 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross4D-JEPA: Dense Cross-modal Correspondence Distillation for 4D Point Cloud Representation Learning
Jul 01, 2026Automatic understanding of dynamic 4D point clouds, the 3D-point sequences captured over time by depth sensors and LiDAR, is central to robotics and embodied perception. Yet annotating them densely is expensive, making self-supervised pretraining the natural route to transferable representations. Existing pretext tasks, however, are almost entirely intra-modal, and the few methods that transfer knowledge from 2D foundation models rely on a single global embedding per clip, discarding the rich per-patch semantics that these models compute. To address this gap, we propose Cross4D-JEPA, a teacher-student method that distills a frozen 2D foundation model, an image model DINOv2, or a video model V-JEPA 2, into a 4D point encoder. The proposed method combines (1) a dense cross-modal correspondence that maps every 3D point to the teacher patch feature it projects to, and (2) a per-point objective that trains the student to match these features in latent space with no masking, negatives, or decoder. We evaluate Cross4D-JEPA on four benchmarks, MSR-Action3D, DeformingThings4D, NTU-RGB+D 60, and HOI4D, against intra-modal and global cross-modal baselines. Experimental results show that, under a matched protocol, the proposed method consistently outperforms intra-modal and global cross-modal baselines across the four benchmarks and is competitive with heavier published 4D methods; further analysis attributes this gain primarily to the granularity of the correspondence rather than the teacher modality. Beyond recognition accuracy, the dense representation learned by Cross4D-JEPA transfers across domains, improves label efficiency, and improves full-label fine-tuning under the same training budget, while a 13x smaller encoder matches a heavyweight pooling backbone.
SelectAnyTree: A Promptable Instance Segmentation Model for 3D Forest LiDAR Point Clouds
Jun 25, 2026Automated instance segmentation of forest LiDAR point clouds is increasingly critical as forest monitoring moves toward scalable, detailed, 3D measurement. Yet, progress is constrained by label scarcity for tree instances; a single hectare can hold millions of points and hundreds of overlapping, complex crowns, making manual annotation from scratch with raw data laborious and error-prone. Annotations are often corrected from automatic pre-segmentations, but remain costly as these provide no interactive or AI-assisted refinement. Inspired by the promptable paradigm of foundation segmentation models, we propose SelectAnyTree, a promptable instance segmentation model that delineates any individual tree in a 3D forest point cloud from a few clicks. It introduces two key components: Click-to-query prompt encoder and Canopy Height Model (CHM)-guided first prompt. The former turns each click into a single content query, encoding its 3D position and positive/negative polarity together with a pooled local backbone feature. The latter provides treetops as a geometry- and ecologically guided first prompt without any user input. The resulting prompt query is then decoded into one tree mask by a state-space query decoder to efficiently capture long-range context in large-scale forest scenes with linear-time complexity. We evaluate SelectAnyTree in interactive and instance-level settings across seven diverse forest regions and an independent held-out test dataset, demonstrating strong generalization beyond the training domains. It segments a target tree to 78.2 Intersection over Union (IoU) from a single click, 24.8 points above the strongest promptable baseline, and reaches every accuracy target with the fewest clicks, while using far fewer parameters and less inference time than prior promptable models. The source code is available at https://github.com/thanhhff/SelectAnyTree.
ForestMamba: Sparse Mamba with Geometry-guided Queries for 3D Forest Point Cloud Segmentation
Jun 01, 2026AI-based semantic and instance segmentation of terrestrial and drone LiDAR point clouds is emerging as a transformative approach for converting the complex 3D structure of forests into actionable information for forest monitoring and biodiversity assessment. However, forest LiDAR scenes remain highly challenging due to their large data volumes, irregular sampling density, overlapping and complex canopy structure, and geographic variability. Existing methods based on sparse convolutions or Transformers achieve promising results, but suffer from two key limitations: Quadratic complexity of attention scales poorly to large forest scenes, and Generic context modeling does not exploit forest structural priors, limiting tree separation in complex regions. To address these challenges, we propose ForestMamba, a structure-aware method that incorporates forest-specific priors into feature encoding, query generation, and query refinement, while replacing quadratic attention with linear-time state-space modeling. First, we introduce a sparse encoder with vertical-priority slab serialization that organizes sparse voxels into vertically coherent sequences for efficient long-range context modeling. Second, we propose a geometry-guided query initialization strategy based on an on-the-fly multi-scale Canopy Height Model (CHM), where canopy maxima provide ecologically meaningful query seeds, supplemented by Farthest Point Sampling (FPS) to cover understory trees. Third, we design a Mamba-based query decoder that combines local kNN voxel aggregation with a spatial dual-path Mamba for query refinement with linear computational complexity. Extensive experiments across seven forest regions demonstrate that ForestMamba consistently outperforms existing baselines in both segmentation tasks, while achieving 3 times faster inference and 2.3 times lower GPU memory than Transformer-based methods.
