 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autonomous damage assessment of structural columns using low-cost micro aerial vehicles and multi-view computer vision
Aug 30, 2023
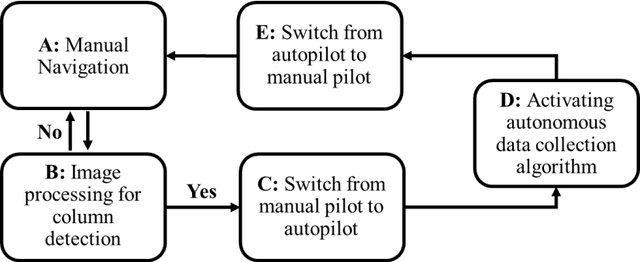
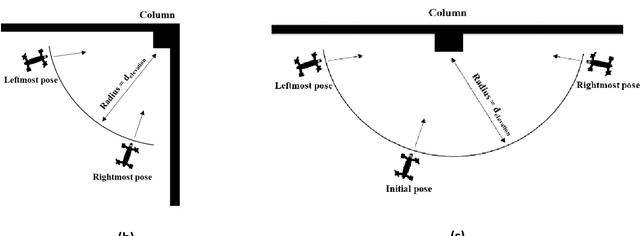

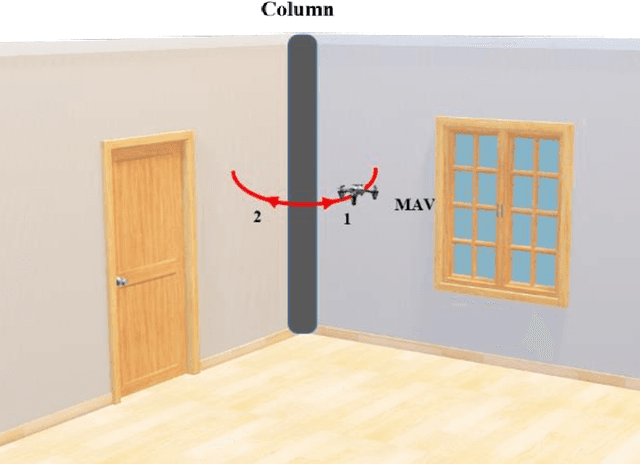
Structural columns are the crucial load-carrying components of buildings and bridges. Early detection of column damage is important for the assessment of the residual performance and the prevention of system-level collapse. This research proposes an innovative end-to-end micro aerial vehicles (MAVs)-based approach to automatically scan and inspect columns. First, an MAV-based automatic image collection method is proposed. The MAV is programmed to sense the structural columns and their surrounding environment. During the navigation, the MAV first detects and approaches the structural columns. Then, it starts to collect image data at multiple viewpoints around every detected column. Second, the collected images will be used to assess the damage types and damage locations. Third, the damage state of the structural column will be determined by fusing the evaluation outcomes from multiple camera views. In this study, reinforced concrete (RC) columns are selected to demonstrate the effectiveness of the approach. Experimental results indicate that the proposed MAV-based inspection approach can effectively collect images from multiple viewing angles, and accurately assess critical RC column damages. The approach improves the level of autonomy during the inspection. In addition, the evaluation outcomes are more comprehensive than the existing 2D vision methods. The concept of the proposed inspection approach can be extended to other structural columns such as bridge piers.
