 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
FoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025



Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench
CompLex: Music Theory Lexicon Constructed by Autonomous Agents for Automatic Music Generation
Aug 27, 2025Generative artificial intelligence in music has made significant strides, yet it still falls short of the substantial achievements seen in natural language processing, primarily due to the limited availability of music data. Knowledge-informed approaches have been shown to enhance the performance of music generation models, even when only a few pieces of musical knowledge are integrated. This paper seeks to leverage comprehensive music theory in AI-driven music generation tasks, such as algorithmic composition and style transfer, which traditionally require significant manual effort with existing techniques. We introduce a novel automatic music lexicon construction model that generates a lexicon, named CompLex, comprising 37,432 items derived from just 9 manually input category keywords and 5 sentence prompt templates. A new multi-agent algorithm is proposed to automatically detect and mitigate hallucinations. CompLex demonstrates impressive performance improvements across three state-of-the-art text-to-music generation models, encompassing both symbolic and audio-based methods. Furthermore, we evaluate CompLex in terms of completeness, accuracy, non-redundancy, and executability, confirming that it possesses the key characteristics of an effective lexicon.
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025


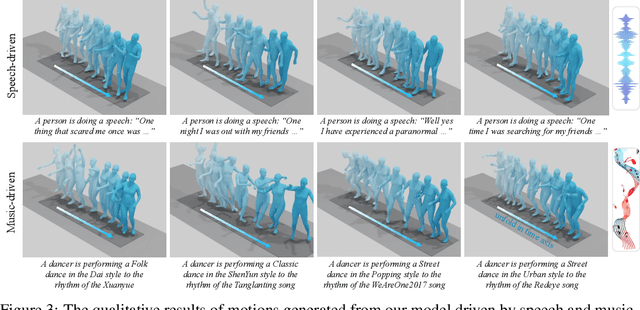
Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
Continuous Audio Language Models
Sep 09, 2025Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart. Experiments on speech and music demonstrate improved efficiency and fidelity over state-of-the-art discrete audio language models, facilitating lightweight, high-quality audio generation. Samples are available at hf.co/spaces/kyutai/calm-samples
Detecting and Mitigating Insertion Hallucination in Video-to-Audio Generation
Oct 09, 2025Video-to-Audio generation has made remarkable strides in automatically synthesizing sound for video. However, existing evaluation metrics, which focus on semantic and temporal alignment, overlook a critical failure mode: models often generate acoustic events, particularly speech and music, that have no corresponding visual source. We term this phenomenon Insertion Hallucination and identify it as a systemic risk driven by dataset biases, such as the prevalence of off-screen sounds, that remains completely undetected by current metrics. To address this challenge, we first develop a systematic evaluation framework that employs a majority-voting ensemble of multiple audio event detectors. We also introduce two novel metrics to quantify the prevalence and severity of this issue: IH@vid (the fraction of videos with hallucinations) and IH@dur (the fraction of hallucinated duration). Building on this, we propose Posterior Feature Correction, a novel training-free inference-time method that mitigates IH. PFC operates in a two-pass process: it first generates an initial audio output to detect hallucinated segments, and then regenerates the audio after masking the corresponding video features at those timestamps. Experiments on several mainstream V2A benchmarks first reveal that state-of-the-art models suffer from severe IH. In contrast, our PFC method reduces both the prevalence and duration of hallucinations by over 50\% on average, without degrading, and in some cases even improving, conventional metrics for audio quality and temporal synchronization. Our work is the first to formally define, systematically measure, and effectively mitigate Insertion Hallucination, paving the way for more reliable and faithful V2A models.
MUSE-Explainer: Counterfactual Explanations for Symbolic Music Graph Classification Models
Sep 30, 2025Interpretability is essential for deploying deep learning models in symbolic music analysis, yet most research emphasizes model performance over explanation. To address this, we introduce MUSE-Explainer, a new method that helps reveal how music Graph Neural Network models make decisions by providing clear, human-friendly explanations. Our approach generates counterfactual explanations by making small, meaningful changes to musical score graphs that alter a model's prediction while ensuring the results remain musically coherent. Unlike existing methods, MUSE-Explainer tailors its explanations to the structure of musical data and avoids unrealistic or confusing outputs. We evaluate our method on a music analysis task and show it offers intuitive insights that can be visualized with standard music tools such as Verovio.
Pitch-Conditioned Instrument Sound Synthesis From an Interactive Timbre Latent Space
Oct 05, 2025



