 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Source Separation
Music source separation is the process of separating individual sound sources from a mixed audio signal.
Papers and Code
PolyLingua: Margin-based Inter-class Transformer for Robust Cross-domain Language Detection
Dec 10, 2025Language identification is a crucial first step in multilingual systems such as chatbots and virtual assistants, enabling linguistically and culturally accurate user experiences. Errors at this stage can cascade into downstream failures, setting a high bar for accuracy. Yet, existing language identification tools struggle with key cases -- such as music requests where the song title and user language differ. Open-source tools like LangDetect, FastText are fast but less accurate, while large language models, though effective, are often too costly for low-latency or low-resource settings. We introduce PolyLingua, a lightweight Transformer-based model for in-domain language detection and fine-grained language classification. It employs a two-level contrastive learning framework combining instance-level separation and class-level alignment with adaptive margins, yielding compact and well-separated embeddings even for closely related languages. Evaluated on two challenging datasets -- Amazon Massive (multilingual digital assistant utterances) and a Song dataset (music requests with frequent code-switching) -- PolyLingua achieves 99.25% F1 and 98.15% F1, respectively, surpassing Sonnet 3.5 while using 10x fewer parameters, making it ideal for compute- and latency-constrained environments.
R2-SVC: Towards Real-World Robust and Expressive Zero-shot Singing Voice Conversion
Oct 23, 2025In real-world singing voice conversion (SVC) applications, environmental noise and the demand for expressive output pose significant challenges. Conventional methods, however, are typically designed without accounting for real deployment scenarios, as both training and inference usually rely on clean data. This mismatch hinders practical use, given the inevitable presence of diverse noise sources and artifacts from music separation. To tackle these issues, we propose R2-SVC, a robust and expressive SVC framework. First, we introduce simulation-based robustness enhancement through random fundamental frequency ($F_0$) perturbations and music separation artifact simulations (e.g., reverberation, echo), substantially improving performance under noisy conditions. Second, we enrich speaker representation using domain-specific singing data: alongside clean vocals, we incorporate DNSMOS-filtered separated vocals and public singing corpora, enabling the model to preserve speaker timbre while capturing singing style nuances. Third, we integrate the Neural Source-Filter (NSF) model to explicitly represent harmonic and noise components, enhancing the naturalness and controllability of converted singing. R2-SVC achieves state-of-the-art results on multiple SVC benchmarks under both clean and noisy conditions.
Source Separation for A Cappella Music
Sep 30, 2025



In this work, we study the task of multi-singer separation in a cappella music, where the number of active singers varies across mixtures. To address this, we use a power set-based data augmentation strategy that expands limited multi-singer datasets into exponentially more training samples. To separate singers, we introduce SepACap, an adaptation of SepReformer, a state-of-the-art speaker separation model architecture. We adapt the model with periodic activations and a composite loss function that remains effective when stems are silent, enabling robust detection and separation. Experiments on the JaCappella dataset demonstrate that our approach achieves state-of-the-art performance in both full-ensemble and subset singer separation scenarios, outperforming spectrogram-based baselines while generalizing to realistic mixtures with varying numbers of singers.
Mamba2 Meets Silence: Robust Vocal Source Separation for Sparse Regions
Aug 20, 2025We introduce a new music source separation model tailored for accurate vocal isolation. Unlike Transformer-based approaches, which often fail to capture intermittently occurring vocals, our model leverages Mamba2, a recent state space model, to better capture long-range temporal dependencies. To handle long input sequences efficiently, we combine a band-splitting strategy with a dual-path architecture. Experiments show that our approach outperforms recent state-of-the-art models, achieving a cSDR of 11.03 dB-the best reported to date-and delivering substantial gains in uSDR. Moreover, the model exhibits stable and consistent performance across varying input lengths and vocal occurrence patterns. These results demonstrate the effectiveness of Mamba-based models for high-resolution audio processing and open up new directions for broader applications in audio research.
TISDiSS: A Training-Time and Inference-Time Scalable Framework for Discriminative Source Separation
Sep 19, 2025Source separation is a fundamental task in speech, music, and audio processing, and it also provides cleaner and larger data for training generative models. However, improving separation performance in practice often depends on increasingly large networks, inflating training and deployment costs. Motivated by recent advances in inference-time scaling for generative modeling, we propose Training-Time and Inference-Time Scalable Discriminative Source Separation (TISDiSS), a unified framework that integrates early-split multi-loss supervision, shared-parameter design, and dynamic inference repetitions. TISDiSS enables flexible speed-performance trade-offs by adjusting inference depth without retraining additional models. We further provide systematic analyses of architectural and training choices and show that training with more inference repetitions improves shallow-inference performance, benefiting low-latency applications. Experiments on standard speech separation benchmarks demonstrate state-of-the-art performance with a reduced parameter count, establishing TISDiSS as a scalable and practical framework for adaptive source separation.
