 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabrica: Dual-Arm Assembly of General Multi-Part Objects via Integrated Planning and Learning
Jun 05, 2025Multi-part assembly poses significant challenges for robots to execute long-horizon, contact-rich manipulation with generalization across complex geometries. We present Fabrica, a dual-arm robotic system capable of end-to-end planning and control for autonomous assembly of general multi-part objects. For planning over long horizons, we develop hierarchies of precedence, sequence, grasp, and motion planning with automated fixture generation, enabling general multi-step assembly on any dual-arm robots. The planner is made efficient through a parallelizable design and is optimized for downstream control stability. For contact-rich assembly steps, we propose a lightweight reinforcement learning framework that trains generalist policies across object geometries, assembly directions, and grasp poses, guided by equivariance and residual actions obtained from the plan. These policies transfer zero-shot to the real world and achieve 80% successful steps. For systematic evaluation, we propose a benchmark suite of multi-part assemblies resembling industrial and daily objects across diverse categories and geometries. By integrating efficient global planning and robust local control, we showcase the first system to achieve complete and generalizable real-world multi-part assembly without domain knowledge or human demonstrations. Project website: http://fabrica.csail.mit.edu/
PolyTouch: A Robust Multi-Modal Tactile Sensor for Contact-rich Manipulation Using Tactile-Diffusion Policies
Apr 27, 2025Achieving robust dexterous manipulation in unstructured domestic environments remains a significant challenge in robotics. Even with state-of-the-art robot learning methods, haptic-oblivious control strategies (i.e. those relying only on external vision and/or proprioception) often fall short due to occlusions, visual complexities, and the need for precise contact interaction control. To address these limitations, we introduce PolyTouch, a novel robot finger that integrates camera-based tactile sensing, acoustic sensing, and peripheral visual sensing into a single design that is compact and durable. PolyTouch provides high-resolution tactile feedback across multiple temporal scales, which is essential for efficiently learning complex manipulation tasks. Experiments demonstrate an at least 20-fold increase in lifespan over commercial tactile sensors, with a design that is both easy to manufacture and scalable. We then use this multi-modal tactile feedback along with visuo-proprioceptive observations to synthesize a tactile-diffusion policy from human demonstrations; the resulting contact-aware control policy significantly outperforms haptic-oblivious policies in multiple contact-aware manipulation policies. This paper highlights how effectively integrating multi-modal contact sensing can hasten the development of effective contact-aware manipulation policies, paving the way for more reliable and versatile domestic robots. More information can be found at https://polytouch.alanz.info/
Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers
Sep 30, 2024



One of the roadblocks for training generalist robotic models today is heterogeneity. Previous robot learning methods often collect data to train with one specific embodiment for one task, which is expensive and prone to overfitting. This work studies the problem of learning policy representations through heterogeneous pre-training on robot data across different embodiments and tasks at scale. We propose Heterogeneous Pre-trained Transformers (HPT), which pre-train a large, shareable trunk of a policy neural network to learn a task and embodiment agnostic shared representation. This general architecture aligns the specific proprioception and vision inputs from distinct embodiments to a short sequence of tokens and then processes such tokens to map to control robots for different tasks. Leveraging the recent large-scale multi-embodiment real-world robotic datasets as well as simulation, deployed robots, and human video datasets, we investigate pre-training policies across heterogeneity. We conduct experiments to investigate the scaling behaviors of training objectives, to the extent of 52 datasets. HPTs outperform several baselines and enhance the fine-tuned policy performance by over 20% on unseen tasks in multiple simulator benchmarks and real-world settings. See the project website (https://liruiw.github.io/hpt/) for code and videos.
* See the project website (https://liruiw.github.io/hpt/) for code and videos
Transferable Tactile Transformers for Representation Learning Across Diverse Sensors and Tasks
Jun 19, 2024



