 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing
May 14, 2025Audio-Visual Video Parsing (AVVP) entails the challenging task of localizing both uni-modal events (i.e., those occurring exclusively in either the visual or acoustic modality of a video) and multi-modal events (i.e., those occurring in both modalities concurrently). Moreover, the prohibitive cost of annotating training data with the class labels of all these events, along with their start and end times, imposes constraints on the scalability of AVVP techniques unless they can be trained in a weakly-supervised setting, where only modality-agnostic, video-level labels are available in the training data. To this end, recently proposed approaches seek to generate segment-level pseudo-labels to better guide model training. However, the absence of inter-segment dependencies when generating these pseudo-labels and the general bias towards predicting labels that are absent in a segment limit their performance. This work proposes a novel approach towards overcoming these weaknesses called Uncertainty-weighted Weakly-supervised Audio-visual Video Parsing (UWAV). Additionally, our innovative approach factors in the uncertainty associated with these estimated pseudo-labels and incorporates a feature mixup based training regularization for improved training. Empirical results show that UWAV outperforms state-of-the-art methods for the AVVP task on multiple metrics, across two different datasets, attesting to its effectiveness and generalizability.
Task-Aware Unified Source Separation
Oct 31, 2024



Several attempts have been made to handle multiple source separation tasks such as speech enhancement, speech separation, sound event separation, music source separation (MSS), or cinematic audio source separation (CASS) with a single model. These models are trained on large-scale data including speech, instruments, or sound events and can often successfully separate a wide range of sources. However, it is still challenging for such models to cover all separation tasks because some of them are contradictory (e.g., musical instruments are separated in MSS while they have to be grouped in CASS). To overcome this issue and support all the major separation tasks, we propose a task-aware unified source separation (TUSS) model. The model uses a variable number of learnable prompts to specify which source to separate, and changes its behavior depending on the given prompts, enabling it to handle all the major separation tasks including contradictory ones. Experimental results demonstrate that the proposed TUSS model successfully handles the five major separation tasks mentioned earlier. We also provide some audio examples, including both synthetic mixtures and real recordings, to demonstrate how flexibly the TUSS model changes its behavior at inference depending on the prompts.
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Jun 12, 2024


The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
Sound Event Bounding Boxes
Jun 06, 2024



Sound event detection is the task of recognizing sounds and determining their extent (onset/offset times) within an audio clip. Existing systems commonly predict sound presence confidence in short time frames. Then, thresholding produces binary frame-level presence decisions, with the extent of individual events determined by merging consecutive positive frames. In this paper, we show that frame-level thresholding degrades the prediction of the event extent by coupling it with the system's sound presence confidence. We propose to decouple the prediction of event extent and confidence by introducing SEBBs, which format each sound event prediction as a tuple of a class type, extent, and overall confidence. We also propose a change-detection-based algorithm to convert legacy frame-level outputs into SEBBs. We find the algorithm significantly improves the performance of DCASE 2023 Challenge systems, boosting the state of the art from .644 to .686 PSDS1.
Post-Processing Independent Evaluation of Sound Event Detection Systems
Jun 27, 2023


Due to the high variation in the application requirements of sound event detection (SED) systems, it is not sufficient to evaluate systems only in a single operating mode. Therefore, the community recently adopted the polyphonic sound detection score (PSDS) as an evaluation metric, which is the normalized area under the PSD receiver operating characteristic (PSD-ROC). It summarizes the system performance over a range of operating modes resulting from varying the decision threshold that is used to translate the system output scores into a binary detection output. Hence, it provides a more complete picture of the overall system behavior and is less biased by specific threshold tuning. However, besides the decision threshold there is also the post-processing that can be changed to enter another operating mode. In this paper we propose the post-processing independent PSDS (piPSDS) as a generalization of the PSDS. Here, the post-processing independent PSD-ROC includes operating points from varying post-processings with varying decision thresholds. Thus, it summarizes even more operating modes of an SED system and allows for system comparison without the need of implementing a post-processing and without a bias due to different post-processings. While piPSDS can in principle combine different types of post-processing, we hear, as a first step, present median filter independent PSDS (miPSDS) results for this year's DCASE Challenge Task4a systems. Source code is publicly available in our sed_scores_eval package (https://github.com/fgnt/sed_scores_eval).
Investigation into Target Speaking Rate Adaptation for Voice Conversion
Sep 05, 2022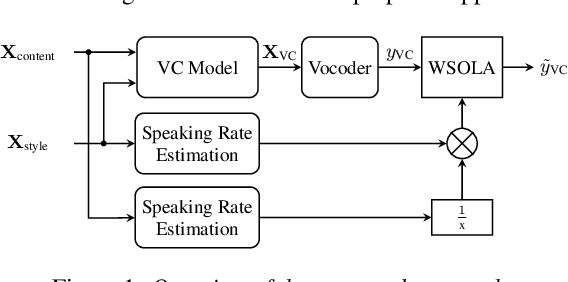