Diving into Darkness: A Dual-Modulated Framework for High-Fidelity Super-Resolution in Ultra-Dark Environments
Sep 11, 2023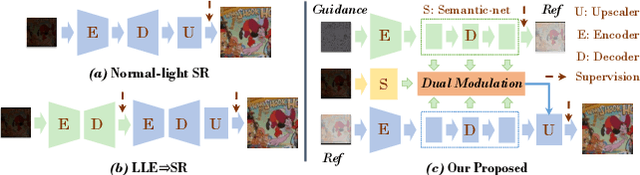
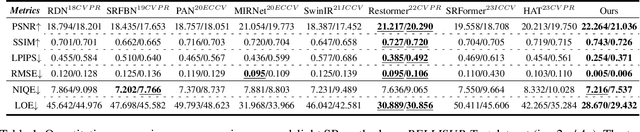


Super-resolution tasks oriented to images captured in ultra-dark environments is a practical yet challenging problem that has received little attention. Due to uneven illumination and low signal-to-noise ratio in dark environments, a multitude of problems such as lack of detail and color distortion may be magnified in the super-resolution process compared to normal-lighting environments. Consequently, conventional low-light enhancement or super-resolution methods, whether applied individually or in a cascaded manner for such problem, often encounter limitations in recovering luminance, color fidelity, and intricate details. To conquer these issues, this paper proposes a specialized dual-modulated learning framework that, for the first time, attempts to deeply dissect the nature of the low-light super-resolution task. Leveraging natural image color characteristics, we introduce a self-regularized luminance constraint as a prior for addressing uneven lighting. Expanding on this, we develop Illuminance-Semantic Dual Modulation (ISDM) components to enhance feature-level preservation of illumination and color details. Besides, instead of deploying naive up-sampling strategies, we design the Resolution-Sensitive Merging Up-sampler (RSMU) module that brings together different sampling modalities as substrates, effectively mitigating the presence of artifacts and halos. Comprehensive experiments showcases the applicability and generalizability of our approach to diverse and challenging ultra-low-light conditions, outperforming state-of-the-art methods with a notable improvement (i.e., $\uparrow$5\% in PSNR, and $\uparrow$43\% in LPIPS). Especially noteworthy is the 19-fold increase in the RMSE score, underscoring our method's exceptional generalization across different darkness levels. The code will be available online upon publication of the paper.
Comparative Study of Visual SLAM-Based Mobile Robot Localization Using Fiducial Markers
Sep 08, 2023
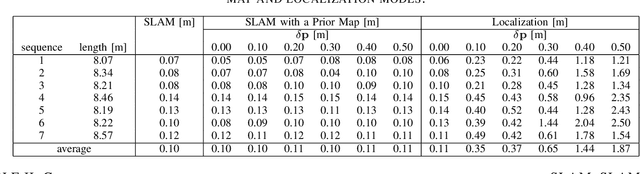
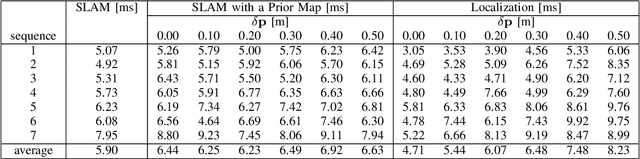
This paper presents a comparative study of three modes for mobile robot localization based on visual SLAM using fiducial markers (i.e., square-shaped artificial landmarks with a black-and-white grid pattern): SLAM, SLAM with a prior map, and localization with a prior map. The reason for comparing the SLAM-based approaches leveraging fiducial markers is because previous work has shown their superior performance over feature-only methods, with less computational burden compared to methods that use both feature and marker detection without compromising the localization performance. The evaluation is conducted using indoor image sequences captured with a hand-held camera containing multiple fiducial markers in the environment. The performance metrics include absolute trajectory error and runtime for the optimization process per frame. In particular, for the last two modes (SLAM and localization with a prior map), we evaluate their performances by perturbing the quality of prior map to study the extent to which each mode is tolerant to such perturbations. Hardware experiments show consistent trajectory error levels across the three modes, with the localization mode exhibiting the shortest runtime among them. Yet, with map perturbations, SLAM with a prior map maintains performance, while localization mode degrades in both aspects.
Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment
Sep 08, 2023
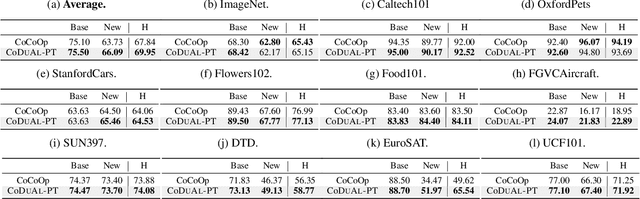
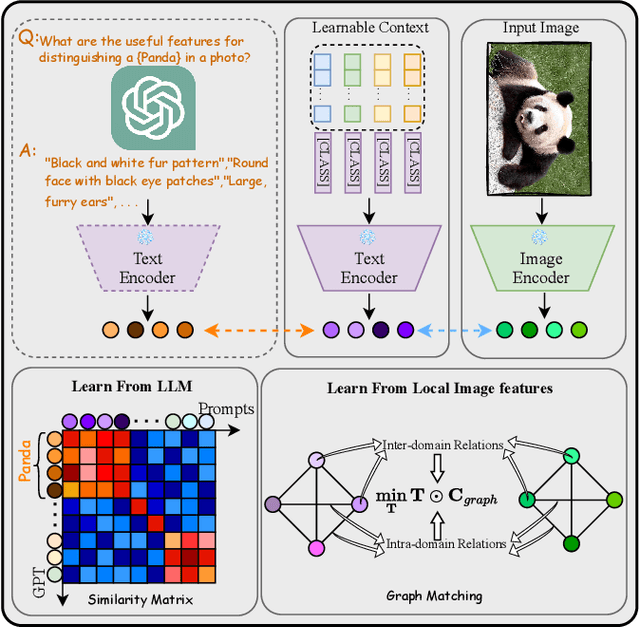
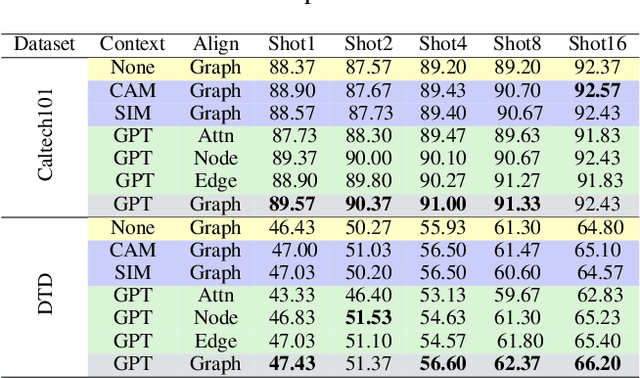
Large-scale vision-language models (VLMs), e.g., CLIP, learn broad visual concepts from tedious training data, showing superb generalization ability. Amount of prompt learning methods have been proposed to efficiently adapt the VLMs to downstream tasks with only a few training samples. We introduce a novel method to improve the prompt learning of vision-language models by incorporating pre-trained large language models (LLMs), called Dual-Aligned Prompt Tuning (DuAl-PT). Learnable prompts, like CoOp, implicitly model the context through end-to-end training, which are difficult to control and interpret. While explicit context descriptions generated by LLMs, like GPT-3, can be directly used for zero-shot classification, such prompts are overly relying on LLMs and still underexplored in few-shot domains. With DuAl-PT, we propose to learn more context-aware prompts, benefiting from both explicit and implicit context modeling. To achieve this, we introduce a pre-trained LLM to generate context descriptions, and we encourage the prompts to learn from the LLM's knowledge by alignment, as well as the alignment between prompts and local image features. Empirically, DuAl-PT achieves superior performance on 11 downstream datasets on few-shot recognition and base-to-new generalization. Hopefully, DuAl-PT can serve as a strong baseline. Code will be available.
