 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark
Papers and Code
Consistent Point Matching
Jul 31, 2025This study demonstrates that incorporating a consistency heuristic into the point-matching algorithm \cite{yerebakan2023hierarchical} improves robustness in matching anatomical locations across pairs of medical images. We validated our approach on diverse longitudinal internal and public datasets spanning CT and MRI modalities. Notably, it surpasses state-of-the-art results on the Deep Lesion Tracking dataset. Additionally, we show that the method effectively addresses landmark localization. The algorithm operates efficiently on standard CPU hardware and allows configurable trade-offs between speed and robustness. The method enables high-precision navigation between medical images without requiring a machine learning model or training data.
Mask-Free Audio-driven Talking Face Generation for Enhanced Visual Quality and Identity Preservation
Jul 28, 2025Audio-Driven Talking Face Generation aims at generating realistic videos of talking faces, focusing on accurate audio-lip synchronization without deteriorating any identity-related visual details. Recent state-of-the-art methods are based on inpainting, meaning that the lower half of the input face is masked, and the model fills the masked region by generating lips aligned with the given audio. Hence, to preserve identity-related visual details from the lower half, these approaches additionally require an unmasked identity reference image randomly selected from the same video. However, this common masking strategy suffers from (1) information loss in the input faces, significantly affecting the networks' ability to preserve visual quality and identity details, (2) variation between identity reference and input image degrading reconstruction performance, and (3) the identity reference negatively impacting the model, causing unintended copying of elements unaligned with the audio. To address these issues, we propose a mask-free talking face generation approach while maintaining the 2D-based face editing task. Instead of masking the lower half, we transform the input images to have closed mouths, using a two-step landmark-based approach trained in an unpaired manner. Subsequently, we provide these edited but unmasked faces to a lip adaptation model alongside the audio to generate appropriate lip movements. Thus, our approach needs neither masked input images nor identity reference images. We conduct experiments on the benchmark LRS2 and HDTF datasets and perform various ablation studies to validate our contributions.
JOLT3D: Joint Learning of Talking Heads and 3DMM Parameters with Application to Lip-Sync
Jul 28, 2025In this work, we revisit the effectiveness of 3DMM for talking head synthesis by jointly learning a 3D face reconstruction model and a talking head synthesis model. This enables us to obtain a FACS-based blendshape representation of facial expressions that is optimized for talking head synthesis. This contrasts with previous methods that either fit 3DMM parameters to 2D landmarks or rely on pretrained face reconstruction models. Not only does our approach increase the quality of the generated face, but it also allows us to take advantage of the blendshape representation to modify just the mouth region for the purpose of audio-based lip-sync. To this end, we propose a novel lip-sync pipeline that, unlike previous methods, decouples the original chin contour from the lip-synced chin contour, and reduces flickering near the mouth.
Beyond Line-of-Sight: Cooperative Localization Using Vision and V2X Communication
Jul 28, 2025Accurate and robust localization is critical for the safe operation of Connected and Automated Vehicles (CAVs), especially in complex urban environments where Global Navigation Satellite System (GNSS) signals are unreliable. This paper presents a novel vision-based cooperative localization algorithm that leverages onboard cameras and Vehicle-to-Everything (V2X) communication to enable CAVs to estimate their poses, even in occlusion-heavy scenarios such as busy intersections. In particular, we propose a novel decentralized observer for a group of connected agents that includes landmark agents (static or moving) in the environment with known positions and vehicle agents that need to estimate their poses (both positions and orientations). Assuming that (i) there are at least three landmark agents in the environment, (ii) each vehicle agent can measure its own angular and translational velocities as well as relative bearings to at least three neighboring landmarks or vehicles, and (iii) neighboring vehicles can communicate their pose estimates, each vehicle can estimate its own pose using the proposed decentralized observer. We prove that the origin of the estimation error is locally exponentially stable under the proposed observer, provided that the minimal observability conditions are satisfied. Moreover, we evaluate the proposed approach through experiments with real 1/10th-scale connected vehicles and large-scale simulations, demonstrating its scalability and validating the theoretical guarantees in practical scenarios.
Modular Robot and Landmark Localisation Using Relative Bearing Measurements
Jul 24, 2025In this paper we propose a modular nonlinear least squares filtering approach for systems composed of independent subsystems. The state and error covariance estimate of each subsystem is updated independently, even when a relative measurement simultaneously depends on the states of multiple subsystems. We integrate the Covariance Intersection (CI) algorithm as part of our solution in order to prevent double counting of information when subsystems share estimates with each other. An alternative derivation of the CI algorithm based on least squares estimation makes this integration possible. We particularise the proposed approach to the robot-landmark localization problem. In this problem, noisy measurements of the bearing angle to a stationary landmark position measured relative to the SE(2) pose of a moving robot couple the estimation problems for the robot pose and the landmark position. In a randomized simulation study, we benchmark the proposed modular method against a monolithic joint state filter to elucidate their respective trade-offs. In this study we also include variants of the proposed method that achieve a graceful degradation of performance with reduced communication and bandwidth requirements.
