 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Non-additive Randomness on ViT against Query-Based Black-Box Attacks
Sep 12, 2023
Deep Neural Networks can be easily fooled by small and imperceptible perturbations. The query-based black-box attack (QBBA) is able to create the perturbations using model output probabilities of image queries requiring no access to the underlying models. QBBA poses realistic threats to real-world applications. Recently, various types of robustness have been explored to defend against QBBA. In this work, we first taxonomize the stochastic defense strategies against QBBA. Following our taxonomy, we propose to explore non-additive randomness in models to defend against QBBA. Specifically, we focus on underexplored Vision Transformers based on their flexible architectures. Extensive experiments show that the proposed defense approach achieves effective defense, without much sacrifice in performance.
COLosSAL: A Benchmark for Cold-start Active Learning for 3D Medical Image Segmentation
Jul 22, 2023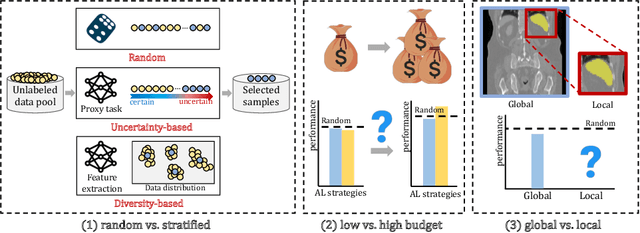
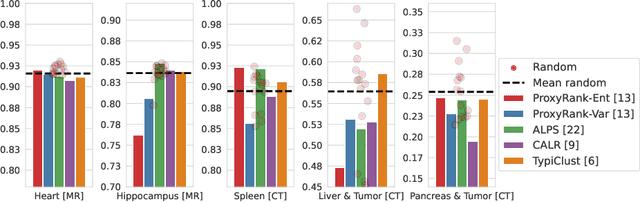
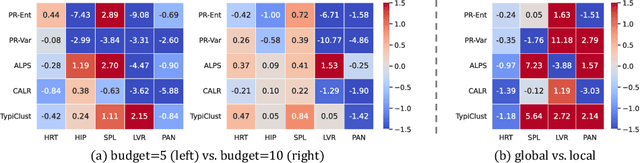
Medical image segmentation is a critical task in medical image analysis. In recent years, deep learning based approaches have shown exceptional performance when trained on a fully-annotated dataset. However, data annotation is often a significant bottleneck, especially for 3D medical images. Active learning (AL) is a promising solution for efficient annotation but requires an initial set of labeled samples to start active selection. When the entire data pool is unlabeled, how do we select the samples to annotate as our initial set? This is also known as the cold-start AL, which permits only one chance to request annotations from experts without access to previously annotated data. Cold-start AL is highly relevant in many practical scenarios but has been under-explored, especially for 3D medical segmentation tasks requiring substantial annotation effort. In this paper, we present a benchmark named COLosSAL by evaluating six cold-start AL strategies on five 3D medical image segmentation tasks from the public Medical Segmentation Decathlon collection. We perform a thorough performance analysis and explore important open questions for cold-start AL, such as the impact of budget on different strategies. Our results show that cold-start AL is still an unsolved problem for 3D segmentation tasks but some important trends have been observed. The code repository, data partitions, and baseline results for the complete benchmark are publicly available at https://github.com/MedICL-VU/COLosSAL.
When to Learn What: Model-Adaptive Data Augmentation Curriculum
Sep 09, 2023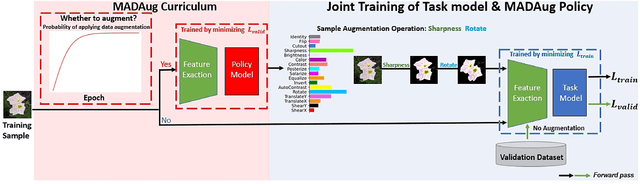
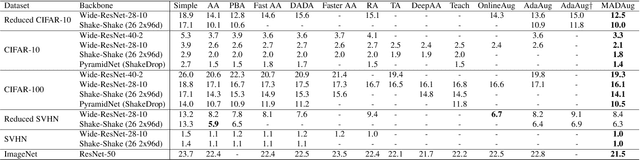

Data augmentation (DA) is widely used to improve the generalization of neural networks by enforcing the invariances and symmetries to pre-defined transformations applied to input data. However, a fixed augmentation policy may have different effects on each sample in different training stages but existing approaches cannot adjust the policy to be adaptive to each sample and the training model. In this paper, we propose Model Adaptive Data Augmentation (MADAug) that jointly trains an augmentation policy network to teach the model when to learn what. Unlike previous work, MADAug selects augmentation operators for each input image by a model-adaptive policy varying between training stages, producing a data augmentation curriculum optimized for better generalization. In MADAug, we train the policy through a bi-level optimization scheme, which aims to minimize a validation-set loss of a model trained using the policy-produced data augmentations. We conduct an extensive evaluation of MADAug on multiple image classification tasks and network architectures with thorough comparisons to existing DA approaches. MADAug outperforms or is on par with other baselines and exhibits better fairness: it brings improvement to all classes and more to the difficult ones. Moreover, MADAug learned policy shows better performance when transferred to fine-grained datasets. In addition, the auto-optimized policy in MADAug gradually introduces increasing perturbations and naturally forms an easy-to-hard curriculum.