Object Detection Difficulty: Suppressing Over-aggregation for Faster and Better Video Object Detection
Aug 22, 2023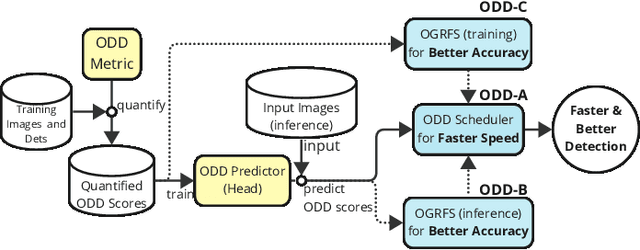
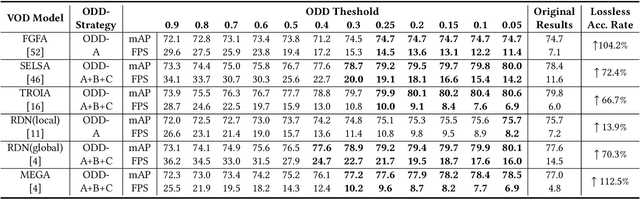

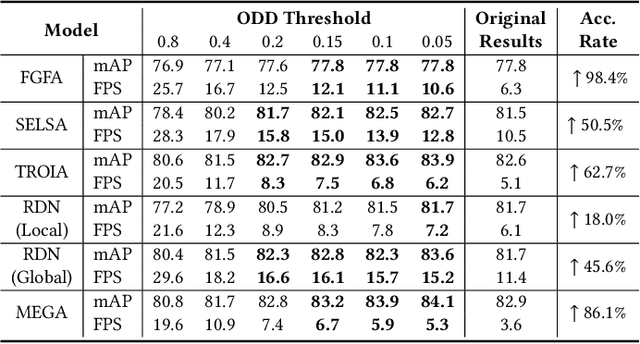
Current video object detection (VOD) models often encounter issues with over-aggregation due to redundant aggregation strategies, which perform feature aggregation on every frame. This results in suboptimal performance and increased computational complexity. In this work, we propose an image-level Object Detection Difficulty (ODD) metric to quantify the difficulty of detecting objects in a given image. The derived ODD scores can be used in the VOD process to mitigate over-aggregation. Specifically, we train an ODD predictor as an auxiliary head of a still-image object detector to compute the ODD score for each image based on the discrepancies between detection results and ground-truth bounding boxes. The ODD score enhances the VOD system in two ways: 1) it enables the VOD system to select superior global reference frames, thereby improving overall accuracy; and 2) it serves as an indicator in the newly designed ODD Scheduler to eliminate the aggregation of frames that are easy to detect, thus accelerating the VOD process. Comprehensive experiments demonstrate that, when utilized for selecting global reference frames, ODD-VOD consistently enhances the accuracy of Global-frame-based VOD models. When employed for acceleration, ODD-VOD consistently improves the frames per second (FPS) by an average of 73.3% across 8 different VOD models without sacrificing accuracy. When combined, ODD-VOD attains state-of-the-art performance when competing with many VOD methods in both accuracy and speed. Our work represents a significant advancement towards making VOD more practical for real-world applications.
DreamIdentity: Improved Editability for Efficient Face-identity Preserved Image Generation
Jul 01, 2023
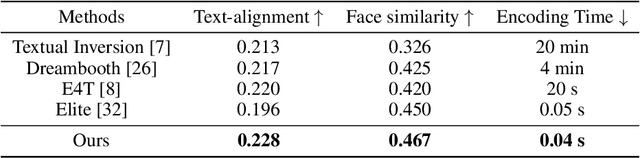
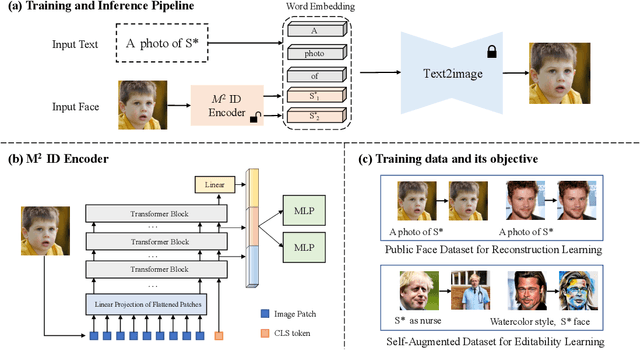

While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centric images, an intractable problem is how to preserve the face identity for conditioned face images. Existing methods either require time-consuming optimization for each face-identity or learning an efficient encoder at the cost of harming the editability of models. In this work, we present an optimization-free method for each face identity, meanwhile keeping the editability for text-to-image models. Specifically, we propose a novel face-identity encoder to learn an accurate representation of human faces, which applies multi-scale face features followed by a multi-embedding projector to directly generate the pseudo words in the text embedding space. Besides, we propose self-augmented editability learning to enhance the editability of models, which is achieved by constructing paired generated face and edited face images using celebrity names, aiming at transferring mature ability of off-the-shelf text-to-image models in celebrity faces to unseen faces. Extensive experiments show that our methods can generate identity-preserved images under different scenes at a much faster speed.
