 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"3d Object Reconstruction From A Single Image": models, code, and papers
TMO: Textured Mesh Acquisition of Objects with a Mobile Device by using Differentiable Rendering
Mar 27, 2023

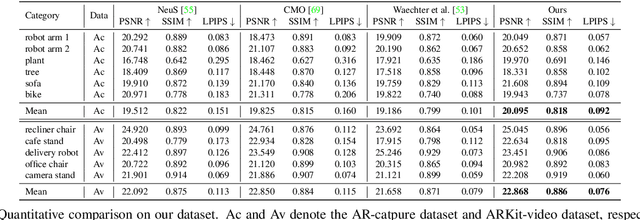


We present a new pipeline for acquiring a textured mesh in the wild with a single smartphone which offers access to images, depth maps, and valid poses. Our method first introduces an RGBD-aided structure from motion, which can yield filtered depth maps and refines camera poses guided by corresponding depth. Then, we adopt the neural implicit surface reconstruction method, which allows for high-quality mesh and develops a new training process for applying a regularization provided by classical multi-view stereo methods. Moreover, we apply a differentiable rendering to fine-tune incomplete texture maps and generate textures which are perceptually closer to the original scene. Our pipeline can be applied to any common objects in the real world without the need for either in-the-lab environments or accurate mask images. We demonstrate results of captured objects with complex shapes and validate our method numerically against existing 3D reconstruction and texture mapping methods.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
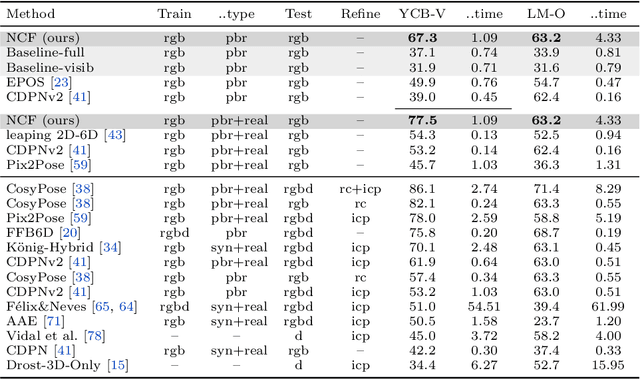
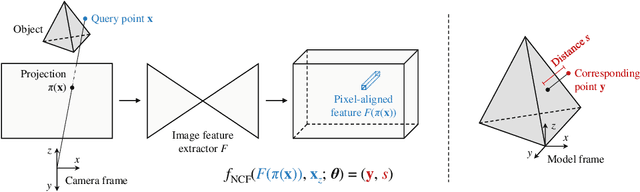
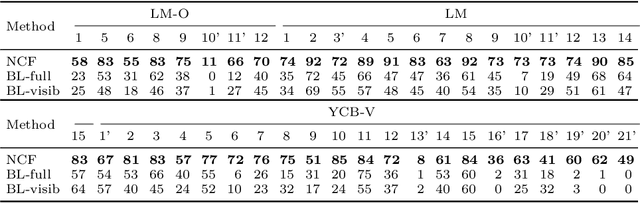
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
Pix2NeRF: Unsupervised Conditional $π$-GAN for Single Image to Neural Radiance Fields Translation
Feb 26, 2022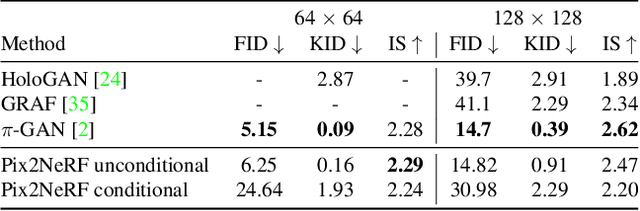
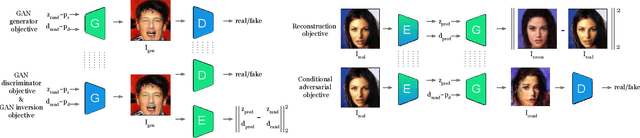
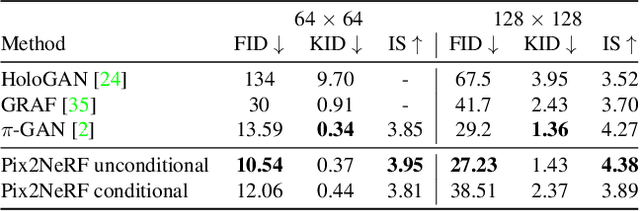