Upper Entropy for 2-Monotone Lower Probabilities
Mar 23, 2026Uncertainty quantification is a key aspect in many tasks such as model selection/regularization, or quantifying prediction uncertainties to perform active learning or OOD detection. Within credal approaches that consider modeling uncertainty as probability sets, upper entropy plays a central role as an uncertainty measure. This paper is devoted to the computational aspect of upper entropies, providing an exhaustive algorithmic and complexity analysis of the problem. In particular, we show that the problem has a strongly polynomial solution, and propose many significant improvements over past algorithms proposed for 2-monotone lower probabilities and their specific cases.
Your Vision-Language-Action Model Already Has Attention Heads For Path Deviation Detection
Mar 14, 2026Vision-Language-Action (VLA) models have demonstrated strong potential for predicting semantic actions in navigation tasks, demonstrating the ability to reason over complex linguistic instructions and visual contexts. However, they are fundamentally hindered by visual-reasoning hallucinations that lead to trajectory deviations. Addressing this issue has conventionally required training external critic modules or relying on complex uncertainty heuristics. In this work, we discover that monitoring a few attention heads within a frozen VLA model can accurately detect path deviations without incurring additional computational overhead. We refer to these heads, which inherently capture the spatiotemporal causality between historical visual sequences and linguistic instructions, as Navigation Heads. Using these heads, we propose an intuitive, training-free anomaly-detection framework that monitors their signals to detect hallucinations in real time. Surprisingly, among over a thousand attention heads, a combination of just three is sufficient to achieve a 44.6 % deviation detection rate with a low false-positive rate of 11.7 %. Furthermore, upon detecting a deviation, we bypass the heavy VLA model and trigger a lightweight Reinforcement Learning (RL) policy to safely execute a shortest-path rollback. By integrating this entire detection-to-recovery pipeline onto a physical robot, we demonstrate its practical robustness. All source code will be publicly available.
DePT3R: Joint Dense Point Tracking and 3D Reconstruction of Dynamic Scenes in a Single Forward Pass
Dec 15, 2025



Current methods for dense 3D point tracking in dynamic scenes typically rely on pairwise processing, require known camera poses, or assume a temporal ordering to input frames, constraining their flexibility and applicability. Additionally, recent advances have successfully enabled efficient 3D reconstruction from large-scale, unposed image collections, underscoring opportunities for unified approaches to dynamic scene understanding. Motivated by this, we propose DePT3R, a novel framework that simultaneously performs dense point tracking and 3D reconstruction of dynamic scenes from multiple images in a single forward pass. This multi-task learning is achieved by extracting deep spatio-temporal features with a powerful backbone and regressing pixel-wise maps with dense prediction heads. Crucially, DePT3R operates without requiring camera poses, substantially enhancing its adaptability and efficiency-especially important in dynamic environments with rapid changes. We validate DePT3R on several challenging benchmarks involving dynamic scenes, demonstrating strong performance and significant improvements in memory efficiency over existing state-of-the-art methods. Data and codes are available via the open repository: https://github.com/StructuresComp/DePT3R
HiddenObject: Modality-Agnostic Fusion for Multimodal Hidden Object Detection
Aug 28, 2025



Detecting hidden or partially concealed objects remains a fundamental challenge in multimodal environments, where factors like occlusion, camouflage, and lighting variations significantly hinder performance. Traditional RGB-based detection methods often fail under such adverse conditions, motivating the need for more robust, modality-agnostic approaches. In this work, we present HiddenObject, a fusion framework that integrates RGB, thermal, and depth data using a Mamba-based fusion mechanism. Our method captures complementary signals across modalities, enabling enhanced detection of obscured or camouflaged targets. Specifically, the proposed approach identifies modality-specific features and fuses them in a unified representation that generalizes well across challenging scenarios. We validate HiddenObject across multiple benchmark datasets, demonstrating state-of-the-art or competitive performance compared to existing methods. These results highlight the efficacy of our fusion design and expose key limitations in current unimodal and na\"ive fusion strategies. More broadly, our findings suggest that Mamba-based fusion architectures can significantly advance the field of multimodal object detection, especially under visually degraded or complex conditions.