DeePAQ: A Perceptual Audio Quality Metric Based On Foundational Models and Weakly Supervised Learning
Oct 14, 2025This paper presents the Deep learning-based Perceptual Audio Quality metric (DeePAQ) for evaluating general audio quality. Our approach leverages metric learning together with the music foundation model MERT, guided by surrogate labels, to construct an embedding space that captures distortion intensity in general audio. To the best of our knowledge, DeePAQ is the first in the general audio quality domain to leverage weakly supervised labels and metric learning for fine-tuning a music foundation model with Low-Rank Adaptation (LoRA), a direction not yet explored by other state-of-the-art methods. We benchmark the proposed model against state-of-the-art objective audio quality metrics across listening tests spanning audio coding and source separation. Results show that our method surpasses existing metrics in detecting coding artifacts and generalizes well to unseen distortions such as source separation, highlighting its robustness and versatility.
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025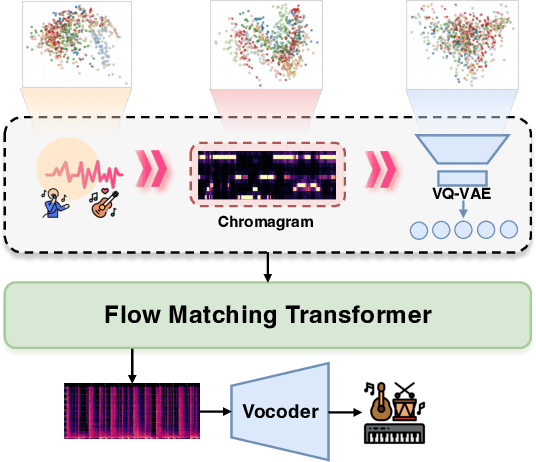
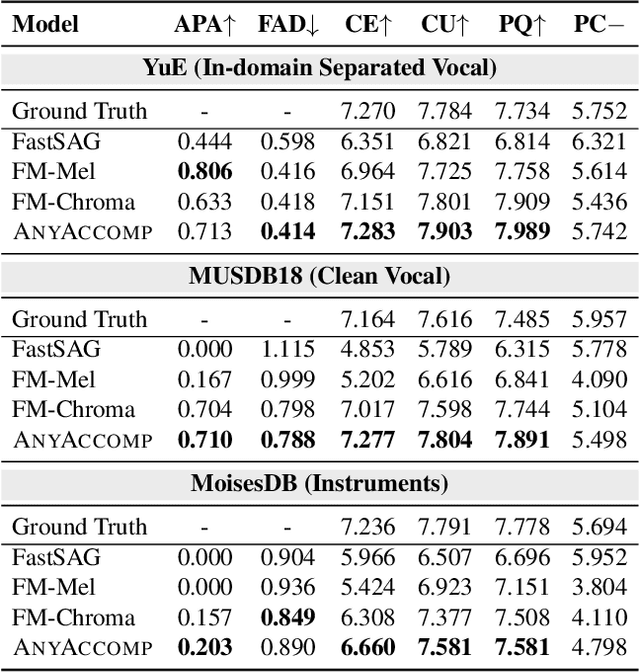
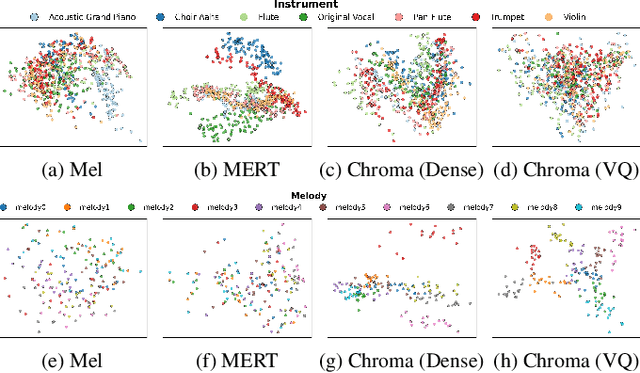
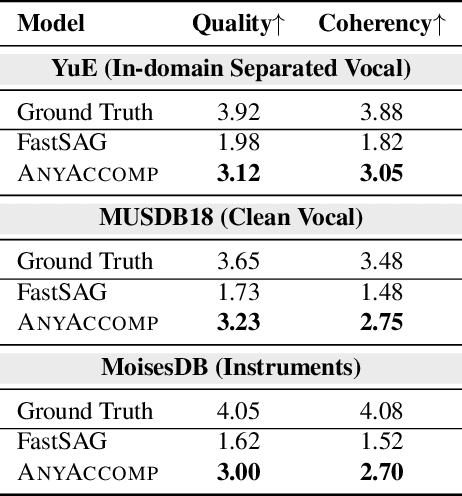
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
Musical Source Separation Bake-Off: Comparing Objective Metrics with Human Perception
Jul 09, 2025Music source separation aims to extract individual sound sources (e.g., vocals, drums, guitar) from a mixed music recording. However, evaluating the quality of separated audio remains challenging, as commonly used metrics like the source-to-distortion ratio (SDR) do not always align with human perception. In this study, we conducted a large-scale listener evaluation on the MUSDB18 test set, collecting approximately 30 ratings per track from seven distinct listener groups. We compared several objective energy-ratio metrics, including legacy measures (BSSEval v4, SI-SDR variants), and embedding-based alternatives (Frechet Audio Distance using CLAP-LAION-music, EnCodec, VGGish, Wave2Vec2, and HuBERT). While SDR remains the best-performing metric for vocal estimates, our results show that the scale-invariant signal-to-artifacts ratio (SI-SAR) better predicts listener ratings for drums and bass stems. Frechet Audio Distance (FAD) computed with the CLAP-LAION-music embedding also performs competitively--achieving Kendall's tau values of 0.25 for drums and 0.19 for bass--matching or surpassing energy-based metrics for those stems. However, none of the embedding-based metrics, including CLAP, correlate positively with human perception for vocal estimates. These findings highlight the need for stem-specific evaluation strategies and suggest that no single metric reliably reflects perceptual quality across all source types. We release our raw listener ratings to support reproducibility and further research.