We propose a pipeline to generate Neural Radiance Fields~(NeRF) of an object or a scene of a specific class, conditioned on a single input image. This is a challenging task, as training NeRF requires multiple views of the same scene, coupled with corresponding poses, which are hard to obtain. Our method is based on $\pi$-GAN, a generative model for unconditional 3D-aware image synthesis, which maps random latent codes to radiance fields of a class of objects. We jointly optimize (1) the $\pi$-GAN objective to utilize its high-fidelity 3D-aware generation and (2) a carefully designed reconstruction objective. The latter includes an encoder coupled with $\pi$-GAN generator to form an auto-encoder. Unlike previous few-shot NeRF approaches, our pipeline is unsupervised, capable of being trained with independent images without 3D, multi-view, or pose supervision. Applications of our pipeline include 3d avatar generation, object-centric novel view synthesis with a single input image, and 3d-aware super-resolution, to name a few.
XDGAN: Multi-Modal 3D Shape Generation in 2D Space
Oct 06, 2022

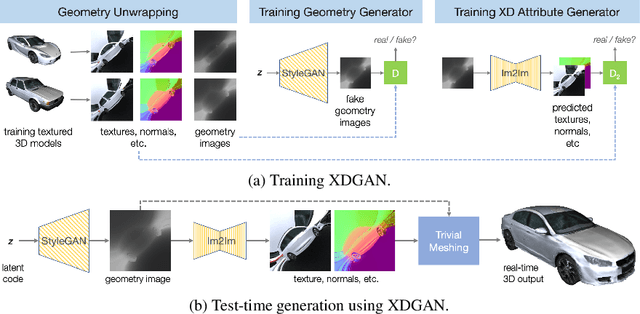
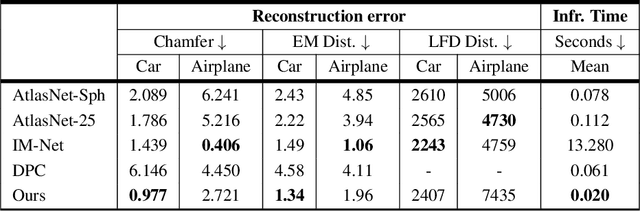
Generative models for 2D images has recently seen tremendous progress in quality, resolution and speed as a result of the efficiency of 2D convolutional architectures. However it is difficult to extend this progress into the 3D domain since most current 3D representations rely on custom network components. This paper addresses a central question: Is it possible to directly leverage 2D image generative models to generate 3D shapes instead? To answer this, we propose XDGAN, an effective and fast method for applying 2D image GAN architectures to the generation of 3D object geometry combined with additional surface attributes, like color textures and normals. Specifically, we propose a novel method to convert 3D shapes into compact 1-channel geometry images and leverage StyleGAN3 and image-to-image translation networks to generate 3D objects in 2D space. The generated geometry images are quick to convert to 3D meshes, enabling real-time 3D object synthesis, visualization and interactive editing. Moreover, the use of standard 2D architectures can help bring more 2D advances into the 3D realm. We show both quantitatively and qualitatively that our method is highly effective at various tasks such as 3D shape generation, single view reconstruction and shape manipulation, while being significantly faster and more flexible compared to recent 3D generative models.
TEXTure: Text-Guided Texturing of 3D Shapes
Feb 03, 2023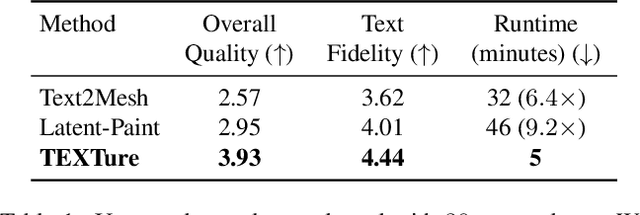