This paper presents T3: Transferable Tactile Transformers, a framework for tactile representation learning that scales across multi-sensors and multi-tasks. T3 is designed to overcome the contemporary issue that camera-based tactile sensing is extremely heterogeneous, i.e. sensors are built into different form factors, and existing datasets were collected for disparate tasks. T3 captures the shared latent information across different sensor-task pairings by constructing a shared trunk transformer with sensor-specific encoders and task-specific decoders. The pre-training of T3 utilizes a novel Foundation Tactile (FoTa) dataset, which is aggregated from several open-sourced datasets and it contains over 3 million data points gathered from 13 sensors and 11 tasks. FoTa is the largest and most diverse dataset in tactile sensing to date and it is made publicly available in a unified format. Across various sensors and tasks, experiments show that T3 pre-trained with FoTa achieved zero-shot transferability in certain sensor-task pairings, can be further fine-tuned with small amounts of domain-specific data, and its performance scales with bigger network sizes. T3 is also effective as a tactile encoder for long horizon contact-rich manipulation. Results from sub-millimeter multi-pin electronics insertion tasks show that T3 achieved a task success rate 25% higher than that of policies trained with tactile encoders trained from scratch, or 53% higher than without tactile sensing. Data, code, and model checkpoints are open-sourced at https://t3.alanz.info.
GelLink: A Compact Multi-phalanx Finger with Vision-based Tactile Sensing and Proprioception
Mar 25, 2024



Compared to fully-actuated robotic end-effectors, underactuated ones are generally more adaptive, robust, and cost-effective. However, state estimation for underactuated hands is usually more challenging. Vision-based tactile sensors, like Gelsight, can mitigate this issue by providing high-resolution tactile sensing and accurate proprioceptive sensing. As such, we present GelLink, a compact, underactuated, linkage-driven robotic finger with low-cost, high-resolution vision-based tactile sensing and proprioceptive sensing capabilities. In order to reduce the amount of embedded hardware, i.e. the cameras and motors, we optimize the linkage transmission with a planar linkage mechanism simulator and develop a planar reflection simulator to simplify the tactile sensing hardware. As a result, GelLink only requires one motor to actuate the three phalanges, and one camera to capture tactile signals along the entire finger. Overall, GelLink is a compact robotic finger that shows adaptability and robustness when performing grasping tasks. The integration of vision-based tactile sensors can significantly enhance the capabilities of underactuated fingers and potentially broaden their future usage.
PoCo: Policy Composition from and for Heterogeneous Robot Learning
Feb 04, 2024



Training general robotic policies from heterogeneous data for different tasks is a significant challenge. Existing robotic datasets vary in different modalities such as color, depth, tactile, and proprioceptive information, and collected in different domains such as simulation, real robots, and human videos. Current methods usually collect and pool all data from one domain to train a single policy to handle such heterogeneity in tasks and domains, which is prohibitively expensive and difficult. In this work, we present a flexible approach, dubbed Policy Composition, to combine information across such diverse modalities and domains for learning scene-level and task-level generalized manipulation skills, by composing different data distributions represented with diffusion models. Our method can use task-level composition for multi-task manipulation and be composed with analytic cost functions to adapt policy behaviors at inference time. We train our method on simulation, human, and real robot data and evaluate in tool-use tasks. The composed policy achieves robust and dexterous performance under varying scenes and tasks and outperforms baselines from a single data source in both simulation and real-world experiments. See https://liruiw.github.io/policycomp for more details .
GelSight Svelte Hand: A Three-finger, Two-DoF, Tactile-rich, Low-cost Robot Hand for Dexterous Manipulation
Sep 19, 2023



This paper presents GelSight Svelte Hand, a novel 3-finger 2-DoF tactile robotic hand that is capable of performing precision grasps, power grasps, and intermediate grasps. Rich tactile signals are obtained from one camera on each finger, with an extended sensing area similar to the full length of a human finger. Each finger of GelSight Svelte Hand is supported by a semi-rigid endoskeleton and covered with soft silicone materials, which provide both rigidity and compliance. We describe the design, fabrication, functionalities, and tactile sensing capability of GelSight Svelte Hand in this paper. More information is available on our website: \url{https://gelsight-svelte.alanz.info}.
GelSight Svelte: A Human Finger-shaped Single-camera Tactile Robot Finger with Large Sensing Coverage and Proprioceptive Sensing
Sep 19, 2023