Fully $1\times1$ Convolutional Network for Lightweight Image Super-Resolution
Jul 30, 2023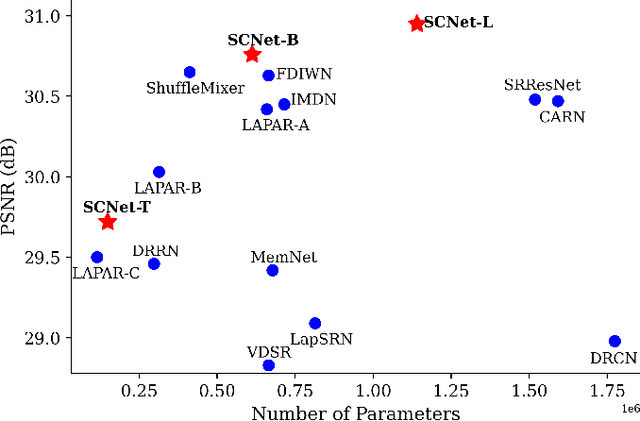
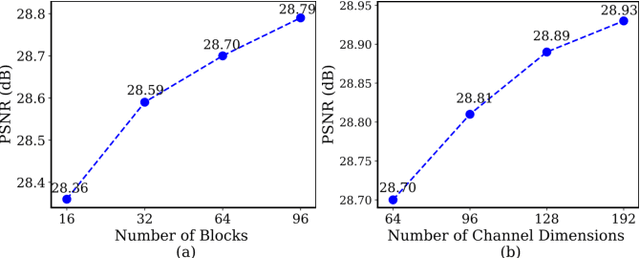
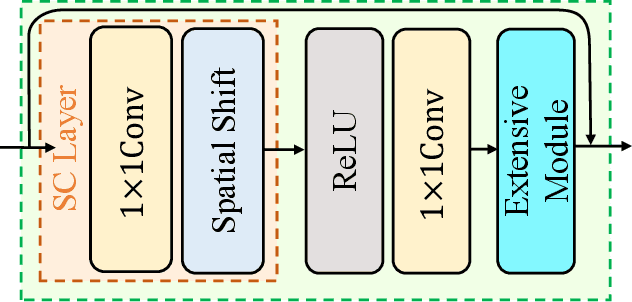
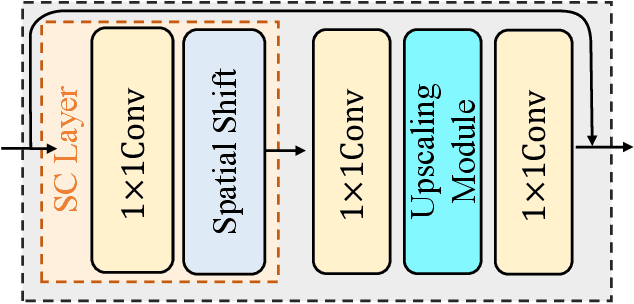
Deep models have achieved significant process on single image super-resolution (SISR) tasks, in particular large models with large kernel ($3\times3$ or more). However, the heavy computational footprint of such models prevents their deployment in real-time, resource-constrained environments. Conversely, $1\times1$ convolutions bring substantial computational efficiency, but struggle with aggregating local spatial representations, an essential capability to SISR models. In response to this dichotomy, we propose to harmonize the merits of both $3\times3$ and $1\times1$ kernels, and exploit a great potential for lightweight SISR tasks. Specifically, we propose a simple yet effective fully $1\times1$ convolutional network, named Shift-Conv-based Network (SCNet). By incorporating a parameter-free spatial-shift operation, it equips the fully $1\times1$ convolutional network with powerful representation capability while impressive computational efficiency. Extensive experiments demonstrate that SCNets, despite its fully $1\times1$ convolutional structure, consistently matches or even surpasses the performance of existing lightweight SR models that employ regular convolutions.