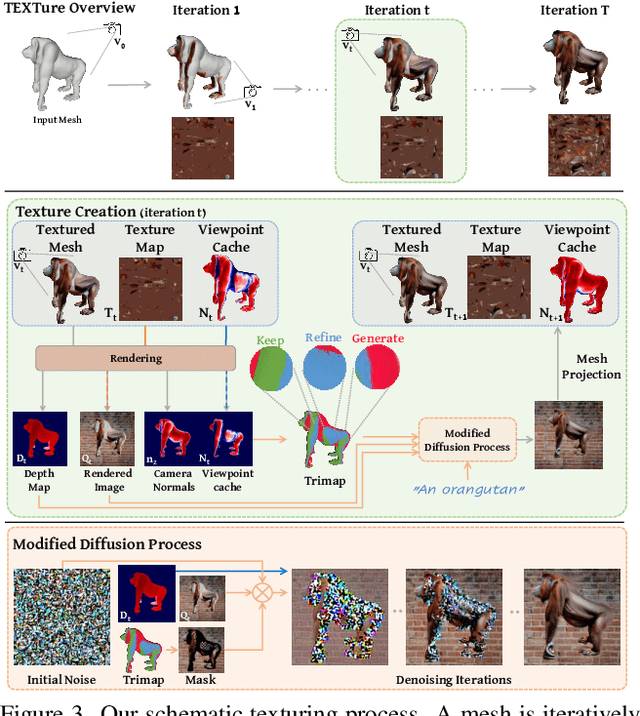
In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing.
FingerSLAM: Closed-loop Unknown Object Localization and Reconstruction from Visuo-tactile Feedback
Mar 14, 2023
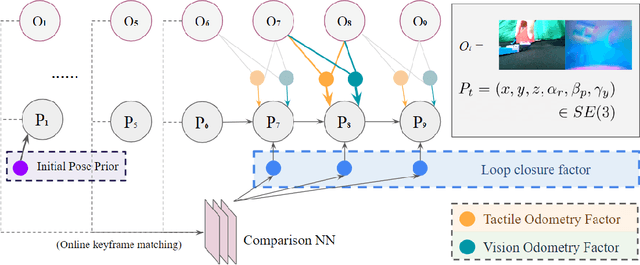
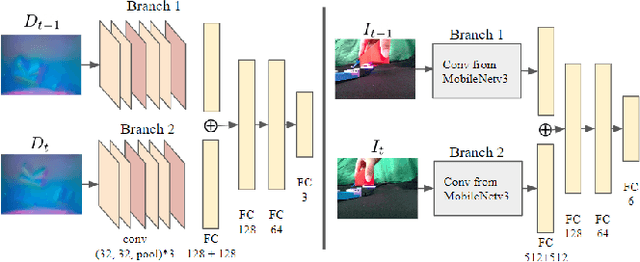
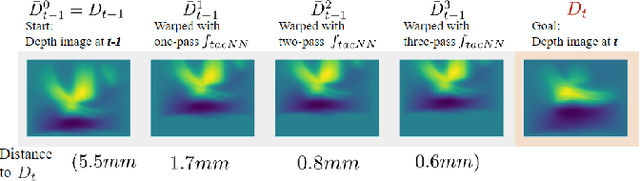
In this paper, we address the problem of using visuo-tactile feedback for 6-DoF localization and 3D reconstruction of unknown in-hand objects. We propose FingerSLAM, a closed-loop factor graph-based pose estimator that combines local tactile sensing at finger-tip and global vision sensing from a wrist-mount camera. FingerSLAM is constructed with two constituent pose estimators: a multi-pass refined tactile-based pose estimator that captures movements from detailed local textures, and a single-pass vision-based pose estimator that predicts from a global view of the object. We also design a loop closure mechanism that actively matches current vision and tactile images to previously stored key-frames to reduce accumulated error. FingerSLAM incorporates the two sensing modalities of tactile and vision, as well as the loop closure mechanism with a factor graph-based optimization framework. Such a framework produces an optimized pose estimation solution that is more accurate than the standalone estimators. The estimated poses are then used to reconstruct the shape of the unknown object incrementally by stitching the local point clouds recovered from tactile images. We train our system on real-world data collected with 20 objects. We demonstrate reliable visuo-tactile pose estimation and shape reconstruction through quantitative and qualitative real-world evaluations on 6 objects that are unseen during training.
An Interactive Image-based Modeling System
Mar 28, 2022


