 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
Jul 22, 2025Previous animatronic faces struggle to express emotions effectively due to hardware and software limitations. On the hardware side, earlier approaches either use rigid-driven mechanisms, which provide precise control but are difficult to design within constrained spaces, or tendon-driven mechanisms, which are more space-efficient but challenging to control. In contrast, we propose a hybrid actuation approach that combines the best of both worlds. The eyes and mouth-key areas for emotional expression-are controlled using rigid mechanisms for precise movement, while the nose and cheek, which convey subtle facial microexpressions, are driven by strings. This design allows us to build a compact yet versatile hardware platform capable of expressing a wide range of emotions. On the algorithmic side, our method introduces a self-modeling network that maps motor actions to facial landmarks, allowing us to automatically establish the relationship between blendshape coefficients for different facial expressions and the corresponding motor control signals through gradient backpropagation. We then train a neural network to map speech input to corresponding blendshape controls. With our method, we can generate distinct emotional expressions such as happiness, fear, disgust, and anger, from any given sentence, each with nuanced, emotion-specific control signals-a feature that has not been demonstrated in earlier systems. We release the hardware design and code at https://github.com/ZZongzheng0918/Morpheus-Hardware and https://github.com/ZZongzheng0918/Morpheus-Software.
Expansion-Squeeze-Excitation Fusion Network for Elderly Activity Recognition
Dec 21, 2021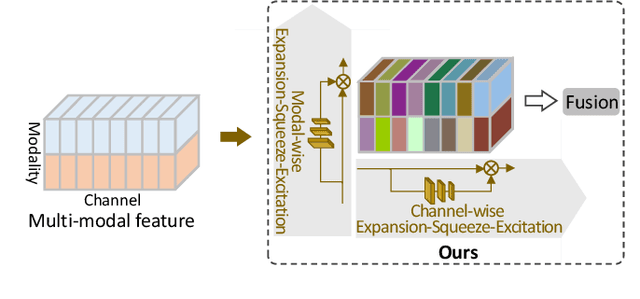

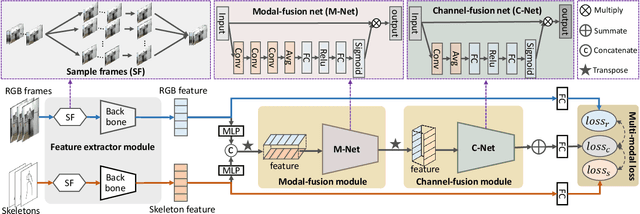

This work focuses on the task of elderly activity recognition, which is a challenging task due to the existence of individual actions and human-object interactions in elderly activities. Thus, we attempt to effectively aggregate the discriminative information of actions and interactions from both RGB videos and skeleton sequences by attentively fusing multi-modal features. Recently, some nonlinear multi-modal fusion approaches are proposed by utilizing nonlinear attention mechanism that is extended from Squeeze-and-Excitation Networks (SENet). Inspired by this, we propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to effectively address the problem of elderly activity recognition, which learns modal and channel-wise Expansion-Squeeze-Excitation (ESE) attentions for attentively fusing the multi-modal features in the modal and channel-wise ways. Furthermore, we design a new Multi-modal Loss (ML) to keep the consistency between the single-modal features and the fused multi-modal features by adding the penalty of difference between the minimum prediction losses on single modalities and the prediction loss on the fused modality. Finally, we conduct experiments on a largest-scale elderly activity dataset, i.e., ETRI-Activity3D (including 110,000+ videos, and 50+ categories), to demonstrate that the proposed ESE-FN achieves the best accuracy compared with the state-of-the-art methods. In addition, more extensive experimental results show that the proposed ESE-FN is also comparable to the other methods in terms of normal action recognition task.