INCEPTNET: Precise And Early Disease Detection Application For Medical Images Analyses
Sep 05, 2023

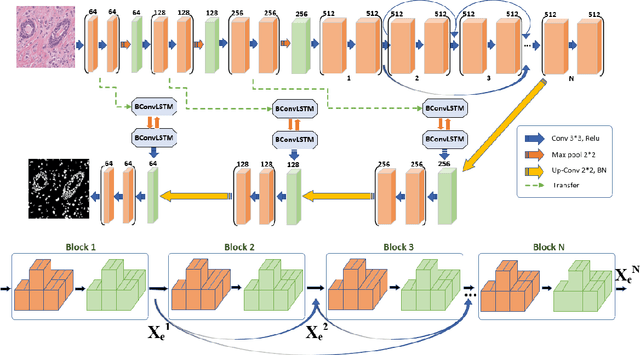
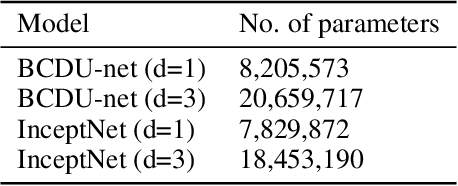
In view of the recent paradigm shift in deep AI based image processing methods, medical image processing has advanced considerably. In this study, we propose a novel deep neural network (DNN), entitled InceptNet, in the scope of medical image processing, for early disease detection and segmentation of medical images in order to enhance precision and performance. We also investigate the interaction of users with the InceptNet application to present a comprehensive application including the background processes, and foreground interactions with users. Fast InceptNet is shaped by the prominent Unet architecture, and it seizes the power of an Inception module to be fast and cost effective while aiming to approximate an optimal local sparse structure. Adding Inception modules with various parallel kernel sizes can improve the network's ability to capture the variations in the scaled regions of interest. To experiment, the model is tested on four benchmark datasets, including retina blood vessel segmentation, lung nodule segmentation, skin lesion segmentation, and breast cancer cell detection. The improvement was more significant on images with small scale structures. The proposed method improved the accuracy from 0.9531, 0.8900, 0.9872, and 0.9881 to 0.9555, 0.9510, 0.9945, and 0.9945 on the mentioned datasets, respectively, which show outperforming of the proposed method over the previous works. Furthermore, by exploring the procedure from start to end, individuals who have utilized a trial edition of InceptNet, in the form of a complete application, are presented with thirteen multiple choice questions in order to assess the proposed method. The outcomes are evaluated through the means of Human Computer Interaction.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023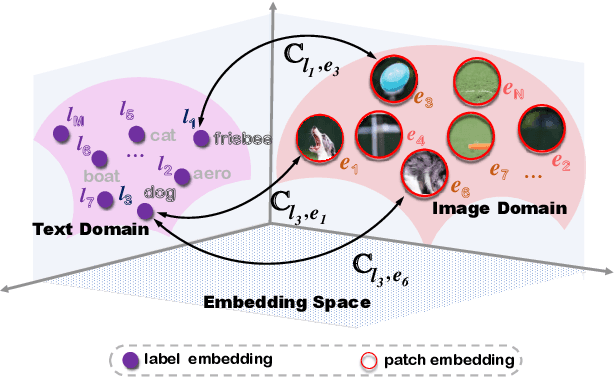
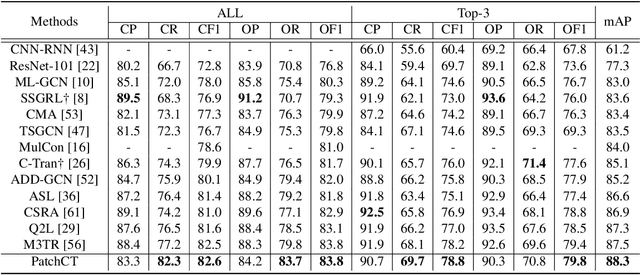
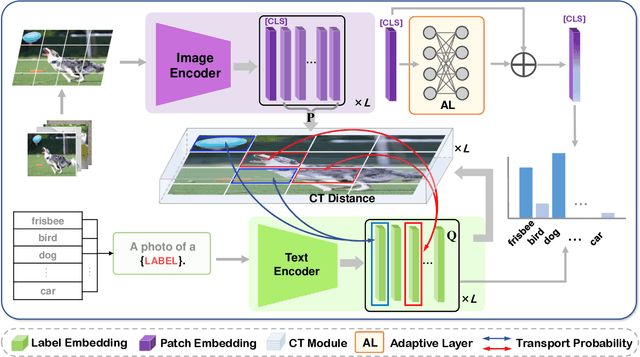
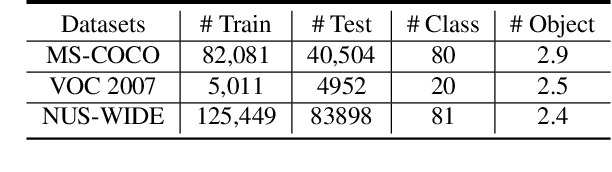
Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