A Multimodal Visual Encoding Model Aided by Introducing Verbal Semantic Information
Aug 29, 2023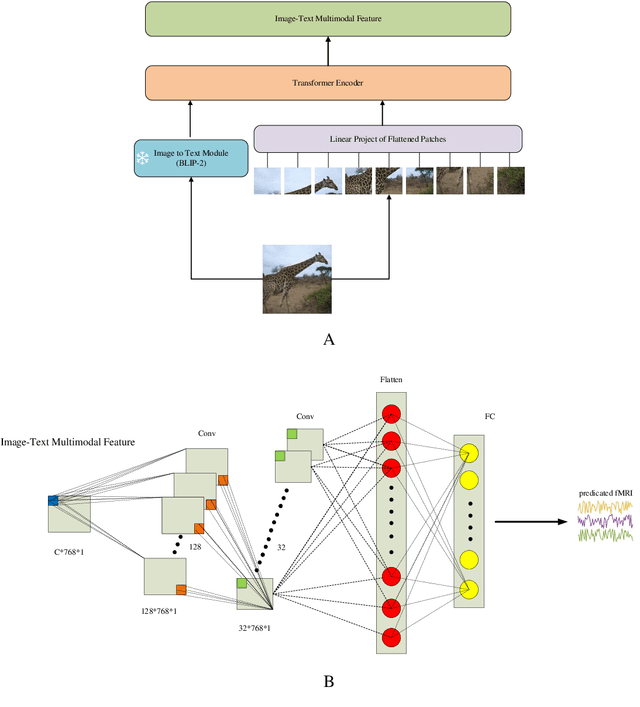
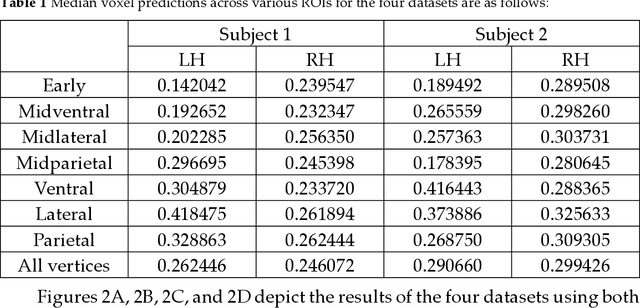
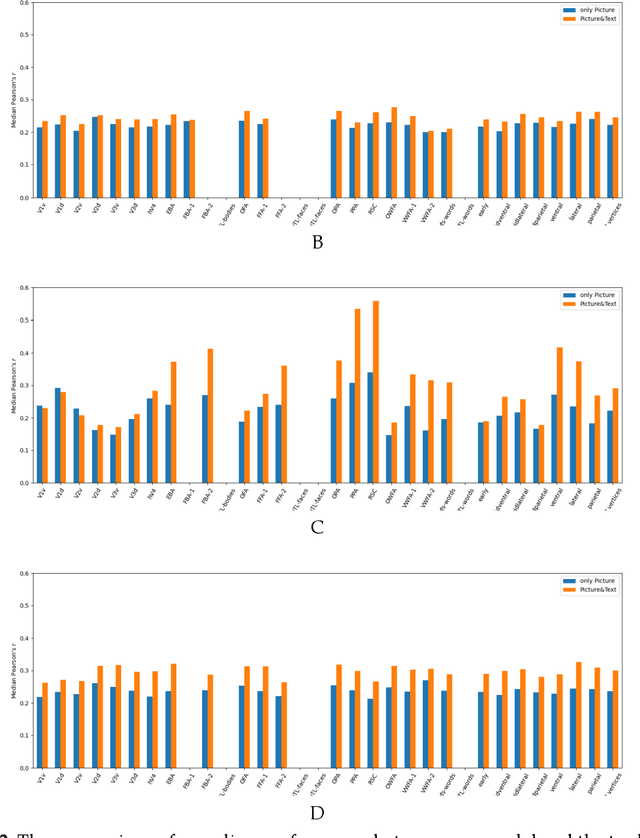
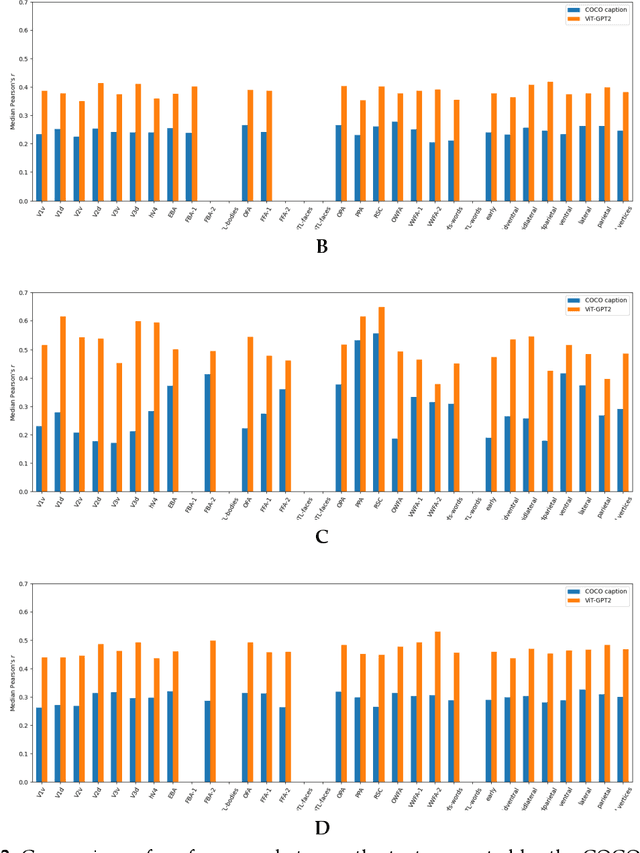
Biological research has revealed that the verbal semantic information in the brain cortex, as an additional source, participates in nonverbal semantic tasks, such as visual encoding. However, previous visual encoding models did not incorporate verbal semantic information, contradicting this biological finding. This paper proposes a multimodal visual information encoding network model based on stimulus images and associated textual information in response to this issue. Our visual information encoding network model takes stimulus images as input and leverages textual information generated by a text-image generation model as verbal semantic information. This approach injects new information into the visual encoding model. Subsequently, a Transformer network aligns image and text feature information, creating a multimodal feature space. A convolutional network then maps from this multimodal feature space to voxel space, constructing the multimodal visual information encoding network model. Experimental results demonstrate that the proposed multimodal visual information encoding network model outperforms previous models under the exact training cost. In voxel prediction of the left hemisphere of subject 1's brain, the performance improves by approximately 15.87%, while in the right hemisphere, the performance improves by about 4.6%. The multimodal visual encoding network model exhibits superior encoding performance. Additionally, ablation experiments indicate that our proposed model better simulates the brain's visual information processing.