This paper presents a novel approach to neural instrument sound synthesis using a two-stage semi-supervised learning framework capable of generating pitch-accurate, high-quality music samples from an expressive timbre latent space. Existing approaches that achieve sufficient quality for music production often rely on high-dimensional latent representations that are difficult to navigate and provide unintuitive user experiences. We address this limitation through a two-stage training paradigm: first, we train a pitch-timbre disentangled 2D representation of audio samples using a Variational Autoencoder; second, we use this representation as conditioning input for a Transformer-based generative model. The learned 2D latent space serves as an intuitive interface for navigating and exploring the sound landscape. We demonstrate that the proposed method effectively learns a disentangled timbre space, enabling expressive and controllable audio generation with reliable pitch conditioning. Experimental results show the model's ability to capture subtle variations in timbre while maintaining a high degree of pitch accuracy. The usability of our method is demonstrated in an interactive web application, highlighting its potential as a step towards future music production environments that are both intuitive and creatively empowering: https://pgesam.faresschulz.com
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025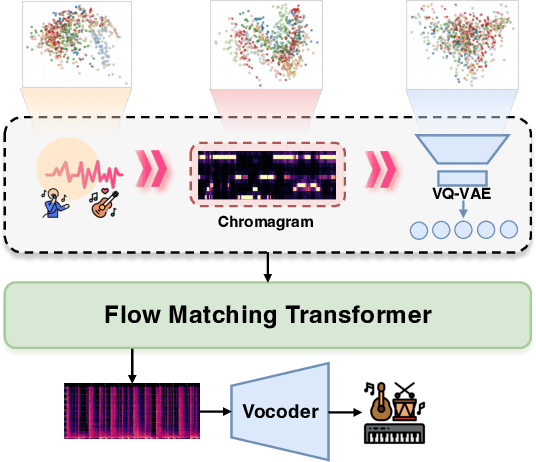
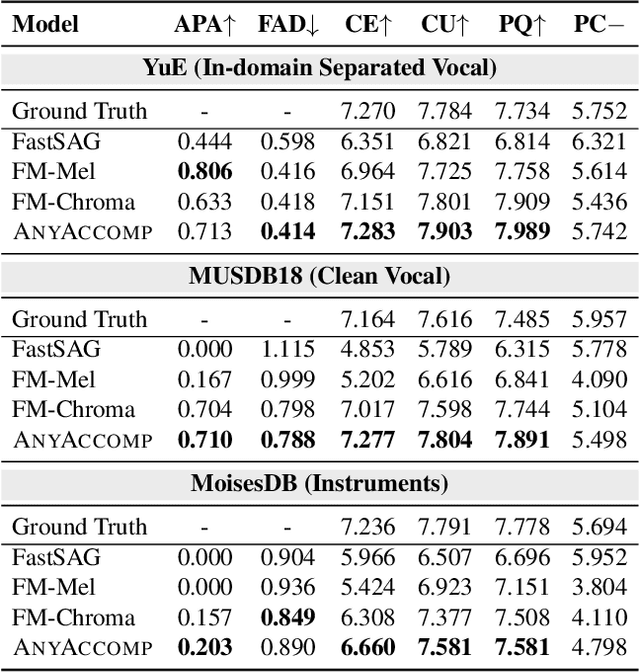
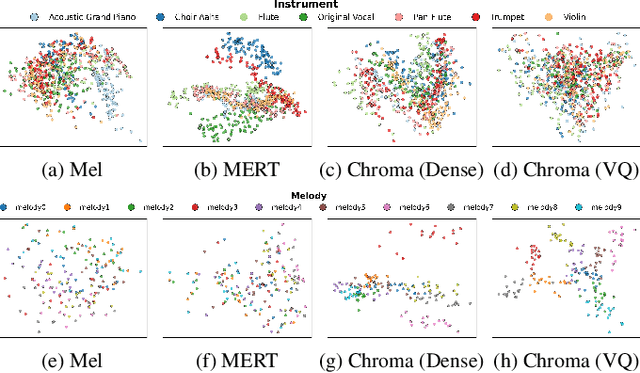
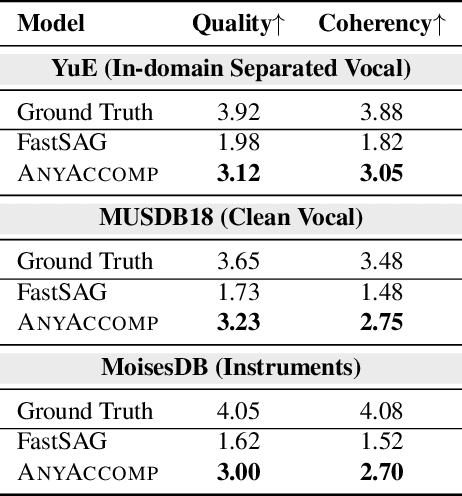
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
Guitar Tone Morphing by Diffusion-based Model
Oct 09, 2025


In Music Information Retrieval (MIR), modeling and transforming the tone of musical instruments, particularly electric guitars, has gained increasing attention due to the richness of the instrument tone and the flexibility of expression. Tone morphing enables smooth transitions between different guitar sounds, giving musicians greater freedom to explore new textures and personalize their performances. This study explores learning-based approaches for guitar tone morphing, beginning with LoRA fine-tuning to improve the model performance on limited data. Moreover, we introduce a simpler method, named spherical interpolation using Music2Latent. It yields significantly better results than the more complex fine-tuning approach. Experiments show that the proposed architecture generates smoother and more natural tone transitions, making it a practical and efficient tool for music production and real-time audio effects.
* 5 pages
TalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling
Oct 02, 2025



While the recent developments in large language models (LLMs) have successfully enabled generative recommenders with natural language interactions, their recommendation behavior is limited, leaving other simpler yet crucial components such as metadata or attribute filtering underutilized in the system. We propose an LLM-based music recommendation system with tool calling to serve as a unified retrieval-reranking pipeline. Our system positions an LLM as an end-to-end recommendation system that interprets user intent, plans tool invocations, and orchestrates specialized components: boolean filters (SQL), sparse retrieval (BM25), dense retrieval (embedding similarity), and generative retrieval (semantic IDs). Through tool planning, the system predicts which types of tools to use, their execution order, and the arguments needed to find music matching user preferences, supporting diverse modalities while seamlessly integrating multiple database filtering methods. We demonstrate that this unified tool-calling framework achieves competitive performance across diverse recommendation scenarios by selectively employing appropriate retrieval methods based on user queries, envisioning a new paradigm for conversational music recommendation systems.