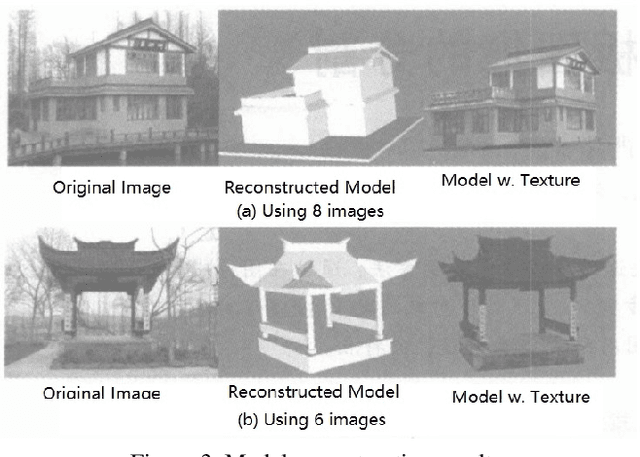
This paper propose a interactive 3D modeling method and corresponding system based on single or multiple uncalibrated images. The main feature of this method is that, according to the modeling habits of ordinary people, the 3D model of the target is reconstructed from coarse to fine images. On the basis of determining the approximate shape, the user adds or modify projection constraints and spatial constraints, and apply topology modification, gradually realize camera calibration, refine rough model, and finally complete the reconstruction of objects with arbitrary geometry and topology. During the interactive process, the geometric parameters and camera projection matrix are solved in real time, and the reconstruction results are displayed in a 3D window.
Dehazing-NeRF: Neural Radiance Fields from Hazy Images
Apr 22, 2023

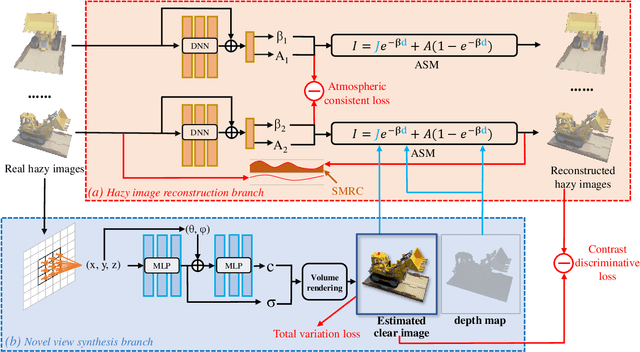

Neural Radiance Field (NeRF) has received much attention in recent years due to the impressively high quality in 3D scene reconstruction and novel view synthesis. However, image degradation caused by the scattering of atmospheric light and object light by particles in the atmosphere can significantly decrease the reconstruction quality when shooting scenes in hazy conditions. To address this issue, we propose Dehazing-NeRF, a method that can recover clear NeRF from hazy image inputs. Our method simulates the physical imaging process of hazy images using an atmospheric scattering model, and jointly learns the atmospheric scattering model and a clean NeRF model for both image dehazing and novel view synthesis. Different from previous approaches, Dehazing-NeRF is an unsupervised method with only hazy images as the input, and also does not rely on hand-designed dehazing priors. By jointly combining the depth estimated from the NeRF 3D scene with the atmospheric scattering model, our proposed model breaks through the ill-posed problem of single-image dehazing while maintaining geometric consistency. Besides, to alleviate the degradation of image quality caused by information loss, soft margin consistency regularization, as well as atmospheric consistency and contrast discriminative loss, are addressed during the model training process. Extensive experiments demonstrate that our method outperforms the simple combination of single-image dehazing and NeRF on both image dehazing and novel view image synthesis.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 22, 2022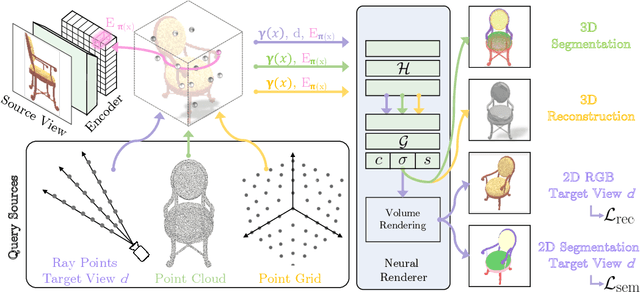