DOOMGAN:High-Fidelity Dynamic Identity Obfuscation Ocular Generative Morphing
Jul 23, 2025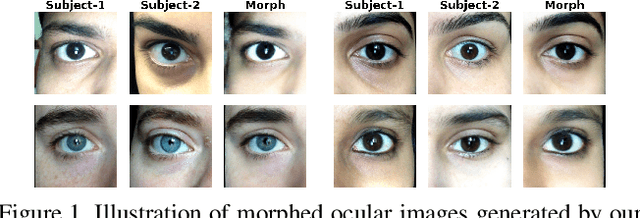
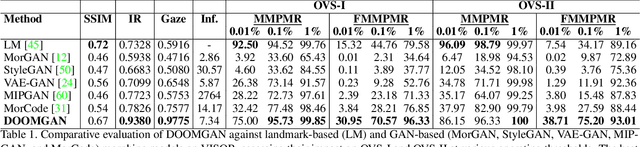
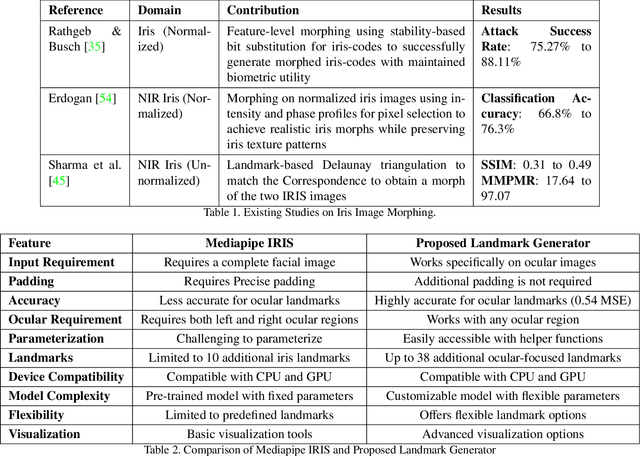
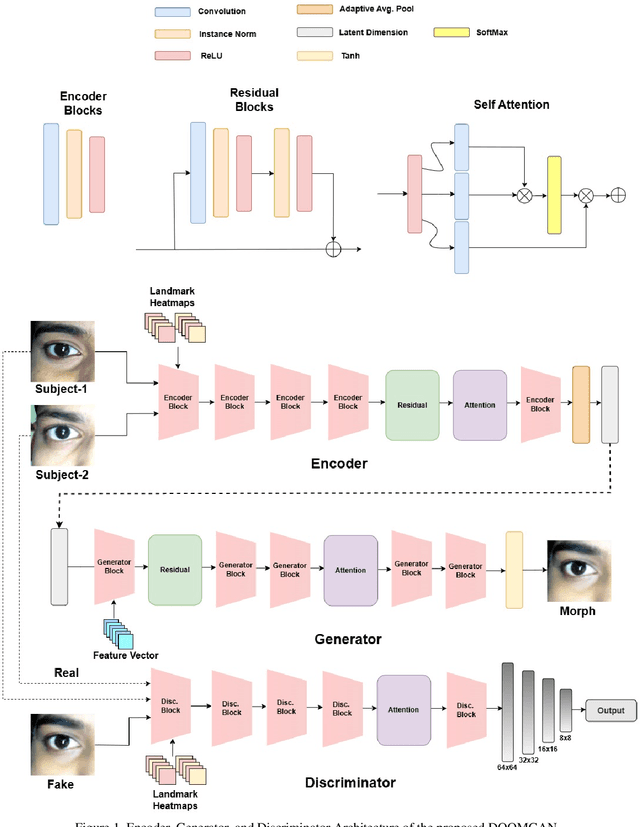
Ocular biometrics in the visible spectrum have emerged as a prominent modality due to their high accuracy, resistance to spoofing, and non-invasive nature. However, morphing attacks, synthetic biometric traits created by blending features from multiple individuals, threaten biometric system integrity. While extensively studied for near-infrared iris and face biometrics, morphing in visible-spectrum ocular data remains underexplored. Simulating such attacks demands advanced generation models that handle uncontrolled conditions while preserving detailed ocular features like iris boundaries and periocular textures. To address this gap, we introduce DOOMGAN, that encompasses landmark-driven encoding of visible ocular anatomy, attention-guided generation for realistic morph synthesis, and dynamic weighting of multi-faceted losses for optimized convergence. DOOMGAN achieves over 20% higher attack success rates than baseline methods under stringent thresholds, along with 20% better elliptical iris structure generation and 30% improved gaze consistency. We also release the first comprehensive ocular morphing dataset to support further research in this domain.