Camera-based tactile sensing is a low-cost, popular approach to obtain highly detailed contact geometry information. However, most existing camera-based tactile sensors are fingertip sensors, and longer fingers often require extraneous elements to obtain an extended sensing area similar to the full length of a human finger. Moreover, existing methods to estimate proprioceptive information such as total forces and torques applied on the finger from camera-based tactile sensors are not effective when the contact geometry is complex. We introduce GelSight Svelte, a curved, human finger-sized, single-camera tactile sensor that is capable of both tactile and proprioceptive sensing over a large area. GelSight Svelte uses curved mirrors to achieve the desired shape and sensing coverage. Proprioceptive information, such as the total bending and twisting torques applied on the finger, is reflected as deformations on the flexible backbone of GelSight Svelte, which are also captured by the camera. We train a convolutional neural network to estimate the bending and twisting torques from the captured images. We conduct gel deformation experiments at various locations of the finger to evaluate the tactile sensing capability and proprioceptive sensing accuracy. To demonstrate the capability and potential uses of GelSight Svelte, we conduct an object holding task with three different grasping modes that utilize different areas of the finger. More information is available on our website: https://gelsight-svelte.alanz.info
FingerSLAM: Closed-loop Unknown Object Localization and Reconstruction from Visuo-tactile Feedback
Mar 14, 2023



In this paper, we address the problem of using visuo-tactile feedback for 6-DoF localization and 3D reconstruction of unknown in-hand objects. We propose FingerSLAM, a closed-loop factor graph-based pose estimator that combines local tactile sensing at finger-tip and global vision sensing from a wrist-mount camera. FingerSLAM is constructed with two constituent pose estimators: a multi-pass refined tactile-based pose estimator that captures movements from detailed local textures, and a single-pass vision-based pose estimator that predicts from a global view of the object. We also design a loop closure mechanism that actively matches current vision and tactile images to previously stored key-frames to reduce accumulated error. FingerSLAM incorporates the two sensing modalities of tactile and vision, as well as the loop closure mechanism with a factor graph-based optimization framework. Such a framework produces an optimized pose estimation solution that is more accurate than the standalone estimators. The estimated poses are then used to reconstruct the shape of the unknown object incrementally by stitching the local point clouds recovered from tactile images. We train our system on real-world data collected with 20 objects. We demonstrate reliable visuo-tactile pose estimation and shape reconstruction through quantitative and qualitative real-world evaluations on 6 objects that are unseen during training.
Causal Reasoning in Simulation for Structure and Transfer Learning of Robot Manipulation Policies
Mar 31, 2021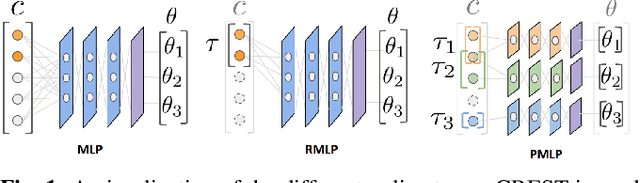
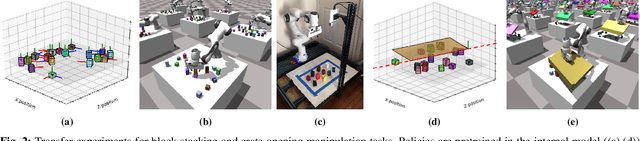
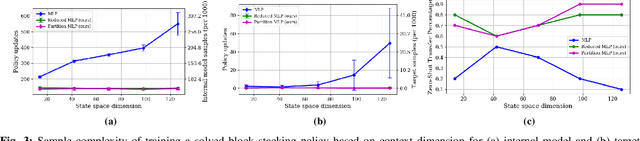
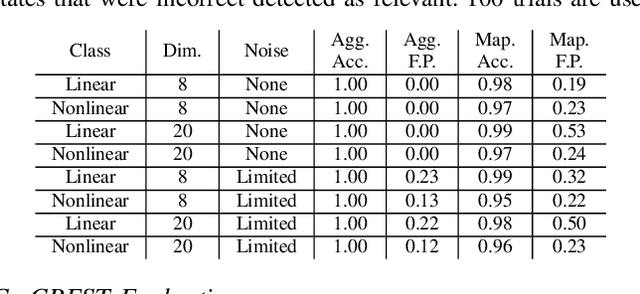
We present CREST, an approach for causal reasoning in simulation to learn the relevant state space for a robot manipulation policy. Our approach conducts interventions using internal models, which are simulations with approximate dynamics and simplified assumptions. These interventions elicit the structure between the state and action spaces, enabling construction of neural network policies with only relevant states as input. These policies are pretrained using the internal model with domain randomization over the relevant states. The policy network weights are then transferred to the target domain (e.g., the real world) for fine tuning. We perform extensive policy transfer experiments in simulation for two representative manipulation tasks: block stacking and crate opening. Our policies are shown to be more robust to domain shifts, more sample efficient to learn, and scale to more complex settings with larger state spaces. We also show improved zero-shot sim-to-real transfer of our policies for the block stacking task.