Multimodal Foundation Models For Echocardiogram Interpretation
Aug 29, 2023
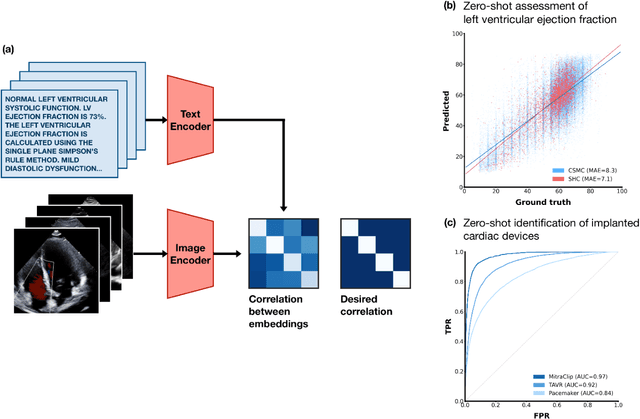
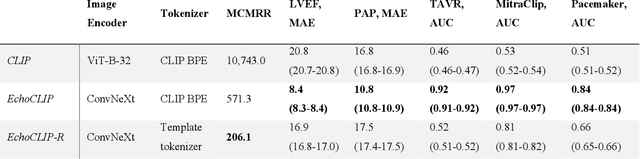
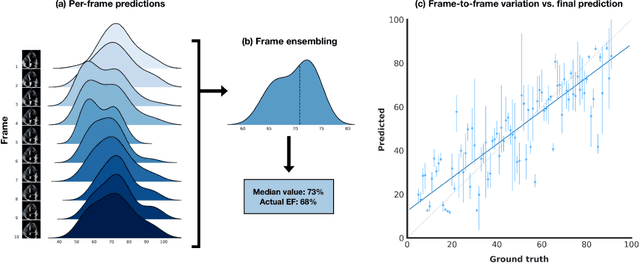
Multimodal deep learning foundation models can learn the relationship between images and text. In the context of medical imaging, mapping images to language concepts reflects the clinical task of diagnostic image interpretation, however current general-purpose foundation models do not perform well in this context because their training corpus have limited medical text and images. To address this challenge and account for the range of cardiac physiology, we leverage 1,032,975 cardiac ultrasound videos and corresponding expert interpretations to develop EchoCLIP, a multimodal foundation model for echocardiography. EchoCLIP displays strong zero-shot (not explicitly trained) performance in cardiac function assessment (external validation left ventricular ejection fraction mean absolute error (MAE) of 7.1%) and identification of implanted intracardiac devices (areas under the curve (AUC) between 0.84 and 0.98 for pacemakers and artificial heart valves). We also developed a long-context variant (EchoCLIP-R) with a custom echocardiography report text tokenizer which can accurately identify unique patients across multiple videos (AUC of 0.86), identify clinical changes such as orthotopic heart transplants (AUC of 0.79) or cardiac surgery (AUC 0.77), and enable robust image-to-text search (mean cross-modal retrieval rank in the top 1% of candidate text reports). These emergent capabilities can be used for preliminary assessment and summarization of echocardiographic findings.