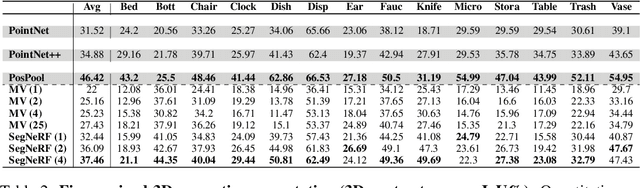
Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation. In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
Enhance-NeRF: Multiple Performance Evaluation for Neural Radiance Fields
Jun 08, 2023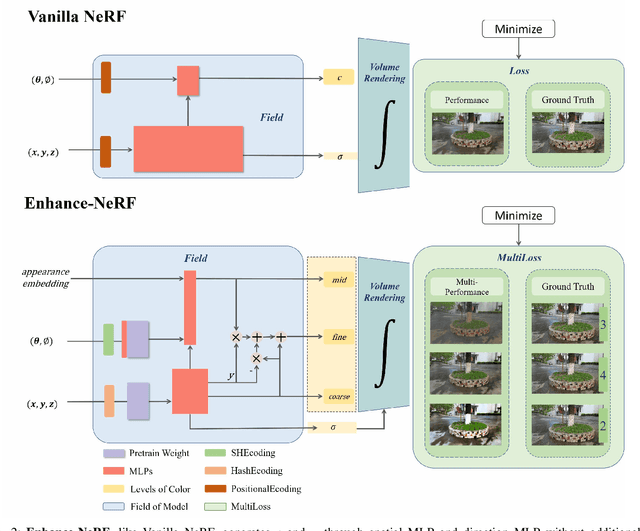



The quality of three-dimensional reconstruction is a key factor affecting the effectiveness of its application in areas such as virtual reality (VR) and augmented reality (AR) technologies. Neural Radiance Fields (NeRF) can generate realistic images from any viewpoint. It simultaneously reconstructs the shape, lighting, and materials of objects, and without surface defects, which breaks down the barrier between virtuality and reality. The potential spatial correspondences displayed by NeRF between reconstructed scenes and real-world scenes offer a wide range of practical applications possibilities. Despite significant progress in 3D reconstruction since NeRF were introduced, there remains considerable room for exploration and experimentation. NeRF-based models are susceptible to interference issues caused by colored "fog" noise. Additionally, they frequently encounter instabilities and failures while attempting to reconstruct unbounded scenes. Moreover, the model takes a significant amount of time to converge, making it even more challenging to use in such scenarios. Our approach, coined Enhance-NeRF, which adopts joint color to balance low and high reflectivity objects display, utilizes a decoding architecture with prior knowledge to improve recognition, and employs multi-layer performance evaluation mechanisms to enhance learning capacity. It achieves reconstruction of outdoor scenes within one hour under single-card condition. Based on experimental results, Enhance-NeRF partially enhances fitness capability and provides some support to outdoor scene reconstruction. The Enhance-NeRF method can be used as a plug-and-play component, making it easy to integrate with other NeRF-based models. The code is available at: https://github.com/TANQIanQ/Enhance-NeRF