AgriChrono: A Multi-modal Dataset Capturing Crop Growth and Lighting Variability with a Field Robot
Aug 26, 2025Existing datasets for precision agriculture have primarily been collected in static or controlled environments such as indoor labs or greenhouses, often with limited sensor diversity and restricted temporal span. These conditions fail to reflect the dynamic nature of real farmland, including illumination changes, crop growth variation, and natural disturbances. As a result, models trained on such data often lack robustness and generalization when applied to real-world field scenarios. In this paper, we present AgriChrono, a novel robotic data collection platform and multi-modal dataset designed to capture the dynamic conditions of real-world agricultural environments. Our platform integrates multiple sensors and enables remote, time-synchronized acquisition of RGB, Depth, LiDAR, and IMU data, supporting efficient and repeatable long-term data collection across varying illumination and crop growth stages. We benchmark a range of state-of-the-art 3D reconstruction models on the AgriChrono dataset, highlighting the difficulty of reconstruction in real-world field environments and demonstrating its value as a research asset for advancing model generalization under dynamic conditions. The code and dataset are publicly available at: https://github.com/StructuresComp/agri-chrono
Reconstruction Using the Invisible: Intuition from NIR and Metadata for Enhanced 3D Gaussian Splatting
Aug 20, 2025
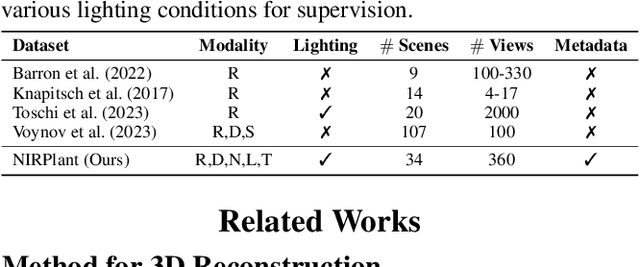


While 3D Gaussian Splatting (3DGS) has rapidly advanced, its application in agriculture remains underexplored. Agricultural scenes present unique challenges for 3D reconstruction methods, particularly due to uneven illumination, occlusions, and a limited field of view. To address these limitations, we introduce \textbf{NIRPlant}, a novel multimodal dataset encompassing Near-Infrared (NIR) imagery, RGB imagery, textual metadata, Depth, and LiDAR data collected under varied indoor and outdoor lighting conditions. By integrating NIR data, our approach enhances robustness and provides crucial botanical insights that extend beyond the visible spectrum. Additionally, we leverage text-based metadata derived from vegetation indices, such as NDVI, NDWI, and the chlorophyll index, which significantly enriches the contextual understanding of complex agricultural environments. To fully exploit these modalities, we propose \textbf{NIRSplat}, an effective multimodal Gaussian splatting architecture employing a cross-attention mechanism combined with 3D point-based positional encoding, providing robust geometric priors. Comprehensive experiments demonstrate that \textbf{NIRSplat} outperforms existing landmark methods, including 3DGS, CoR-GS, and InstantSplat, highlighting its effectiveness in challenging agricultural scenarios. The code and dataset are publicly available at: https://github.com/StructuresComp/3D-Reconstruction-NIR
Towards Transferable Attacks Against Vision-LLMs in Autonomous Driving with Typography
May 23, 2024



Vision-Large-Language-Models (Vision-LLMs) are increasingly being integrated into autonomous driving (AD) systems due to their advanced visual-language reasoning capabilities, targeting the perception, prediction, planning, and control mechanisms. However, Vision-LLMs have demonstrated susceptibilities against various types of adversarial attacks, which would compromise their reliability and safety. To further explore the risk in AD systems and the transferability of practical threats, we propose to leverage typographic attacks against AD systems relying on the decision-making capabilities of Vision-LLMs. Different from the few existing works developing general datasets of typographic attacks, this paper focuses on realistic traffic scenarios where these attacks can be deployed, on their potential effects on the decision-making autonomy, and on the practical ways in which these attacks can be physically presented. To achieve the above goals, we first propose a dataset-agnostic framework for automatically generating false answers that can mislead Vision-LLMs' reasoning. Then, we present a linguistic augmentation scheme that facilitates attacks at image-level and region-level reasoning, and we extend it with attack patterns against multiple reasoning tasks simultaneously. Based on these, we conduct a study on how these attacks can be realized in physical traffic scenarios. Through our empirical study, we evaluate the effectiveness, transferability, and realizability of typographic attacks in traffic scenes. Our findings demonstrate particular harmfulness of the typographic attacks against existing Vision-LLMs (e.g., LLaVA, Qwen-VL, VILA, and Imp), thereby raising community awareness of vulnerabilities when incorporating such models into AD systems. We will release our source code upon acceptance.