Document AI: A Comparative Study of Transformer-Based, Graph-Based Models, and Convolutional Neural Networks For Document Layout Analysis
Aug 29, 2023
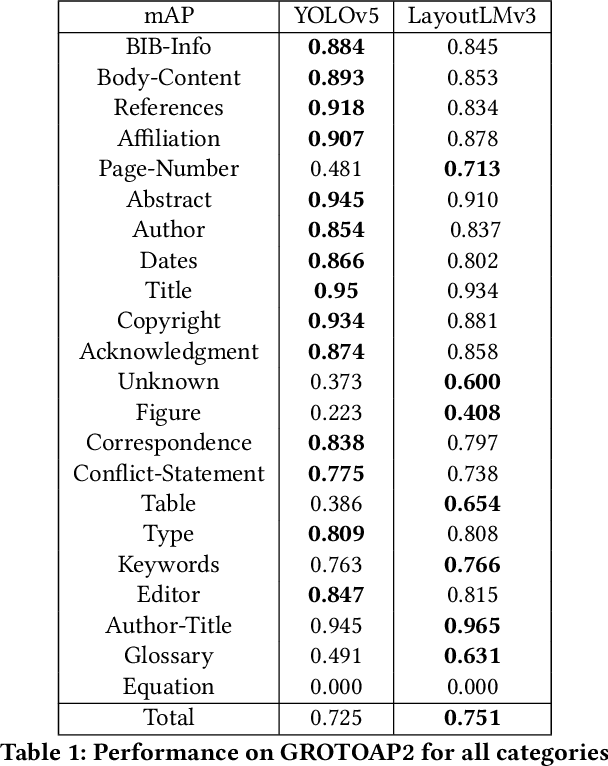
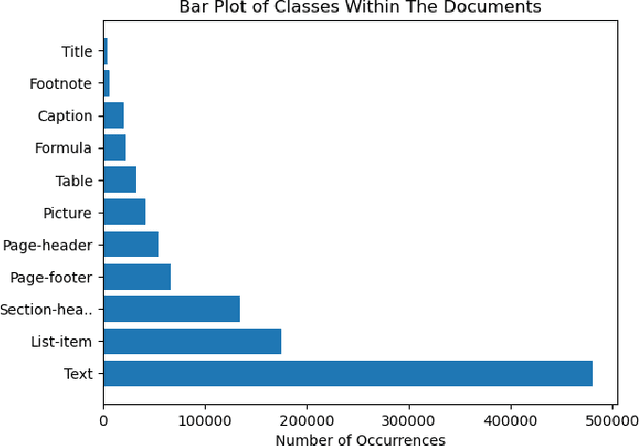

Document AI aims to automatically analyze documents by leveraging natural language processing and computer vision techniques. One of the major tasks of Document AI is document layout analysis, which structures document pages by interpreting the content and spatial relationships of layout, image, and text. This task can be image-centric, wherein the aim is to identify and label various regions such as authors and paragraphs, or text-centric, where the focus is on classifying individual words in a document. Although there are increasingly sophisticated methods for improving layout analysis, doubts remain about the extent to which their findings can be generalized to a broader context. Specifically, prior work developed systems based on very different architectures, such as transformer-based, graph-based, and CNNs. However, no work has mentioned the effectiveness of these models in a comparative analysis. Moreover, while language-independent Document AI models capable of knowledge transfer have been developed, it remains to be investigated to what degree they can effectively transfer knowledge. In this study, we aim to fill these gaps by conducting a comparative evaluation of state-of-the-art models in document layout analysis and investigating the potential of cross-lingual layout analysis by utilizing machine translation techniques.
