 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
SAT3D: Image-driven Semantic Attribute Transfer in 3D
Aug 03, 2024GAN-based image editing task aims at manipulating image attributes in the latent space of generative models. Most of the previous 2D and 3D-aware approaches mainly focus on editing attributes in images with ambiguous semantics or regions from a reference image, which fail to achieve photographic semantic attribute transfer, such as the beard from a photo of a man. In this paper, we propose an image-driven Semantic Attribute Transfer method in 3D (SAT3D) by editing semantic attributes from a reference image. For the proposed method, the exploration is conducted in the style space of a pre-trained 3D-aware StyleGAN-based generator by learning the correlations between semantic attributes and style code channels. For guidance, we associate each attribute with a set of phrase-based descriptor groups, and develop a Quantitative Measurement Module (QMM) to quantitatively describe the attribute characteristics in images based on descriptor groups, which leverages the image-text comprehension capability of CLIP. During the training process, the QMM is incorporated into attribute losses to calculate attribute similarity between images, guiding target semantic transferring and irrelevant semantics preserving. We present our 3D-aware attribute transfer results across multiple domains and also conduct comparisons with classical 2D image editing methods, demonstrating the effectiveness and customizability of our SAT3D.
DLP-GAN: learning to draw modern Chinese landscape photos with generative adversarial network
Mar 07, 2024Chinese landscape painting has a unique and artistic style, and its drawing technique is highly abstract in both the use of color and the realistic representation of objects. Previous methods focus on transferring from modern photos to ancient ink paintings. However, little attention has been paid to translating landscape paintings into modern photos. To solve such problems, in this paper, we (1) propose DLP-GAN (Draw Modern Chinese Landscape Photos with Generative Adversarial Network), an unsupervised cross-domain image translation framework with a novel asymmetric cycle mapping, and (2) introduce a generator based on a dense-fusion module to match different translation directions. Moreover, a dual-consistency loss is proposed to balance the realism and abstraction of model painting. In this way, our model can draw landscape photos and sketches in the modern sense. Finally, based on our collection of modern landscape and sketch datasets, we compare the images generated by our model with other benchmarks. Extensive experiments including user studies show that our model outperforms state-of-the-art methods.
* Corrected typos
Stylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Apr 08, 2024



Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
StyleCity: Large-Scale 3D Urban Scenes Stylization with Vision-and-Text Reference via Progressive Optimization
Apr 16, 2024



Creating large-scale virtual urban scenes with variant styles is inherently challenging. To facilitate prototypes of virtual production and bypass the need for complex materials and lighting setups, we introduce the first vision-and-text-driven texture stylization system for large-scale urban scenes, StyleCity. Taking an image and text as references, StyleCity stylizes a 3D textured mesh of a large-scale urban scene in a semantics-aware fashion and generates a harmonic omnidirectional sky background. To achieve that, we propose to stylize a neural texture field by transferring 2D vision-and-text priors to 3D globally and locally. During 3D stylization, we progressively scale the planned training views of the input 3D scene at different levels in order to preserve high-quality scene content. We then optimize the scene style globally by adapting the scale of the style image with the scale of the training views. Moreover, we enhance local semantics consistency by the semantics-aware style loss which is crucial for photo-realistic stylization. Besides texture stylization, we further adopt a generative diffusion model to synthesize a style-consistent omnidirectional sky image, which offers a more immersive atmosphere and assists the semantic stylization process. The stylized neural texture field can be baked into an arbitrary-resolution texture, enabling seamless integration into conventional rendering pipelines and significantly easing the virtual production prototyping process. Extensive experiments demonstrate our stylized scenes' superiority in qualitative and quantitative performance and user preferences.
Optimal Image Transport on Sparse Dictionaries
Nov 03, 2023



In this paper, we derive a novel optimal image transport algorithm over sparse dictionaries by taking advantage of Sparse Representation (SR) and Optimal Transport (OT). Concisely, we design a unified optimization framework in which the individual image features (color, textures, styles, etc.) are encoded using sparse representation compactly, and an optimal transport plan is then inferred between two learned dictionaries in accordance with the encoding process. This paradigm gives rise to a simple but effective way for simultaneous image representation and transformation, which is also empirically solvable because of the moderate size of sparse coding and optimal transport sub-problems. We demonstrate its versatility and many benefits to different image-to-image translation tasks, in particular image color transform and artistic style transfer, and show the plausible results for photo-realistic transferred effects.
PP-GAN : Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN
Jun 23, 2023
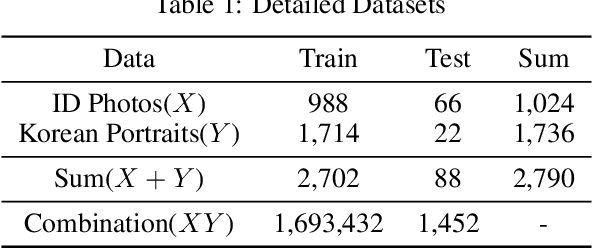