High-Quality Sound Separation Across Diverse Categories via Visually-Guided Generative Modeling
Sep 26, 2025We propose DAVIS, a Diffusion-based Audio-VIsual Separation framework that solves the audio-visual sound source separation task through generative learning. Existing methods typically frame sound separation as a mask-based regression problem, achieving significant progress. However, they face limitations in capturing the complex data distribution required for high-quality separation of sounds from diverse categories. In contrast, DAVIS circumvents these issues by leveraging potent generative modeling paradigms, specifically Denoising Diffusion Probabilistic Models (DDPM) and the more recent Flow Matching (FM), integrated within a specialized Separation U-Net architecture. Our framework operates by synthesizing the desired separated sound spectrograms directly from a noise distribution, conditioned concurrently on the mixed audio input and associated visual information. The inherent nature of its generative objective makes DAVIS particularly adept at producing high-quality sound separations for diverse sound categories. We present comparative evaluations of DAVIS, encompassing both its DDPM and Flow Matching variants, against leading methods on the standard AVE and MUSIC datasets. The results affirm that both variants surpass existing approaches in separation quality, highlighting the efficacy of our generative framework for tackling the audio-visual source separation task.
User-guided Generative Source Separation
Jul 02, 2025



Music source separation (MSS) aims to extract individual instrument sources from their mixture. While most existing methods focus on the widely adopted four-stem separation setup (vocals, bass, drums, and other instruments), this approach lacks the flexibility needed for real-world applications. To address this, we propose GuideSep, a diffusion-based MSS model capable of instrument-agnostic separation beyond the four-stem setup. GuideSep is conditioned on multiple inputs: a waveform mimicry condition, which can be easily provided by humming or playing the target melody, and mel-spectrogram domain masks, which offer additional guidance for separation. Unlike prior approaches that relied on fixed class labels or sound queries, our conditioning scheme, coupled with the generative approach, provides greater flexibility and applicability. Additionally, we design a mask-prediction baseline using the same model architecture to systematically compare predictive and generative approaches. Our objective and subjective evaluations demonstrate that GuideSep achieves high-quality separation while enabling more versatile instrument extraction, highlighting the potential of user participation in the diffusion-based generative process for MSS. Our code and demo page are available at https://yutongwen.github.io/GuideSep/