 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
A Reproducible, Scalable Pipeline for Synthesizing Autoregressive Model Literature
Aug 06, 2025The accelerating pace of research on autoregressive generative models has produced thousands of papers, making manual literature surveys and reproduction studies increasingly impractical. We present a fully open-source, reproducible pipeline that automatically retrieves candidate documents from public repositories, filters them for relevance, extracts metadata, hyper-parameters and reported results, clusters topics, produces retrieval-augmented summaries and generates containerised scripts for re-running selected experiments. Quantitative evaluation on 50 manually-annotated papers shows F1 scores above 0.85 for relevance classification, hyper-parameter extraction and citation identification. Experiments on corpora of up to 1000 papers demonstrate near-linear scalability with eight CPU workers. Three case studies -- AWD-LSTM on WikiText-2, Transformer-XL on WikiText-103 and an autoregressive music model on the Lakh MIDI dataset -- confirm that the extracted settings support faithful reproduction, achieving test perplexities within 1--3% of the original reports.
How Animals Dance (When You're Not Looking)
May 29, 2025



We present a keyframe-based framework for generating music-synchronized, choreography aware animal dance videos. Starting from a few keyframes representing distinct animal poses -- generated via text-to-image prompting or GPT-4o -- we formulate dance synthesis as a graph optimization problem: find the optimal keyframe structure that satisfies a specified choreography pattern of beats, which can be automatically estimated from a reference dance video. We also introduce an approach for mirrored pose image generation, essential for capturing symmetry in dance. In-between frames are synthesized using an video diffusion model. With as few as six input keyframes, our method can produce up to 30 second dance videos across a wide range of animals and music tracks.
SmoothSinger: A Conditional Diffusion Model for Singing Voice Synthesis with Multi-Resolution Architecture
Jun 26, 2025Singing voice synthesis (SVS) aims to generate expressive and high-quality vocals from musical scores, requiring precise modeling of pitch, duration, and articulation. While diffusion-based models have achieved remarkable success in image and video generation, their application to SVS remains challenging due to the complex acoustic and musical characteristics of singing, often resulting in artifacts that degrade naturalness. In this work, we propose SmoothSinger, a conditional diffusion model designed to synthesize high quality and natural singing voices. Unlike prior methods that depend on vocoders as a final stage and often introduce distortion, SmoothSinger refines low-quality synthesized audio directly in a unified framework, mitigating the degradation associated with two-stage pipelines. The model adopts a reference-guided dual-branch architecture, using low-quality audio from any baseline system as a reference to guide the denoising process, enabling more expressive and context-aware synthesis. Furthermore, it enhances the conventional U-Net with a parallel low-frequency upsampling path, allowing the model to better capture pitch contours and long term spectral dependencies. To improve alignment during training, we replace reference audio with degraded ground truth audio, addressing temporal mismatch between reference and target signals. Experiments on the Opencpop dataset, a large-scale Chinese singing corpus, demonstrate that SmoothSinger achieves state-of-the-art results in both objective and subjective evaluations. Extensive ablation studies confirm its effectiveness in reducing artifacts and improving the naturalness of synthesized voices.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.