OPEN: A Benchmark Dataset and Baseline for Older Adult Patient Engagement Recognition in Virtual Rehabilitation Learning Environments
Jul 23, 2025Engagement in virtual learning is essential for participant satisfaction, performance, and adherence, particularly in online education and virtual rehabilitation, where interactive communication plays a key role. Yet, accurately measuring engagement in virtual group settings remains a challenge. There is increasing interest in using artificial intelligence (AI) for large-scale, real-world, automated engagement recognition. While engagement has been widely studied in younger academic populations, research and datasets focused on older adults in virtual and telehealth learning settings remain limited. Existing methods often neglect contextual relevance and the longitudinal nature of engagement across sessions. This paper introduces OPEN (Older adult Patient ENgagement), a novel dataset supporting AI-driven engagement recognition. It was collected from eleven older adults participating in weekly virtual group learning sessions over six weeks as part of cardiac rehabilitation, producing over 35 hours of data, making it the largest dataset of its kind. To protect privacy, raw video is withheld; instead, the released data include facial, hand, and body joint landmarks, along with affective and behavioral features extracted from video. Annotations include binary engagement states, affective and behavioral labels, and context-type indicators, such as whether the instructor addressed the group or an individual. The dataset offers versions with 5-, 10-, 30-second, and variable-length samples. To demonstrate utility, multiple machine learning and deep learning models were trained, achieving engagement recognition accuracy of up to 81 percent. OPEN provides a scalable foundation for personalized engagement modeling in aging populations and contributes to broader engagement recognition research.
Morpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
Jul 22, 2025Previous animatronic faces struggle to express emotions effectively due to hardware and software limitations. On the hardware side, earlier approaches either use rigid-driven mechanisms, which provide precise control but are difficult to design within constrained spaces, or tendon-driven mechanisms, which are more space-efficient but challenging to control. In contrast, we propose a hybrid actuation approach that combines the best of both worlds. The eyes and mouth-key areas for emotional expression-are controlled using rigid mechanisms for precise movement, while the nose and cheek, which convey subtle facial microexpressions, are driven by strings. This design allows us to build a compact yet versatile hardware platform capable of expressing a wide range of emotions. On the algorithmic side, our method introduces a self-modeling network that maps motor actions to facial landmarks, allowing us to automatically establish the relationship between blendshape coefficients for different facial expressions and the corresponding motor control signals through gradient backpropagation. We then train a neural network to map speech input to corresponding blendshape controls. With our method, we can generate distinct emotional expressions such as happiness, fear, disgust, and anger, from any given sentence, each with nuanced, emotion-specific control signals-a feature that has not been demonstrated in earlier systems. We release the hardware design and code at https://github.com/ZZongzheng0918/Morpheus-Hardware and https://github.com/ZZongzheng0918/Morpheus-Software.
HOComp: Interaction-Aware Human-Object Composition
Jul 22, 2025While existing image-guided composition methods may help insert a foreground object onto a user-specified region of a background image, achieving natural blending inside the region with the rest of the image unchanged, we observe that these existing methods often struggle in synthesizing seamless interaction-aware compositions when the task involves human-object interactions. In this paper, we first propose HOComp, a novel approach for compositing a foreground object onto a human-centric background image, while ensuring harmonious interactions between the foreground object and the background person and their consistent appearances. Our approach includes two key designs: (1) MLLMs-driven Region-based Pose Guidance (MRPG), which utilizes MLLMs to identify the interaction region as well as the interaction type (e.g., holding and lefting) to provide coarse-to-fine constraints to the generated pose for the interaction while incorporating human pose landmarks to track action variations and enforcing fine-grained pose constraints; and (2) Detail-Consistent Appearance Preservation (DCAP), which unifies a shape-aware attention modulation mechanism, a multi-view appearance loss, and a background consistency loss to ensure consistent shapes/textures of the foreground and faithful reproduction of the background human. We then propose the first dataset, named Interaction-aware Human-Object Composition (IHOC), for the task. Experimental results on our dataset show that HOComp effectively generates harmonious human-object interactions with consistent appearances, and outperforms relevant methods qualitatively and quantitatively.
Generative AI-Driven High-Fidelity Human Motion Simulation
Jul 18, 2025



Human motion simulation (HMS) supports cost-effective evaluation of worker behavior, safety, and productivity in industrial tasks. However, existing methods often suffer from low motion fidelity. This study introduces Generative-AI-Enabled HMS (G-AI-HMS), which integrates text-to-text and text-to-motion models to enhance simulation quality for physical tasks. G-AI-HMS tackles two key challenges: (1) translating task descriptions into motion-aware language using Large Language Models aligned with MotionGPT's training vocabulary, and (2) validating AI-enhanced motions against real human movements using computer vision. Posture estimation algorithms are applied to real-time videos to extract joint landmarks, and motion similarity metrics are used to compare them with AI-enhanced sequences. In a case study involving eight tasks, the AI-enhanced motions showed lower error than human created descriptions in most scenarios, performing better in six tasks based on spatial accuracy, four tasks based on alignment after pose normalization, and seven tasks based on overall temporal similarity. Statistical analysis showed that AI-enhanced prompts significantly (p $<$ 0.0001) reduced joint error and temporal misalignment while retaining comparable posture accuracy.