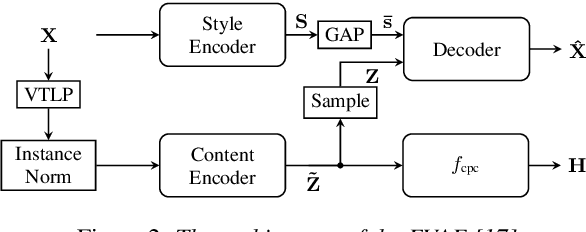
Disentangling speaker and content attributes of a speech signal into separate latent representations followed by decoding the content with an exchanged speaker representation is a popular approach for voice conversion, which can be trained with non-parallel and unlabeled speech data. However, previous approaches perform disentanglement only implicitly via some sort of information bottleneck or normalization, where it is usually hard to find a good trade-off between voice conversion and content reconstruction. Further, previous works usually do not consider an adaptation of the speaking rate to the target speaker or they put some major restrictions to the data or use case. Therefore, the contribution of this work is two-fold. First, we employ an explicit and fully unsupervised disentanglement approach, which has previously only been used for representation learning, and show that it allows to obtain both superior voice conversion and content reconstruction. Second, we investigate simple and generic approaches to linearly adapt the length of a speech signal, and hence the speaking rate, to a target speaker and show that the proposed adaptation allows to increase the speaking rate similarity with respect to the target speaker.
Threshold Independent Evaluation of Sound Event Detection Scores
Jan 31, 2022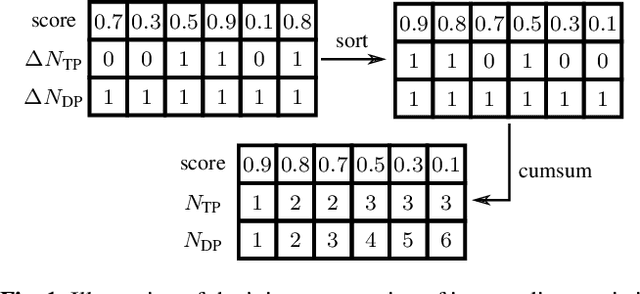
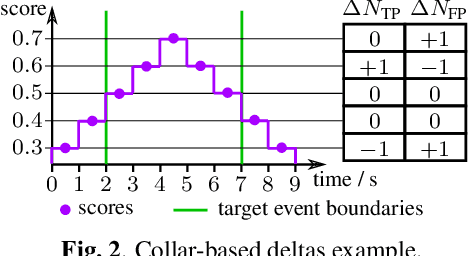
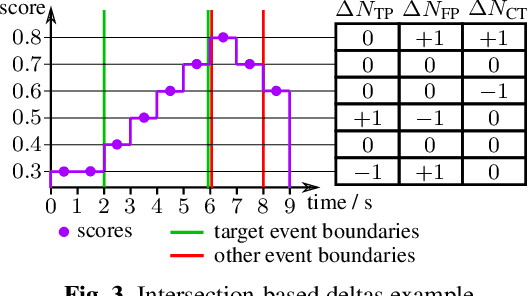
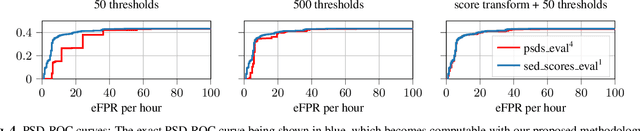
Performing an adequate evaluation of sound event detection (SED) systems is far from trivial and is still subject to ongoing research. The recently proposed polyphonic sound detection (PSD)-receiver operating characteristic (ROC) and PSD score (PSDS) make an important step into the direction of an evaluation of SED systems which is independent from a certain decision threshold. This allows to obtain a more complete picture of the overall system behavior which is less biased by threshold tuning. Yet, the PSD-ROC is currently only approximated using a finite set of thresholds. The choice of the thresholds used in approximation, however, can have a severe impact on the resulting PSDS. In this paper we propose a method which allows for computing system performance on an evaluation set for all possible thresholds jointly, enabling accurate computation not only of the PSD-ROC and PSDS but also of other collar-based and intersection-based performance curves. It further allows to select the threshold which best fulfills the requirements of a given application. Source code is publicly available in our SED evaluation package sed_scores_eval.
Voice Conversion Based Speaker Normalization for Acoustic Unit Discovery
May 04, 2021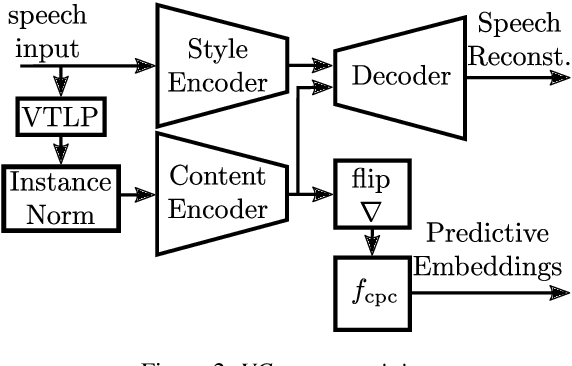
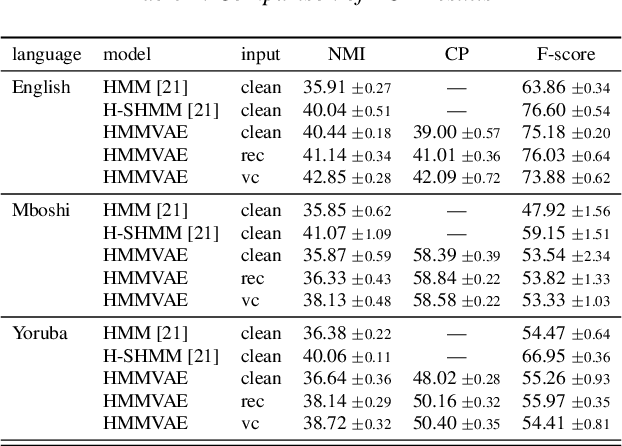
Discovering speaker independent acoustic units purely from spoken input is known to be a hard problem. In this work we propose an unsupervised speaker normalization technique prior to unit discovery. It is based on separating speaker related from content induced variations in a speech signal with an adversarial contrastive predictive coding approach. This technique does neither require transcribed speech nor speaker labels, and, furthermore, can be trained in a multilingual fashion, thus achieving speaker normalization even if only few unlabeled data is available from the target language. The speaker normalization is done by mapping all utterances to a medoid style which is representative for the whole database. We demonstrate the effectiveness of the approach by conducting acoustic unit discovery with a hidden Markov model variational autoencoder noting, however, that the proposed speaker normalization can serve as a front end to any unit discovery system. Experiments on English, Yoruba and Mboshi show improvements compared to using non-normalized input.
Forward-Backward Convolutional Recurrent Neural Networks and Tag-Conditioned Convolutional Neural Networks for Weakly Labeled Semi-supervised Sound Event Detection
Mar 11, 2021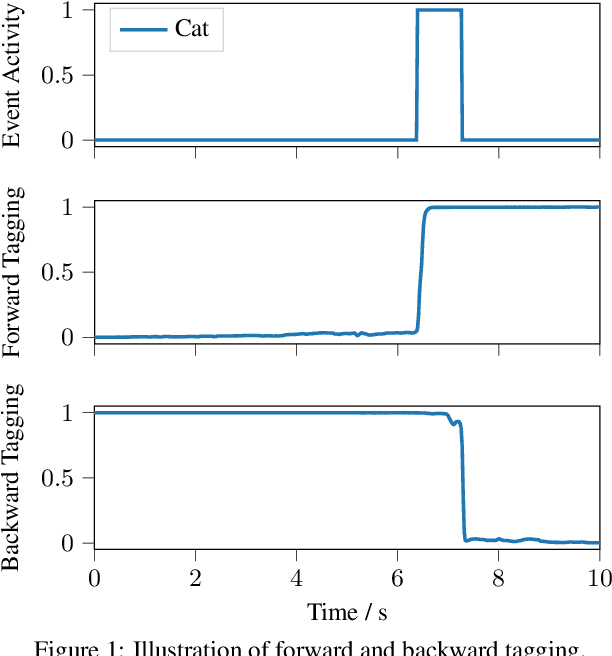