SonicMotion: Dynamic Spatial Audio Soundscapes with Latent Diffusion Models
Jul 09, 2025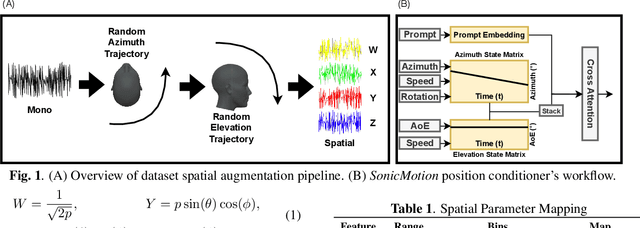
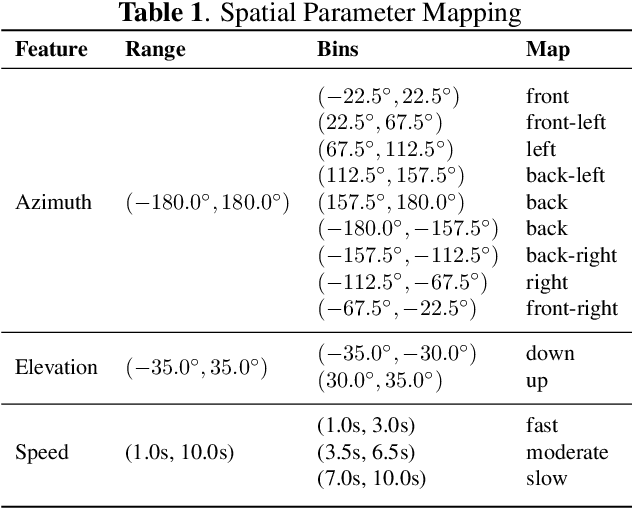
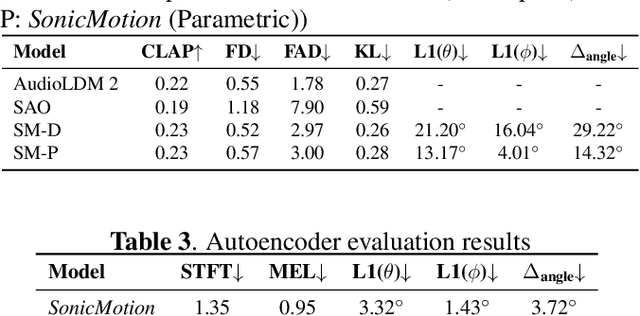
Spatial audio is an integral part of immersive entertainment, such as VR/AR, and has seen increasing popularity in cinema and music as well. The most common format of spatial audio is described as first-order Ambisonics (FOA). We seek to extend recent advancements in FOA generative AI models to enable the generation of 3D scenes with dynamic sound sources. Our proposed end-to-end model, SonicMotion, comes in two variations which vary in their user input and level of precision in sound source localization. In addition to our model, we also present a new dataset of simulated spatial audio-caption pairs. Evaluation of our models demonstrate that they are capable of matching the semantic alignment and audio quality of state of the art models while capturing the desired spatial attributes.
Spatial-Temporal Graph Mamba for Music-Guided Dance Video Synthesis
Jul 09, 2025



We propose a novel spatial-temporal graph Mamba (STG-Mamba) for the music-guided dance video synthesis task, i.e., to translate the input music to a dance video. STG-Mamba consists of two translation mappings: music-to-skeleton translation and skeleton-to-video translation. In the music-to-skeleton translation, we introduce a novel spatial-temporal graph Mamba (STGM) block to effectively construct skeleton sequences from the input music, capturing dependencies between joints in both the spatial and temporal dimensions. For the skeleton-to-video translation, we propose a novel self-supervised regularization network to translate the generated skeletons, along with a conditional image, into a dance video. Lastly, we collect a new skeleton-to-video translation dataset from the Internet, containing 54,944 video clips. Extensive experiments demonstrate that STG-Mamba achieves significantly better results than existing methods.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Audio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
Do Music Preferences Reflect Cultural Values? A Cross-National Analysis Using Music Embedding and World Values Survey
Jun 16, 2025This study explores the extent to which national music preferences reflect underlying cultural values. We collected long-term popular music data from YouTube Music Charts across 62 countries, encompassing both Western and non-Western regions, and extracted audio embeddings using the CLAP model. To complement these quantitative representations, we generated semantic captions for each track using LP-MusicCaps and GPT-based summarization. Countries were clustered based on contrastive embeddings that highlight deviations from global musical norms. The resulting clusters were projected into a two-dimensional space via t-SNE for visualization and evaluated against cultural zones defined by the World Values Survey (WVS). Statistical analyses, including MANOVA and chi-squared tests, confirmed that music-based clusters exhibit significant alignment with established cultural groupings. Furthermore, residual analysis revealed consistent patterns of overrepresentation, suggesting non-random associations between specific clusters and cultural zones. These findings indicate that national-level music preferences encode meaningful cultural signals and can serve as a proxy for understanding global cultural boundaries.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.