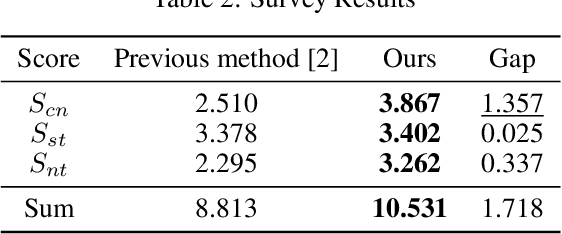
The objective of a style transfer is to maintain the content of an image while transferring the style of another image. However, conventional research on style transfer has a significant limitation in preserving facial landmarks, such as the eyes, nose, and mouth, which are crucial for maintaining the identity of the image. In Korean portraits, the majority of individuals wear "Gat", a type of headdress exclusively worn by men. Owing to its distinct characteristics from the hair in ID photos, transferring the "Gat" is challenging. To address this issue, this study proposes a deep learning network that can perform style transfer, including the "Gat", while preserving the identity of the face. Unlike existing style transfer approaches, the proposed method aims to preserve texture, costume, and the "Gat" on the style image. The Generative Adversarial Network forms the backbone of the proposed network. The color, texture, and intensity were extracted differently based on the characteristics of each block and layer of the pre-trained VGG-16, and only the necessary elements during training were preserved using a facial landmark mask. The head area was presented using the eyebrow area to transfer the "Gat". Furthermore, the identity of the face was retained, and style correlation was considered based on the Gram matrix. The proposed approach demonstrated superior transfer and preservation performance compared to previous studies.
Intelligent Director: An Automatic Framework for Dynamic Visual Composition using ChatGPT
Feb 24, 2024



With the rise of short video platforms represented by TikTok, the trend of users expressing their creativity through photos and videos has increased dramatically. However, ordinary users lack the professional skills to produce high-quality videos using professional creation software. To meet the demand for intelligent and user-friendly video creation tools, we propose the Dynamic Visual Composition (DVC) task, an interesting and challenging task that aims to automatically integrate various media elements based on user requirements and create storytelling videos. We propose an Intelligent Director framework, utilizing LENS to generate descriptions for images and video frames and combining ChatGPT to generate coherent captions while recommending appropriate music names. Then, the best-matched music is obtained through music retrieval. Then, materials such as captions, images, videos, and music are integrated to seamlessly synthesize the video. Finally, we apply AnimeGANv2 for style transfer. We construct UCF101-DVC and Personal Album datasets and verified the effectiveness of our framework in solving DVC through qualitative and quantitative comparisons, along with user studies, demonstrating its substantial potential.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023



Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer
Apr 10, 2023



This paper firstly presents old photo modernization using multiple references by performing stylization and enhancement in a unified manner. In order to modernize old photos, we propose a novel multi-reference-based old photo modernization (MROPM) framework consisting of a network MROPM-Net and a novel synthetic data generation scheme. MROPM-Net stylizes old photos using multiple references via photorealistic style transfer (PST) and further enhances the results to produce modern-looking images. Meanwhile, the synthetic data generation scheme trains the network to effectively utilize multiple references to perform modernization. To evaluate the performance, we propose a new old photos benchmark dataset (CHD) consisting of diverse natural indoor and outdoor scenes. Extensive experiments show that the proposed method outperforms other baselines in performing modernization on real old photos, even though no old photos were used during training. Moreover, our method can appropriately select styles from multiple references for each semantic region in the old photo to further improve the modernization performance.
Painterly Image Harmonization via Adversarial Residual Learning
Nov 15, 2023
Image compositing plays a vital role in photo editing. After inserting a foreground object into another background image, the composite image may look unnatural and inharmonious. When the foreground is photorealistic and the background is an artistic painting, painterly image harmonization aims to transfer the style of background painting to the foreground object, which is a challenging task due to the large domain gap between foreground and background. In this work, we employ adversarial learning to bridge the domain gap between foreground feature map and background feature map. Specifically, we design a dual-encoder generator, in which the residual encoder produces the residual features added to the foreground feature map from main encoder. Then, a pixel-wise discriminator plays against the generator, encouraging the refined foreground feature map to be indistinguishable from background feature map. Extensive experiments demonstrate that our method could achieve more harmonious and visually appealing results than previous methods.