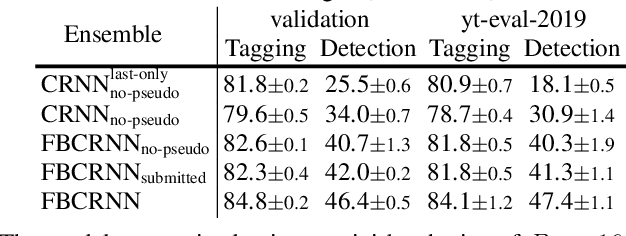
In this paper we present our system for the detection and classification of acoustic scenes and events (DCASE) 2020 Challenge Task 4: Sound event detection and separation in domestic environments. We introduce two new models: the forward-backward convolutional recurrent neural network (FBCRNN) and the tag-conditioned convolutional neural network (CNN). The FBCRNN employs two recurrent neural network (RNN) classifiers sharing the same CNN for preprocessing. With one RNN processing a recording in forward direction and the other in backward direction, the two networks are trained to jointly predict audio tags, i.e., weak labels, at each time step within a recording, given that at each time step they have jointly processed the whole recording. The proposed training encourages the classifiers to tag events as soon as possible. Therefore, after training, the networks can be applied to shorter audio segments of, e.g., 200 ms, allowing sound event detection (SED). Further, we propose a tag-conditioned CNN to complement SED. It is trained to predict strong labels while using (predicted) tags, i.e., weak labels, as additional input. For training pseudo strong labels from a FBCRNN ensemble are used. The presented system scored the fourth and third place in the systems and teams rankings, respectively. Subsequent improvements allow our system to even outperform the challenge baseline and winner systems in average by, respectively, 18.0% and 2.2% event-based F1-score on the validation set. Source code is publicly available at https://github.com/fgnt/pb_sed.