 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Audio Language Models
Sep 09, 2025Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart. Experiments on speech and music demonstrate improved efficiency and fidelity over state-of-the-art discrete audio language models, facilitating lightweight, high-quality audio generation. Samples are available at hf.co/spaces/kyutai/calm-samples
MusicGen-Stem: Multi-stem music generation and edition through autoregressive modeling
Jan 07, 2025



While most music generation models generate a mixture of stems (in mono or stereo), we propose to train a multi-stem generative model with 3 stems (bass, drums and other) that learn the musical dependencies between them. To do so, we train one specialized compression algorithm per stem to tokenize the music into parallel streams of tokens. Then, we leverage recent improvements in the task of music source separation to train a multi-stream text-to-music language model on a large dataset. Finally, thanks to a particular conditioning method, our model is able to edit bass, drums or other stems on existing or generated songs as well as doing iterative composition (e.g. generating bass on top of existing drums). This gives more flexibility in music generation algorithms and it is to the best of our knowledge the first open-source multi-stem autoregressive music generation model that can perform good quality generation and coherent source editing. Code and model weights will be released and samples are available on https://simonrouard.github.io/musicgenstem/.
Lina-Speech: Gated Linear Attention is a Fast and Parameter-Efficient Learner for text-to-speech synthesis
Oct 30, 2024



Neural codec language models have achieved state-of-the-art performance in text-to-speech (TTS) synthesis, leveraging scalable architectures like autoregressive transformers and large-scale speech datasets. By framing voice cloning as a prompt continuation task, these models excel at cloning voices from short audio samples. However, this approach is limited in its ability to handle numerous or lengthy speech excerpts, since the concatenation of source and target speech must fall within the maximum context length which is determined during training. In this work, we introduce Lina-Speech, a model that replaces traditional self-attention mechanisms with emerging recurrent architectures like Gated Linear Attention (GLA). Building on the success of initial-state tuning on RWKV, we extend this technique to voice cloning, enabling the use of multiple speech samples and full utilization of the context window in synthesis. This approach is fast, easy to deploy, and achieves performance comparable to fine-tuned baselines when the dataset size ranges from 3 to 15 minutes. Notably, Lina-Speech matches or outperforms state-of-the-art baseline models, including some with a parameter count up to four times higher or trained in an end-to-end style. We release our code and checkpoints. Audio samples are available at https://theodorblackbird.github.io/blog/demo_lina/.
Audio Conditioning for Music Generation via Discrete Bottleneck Features
Jul 17, 2024

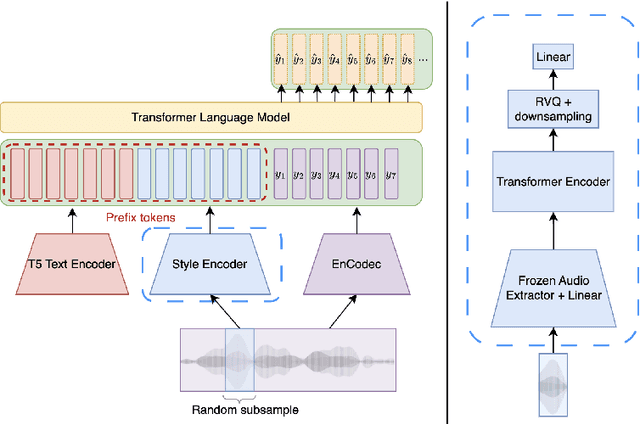

While most music generation models use textual or parametric conditioning (e.g. tempo, harmony, musical genre), we propose to condition a language model based music generation system with audio input. Our exploration involves two distinct strategies. The first strategy, termed textual inversion, leverages a pre-trained text-to-music model to map audio input to corresponding "pseudowords" in the textual embedding space. For the second model we train a music language model from scratch jointly with a text conditioner and a quantized audio feature extractor. At inference time, we can mix textual and audio conditioning and balance them thanks to a novel double classifier free guidance method. We conduct automatic and human studies that validates our approach. We will release the code and we provide music samples on https://musicgenstyle.github.io in order to show the quality of our model.
Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Jun 06, 2024



Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size.
VaSAB: The variable size adaptive information bottleneck for disentanglement on speech and singing voice
Oct 05, 2023