Multi-Stain Self-Attention Graph Multiple Instance Learning Pipeline for Histopathology Whole Slide Images
Sep 19, 2023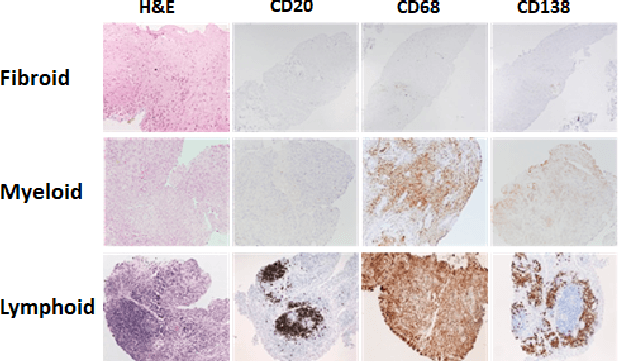


Whole Slide Images (WSIs) present a challenging computer vision task due to their gigapixel size and presence of numerous artefacts. Yet they are a valuable resource for patient diagnosis and stratification, often representing the gold standard for diagnostic tasks. Real-world clinical datasets tend to come as sets of heterogeneous WSIs with labels present at the patient-level, with poor to no annotations. Weakly supervised attention-based multiple instance learning approaches have been developed in recent years to address these challenges, but can fail to resolve both long and short-range dependencies. Here we propose an end-to-end multi-stain self-attention graph (MUSTANG) multiple instance learning pipeline, which is designed to solve a weakly-supervised gigapixel multi-image classification task, where the label is assigned at the patient-level, but no slide-level labels or region annotations are available. The pipeline uses a self-attention based approach by restricting the operations to a highly sparse k-Nearest Neighbour Graph of embedded WSI patches based on the Euclidean distance. We show this approach achieves a state-of-the-art F1-score/AUC of 0.89/0.92, outperforming the widely used CLAM model. Our approach is highly modular and can easily be modified to suit different clinical datasets, as it only requires a patient-level label without annotations and accepts WSI sets of different sizes, as the graphs can be of varying sizes and structures. The source code can be found at https://github.com/AmayaGS/MUSTANG.
DRM-IR: Task-Adaptive Deep Unfolding Network for All-In-One Image Restoration
Jul 15, 2023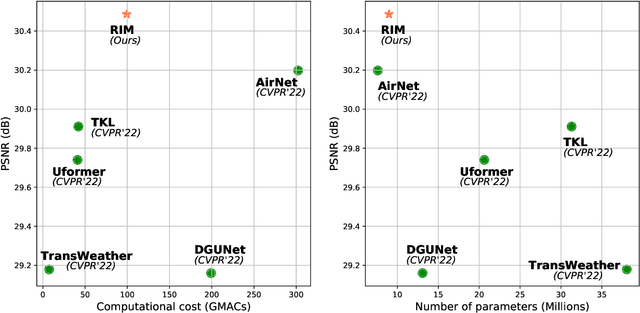
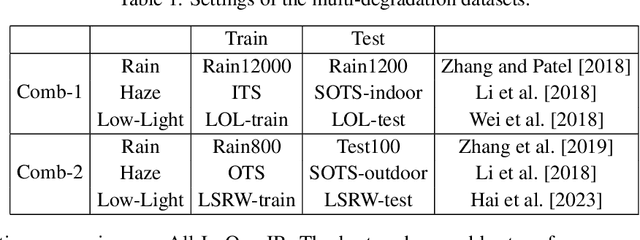
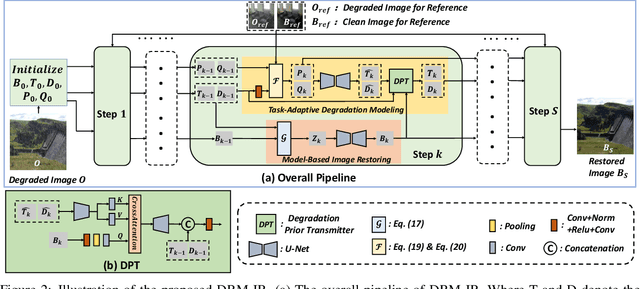
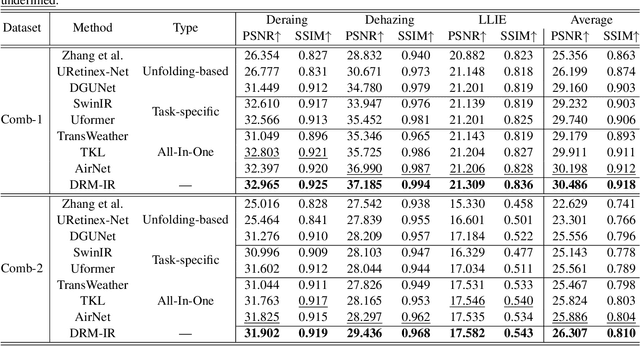