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
Aug 25, 2023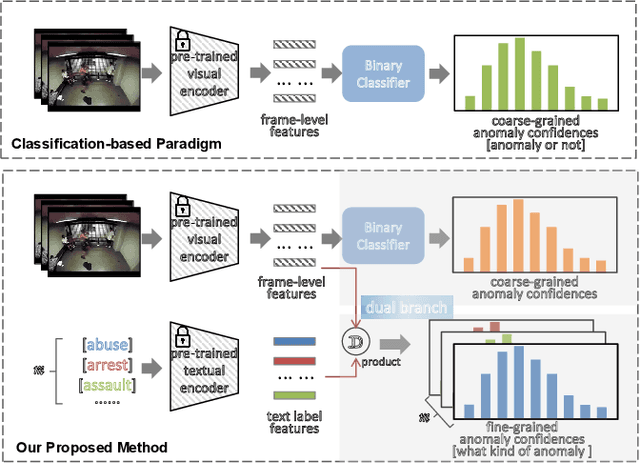
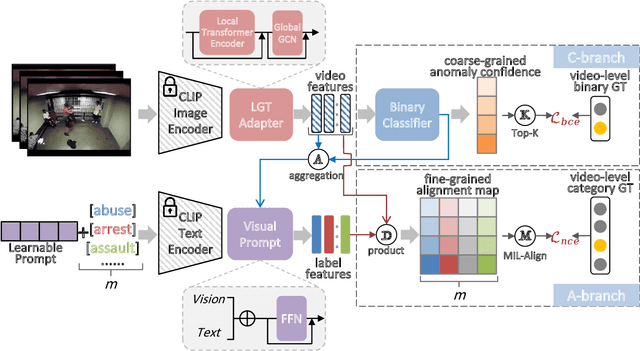

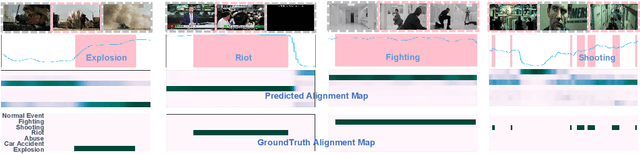
The recent contrastive language-image pre-training (CLIP) model has shown great success in a wide range of image-level tasks, revealing remarkable ability for learning powerful visual representations with rich semantics. An open and worthwhile problem is efficiently adapting such a strong model to the video domain and designing a robust video anomaly detector. In this work, we propose VadCLIP, a new paradigm for weakly supervised video anomaly detection (WSVAD) by leveraging the frozen CLIP model directly without any pre-training and fine-tuning process. Unlike current works that directly feed extracted features into the weakly supervised classifier for frame-level binary classification, VadCLIP makes full use of fine-grained associations between vision and language on the strength of CLIP and involves dual branch. One branch simply utilizes visual features for coarse-grained binary classification, while the other fully leverages the fine-grained language-image alignment. With the benefit of dual branch, VadCLIP achieves both coarse-grained and fine-grained video anomaly detection by transferring pre-trained knowledge from CLIP to WSVAD task. We conduct extensive experiments on two commonly-used benchmarks, demonstrating that VadCLIP achieves the best performance on both coarse-grained and fine-grained WSVAD, surpassing the state-of-the-art methods by a large margin. Specifically, VadCLIP achieves 84.51% AP and 88.02% AUC on XD-Violence and UCF-Crime, respectively. Code and features will be released to facilitate future VAD research.