The information bottleneck auto-encoder is a tool for disentanglement commonly used for voice transformation. The successful disentanglement relies on the right choice of bottleneck size. Previous bottleneck auto-encoders created the bottleneck by the dimension of the latent space or through vector quantization and had no means to change the bottleneck size of a specific model. As the bottleneck removes information from the disentangled representation, the choice of bottleneck size is a trade-off between disentanglement and synthesis quality. We propose to build the information bottleneck using dropout which allows us to change the bottleneck through the dropout rate and investigate adapting the bottleneck size depending on the context. We experimentally explore into using the adaptive bottleneck for pitch transformation and demonstrate that the adaptive bottleneck leads to improved disentanglement of the F0 parameter for both, speech and singing voice leading to improved synthesis quality. Using the variable bottleneck size, we were able to achieve disentanglement for singing voice including extremely high pitches and create a universal voice model, that works on both speech and singing voice with improved synthesis quality.
Analysis and transformations of intensity in singing voice
Apr 08, 2022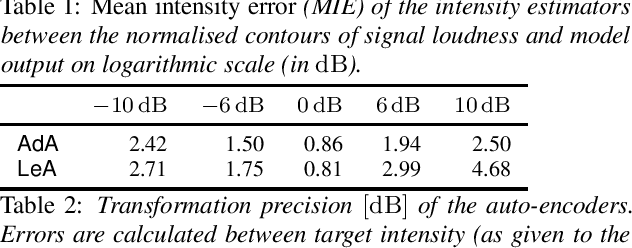
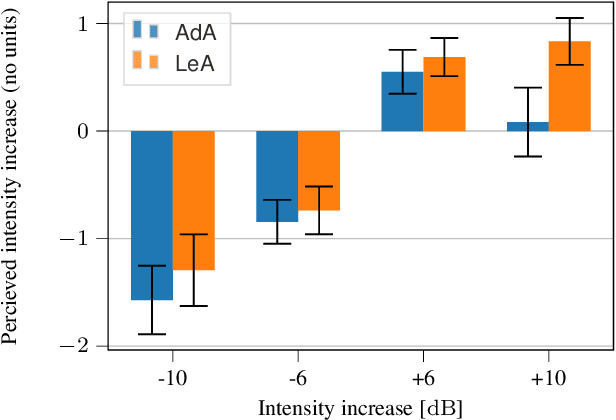
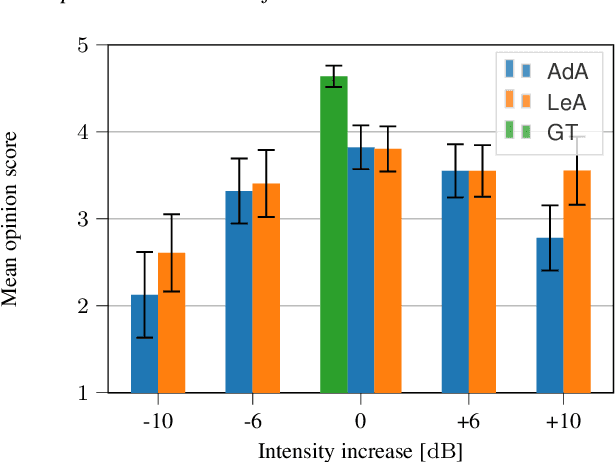

In this paper we introduce a neural auto-encoder that transforms the voice intensity in recordings of singing voice. Since most recordings of singing voice are not annotated with voice intensity we propose a means to estimate the relative voice intensity from the signal's timbre using a neural intensity estimator. Two methods to overcome the unknown recording factor that relates voice intensity to recorded signal power are given: The unknown recording factor can either be learned alongside the weights of the intensity estimator, or a special loss function based on the scalar product can be used to only match the intensity contour of the recorded signal's power. The intensity models are used to condition a previously introduced bottleneck auto-encoder that disentangles its input, the mel-spectrogram, from the intensity. We evaluate the intensity models by their consistency and by their fitness to provide useful information to the auto-encoder. A perceptive test is carried out that evaluates the perceived intensity change in transformed recordings and the synthesis quality. The perceptive test confirms that changing the conditional input changes the perceived intensity accordingly thus suggesting that the proposed intensity models encode information about the voice intensity.
StyleWaveGAN: Style-based synthesis of drum sounds with extensive controls using generative adversarial networks
Apr 02, 2022
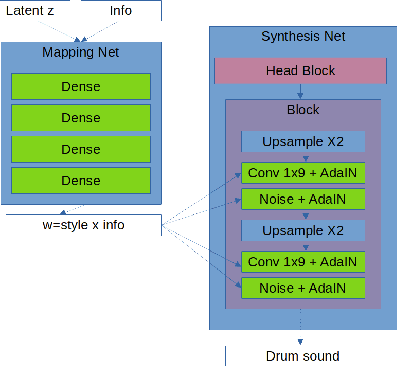