Existing All-In-One image restoration (IR) methods usually lack flexible modeling on various types of degradation, thus impeding the restoration performance. To achieve All-In-One IR with higher task dexterity, this work proposes an efficient Dynamic Reference Modeling paradigm (DRM-IR), which consists of task-adaptive degradation modeling and model-based image restoring. Specifically, these two subtasks are formalized as a pair of entangled reference-based maximum a posteriori (MAP) inferences, which are optimized synchronously in an unfolding-based manner. With the two cascaded subtasks, DRM-IR first dynamically models the task-specific degradation based on a reference image pair and further restores the image with the collected degradation statistics. Besides, to bridge the semantic gap between the reference and target degraded images, we further devise a Degradation Prior Transmitter (DPT) that restrains the instance-specific feature differences. DRM-IR explicitly provides superior flexibility for All-in-One IR while being interpretable. Extensive experiments on multiple benchmark datasets show that our DRM-IR achieves state-of-the-art in All-In-One IR.
Revisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023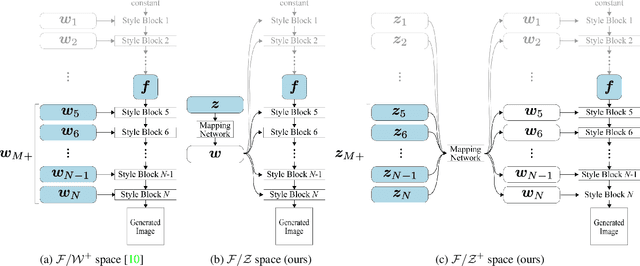


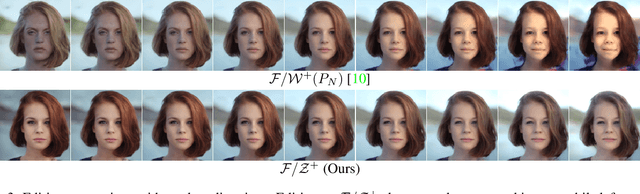
The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
Socratis: Are large multimodal models emotionally aware?
Aug 31, 2023

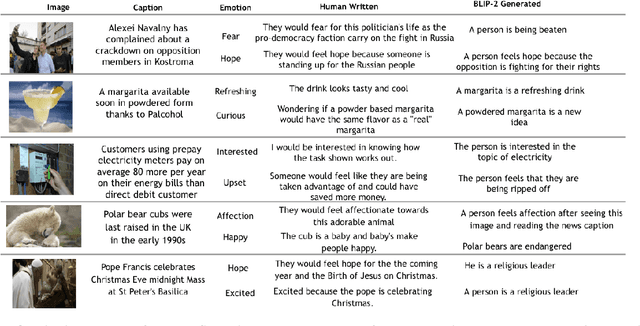
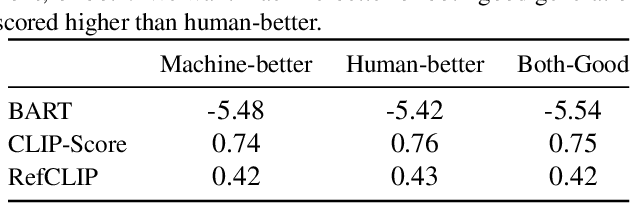
Existing emotion prediction benchmarks contain coarse emotion labels which do not consider the diversity of emotions that an image and text can elicit in humans due to various reasons. Learning diverse reactions to multimodal content is important as intelligent machines take a central role in generating and delivering content to society. To address this gap, we propose Socratis, a \underline{soc}ietal \underline{r}e\underline{a}c\underline{ti}on\underline{s} benchmark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. This shows our task is harder than standard generation tasks because it starkly contrasts recent findings where humans cannot tell apart machine vs human-written news articles, for instance. We further see that current captioning metrics based on large vision-language models also fail to correlate with human preferences. We hope that these findings and our benchmark will inspire further research on training emotionally aware models.