operations. Furthermore, self-attention's computational and memory cost quadratically increases with the image resolution. Generally speaking, it is challenging to employ these architectures in real-world applications due to many hardware and environmental restrictions, such as processing and computational capabilities. Therefore, this survey investigates the most efficient methodologies to ensure sub-optimal estimation performances. More in detail, four efficient categories will be analyzed: compact architecture, pruning, knowledge distillation, and quantization strategies. Moreover, a new metric called Efficient Error Rate has been introduced in order to normalize and compare models' features that affect hardware devices at inference time, such as the number of parameters, bits, FLOPs, and model size. Summarizing, this paper firstly mathematically defines the strategies used to make Vision Transformer efficient, describes and discusses state-of-the-art methodologies, and analyzes their performances over different application scenarios. Toward the end of this paper, we also discuss open challenges and promising research directions.
DepthFake: a depth-based strategy for detecting Deepfake videos
Aug 23, 2022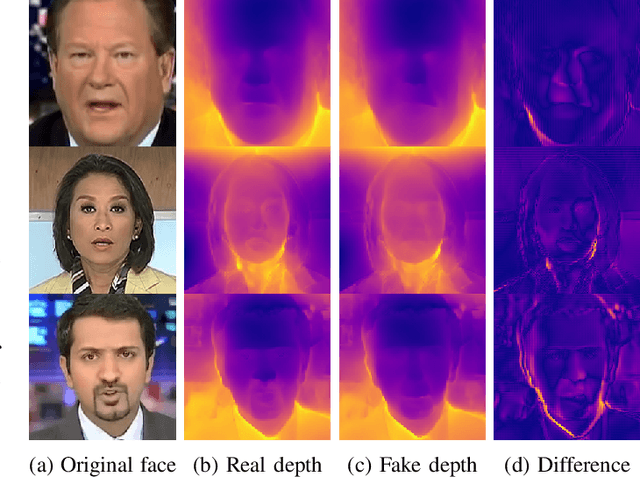
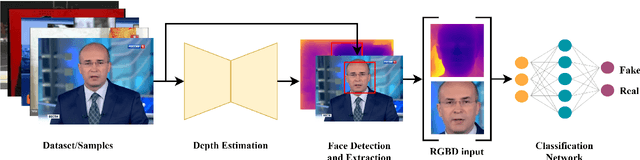
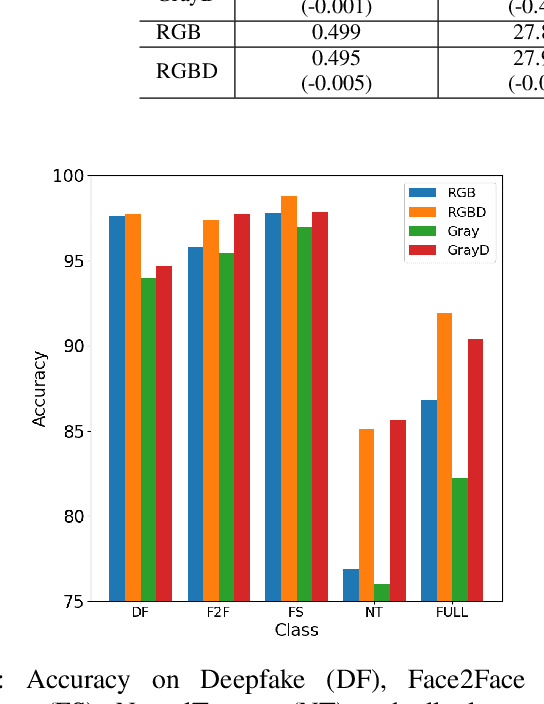
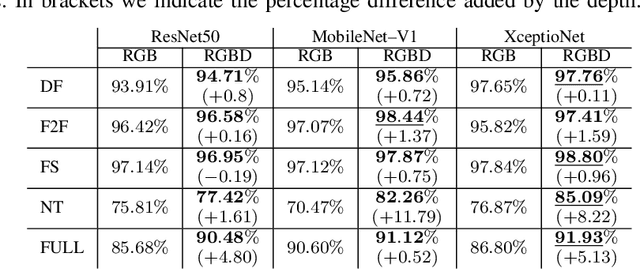
Fake content has grown at an incredible rate over the past few years. The spread of social media and online platforms makes their dissemination on a large scale increasingly accessible by malicious actors. In parallel, due to the growing diffusion of fake image generation methods, many Deep Learning-based detection techniques have been proposed. Most of those methods rely on extracting salient features from RGB images to detect through a binary classifier if the image is fake or real. In this paper, we proposed DepthFake, a study on how to improve classical RGB-based approaches with depth-maps. The depth information is extracted from RGB images with recent monocular depth estimation techniques. Here, we demonstrate the effective contribution of depth-maps to the deepfake detection task on robust pre-trained architectures. The proposed RGBD approach is in fact able to achieve an average improvement of 3.20% and up to 11.7% for some deepfake attacks with respect to standard RGB architectures over the FaceForensic++ dataset.