In this paper we introduce StyleWaveGAN, a style-based drum sound generator that is a variation of StyleGAN, a state-of-the-art image generator. By conditioning StyleWaveGAN on both the type of drum and several audio descriptors, we are able to synthesize waveforms faster than real-time on a GPU directly in CD quality up to a duration of 1.5s while retaining a considerable amount of control over the generation. We also introduce an alternative to the progressive growing of GANs and experimented on the effect of dataset balancing for generative tasks. The experiments are carried out on an augmented subset of a publicly available dataset comprised of different drums and cymbals. We evaluate against two recent drum generators, WaveGAN and NeuroDrum, demonstrating significantly improved generation quality (measured with the Frechet Audio Distance) and interesting results with perceptual features.
Audio Defect Detection in Music with Deep Networks
Feb 11, 2022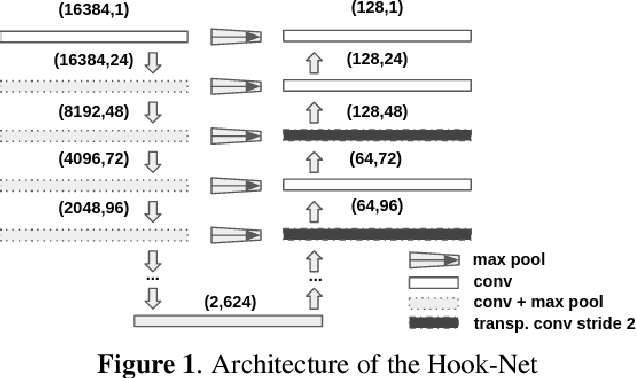
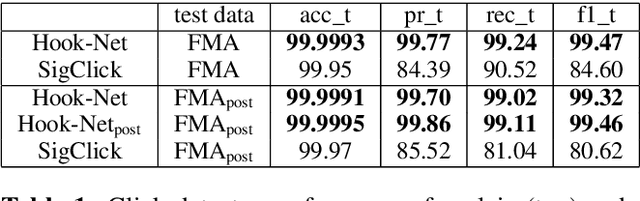
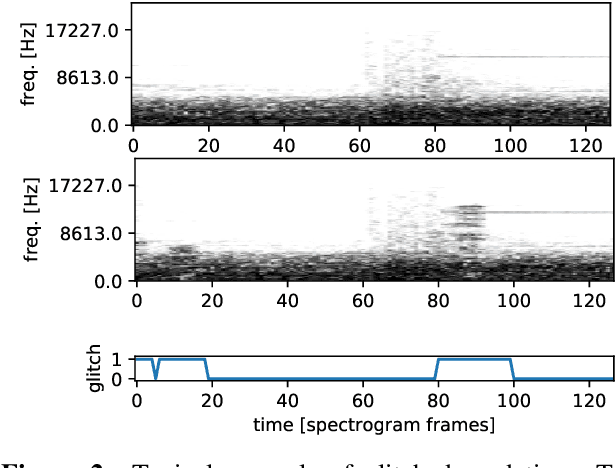
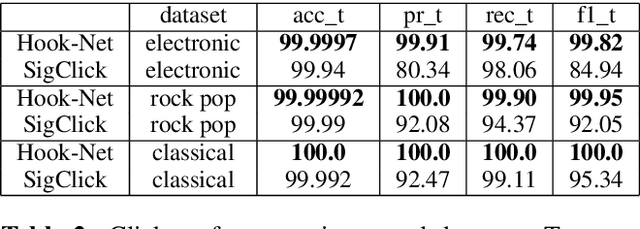
With increasing amounts of music being digitally transferred from production to distribution, automatic means of determining media quality are needed. Protection mechanisms in digital audio processing tools have not eliminated the need of production entities located downstream the distribution chain to assess audio quality and detect defects inserted further upstream. Such analysis often relies on the received audio and scarce meta-data alone. Deliberate use of artefacts such as clicks in popular music as well as more recent defects stemming from corruption in modern audio encodings call for data-centric and context sensitive solutions for detection. We present a convolutional network architecture following end-to-end encoder decoder configuration to develop detectors for two exemplary audio defects. A click detector is trained and compared to a traditional signal processing method, with a discussion on context sensitivity. Additional post-processing is used for data augmentation and workflow simulation. The ability of our models to capture variance is explored in a detector for artefacts from decompression of corrupted MP3 compressed audio. For both tasks we describe the synthetic generation of artefacts for controlled detector training and evaluation. We evaluate our detectors on the large open-source Free Music Archive (FMA) and genre-specific datasets.
* 6 pages
Sequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021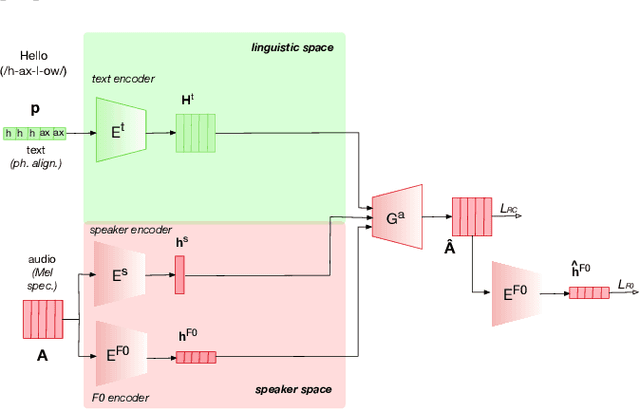
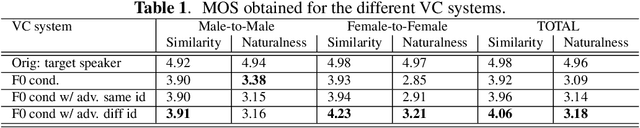
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.